Communication-Free Collective Navigation for a Swarm of UAVs via LiDAR-Based Deep Reinforcement Learning
Abstract: This paper presents a deep reinforcement learning (DRL) based controller for collective navigation of unmanned aerial vehicle (UAV) swarms in communication-denied environments, enabling robust operation in complex, obstacle-rich environments. Inspired by biological swarms where informed individuals guide groups without explicit communication, we employ an implicit leader-follower framework. In this paradigm, only the leader possesses goal information, while follower UAVs learn robust policies using only onboard LiDAR sensing, without requiring any inter-agent communication or leader identification. Our system utilizes LiDAR point clustering and an extended Kalman filter for stable neighbor tracking, providing reliable perception independent of external positioning systems. The core of our approach is a DRL controller, trained in GPU-accelerated Nvidia Isaac Sim, that enables followers to learn complex emergent behaviors - balancing flocking and obstacle avoidance - using only local perception. This allows the swarm to implicitly follow the leader while robustly addressing perceptual challenges such as occlusion and limited field-of-view. The robustness and sim-to-real transfer of our approach are confirmed through extensive simulations and challenging real-world experiments with a swarm of five UAVs, which successfully demonstrated collective navigation across diverse indoor and outdoor environments without any communication or external localization.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching a group of drones (a “swarm”) to fly together to a destination without talking to each other and without GPS. Only one drone—the leader—knows where to go. The others just use their own sensors to look around and learn to stick together and avoid obstacles. The key idea: use a laser-based sensor (LiDAR) for “seeing” and a learning method called deep reinforcement learning (DRL) so the followers can figure out how to behave by practicing in simulation.
What questions did the researchers ask?
- Can a swarm of drones travel together toward a goal when communication is blocked and GPS isn’t available?
- Can the followers learn to keep the group together and avoid obstacles using only what they can sense nearby (no shared maps, no messages)?
- Is it possible for the group to follow the leader without knowing who the leader is or where the goal is?
- Will a policy learned in simulation still work in real outdoor and indoor environments?
How did they do it?
LiDAR-based “eyes” for each drone
- LiDAR is like a laser scanner that spins around and measures how far things are—think of it as a flashlight that can “feel” distances instead of brightness. It works in bright sun or darkness.
- Each drone uses a single 360° LiDAR to spot nearby drones and obstacles. To make drones easy to detect, they have reflective tape that bounces back strong LiDAR signals.
- The raw LiDAR “dots” (points) are:
- Grouped into blobs that represent objects (like clustering nearby dots together—similar to noticing that nearby sprinkles on a donut belong to the same cluster).
- Tracked over time with an extended Kalman filter (EKF), which is a math method that smooths noisy measurements by predicting where things should be next and correcting that guess with new data. Think of it like keeping track of a friend in a crowd by guessing where they’re walking and adjusting as you see them again.
Teaching drones with trial and error (deep reinforcement learning)
- Followers don’t get the goal or leader identity. They only get:
- Their own motion (how fast and which way they’re tilted),
- A simple map of nearby obstacles,
- The positions and movements of a few nearest neighbors (up to six).
- The learning method, DRL, works like this: try an action, see what happens, get a score (reward), and repeat millions of times to improve.
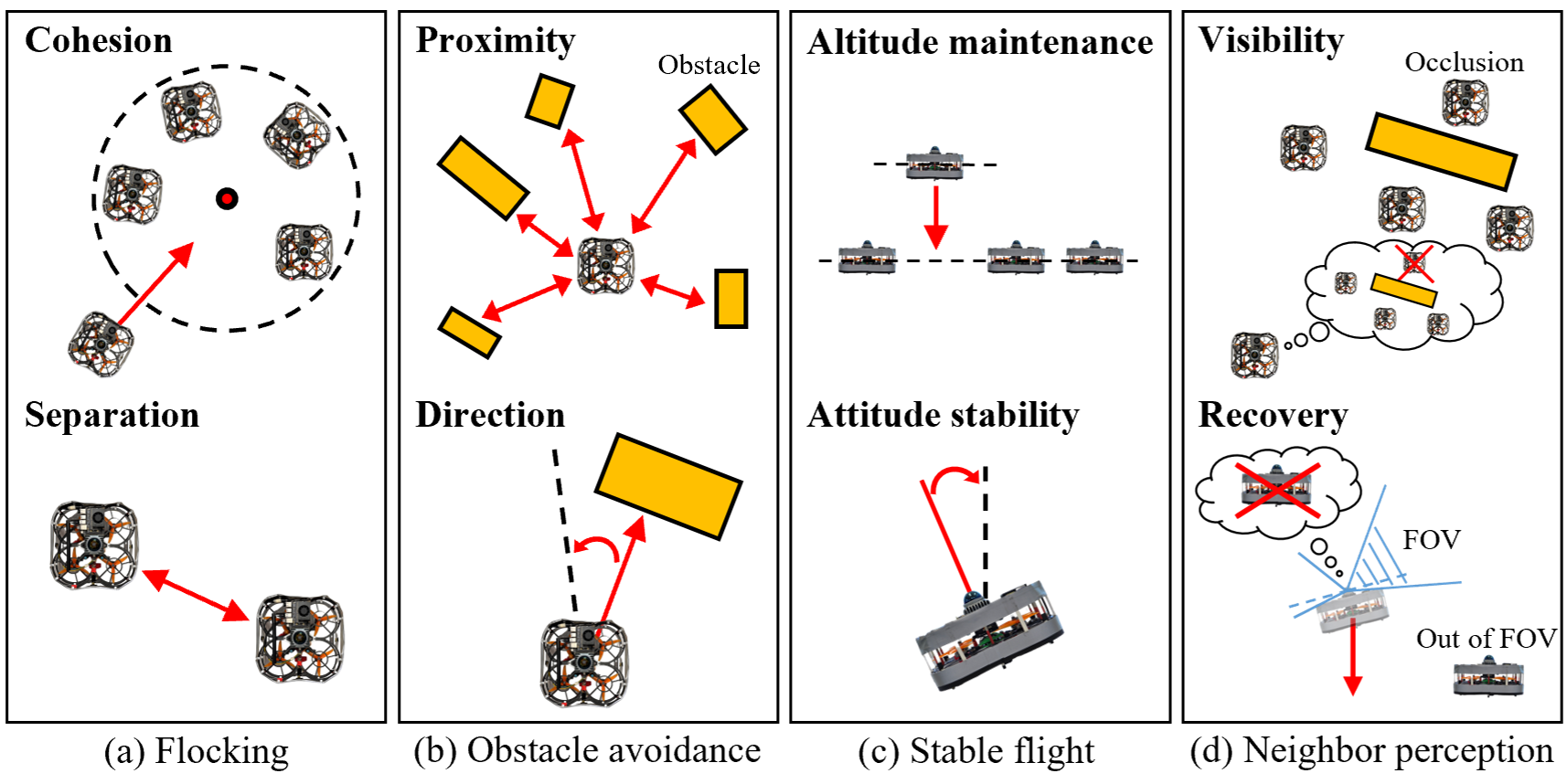
- The reward encourages:
- Staying close to the group but not too close (no bumping),
- Avoiding obstacles and not flying toward them,
- Keeping flight stable (right height and upright),
- Keeping neighbors in view (so you don’t lose the group), and a recovery move if you do lose them.
- Importantly, the followers are not given their absolute position as input during learning. This helps them learn behaviors that work anywhere, not just in one specific map.
Training in simulation, then real-world tests
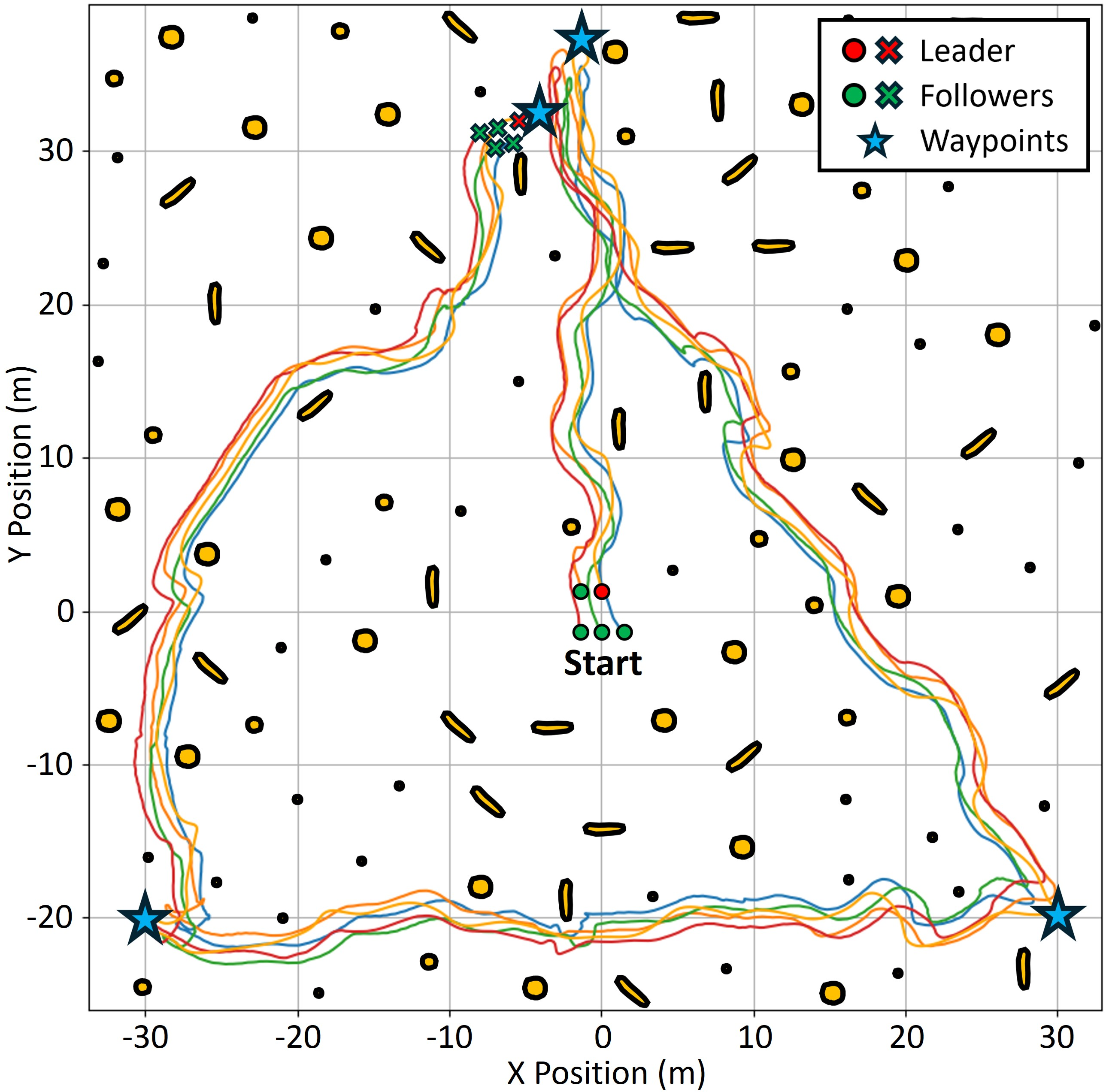
- They trained in Nvidia Isaac Sim (a high-fidelity simulator), running hundreds of training worlds in parallel—like practicing in many game levels at once.
- The leader used a standard path planning method to move toward waypoints while avoiding obstacles.
- The team added realistic challenges to training: sensor noise, limited viewing angles, occlusions (when something blocks the view), and delays from onboard processing.
- After training, they tested with five real drones, indoors and outdoors, without GPS and without any communication between drones.
What did they find, and why does it matter?
- The followers learned to:
- Stay together using only local sensing,
- Avoid obstacles in tight, cluttered spaces,
- “Implicitly” follow the leader—meaning the group naturally moved toward the goal as they stayed cohesive, even though the followers didn’t know the goal or who the leader was.
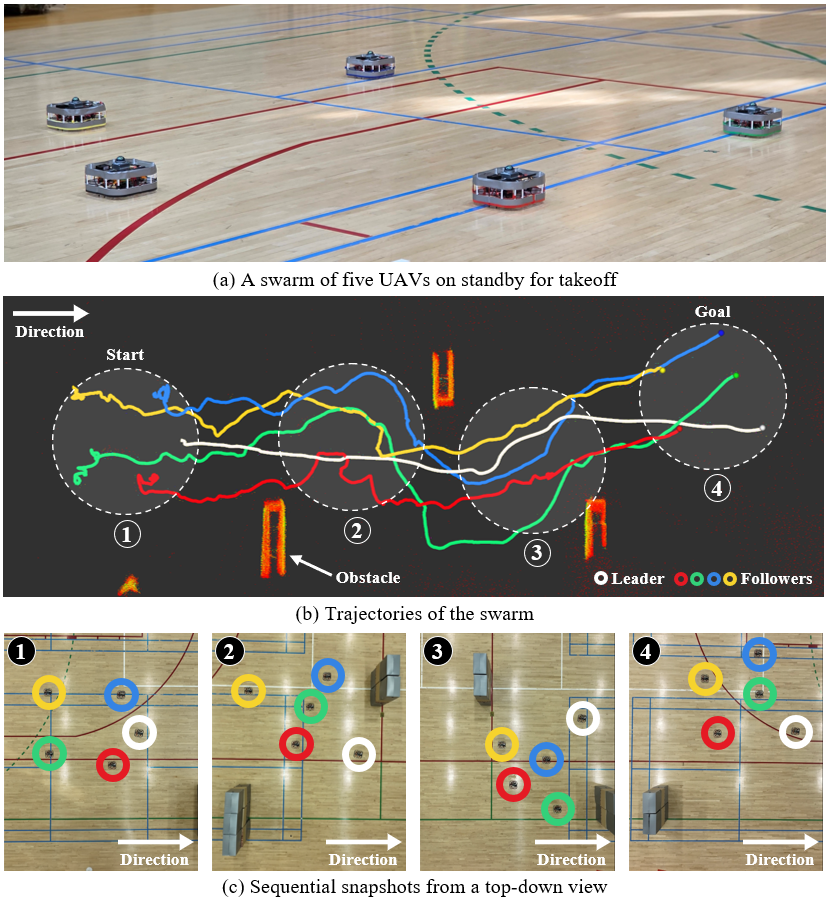
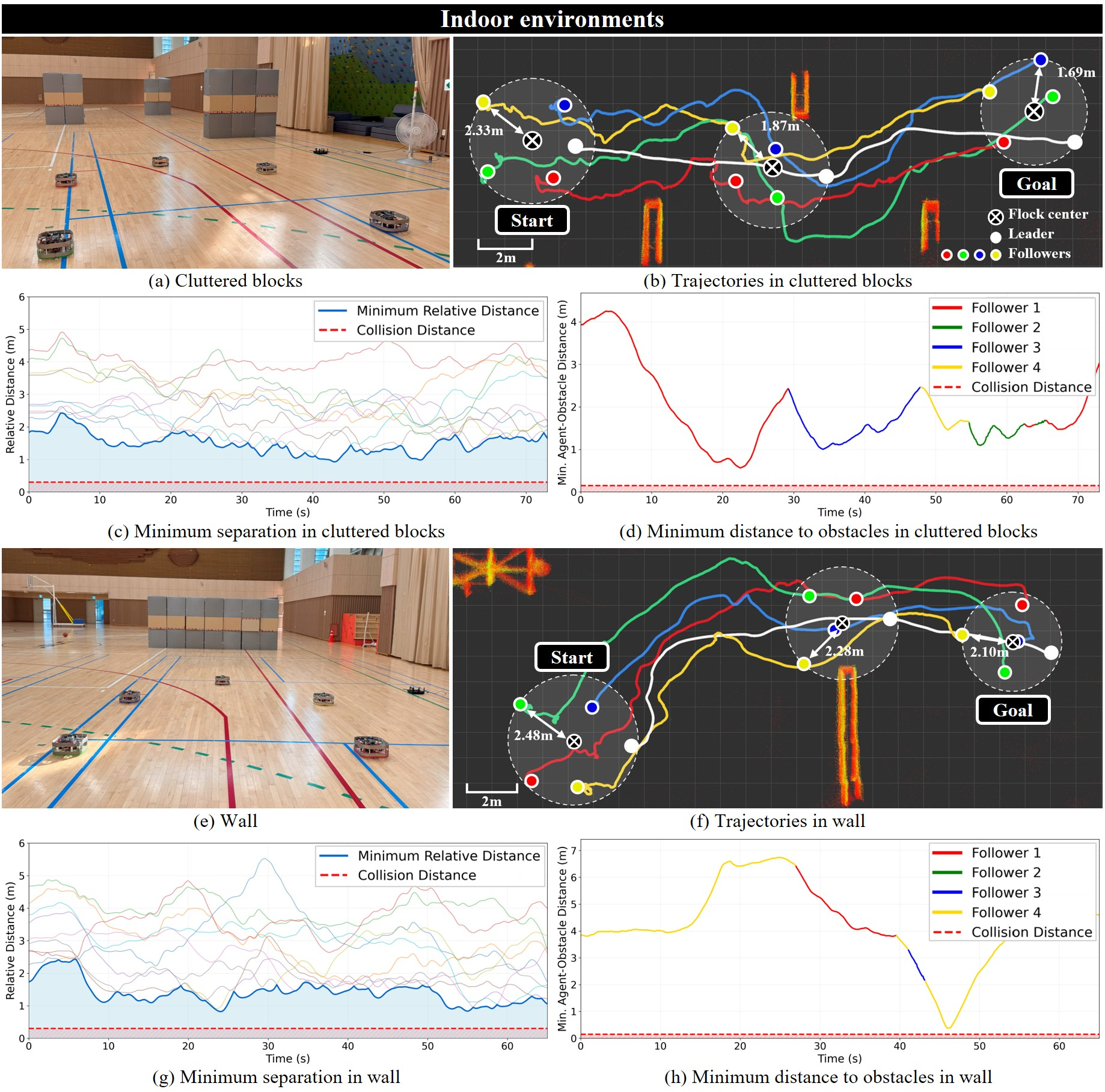
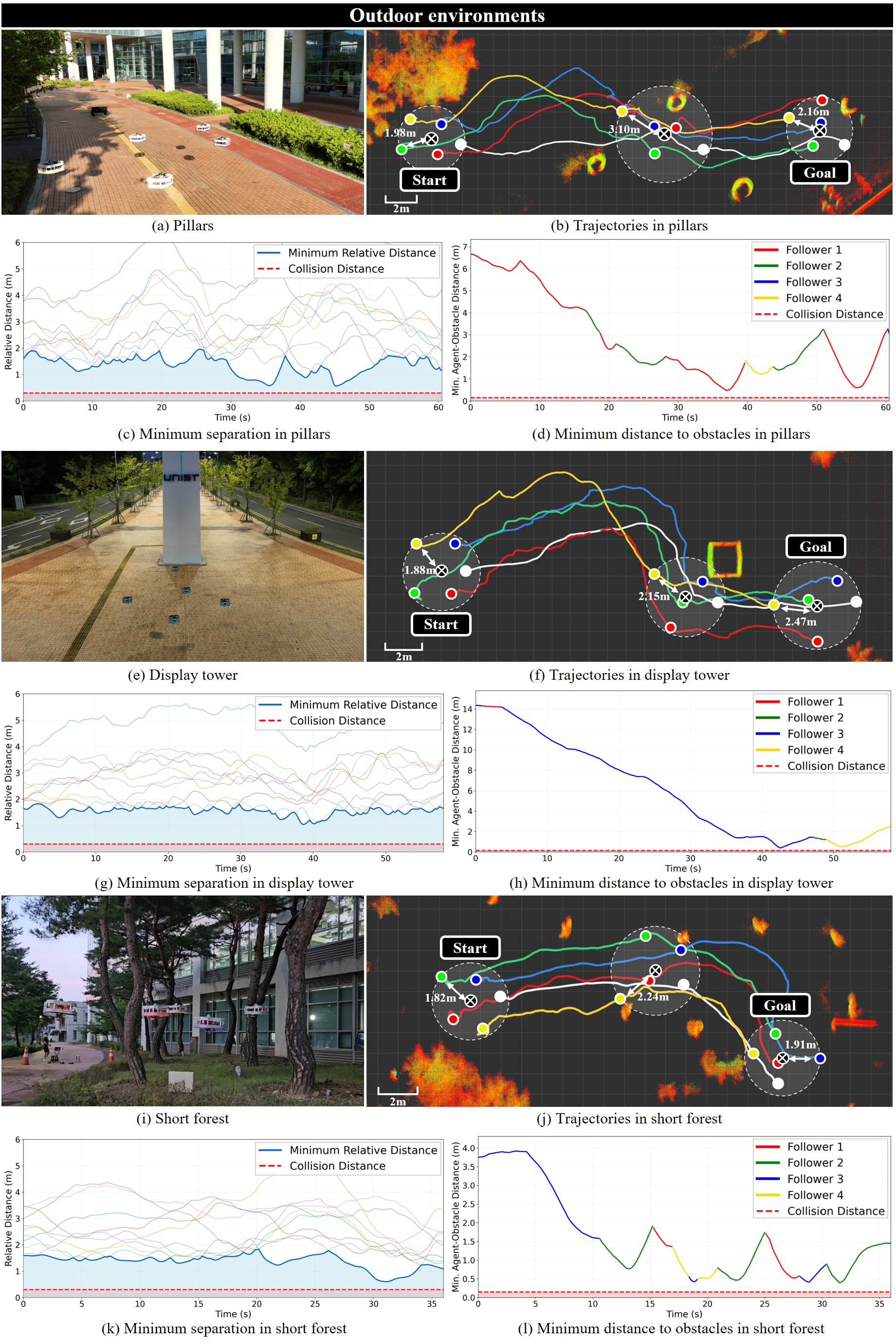
- The approach worked in both simulation and real-world trials with five drones in different environments, without external tracking systems or inter-drone messages.
- This is the first time (to the authors’ knowledge) a LiDAR-based, communication-free swarm navigation strategy trained with DRL was successfully tested in the real world.
Why it matters:
- Swarms that don’t rely on communication or GPS can still work during power outages, in disaster zones, under jamming, or in places without infrastructure.
- Using a single LiDAR keeps the hardware simpler and more reliable than multi-camera systems, and it works in all lighting conditions.
What’s the impact and what could come next?
- Practical uses include search and rescue, inspecting dangerous areas, or exploring after disasters—situations where communication and GPS might fail.
- It reduces the need for heavy network traffic between drones, making large swarms more scalable.
- Future steps could include:
- Scaling to larger swarms,
- Removing the need for reflective tape by improving detection,
- Handling even denser obstacles and more complex missions,
- Combining this with other sensors for even greater robustness.
In short, the researchers showed that a drone swarm can learn to travel together safely and purposefully using only what each drone can see and sense locally, no talking required.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
The following list captures what remains missing, uncertain, or unexplored, framed to guide future research efforts:
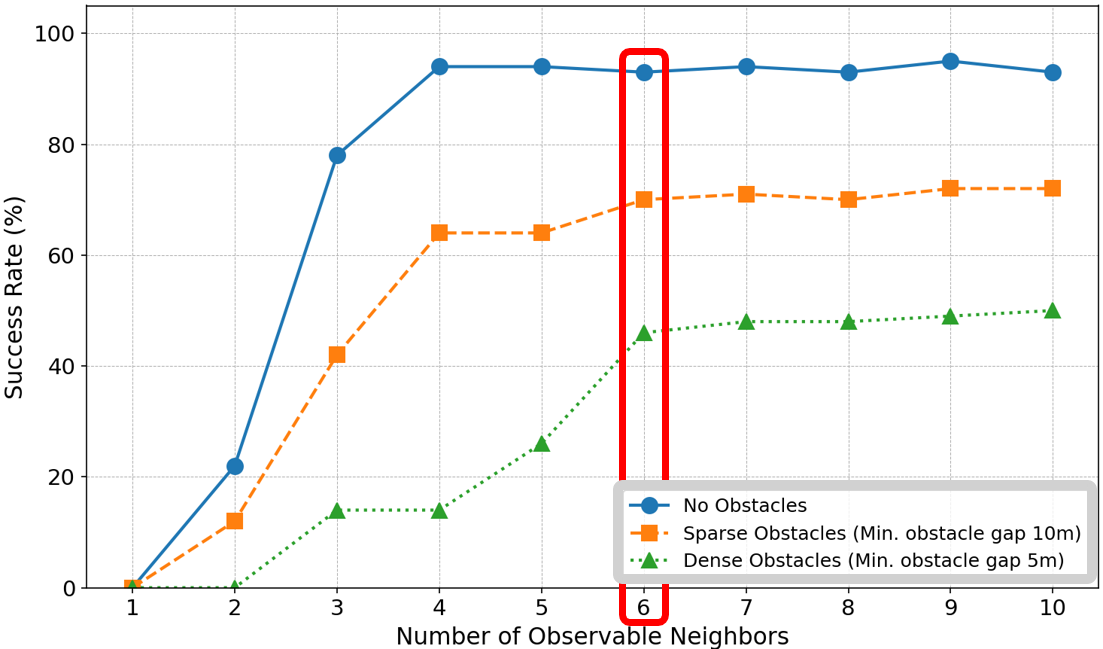
- Scalability to larger swarms: Performance, stability, and safety for swarms significantly larger than five UAVs (e.g., 10–50+) are not evaluated; the impact of the fixed “topological” neighbor cap (six) on larger densities and varying formations remains unknown.
- Variable swarm density and spacing: Sensitivity to initial spacings, inter-agent distances, and dynamic compression/expansion of the flock in tight environments is not quantified.
- Heterogeneity of agents: The approach is validated on homogeneous quadrotors; behavior with mixed dynamics, sizes, sensor suites (e.g., fixed-wing, VTOL, varying LiDAR specs) is unexplored.
- Leader failure and role dynamics: There is no mechanism for handling leader loss, failure, or temporary occlusion beyond a heuristic descent; policies for leader handover, multiple leaders, or re-election under communication denial are not addressed.
- Interaction between multiple informed agents: How the system behaves when more than one agent has goal knowledge (with potentially conflicting goals) is not studied.
- Explicit guarantees on safety and convergence: There are no formal guarantees for collision avoidance, flock cohesion, or convergence to the leader/goal under partial observability and latency; verification via control barrier certificates or reachability analysis is absent.
- Handling dynamic obstacles: The system focuses on static (pillar-like) obstacles; robustness against moving obstacles (pedestrians, vehicles, other UAVs) and rapidly changing clutter is not evaluated.
- Environmental robustness (weather and degraded sensing): LiDAR performance under rain, fog, dust, snow, or strong sunlight reflections is not studied; how degradation affects neighbor detection and control is unclear.
- Dependence on reflective tape: Neighbor detection hinges on reflective tape producing high-intensity LiDAR returns; feasibility without cooperative markers and susceptibility to false positives/decoys are open issues.
- Perception-to-control coupling in training: Simulation uses ground-truth neighbor identification with injected noise rather than end-to-end perception; the policy’s robustness to real tracking errors, misassociations, and intermittent detections requires further evaluation and training integration.
- Data association and tracking failure modes: EKF with constant-velocity and simple nearest-neighbor matching may fail in close-proximity clutter; multi-target association ambiguities and track swapping are not analyzed or mitigated.
- Limited vertical field-of-view (FOV): The recovery strategy (descent when neighbors are lost) is heuristic; optimal altitude management and 3D neighbor reacquisition under severe occlusion require systematic study.
- Use of privileged information in reward shaping: Rewards referencing leader altitude (hl) during training introduce privileged signals unavailable at run-time (followers cannot identify the leader), creating potential train–test mismatches that are not addressed.
- Exclusion of alignment from flocking: The decision to omit velocity alignment is motivated but not empirically compared; conditions where alignment aids stability or responsiveness (or harms them) remain to be characterized.
- Policy memory for POMDPs: The feedforward architecture lacks temporal memory; whether recurrent policies (e.g., LSTM/GRU) improve robustness under occlusion, latency, and intermittent observations is unexplored.
- Latency and synchronization sensitivity: The impact of varying perception and control delays on stability and safety, and the controller’s robustness to jitter, is not systematically analyzed.
- LIO drift and map-frame consistency: Followers rely on LIO but do not use global position; effects of accumulated odometry drift on neighbor tracking, obstacle representation, and long missions are unquantified.
- Rich 3D environments: Navigation in multi-level spaces (stairs, mezzanines), narrow vertical passages, and urban canyons with complex vertical geometry has not been validated.
- Wind, downwash, and aerodynamics: The influence of wind gusts, turbulence, and inter-UAV aerodynamic interactions (especially in close formations) is not studied.
- Energy and onboard compute constraints: Runtime computational load, energy consumption, and thermal limits on small UAV platforms—and their effect on mission endurance—are not measured.
- Reward sensitivity and ablations: Comprehensive ablations of reward terms, weights, observation encodings (e.g., grid resolution, neighbor count), and their effect on learned behaviors and safety are missing.
- Domain randomization and sim-to-real breadth: Details of randomization breadth (textures, obstacle types, sensor artifacts) and their quantitative impact on transfer are limited; broader randomization and systematic transfer metrics are needed.
- Baseline comparisons: The method is not compared against classical flocking (with/without alignment), potential-field heuristics, vision-based approaches, or communication-enabled distributed planners; relative performance, safety, and robustness remain unclear.
- Adversarial robustness: Vulnerabilities to LiDAR spoofing, reflective decoys, or adversarial obstacles (e.g., mirrors) are not assessed; detection hardening and anomaly identification remain open.
- Hybrid communication scenarios: How minimal or intermittent communication (e.g., sparse beacons, occasional broadcast) could be exploited to enhance robustness while remaining resilient to denial is unexplored.
- Leader planner limitations: Leader uses RRT+APF; behavior in highly dynamic or trap-rich environments (local minima, narrow doorways) and coordination with followers through tight spaces is not analyzed.
- Formation control objectives: Beyond simple cohesion/separation, higher-level formation objectives (shape, spacing, role assignment) under communication denial are not addressed.
- Multi-swarm interactions: Behavior when multiple independent swarms share space (collision avoidance, mutual occlusion, interference) is not studied.
- Safety margins near obstacles: Minimum obstacle clearance under varying speeds and clutter density is not characterized; adaptive margin control based on uncertainty is missing.
- Policy portability across sensors: The occupancy-grid encoding is tailored to a specific 360-degree LiDAR and resolution; portability to different LiDARs (scan rate, FOV, resolution) or other sensors (stereo, radar) requires investigation.
- Mission-level performance: Quantitative mission metrics (time-to-goal, path efficiency, fragmentation rate) in diverse real-world scenarios are limited; failure case taxonomy and root-cause analyses are absent.
- Regulatory and operational constraints: Practical considerations (BVLOS rules, detect-and-avoid standards, minimum separation requirements) and how the method satisfies them in real deployments are not discussed.
Practical Applications
Immediate Applications
The following applications can be deployed with modest adaptation, leveraging the paper’s validated LiDAR-based, communication-free collective navigation and sim-to-real transfer demonstrated with a five-UAV swarm.
- Collective UAV navigation in GNSS- and communication-denied disaster zones (collapsed buildings, tunnels, urban canyons)
- Sector: defense and public safety; emergency response
- What it enables: coordinated search, mapping, and victim localization when radio links are jammed/unreliable
- Potential tools/products/workflows:
- A “leader” drone with pre-loaded waypoints and RRT+APF local planner; “follower” drones running the DRL policy for cohesion/separation and obstacle avoidance
- ROS2 package integrating LiDAR-based neighbor detection (DBSCAN + EKF + intensity validation), LiDAR-inertial odometry (LIO), and follower policy inference
- Pre-mission checklist: reflective tape placement, LiDAR calibration, altitude bounds, descent-based neighbor recovery protocol
- Assumptions/Dependencies: 360-degree LiDAR per UAV; reflective tape for neighbor identification; regulatory approval for flight over people; LiDAR performance in dust/smoke; safe descent space for recovery maneuvers
- Indoor industrial inspection in RF-hostile environments (steel plants, refineries, large warehouses)
- Sector: manufacturing; logistics; energy
- What it enables: multi-UAV coordinated traversal of aisles and structures without relying on Wi-Fi/mesh networks
- Potential tools/products/workflows:
- “Comms-free swarm inspection kit” combining the perception pipeline, DRL follower policy, and an operations SOP for leader-follower missions along pre-defined routes
- Integration with PX4/MAVROS and Isaac Sim-based rehearsal (domain randomization for aisle widths, obstacle density)
- Assumptions/Dependencies: sufficient lighting not required (LiDAR is illumination-invariant), but reflective tape maintenance and LiDAR occlusion handling must be checked; clearance for safe emergency descent
- Coordinated perimeter patrol in jamming-prone environments
- Sector: security; defense
- What it enables: silent, robust patrolling and waypoint-following with minimal emissions footprint (no inter-UAV radio)
- Potential tools/products/workflows:
- Fleet deployment where the leader updates patrol waypoints; followers maintain cohesion via DRL policy using only local LiDAR data
- Command post workflow: field tests in replica environments, preset altitude windows, fallback landing if neighbors are lost for extended durations
- Assumptions/Dependencies: LiDAR-equipped UAVs; compliance with night operations rules; terrain/vegetation effects on occlusion
- Orchard and forest under-canopy inspection where GNSS and communication are unreliable
- Sector: agriculture; environmental monitoring
- What it enables: collective navigation through cluttered vegetation to scan rows/canopy segments
- Potential tools/products/workflows:
- Predefined leader paths across orchard rows; followers autonomously preserve group cohesion while avoiding trunks and branches
- Simulation-based task rehearsal (Isaac Sim + OmniDrones) with canopy density randomization
- Assumptions/Dependencies: LiDAR signal quality through foliage; tape visibility in outdoor conditions; safe altitude bands for tree row traversal
- Subterranean inspection in tunnels, mines, and utility conduits
- Sector: construction; mining; energy infrastructure
- What it enables: GNSS-free, comms-free collective navigation in narrow, cluttered spaces for mapping and hazard identification
- Potential tools/products/workflows:
- Leader with pre-loaded map segments; followers infer local occupancy and maintain separation/cohesion
- Safety workflow: geofenced altitude and velocity limits, emergency descent and landing triggers
- Assumptions/Dependencies: LiDAR robustness in dust; reflective marker visibility; power constraints in extended missions
- Educational and research testbeds for communication-free multi-robot coordination
- Sector: academia; education; software
- What it enables: hands-on courses and labs in emergent behaviors, DRL under partial observability, and sim-to-real transfer
- Potential tools/products/workflows:
- Curriculum modules and assignments using Isaac Sim + OmniDrones
- Reusable ROS2 nodes for perception (clustering/validation) and policy inference; ablation tools for reward shaping and neighbor caps
- Assumptions/Dependencies: access to 360-degree LiDARs; indoor flight cages; safety protocols
- Packaged software components for robotics stacks
- Sector: software; robotics
- What it enables: drop-in ROS2 packages for LiDAR-based neighbor tracking (DBSCAN + EKF), occupancy grid generation, and follower DRL policy
- Potential tools/products/workflows:
- “Perception stack” and “Follower policy” nodes; PX4/MAVROS integration; lightweight monitoring UI showing perceived neighbors and occupancy
- Assumptions/Dependencies: sensor drivers compatible with ROS2; onboard compute budget for real-time clustering/inference; policy tuning to platform dynamics
- Facility surveying for nuclear or sensitive sites with radio restrictions
- Sector: energy; government
- What it enables: multi-UAV navigation for radiation mapping or structural inspection without RF emissions between drones
- Potential tools/products/workflows:
- Mission planning with strict altitude and proximity constraints; leader path set by radiation-safe corridors; followers maintain safe spacing via learned policy
- Assumptions/Dependencies: site-specific safety approvals; LiDAR operation near metallic surfaces; radiation-hardened hardware where necessary
- Live-event rigging and indoor stage inspections
- Sector: entertainment; construction
- What it enables: coordinated inspection of truss and lighting rigs without relying on venue networking
- Potential tools/products/workflows:
- Preplanned leader routes; micro-UAV followers for redundant coverage and obstacle avoidance using occupancy grids
- Assumptions/Dependencies: venue flight permissions; indoor LiDAR calibration; careful descent logic around stage equipment
- Hybrid training and deployment pipeline for enterprises
- Sector: software; robotics; consulting
- What it enables: enterprise workflows to train/fine-tune the DRL follower policy for specific facilities, then deploy on compatible UAVs
- Potential tools/products/workflows:
- “Sim-to-field” service package: environment modeling in Isaac Sim, domain randomization scripts, reward tuning templates, transfer evaluation checklists
- Assumptions/Dependencies: representative digital twins; access to training compute; version-controlled policy management
Long-Term Applications
These applications require further research, scaling, productization, or regulatory progress to become broadly feasible.
- Scaling to large swarms (dozens to hundreds) with robust occlusion handling and minimal sensing artifacts
- Sector: defense; logistics; environmental monitoring
- What it enables: high-coverage operations with minimal coordination overhead
- Dependencies: improved neighbor sensing without reflective tape (e.g., learned LiDAR signature models), solid-state LiDARs for reduced weight/power, advanced data association under dense occlusions, policy stability for larger N
- Heterogeneous, communication-free multi-robot swarms (UAV + UGV + UUV/USV)
- Sector: defense; construction; environmental monitoring
- What it enables: cross-domain teams that coordinate via local perception only (e.g., UAVs guiding UGVs in complex terrains)
- Dependencies: domain-adaptive policies per platform, unified perception abstractions, safety certifications across domains
- Role switching and distributed leadership without communication
- Sector: robotics; defense; autonomy research
- What it enables: implicit leader transfer when the current leader fails or is blocked, using emergent cues from local motion
- Dependencies: reward structures and training regimes for dynamic role emergence; formal safety guarantees
- Hybrid comms-aware policies that gracefully degrade to comms-free control
- Sector: software; robotics; public safety
- What it enables: use short bursts of communication (when available) to improve performance while maintaining resilience when communication fails
- Dependencies: multi-modal policy architectures, robust integration of limited broadcast signals without overfitting, policy evaluation under intermittent link conditions
- Precision tasks in healthcare logistics (e.g., multi-drone medical supply delivery in disaster triage areas)
- Sector: healthcare; public safety
- What it enables: coordinated micro-logistics in jamming-prone or infrastructure-damaged zones
- Dependencies: regulatory approvals, reliable landing/delivery mechanisms, safety and redundancy, human-in-the-loop oversight tools
- Consumer-grade multi-drone group flight in urban settings without mesh networks
- Sector: consumer electronics; recreational drones
- What it enables: safe hobbyist group flight where RF interference is high
- Dependencies: lightweight, low-cost LiDAR or alternative omnidirectional sensing; geofencing and remote ID compliance; simplified UX for leader selection and mission setup
- Interior inspection in high-risk environments (e.g., offshore platforms, large ships, enclosed industrial complexes)
- Sector: energy; maritime; manufacturing
- What it enables: coordinated, robust coverage under metallic clutter and variable lighting
- Dependencies: corrosion- and weather-resistant sensor packages, docking/recharging workflows, formal hazard analyses
- Formal verification and certification of DRL-based swarm policies
- Sector: policy; standards; aerospace certification
- What it enables: compliance pathways for deploying learning-based systems in safety-critical missions
- Dependencies: verifiable reward specifications, runtime monitors, explainability tooling, standardized test suites for partial observability and occlusion
- Generalized perception beyond reflective tape (markerless neighbor identification)
- Sector: robotics; autonomy
- What it enables: plug-and-play operation across diverse UAV fleets without physical modifications
- Dependencies: robust LiDAR-based object recognition and tracking of UAV geometries, multi-sensor fusion (e.g., acoustic, radar) to mitigate LiDAR failure modes
- Integrated productization: “Comms-Free Swarm Navigation Kit”
- Sector: robotics; software; systems integration
- What it enables: end-to-end solution with hardware (lightweight LiDARs), perception software, DRL policies, and mission planning tools
- Dependencies: hardware miniaturization and cost reduction, cross-platform autopilot support, user-facing mission UI, maintenance and support ecosystems
- City-scale subterranean and indoor logistics (e.g., coordinated micro-warehouse operations, delivery tunnels)
- Sector: logistics; smart cities
- What it enables: resilient autonomous transport in built environments without GPS or constant networking
- Dependencies: infrastructure access and safety regulation, large-swarm policy stability, integration with human workflows and emergency protocols
- Benchmarking suites and open standards for communication-free multi-robot navigation
- Sector: academia; standards; software
- What it enables: reproducible comparisons and interoperable modules across platforms and labs
- Dependencies: curated datasets (real/sim), shared environments with varied occlusions/FOV constraints, consensus metrics for cohesion, safety, and mission progress
Notes common to multiple applications:
- Assumptions: each UAV carries a 360-degree LiDAR and sufficient compute for clustering, EKF tracking, occupancy grid generation, and DRL inference; followers rely on local observations only; leader path planning (RRT+APF) must be robust to local minima in complex spaces.
- Environmental dependencies: LiDAR degradation in particulates (dust/smoke), occlusions in narrow corridors, and limited vertical FOV necessitate careful altitude bands and recovery strategies.
- Regulatory and safety: flight permissions, geofencing, runtime failsafes (emergency descent/landing), and human oversight are critical for real deployments.
- Adaptation: policies may need fine-tuning per platform/sensor and per environment using the provided Isaac Sim pipeline with domain randomization.
Glossary
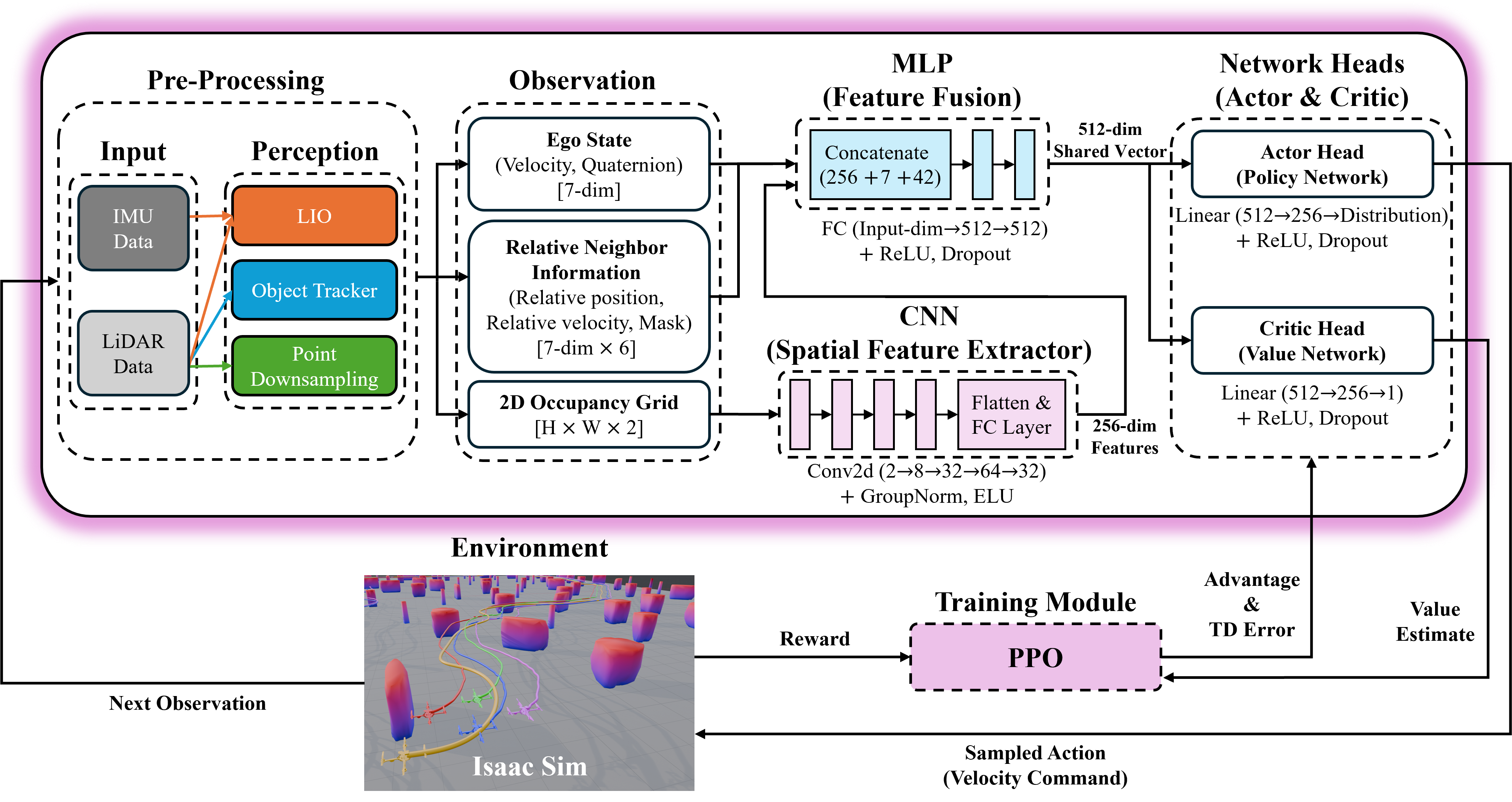
- Actor-critic network: A reinforcement learning architecture with separate policy (actor) and value (critic) components trained jointly. Example: "Our control policy is implemented as an actor-critic network, illustrated in Fig.~\ref{fig:drl}."
- Adam optimizer: A stochastic gradient-based optimization method combining momentum and adaptive learning rates. Example: "using the Adam optimizer with learning rates of for the encoder, actor, and critic."
- Alpha-lattice structures: Specific spatial formations for multi-agent coordination derived from potential functions. Example: "introducing collective potential functions and -lattice structures for multi-agent coordination."
- Artificial potential field (APF): A control method that uses attractive and repulsive artificial forces to guide motion and avoid obstacles. Example: "the artificial potential field (APF)~\cite{khatib1986real} for real-time navigation."
- Clipped surrogate objective: The PPO loss term that limits policy updates to ensure stable learning. Example: "The primary component is the clipped surrogate objective:"
- Convolutional neural network (CNN): A neural network specialized for processing grid-like data such as images or occupancy maps via convolutional filters. Example: "The two-channel LiDAR occupancy grid is processed by a convolutional neural network (CNN)."
- Data association: The process of matching observed clusters to existing tracks in tracking systems. Example: "Data association matches each valid cluster to the nearest existing track if their distance is below threshold $d_{\text{match}$."
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise): A clustering algorithm that groups points based on density, robust to noise and varying cluster shapes. Example: "grouped into individual clusters using the density-based spatial clustering of applications with noise (DBSCAN) algorithm~\cite{ester1996density}."
- Deep reinforcement learning (DRL): A method combining deep neural networks with reinforcement learning to learn complex policies from interaction. Example: "This paper presents a deep reinforcement learning (DRL) based controller for collective navigation of unmanned aerial vehicle (UAV) swarms in communication-denied environments"
- Entropy bonus: An additional term in the RL objective encouraging policy exploration by maximizing action distribution entropy. Example: "Finally, an entropy bonus encourages exploration"
- Extended Kalman filter (EKF): A state estimation algorithm for nonlinear systems that linearizes about the current estimate. Example: "Each cluster is tracked using the extended Kalman filter (EKF)~\cite{kalman1960new} with a constant velocity model"
- GAE (Generalized Advantage Estimation): A variance-reduced estimator of the advantage function using exponentially weighted TD errors. Example: "We apply generalized advantage estimation (GAE)~\cite{schulman2015high}"
- Gaussian policy: A stochastic continuous-action policy parameterized by the mean and standard deviation of a Gaussian distribution. Example: "The actor head is an MLP with a hidden layer of 256 units that outputs the mean and standard deviation for a continuous Gaussian policy."
- GNSS-denied environments: Scenarios where satellite-based navigation (e.g., GPS) is unavailable or unreliable. Example: "robust operation in GNSS-denied and communication-denied environments."
- LiDAR-inertial odometry (LIO): A state estimation method fusing LiDAR and inertial measurements to estimate motion without external localization. Example: "the UAV 's state is estimated by LiDAR-inertial odometry (LIO)."
- LiDAR occupancy grid: A discretized spatial map encoding obstacle proximity and occupancy derived from LiDAR measurements. Example: "a two-channel occupancy grid derived from LiDAR data"
- LiDAR point clustering: Grouping LiDAR points into clusters representing objects or agents. Example: "utilizes LiDAR point clustering and an extended Kalman filter for stable neighbor tracking"
- Nvidia Isaac Sim: A GPU-accelerated robotics simulation platform for training and testing autonomous systems. Example: "trained in GPU-accelerated Nvidia Isaac Sim"
- Nonlinear model predictive control (NMPC): An optimization-based control method that plans control actions over a horizon considering nonlinear dynamics. Example: "nonlinear model predictive control~\cite{soria2021predictive}"
- OmniDrones: A simulation framework built on Isaac Sim for scalable, parallelized UAV environments. Example: "using the OmniDrones~\cite{xu2024omnidrones} framework for GPU-accelerated parallel simulations."
- On-policy algorithm: A reinforcement learning approach that updates the policy using data collected from the current policy. Example: "As an on-policy algorithm, PPO enables synchronous data collection from multiple UAVs and efficient batch updates in GPU-accelerated parallel environments."
- POMDP (Partially Observable Markov Decision Process): A formal model for decision-making under uncertainty where the agent has incomplete state information. Example: "We model the follower's control problem as a partially observable Markov decision process (POMDP)"
- Polyhedral representation: A geometric representation of space or constraints using polyhedra, often used in planning. Example: "MADER~\cite{tordesillas2021mader} segments trajectory planning into perception, polyhedral representation, and optimization"
- PPO (Proximal Policy Optimization): A stable policy gradient algorithm that constrains updates via a clipped objective. Example: "trained via DRL using proximal policy optimization (PPO)~\cite{schulman2017proximal}"
- RRT (Rapidly-Exploring Random Tree): A sampling-based motion planning algorithm for quickly exploring high-dimensional spaces. Example: "the rapidly-exploring random tree (RRT)~\cite{lavalle1998rapidly}"
- Sim-to-real transfer: The ability of policies learned in simulation to perform effectively on real-world systems. Example: "The robustness and sim-to-real transfer of our approach are confirmed through extensive simulations and challenging real-world experiments"
- Spatial-temporal optimization framework: An approach that jointly optimizes over space and time for multi-agent trajectory planning. Example: "Zhou et al.~\cite{zhou2022swarm} introduce a spatial-temporal optimization framework for fully autonomous UAV swarms"
- TD error (Temporal Difference error): The one-step bootstrapped error used to compute advantages and value updates in RL. Example: "based on the temporal difference (TD) error, :"
- Topological approach: A neighbor-selection strategy based on a fixed number of nearest agents rather than metric distance. Example: "The use of a fixed number of observable neighbors is a topological approach inspired by robust collective behaviors in animal swarms"
- VPF (Visual Projection Field): A bio-inspired method that projects visual cues to enable collective motion and collision avoidance. Example: "implemented a bio-inspired visual projection field (VPF) approach with six UAVs in controlled indoor environments."
- Zero-shot transfer: Deploying learned policies to new real-world scenarios without additional fine-tuning. Example: "enabling zero-shot transfer to real robots in obstacle-dense environments"
Collections
Sign up for free to add this paper to one or more collections.