- The paper introduces an integrated PyTorch framework that combines GPU-accelerated sparse solvers with adjoint-based differentiation for efficient, large-scale simulations.
- The methodology reduces autograd graph complexity from O(k) to O(n + nnz), achieving memory and compute efficiency on problems scaling from 10K to 400M DOF.
- The implementation features distributed multi-GPU sparse tensor parallelism, enabling near-linear scaling and practical deployment for physics-informed machine learning and simulation tasks.
torch-sla: Differentiable Sparse Linear Algebra with Adjoint Solvers and Sparse Tensor Parallelism for PyTorch
Overview and Motivation
The torch-sla library introduces a comprehensive framework for scalable, GPU-accelerated, and differentiable sparse linear algebra, tailored for integration with PyTorch. Unlike dense matrix operations, scientific and industrial applications frequently generate large sparse systems characteristic of finite element meshes, graph networks, and point clouds. Making these computations differentiable and tractable at industrial scales—on contemporary hardware, with end-to-end gradient support—poses critical challenges, particularly with iterative solver differentiation, multi-GPU scaling, and efficient utilization of GPU bandwidth. torch-sla targets this intersection of high-performance sparse computation, distributed simulation, and differentiable programming.
Technical Contributions
GPU-Accelerated Sparse Solvers with PyTorch Integration
torch-sla provides unified APIs for key algorithmic primitives:
- Linear Solves: CG, BiCGStab with SPARSE backends (cuDSS, PyTorch GPU-native, SciPy).
- Nonlinear Solves: Newton, Picard, Anderson acceleration.
- Eigenvalue Computation: LOBPCG.
Backend selection is automated to optimize for problem size and hardware, falling back to iterative algorithms once memory-bound direct solvers reach their limits. This design enables effortless scaling from small to extremely large problems (>100 million DOF), all within PyTorch’s computational graph and autograd system.
Single-GPU benchmarks on H200 demonstrate torch-sla’s ability to scale PyTorch CG from 10K to 169M DOF while maintaining competitive memory efficiency, with iterative solvers outpacing direct solvers past 1M DOF due to superior scaling in memory and compute.
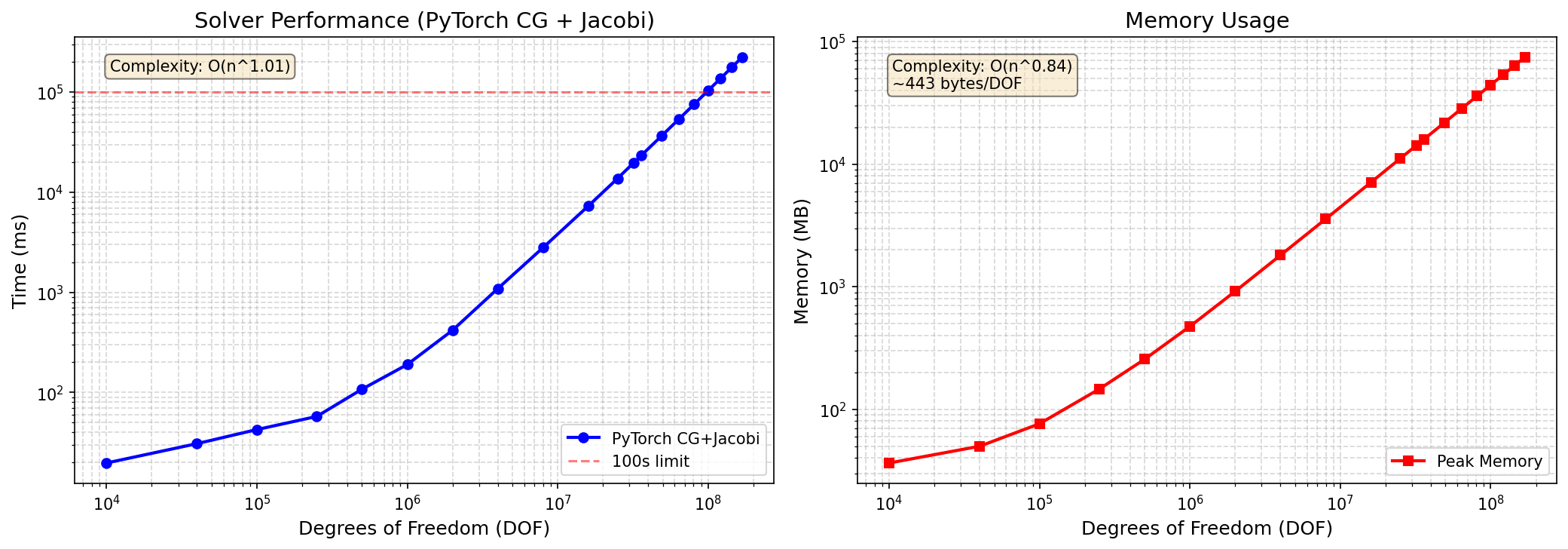
Figure 1: Single-GPU benchmark results highlight performance, memory, and solver residuals for SciPy, cuDSS, and PyTorch CG backends on 2D Poisson problems with H200 GPU.
Adjoint-Based Differentiation: O(1) Graph Complexity
Differentiating through iterative solvers using autograd naively incurs O(k) graph nodes for k iterations, resulting in unsustainable memory requirements (∼80GB at 1M DOF, 1000 CG steps). torch-sla instead deploys adjoint-based implicit differentiation, leveraging the implicit function theorem to decouple gradient computation from solver iterations.
In the linear case x=A−1b, the backward pass solves a single adjoint system A⊤λ=∂L/∂x, with gradients ∂L/∂b=λ and ∂L/∂Aij=−λixj for each nonzero. For nonlinear and eigenvalue problems, similar adjoint formulations are used, with complexities governed by solution vector and nonzero count—completely independent of iteration count. Rigorous gradient verifications against finite-difference baselines confirm relative errors below 10−5, substantiating both correctness and efficiency.
The adjoint approach reduces memory from O(kn) to O(n+nnz), and backward pass duration to that of a single solve plus matrix-vector gradient accrual.
Distributed Multi-GPU Sparse Tensor Parallelism
torch-sla’s parallel architecture centers around domain decomposition and automatic halo exchange, following industrial paradigms (e.g., PETSc, OpenFOAM) but tightly integrated with autograd. Distributed sparse matrix-vector multiplication initiates asynchronous boundary communication, synchronization, and local computation, while distributed CG augments this with global reductions for dot products.
Partition strategies include METIS (graph partitioning), RCB, and contiguous schemes, optimizing load balance and communication surface.
Distributed CG achieves near-linear scaling with H200 GPUs, efficiently solving up to 400M DOF on three devices. Per-GPU memory aligns with the theoretical minimum for sparse matrices and vectors, while performance demonstrates throughput approaching hardware peak bandwidth.
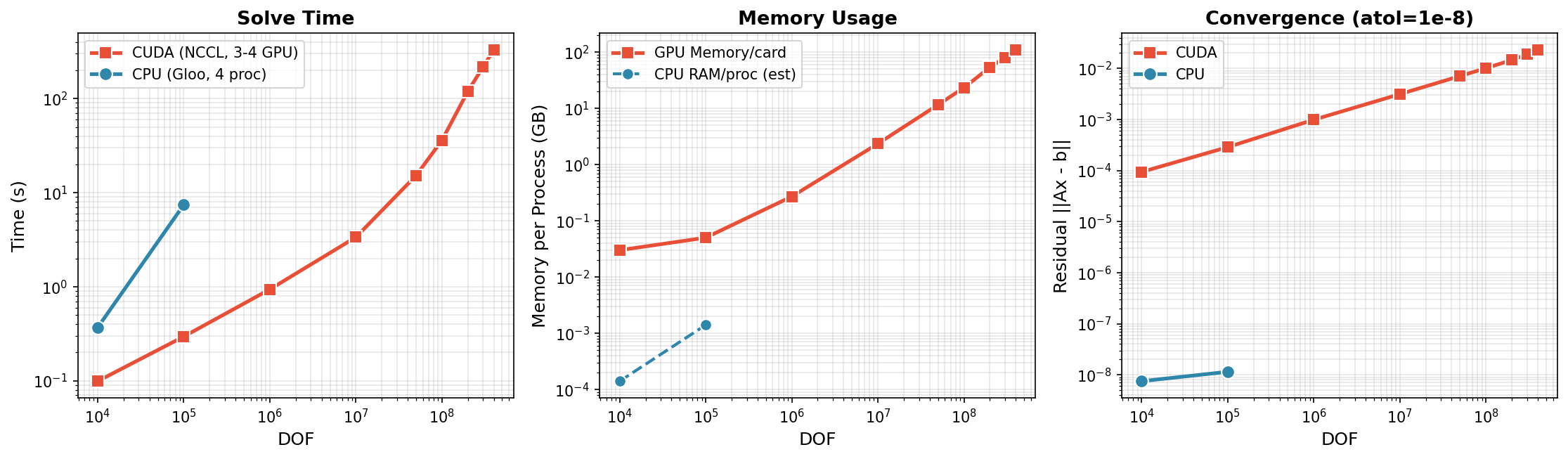
Figure 2: Multi-GPU scaling of distributed CG with NCCL backend reveals time and memory scaling across problem sizes up to 400M DOF.
Residual convergence rates correspond to theoretical expectations for Jacobi-preconditioned CG, with elevated condition numbers at high DOF. Communication per iteration is bound by halo and global reduction complexity.
Numerical Results and Claims
Benchmarks validate several salient claims:
- Iterative solvers remain feasible (and performant) up to hundreds of millions of DOF, with direct solvers failing due to memory fill-in.
- Single-GPU PyTorch CG achieves α≈1.1 time scaling (T=cnα) for 2D Poisson, confirming subquadratic time scaling.
- Distributed CG sustains ∼2.8M DOF/sec throughput at 100M DOF, with memory efficiency at 275 bytes/DOF at 400M DOF.
- Adjoint differentiation dramatically reduces autograd graph complexity and memory, enabling gradients at scale with correctness validated by finite differences.
Practical and Theoretical Implications
torch-sla enables seamless integration of high-fidelity, differentiable physics simulations and scientific computational workflows within deep learning pipelines. End-to-end gradient propagation through entire multi-GPU sparse simulation workflows becomes practical, unlocking new optimization and learning paradigms for physics-informed ML, neural operators, computational engineering, and graph-based learning systems.
By abstracting distributed computation and adjoint gradient propagation under the same PyTorch API, torch-sla bridges the gap between high-performance scientific simulation libraries and differentiable programming, supporting hybrid neural-classical solvers, learned preconditioners, and simulation-as-optimization tasks.
Prospects for Future Developments
The paper outlines several avenues for advancing differentiable sparse simulation:
- Roofline-Guided Tuning: Communications-avoiding variants, dynamic partitioning, and compute/comm overlap for improved scaling.
- Learned Preconditioners: Meta-learning and GNN-based multigrid for adaptive solver convergence.
- Mixed Precision SpMV: Enabling higher throughput with appropriate numerical stability safeguards.
- Hybrid Neural Operators: Merging with FNO, DeepONet, mesh-based GNNs for multi-resolution PDE solvers.
- Differentiable Simulation Pipelines: Integration with frameworks such as ΦFlow and DiffTaichi for full-stack physics optimization and design.
The library’s open-source availability under MIT license and scalable distributed architecture position it as a foundation for future research in differentiable scientific computing, optimization, and simulation-informed AI.
Conclusion
torch-sla delivers efficient, scalable, and differentiable sparse linear algebra with adjoint-based solvers and distributed tensor parallelism, directly within PyTorch. It enables industrial-scale problems—with up to 400M degrees of freedom—to be incorporated in end-to-end learning, simulation, and optimization tasks, establishing a robust platform for future advances in scientific machine learning, differentiable physics, and hybrid neural-simulation paradigms (2601.13994).

