- The paper presents PCBM-ReD, which extracts and filters visual concepts via sparse autoencoders to achieve high-fidelity interpretations with minimal accuracy loss.
- It leverages multimodal LLMs for semantic labeling and reconstruction-guided selection, ensuring concept independence and causal interpretability.
- Empirical results across 11 benchmarks demonstrate near end-to-end performance and robust zero/few-shot generalization across diverse visual tasks.
Post-hoc Concept Bottleneck Models via Sparse Decomposition of Visual Representations
Introduction
The paper "Concepts from Representations: Post-hoc Concept Bottleneck Models via Sparse Decomposition of Visual Representations" (2601.12303) presents PCBM-ReD, a framework that integrates concept-based interpretability with the representational capacity of state-of-the-art pretrained vision encoders. By extracting, filtering, and selecting visual concepts directly from large-scale model representations, and mapping these to human-understandable descriptors via multimodal LLMs, PCBM-ReD establishes a route to interpretable, high-fidelity image classification that retains strong prediction accuracy on a diverse set of challenging tasks.
Pipeline Overview and Technical Framework
PCBM-ReD is structured in four major steps: concept mining, semantic labeling and selection, sparse decomposition, and predictive modeling within the bottleneck abstraction.
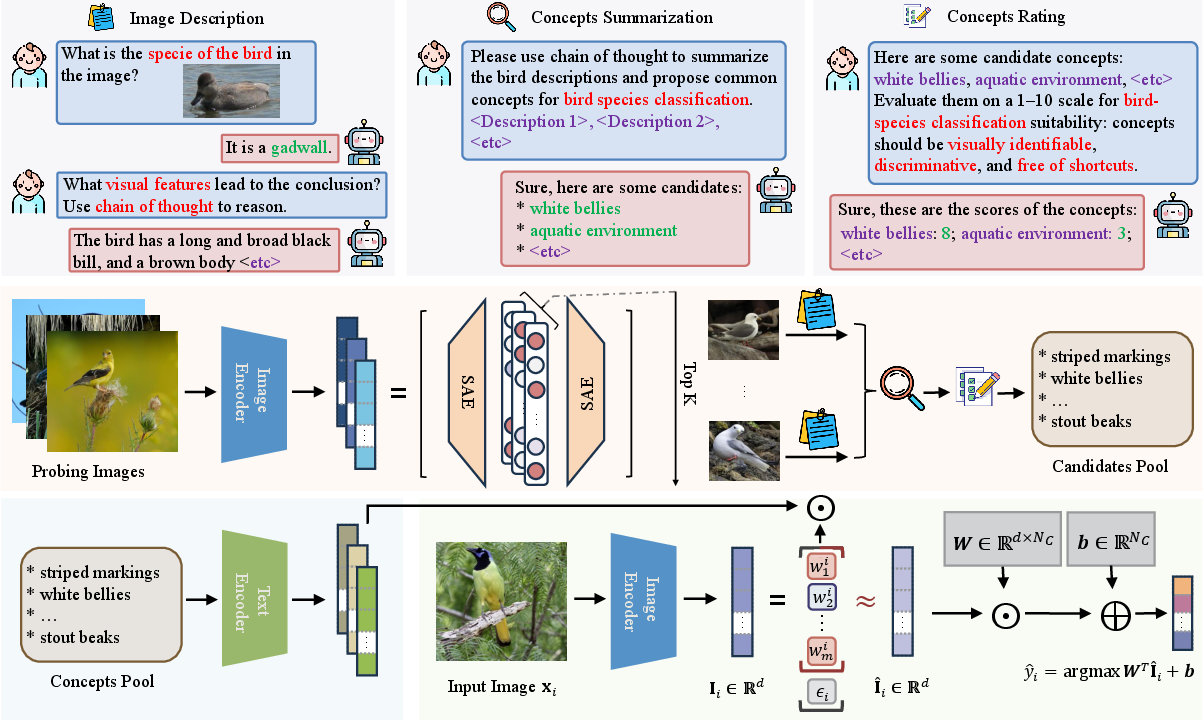
Figure 1: Overview of PCBM-ReD: concept extraction from image representations, ranking with MLLMs, selection for a bottleneck via reconstruction, sparse decomposition, and linear target prediction.
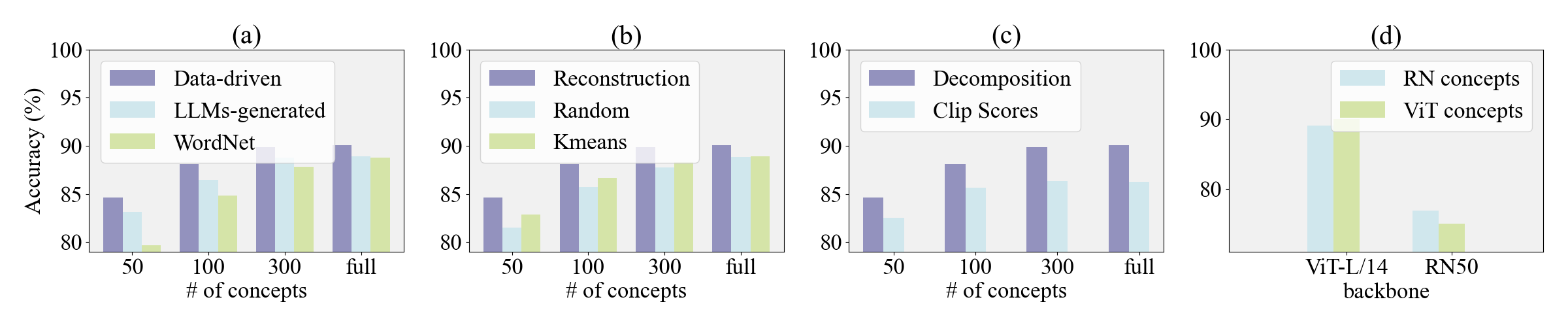
- Concept Extraction: Visual embeddings from a pretrained image encoder (e.g., CLIP) are factorized using a sparse autoencoder (SAE), yielding a bank of disentangled, interpretable basis vectors (“concepts”). This data-driven approach, in contrast to previous hand-crafted or purely LLM-generated concepts, aligns the bottleneck with the intrinsic factors of variation captured by the model.
- Semantic Labeling and Scoring: For each concept vector, top-activated images are retrieved; MLLMs (Llama-3.2-11B-Vision-Instruct, DeepSeek-V3) are prompted to generate detailed per-image descriptions, which are then summarized and filtered by LLMs for visual discriminativeness, identifiability, and lack of shortcut features. Only concepts with high semantic quality are retained.
- Reconstruction-guided Concept Selection: From the filtered set, a greedy unsupervised algorithm selects concepts that minimize reconstruction error of image representations under a constrained linear span, guaranteeing near-complete coverage of the latent space while enforcing independence and avoiding redundancy.
- Sparse Decomposition and Predictive Modeling: For each image, its embedding is decomposed into a sparse linear combination of the selected concepts (via OMP or similar algorithms). The resulting concept activations serve as direct CBM bottleneck inputs for a learned linear classifier. Label prediction thus flows transparently from concept activations, supporting causal interpretability and faithful explanation.
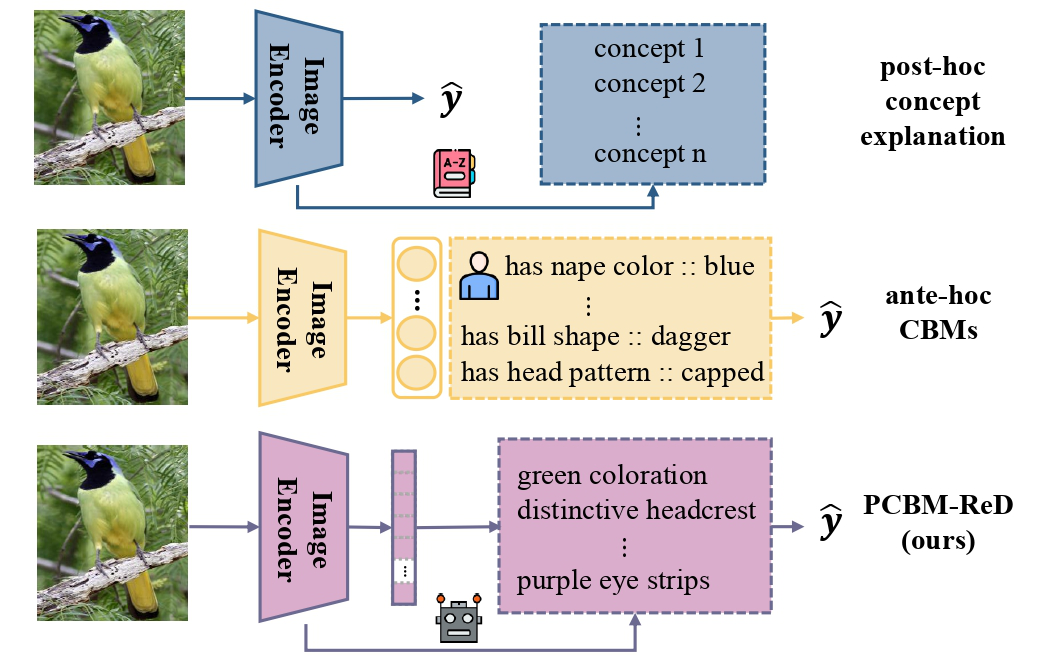
Figure 2: PCBM-ReD utilizes concepts extracted from the encoder to reconstruct the visual space, connecting interpretability with the model’s original expressiveness.
This decomposition is made possible—and remains high-fidelity—thanks to the semantic alignment in vision-LLMs like CLIP, where language and vision spaces are structurally compatible.
Empirical Results and Analytical Findings
The evaluation of PCBM-ReD spans 11 benchmarks covering generic, fine-grained, texture, action, medical, and satellite imagery. The experimental protocol includes fully-supervised, zero-shot, and few-shot setups, with comparisons against both linear probes (end-to-end models) and recent CBM variants (LaBo, Res-CBM, V2C-CBM, etc.).
Key results include:
- Accuracy: The mean test accuracy gap between PCBM-ReD and a supervised linear probe is only 0.41%, and PCBM-ReD outperforms leading language-guided CBM baselines by significant margins (1.25% over LaBo; 5.57% over label-free CBMs). Performance saturates with approximately 300 concepts, but even 50 concepts yield acceptable results, highlighting efficiency.
- Zero/Few-Shot Generalization: The sparse reconstruction means zero-shot performance closely tracks that of the underlying CLIP backbone, preserving generalization even with limited labels. PCBM-ReD consistently outperforms prior CBMs in the few-shot regime (e.g., a 5.01% improvement over LaBo).
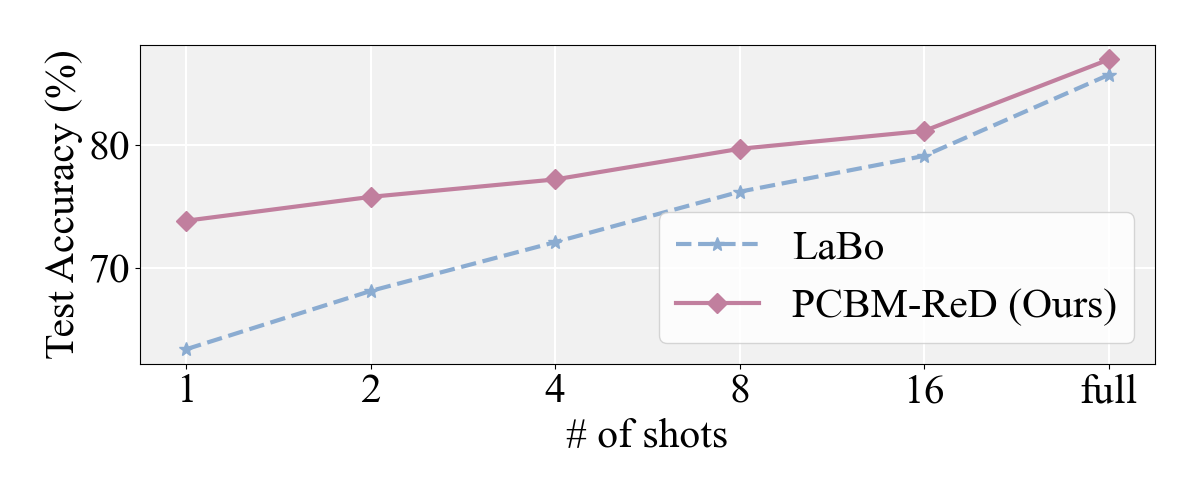
Figure 3: Few-shot accuracy across 11 datasets shows superior average generalization for PCBM-ReD compared to baselines.
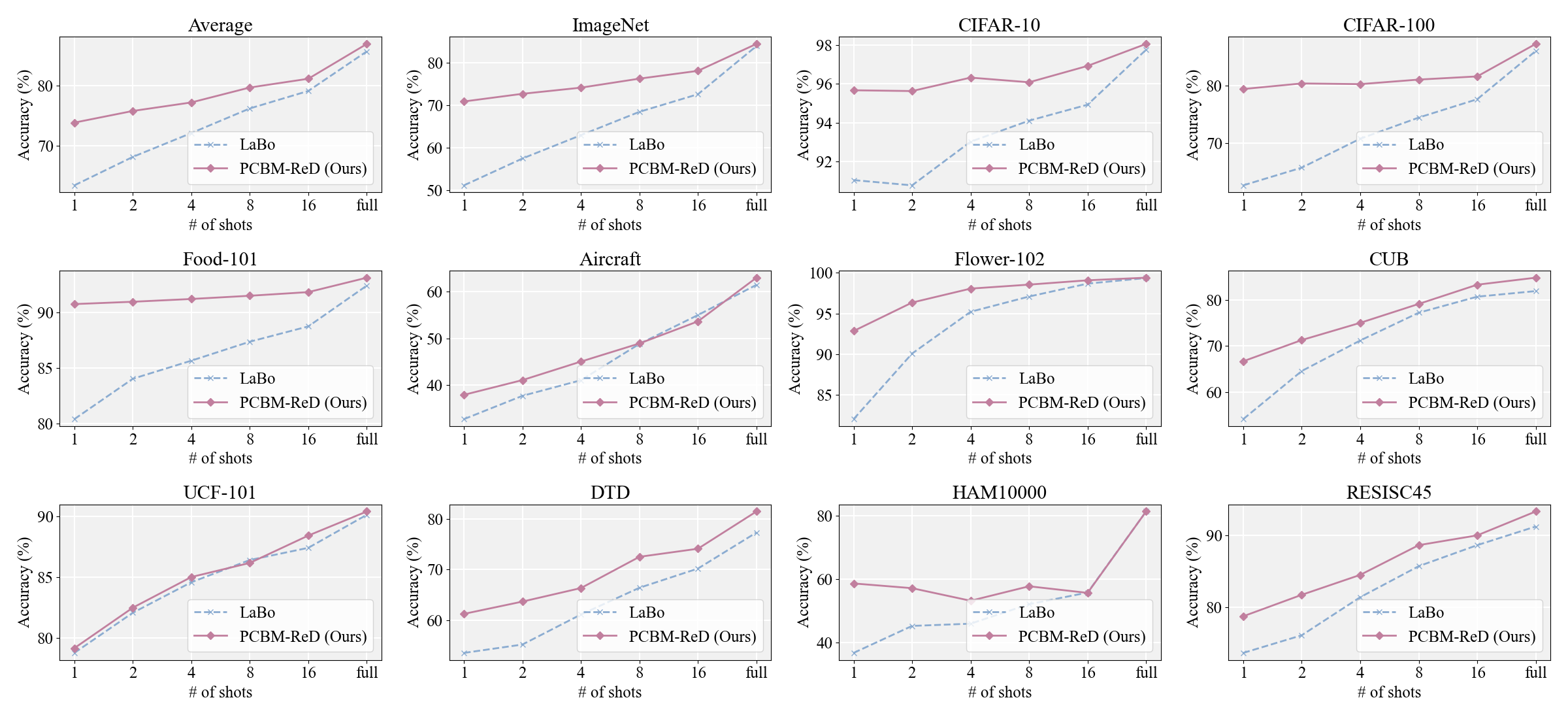
Figure 4: Detailed comparison with LaBo in few-shot learning; PCBM-ReD maintains a consistent lead as labeled data increases.
- Interpretability and Explanation Quality: Visual and human studies were conducted to assess whether top concepts (those with highest causal contribution to predictions) are human-identifiable and genuinely explanatory.

Figure 5: Example explanations with top concepts that drive image classifications; concepts are visually grounded and task-specific.
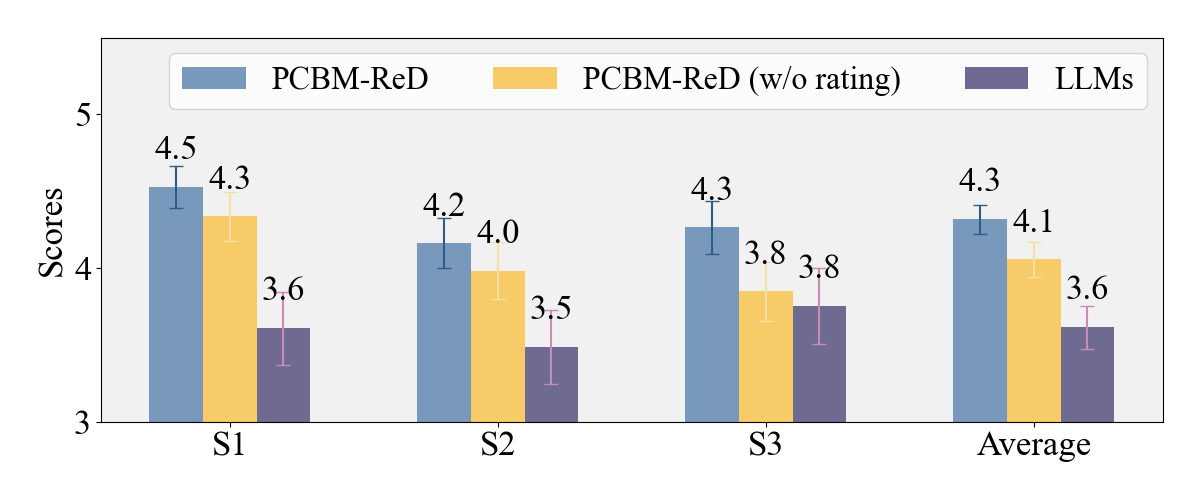
Figure 6: Human evaluation scores show that PCBM-ReD’s explanations are judged highly for visual identifiability, descriptive fidelity, and causal link to predictions.
Interpretability is further enhanced by discarding non-causal or non-visual features as determined by LLM scoring.
Methodological Innovations and Theoretical Implications
PCBM-ReD’s core technical advances include:
- Alignment of Concept Set with Data Distribution and Encoder Capacity: Unlike prior CBMs, whose concepts are fixed externally, PCBM-ReD discovers and ranks concepts inherently present in the foundation model’s representation. This results in semantically meaningful and discriminative factors that match the backbone’s learned invariances and biases.
- Sparsity and Independence in Explanatory Factors: Both the SAE and the greedy selection provide independence across chosen concepts, facilitating possible CBM interventions and avoiding the representational redundancy that undermines causal interpretation.
- Model Faithfulness and Completeness: By reducing the projection residual, the predictive performance of the interpretably-constrained model remains strongly faithful to the pretrained encoder—challenging the notion that interpretability and performance are inherently at odds in post-hoc settings.
- MLLM-driven Semantic Validation: By using MLLMs and LLMs in a loop for labeling, scoring, and filtering, the pipeline ensures that concepts are visually meaningful and exclude non-perceptual shortcuts, a frequent failure mode in both manual curation and text-only LLM concept bottlenecks.
Practical Implications and Future Directions
PCBM-ReD provides a practical path towards interpretable deployment of foundation vision models in sensitive, high-stakes settings (medical imaging, autonomous systems, scientific analysis). The pipeline is domain-agnostic provided the foundation model and the MLLM/LLM components are sufficiently expressive about the task-specific visual modalities.
Extensions of this method could involve:
- Domain-Adapted LLMs/MLLMs: For medical or technical imagery, specialized LLMs could further refine the labeling and filtering stages, freeing PCBM-ReD from errors due to inadequate descriptive power in generalist LLMs.
- Non-CLIP Backbones: While the method leverages joint alignment in CLIP, similar decompositional strategies could be ported to architectures supporting concept activation vectors or other forms of latent disentanglement.
- Causal Interventions and Editing: The independence and faithfulness of concept mappings open avenues for direct intervention on predictions, debugging, and even ethical audits at concept granularity.
- Global and Local Attribution: The framework is compatible with both per-sample (local) and dataset-level (global) concept importance analyses.
Conclusion
PCBM-ReD advances concept-based interpretability for vision models by employing sparse decomposition, reconstruction-based concept selection, and LLM-guided semantic validation. It achieves classification accuracy on par with end-to-end models, robust zero/few-shot generalization, and highly rated interpretability, setting a new standard for post-hoc CBM construction. The approach effectively bridges the gap between the opaque, distributed features of foundation models and the structured, human-centered abstractions required for trustworthy AI deployment.