Alterbute: Editing Intrinsic Attributes of Objects in Images
Abstract: We introduce Alterbute, a diffusion-based method for editing an object's intrinsic attributes in an image. We allow changing color, texture, material, and even the shape of an object, while preserving its perceived identity and scene context. Existing approaches either rely on unsupervised priors that often fail to preserve identity or use overly restrictive supervision that prevents meaningful intrinsic variations. Our method relies on: (i) a relaxed training objective that allows the model to change both intrinsic and extrinsic attributes conditioned on an identity reference image, a textual prompt describing the target intrinsic attributes, and a background image and object mask defining the extrinsic context. At inference, we restrict extrinsic changes by reusing the original background and object mask, thereby ensuring that only the desired intrinsic attributes are altered; (ii) Visual Named Entities (VNEs) - fine-grained visual identity categories (e.g., ''Porsche 911 Carrera'') that group objects sharing identity-defining features while allowing variation in intrinsic attributes. We use a vision-LLM to automatically extract VNE labels and intrinsic attribute descriptions from a large public image dataset, enabling scalable, identity-preserving supervision. Alterbute outperforms existing methods on identity-preserving object intrinsic attribute editing.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Alterbute, a computer program that can change how an object looks inside a photo—its color, texture, material, or shape—without changing what the object is (its identity) or the scene around it. For example, it can turn a blue Porsche into a red Porsche while keeping it clearly the same model and leaving the street background untouched.
What questions does it try to answer?
The paper tackles two big questions:
- How can we edit the “intrinsic” parts of an object (like color and material) in a photo while keeping the object’s identity the same?
- How do we define an object’s identity so edits feel natural to people (not too strict, not too loose)?
To answer these, the authors propose a middle-ground way to define identity and a training method that makes learning this kind of editing possible at scale.
Key ideas in simple terms
Before explaining the method, here are two core ideas:
- Intrinsic vs. extrinsic attributes:
- Intrinsic: built-in parts of the object (color, texture, material, shape).
- Extrinsic: outside conditions (camera angle, lighting, background).
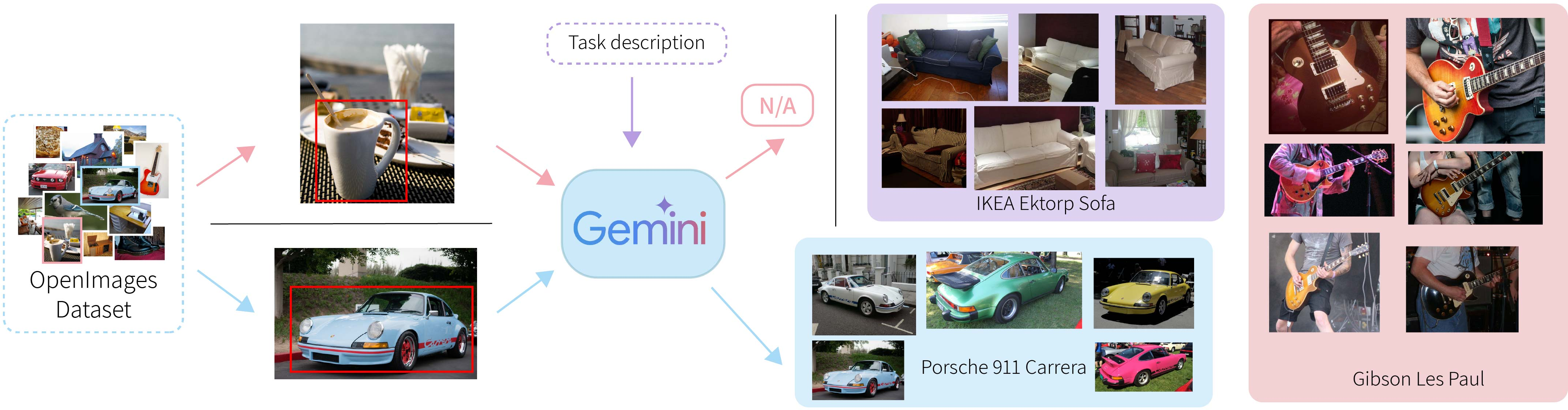
- Visual Named Entities (VNEs): Instead of saying “car” (too broad) or “this exact car in this photo” (too strict), VNEs use specific names like “Porsche 911 Carrera” or “iPhone 16 Pro.” This groups similar objects that share identity-defining features, while still allowing changes like color or material.
How does Alterbute work?
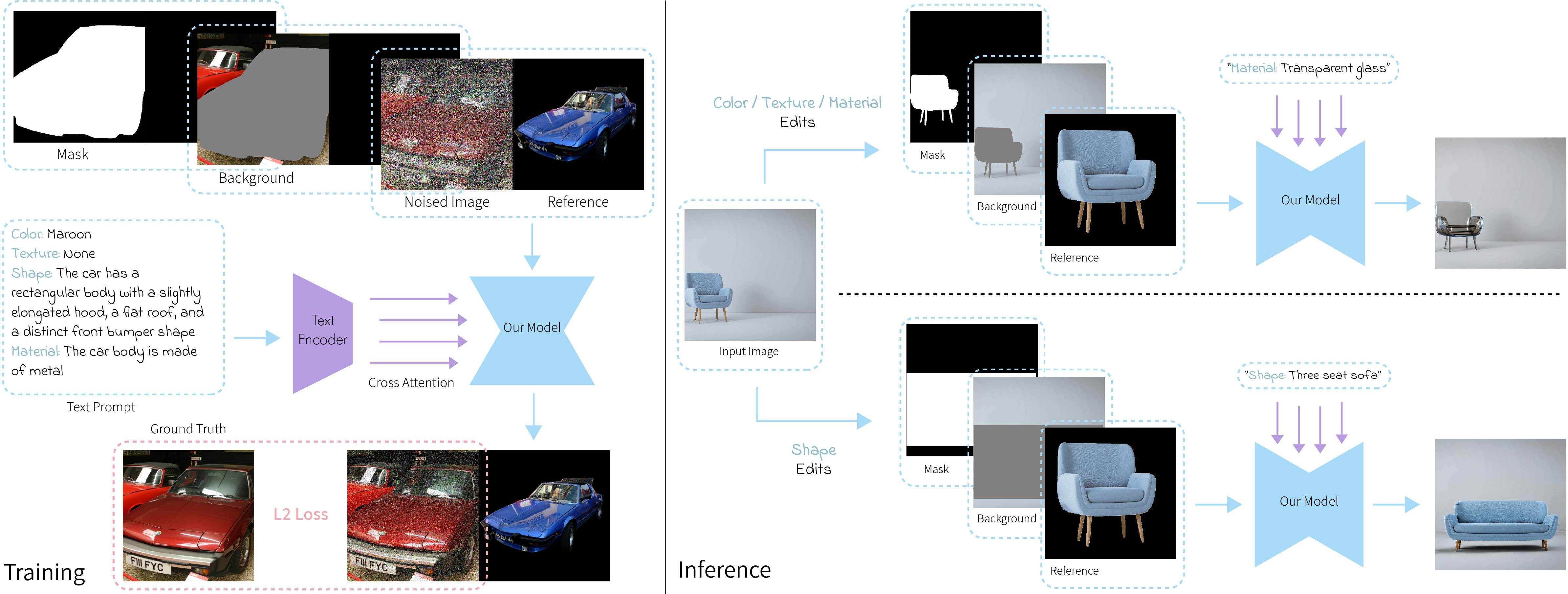
Alterbute is built on a type of AI called a diffusion model. Think of diffusion as starting with a very noisy, grainy image and step-by-step removing the noise until a clear image appears. By guiding this process with text and example images, the model learns to produce specific edits.
Training (practice time)
The authors do something clever to make training realistic and scalable:
- Instead of forcing the model to only change intrinsic attributes during training (which is hard to find data for), they let it learn from examples that may include both intrinsic and extrinsic changes. These are easier to collect.
- The model is given three inputs together: 1) An identity reference image: a cutout of the same type of object (from the same VNE cluster), so the model learns what “stays the same.” 2) A text prompt: a simple description of the target intrinsic attributes (like “color: red” or “material: wood”). 3) A background image plus an object mask: the scene where the object should appear and a map of where the object goes (the mask is like an outline or a box that marks the object’s location).
To make the model learn how to keep identity information, they place the noisy target image on the left and the clean reference object on the right in a two-panel grid. The model learns to “borrow” identity cues from the right while shaping the left into the edited result.
They also automatically build huge training sets using a vision-LLM (Gemini). It looks at a large public image dataset (OpenImages), finds objects that share a VNE (like many images of “Porsche 911 Carrera”), and writes simple attribute descriptions (color, texture, material, shape) to use as text prompts. This avoids manual labeling and scales to many identities.
Inference (use time)
At use time, the goal is to change only intrinsic attributes and keep everything else unchanged:
- They reuse the original photo’s background and the object’s mask (its outline).
- They crop the object to form the identity reference.
- They feed in a short text prompt for the specific attribute to change (like “texture: knitted”).
- The model then edits just that attribute, keeping identity and the scene intact.
For shape edits (where the exact new outline isn’t known), they use a coarse rectangular box instead of a precise shape mask, which gives the model room to adjust the object’s geometry.
What did they find?
The authors report that Alterbute:
- Can edit color, texture, material, and shape using a single model.
- Preserves the object’s identity and the original scene better than other methods.
- Outperforms several general-purpose editors (like InstructPix2Pix and Diptych) and specialized editors (for texture or material only) in side-by-side comparisons.
- In user studies, people preferred Alterbute’s results most of the time (often around 80–90% of comparisons).
- AI judges (large models like Gemini, GPT-4o, and Claude) also preferred Alterbute, aligning with human judgments.
Why this matters: Most existing tools either don’t keep identity well (they change too much) or they keep identity too strictly (they won’t let you change intrinsic attributes at all). Alterbute finds the balance.
Why does it matter?
This research shows a practical way to make realistic, identity-preserving edits to objects in photos. That’s useful for:
- Product photos: Try different colors or materials without new photo shoots.
- Design and marketing: Explore variations quickly while staying on-brand.
- Movies and games: Adjust props or assets while keeping their recognizable look.
- AR/VR and e-commerce: Let customers preview options (like furniture materials) in their own spaces without changing the room.
By defining identity with VNEs and by training with a relaxed objective, Alterbute enables flexible, high-quality edits that feel natural.
Limitations and future directions
- Background artifacts: Using rough bounding boxes (instead of perfect outlines) can sometimes introduce small background errors inside the masked area.
- Shape edits of rigid objects: Changing the geometry of hard, structured things (like certain cars or furniture) is still tricky and can look unrealistic.
- Conflicting attributes: Some attribute combinations don’t make sense (e.g., “material: gold” plus “color: matte black”). The model usually avoids contradictions learned from data, but it isn’t perfect.
- Multi-attribute edits: It can change multiple attributes at once if they make sense together, but complex or conflicting requests may be challenging.
Overall, Alterbute is a strong step toward practical, identity-preserving image editing, and future work could improve shape realism, background handling, and multi-attribute control.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed so future researchers can act on it.
- Identity metric and evaluation: No objective, quantitative metric is provided to measure identity preservation under VNE definitions; define and validate metrics that correlate with human perception across color/texture/material/shape edits.
- Extrinsic fidelity measurement: Background and lighting preservation are asserted qualitatively; develop automated measures for extrinsic consistency (e.g., background similarity, illumination invariance) and quantify leakage rates.
- Training–inference mismatch: The model is trained to edit both intrinsic and extrinsic attributes but constrained at inference; assess and mitigate distribution shift and its effect on identity/extrinsic fidelity.
- VNE label quality and bias: The Gemini-driven VNE labeling pipeline lacks reported accuracy, purity, and bias analyses; quantify cluster purity, mislabeling rates, long-tail coverage, and brand/category biases, and evaluate their impact on edits.
- Coverage of generic/unnameable objects: Objects without clear VNEs are filtered out; investigate methods to extend identity conditioning to generic or unnameable items while preserving perceived identity.
- Prompt parsing and disentanglement: The paper does not quantify whether edits remain confined to the specified attribute; develop disentanglement tests and metrics to detect unintended changes in non-target attributes.
- Multi-attribute edits and contradictions: Handling conflicting attribute prompts (e.g., “material: gold” + “color: black”) is not formalized; design constraint-aware prompt parsing and consistency enforcement mechanisms.
- Shape editing boundaries: The conditions under which shape edits preserve identity are not defined; characterize permissible geometric variations per VNE and build mechanisms to prevent identity-violating shapes.
- Physical plausibility: Material and shape edits can violate real-world reflectance and geometry; integrate physically based priors (e.g., BRDF constraints, 3D geometry priors) and evaluate realism quantitatively.
- Mask dependency and segmentation errors: Performance and failure rates under imperfect masks (thin structures, occlusions, clutter) are not studied; quantify robustness to mask noise and explore mask-free or self-refining strategies.
- Bounding-box artifacts: Box masks cause background inconsistencies; evaluate object removal/inpainting integration and devise post-processing or joint background reconstruction to reduce artifacts.
- Multi-object scenes: The method targets single-object edits; study identity-preserving edits in multi-object settings with overlapping masks, interactions, and contextual constraints.
- Occlusions and complex geometry: Editing partially occluded or articulated objects is not addressed; benchmark and improve handling of occlusion, self-shadowing, and fine geometry details.
- Domain generalization: Training relies on OpenImages; assess generalization to diverse domains (e.g., product photos, indoor scenes, wild internet images) and propose domain adaptation strategies.
- Scale and long-tail identities: Heavy-tailed VNE distributions may bias the model toward frequent classes; design sampling/curriculum strategies to improve performance on rare identities and report class-wise results.
- Compute and reproducibility: Training requires substantial TPU resources and uses closed-source VLM labeling; provide resource-efficient variants, open-source labeling alternatives, and release code/data to improve reproducibility.
- Attribute intensity control: Fine-grained control (e.g., glossiness level, texture scale, subtle hue shifts) is not exposed; build parameterizable controls for continuous attribute strengths and evaluate precision.
- User guidance and edit predictability: The degree of change resulting from a prompt is not predictable; introduce mechanisms for predictable edit magnitude (e.g., sliders) and calibration procedures.
- Architecture ablations: Grid-based identity conditioning is chosen without extensive comparison; systematically compare conditioning designs (adapters, reference encoders, LoRA) and report trade-offs.
- Identity drift detection: No automatic detection of identity violation in outputs; develop VNE-consistency validators (e.g., retrieval-based, classifier-based) and use them for training-time or inference-time rejection.
- Formalization of identity: Identity is operationalized via VNEs but lacks theoretical grounding; propose a formal model linking identity-defining features to permissible intrinsic variations and validate with user studies.
- Video/multi-view consistency: The approach is image-only; extend and evaluate multi-view or video editing for temporally/spatially consistent identity-preserving edits.
- Lighting and shadows: Edits can require lighting changes for realism but are constrained to preserve extrinsic factors; investigate joint attribute editing with physically plausible relighting while maintaining scene consistency.
- Robustness to text ambiguity: The pipeline assumes well-formed key–value prompts; evaluate robustness to free-form or ambiguous prompts and improve parsing with structured semantics.
- Safety and misuse: Identity-preserving edits on branded products could facilitate counterfeiting or deceptive imagery; propose safeguards (e.g., watermarking, detection, usage policies) and evaluate their effectiveness.
Glossary
- Ablation study: A controlled analysis that removes or changes components to assess their impact on performance. "An ablation study in \cref{sec:analysis_ablation} highlights the critical role of VNEs in enabling effective identity-preserving attribute editing."
- Albedo: The intrinsic diffuse reflectance property of a surface that affects its perceived brightness and color independent of lighting. "enables changes to physical properties such as albedo and roughness using synthetic data."
- Bounding-box mask: A coarse rectangular mask defining an object's region, used when precise segmentation is unavailable or shape is changing. "For shape edits where the target geometry is unknown, we use coarse bounding-box masks (bottom)."
- Classifier-free guidance: A technique in diffusion models that balances conditional and unconditional scores to control fidelity vs. adherence to conditioning signals. "Following~\cite{brooks2023instructpix2pix}, we use classifier-free guidance~\cite{ho2022classifier_cfg} with scales of $7.5$ (text) and $2.0$ (image)."
- Cross-attention: An attention mechanism that conditions one sequence (e.g., image features) on another (e.g., text embeddings) to guide generation. "The text prompt is encoded using a text encoder and injected into the UNet through cross-attention layers."
- Denoising network: The core neural network in a diffusion model that predicts noise or clean data during the iterative denoising process. "Specifically, we adapt the UNet-based denoising network to condition on three inputs:"
- DINOv2: A self-supervised vision transformer feature extractor used for semantic similarity and retrieval tasks. "DINOv2 performs worse, often clustering visually similar but identity-distinct objects, which damages identity conditioning."
- Diffusion loss: The training objective (typically L2 on noise) used to train diffusion models to denoise progressively noised data. "The diffusion loss is applied only to the left half to focus the learning on the edited region."
- Diffusion models: Generative models that synthesize data by reversing a gradual noising process through learned denoising steps. "Diffusion models have become the standard for high-fidelity text-to-image generation~\cite{ldm_rombach2022high,ldm_ramesh2022hierarchical}."
- Diffusion timestep: The discrete step index in the diffusion process corresponding to a particular noise level during training or sampling. "where denotes the diffusion timestep, and , parameterize the noise schedule."
- FLUX: A recent generative model architecture used as a backbone in some reference-based image generation systems. "Diptych~\cite{diptych}, based on FLUX~\cite{flux}, supports reference-based generation via input grids but struggles with intrinsic edits."
- Gemini: A multimodal vision-LLM used for automated labeling and attribute extraction. "We use Gemini to assign textual VNE labels to objects detected in OpenImages."
- Grid-based self-attention: A mechanism that applies self-attention over spatially arranged inputs (e.g., tiled images) to propagate information across regions. "introduces a grid-based self-attention mechanism conditioned on instance-retrieval-based references, enabling object insertion."
- Heavy-tailed pattern: A statistical distribution where extreme values (e.g., very large clusters) occur with non-negligible probability. "\cref{fig:vne_cluster_size} shows the distribution of cluster sizes, which follows a heavy-tailed pattern: while most clusters are small, a few contain thousands of instances."
- Identity conditioning: Conditioning a generative model on information that specifies object identity to preserve it during editing. "For identity conditioning, we define an object's identity through its Visual Named Entity (VNE)."
- Image inpainting: Filling or generating missing/occluded image regions, often guided by surrounding context and prompts. "Extensions such as inpainting~\cite{ssl_yang2023paint}, style transfer~\cite{hertz2024style,b-lora}, and image-to-image~\cite{ye2023ip_adapter} have broadened their applicability."
- Inference-time editing: Applying the trained model to modify inputs according to prompts during inference without further training. "At inference time, given a source image and a text prompt specifying the change of the target attribute (e.g.,
color: red'',material: wood''), Alterbute modifies only the specified intrinsic attribute while preserving all other intrinsic and extrinsic properties, as well as the identity of the object." - Instance-retrieval features: Visual descriptors optimized for retrieving specific object instances, often enforcing fine-grained similarity. "instance-retrieval features~\cite{cao2020unifying_ir1,shao20221st_place_ir} result in overly restrictive identities, which do not allow any changes to intrinsic attributes."
- Inversion-based methods: Techniques that map an input image into a generative model’s latent space for faithful reconstruction before editing. "Inversion-based methods~\cite{mokady2023null,voynov2023p+,garibi2024renoise} optimize latent codes to reconstruct input images but struggle with identity preservation during editing."
- Latent diffusion model: A diffusion model operating in a compressed latent space (rather than pixel space) for efficiency and quality. "We fine-tune a pretrained latent diffusion model~\cite{ldm_ramesh2022hierarchical,ldm_rombach2022high,ldm_saharia2022photorealistic} to enable precise control over an object identity, intrinsic attributes, and extrinsic scene context."
- Noise schedule: The schedule defining noise levels over diffusion timesteps for forward noising and reverse denoising. "where denotes the diffusion timestep, and , parameterize the noise schedule."
- Noisy latent: A latent representation of an image corrupted with noise at a given diffusion timestep. "The left half contains the noisy latent of the target image, while the right half contains a reference image sampled from the same VNE cluster."
- OpenImages: A large-scale dataset of images with object annotations used for training and evaluation. "We use Gemini to assign textual VNE labels to objects detected in OpenImages."
- SDXL: A large-scale text-to-image diffusion architecture used as a backbone for fine-tuning. "We fine-tune a text-to-image latent diffusion model based on the SDXL architecture~\citep{podell2023sdxl} (with 7B parameters)."
- Segmentation mask: A pixel-precise binary mask identifying the object region within an image. "Segmentation masks are obtained using~\citep{ravi2024sam}."
- Self-attention layers: Neural layers that compute pairwise interactions among tokens or spatial locations to propagate context. "This spatial layout allows self-attention layers in the UNet to propagate identity features across the two halves."
- Subject-driven generation: Methods that condition on subject-specific examples to preserve identity in generation. "In contrast, subject-driven generation methods~\cite{dreambooth,chendisenbooth,kumari2023multi,tewel2023key} are conditioned on several views of the object identity but preserve a restrictive notion of identity, disallowing any intrinsic changes."
- Text encoder: A neural network that converts textual prompts into embeddings used to condition image generation. "The text prompt is encoded using a text encoder and injected into the UNet through cross-attention layers."
- Text-to-image generation: The task of synthesizing images conditioned on textual descriptions. "We fine-tune a text-to-image latent diffusion model based on the SDXL architecture~\citep{podell2023sdxl} (with 7B parameters)."
- Tuning-free: A method that does not require per-subject or per-image fine-tuning at inference time. "In contrast, Alterbute is tuning-free, built on a simpler backbone (SDXL~\cite{podell2023sdxl}), and uses VNEs for identity-preserving attribute editing."
- UNet: A convolutional neural network architecture with encoder-decoder and skip connections, widely used in diffusion models. "This spatial layout allows self-attention layers in the UNet to propagate identity features across the two halves."
- Vision-LLM (VLM): A model jointly trained on visual and textual data to perform multimodal understanding and generation. "We use a vision-LLM to automatically extract VNE labels and intrinsic attribute descriptions from a large public image dataset, enabling scalable, identity-preserving supervision."
- Visual Named Entities (VNEs): Fine-grained, nameable visual identity categories that group similar instances while allowing intrinsic variation. "Visual Named Entities (VNEs) -- fine-grained visual identity categories (e.g., ``Porsche 911 Carrera'') that group objects sharing identity-defining features while allowing variation in intrinsic attributes."
- VNE cluster: A set of images grouped under the same Visual Named Entity, used for identity-consistent supervision. "This image is randomly sampled from the same VNE cluster as the target image;"
- Zero-shot: Performing a task without task-specific training pairs, by generalizing from learned priors or references. "enables zero-shot material transfer from reference images"
Practical Applications
Practical Applications of Alterbute
Alterbute is a diffusion-based, tuning-free method for editing intrinsic object attributes (color, texture, material, shape) in images while preserving perceived identity and scene context. It achieves this via a relaxed supervised training objective, Visual Named Entities (VNEs) for identity conditioning, and inference-time constraints that reuse the original background and object mask. Below are actionable, real-world applications derived from the method’s findings and innovations.
Immediate Applications
These applications can be deployed today with current tooling (SDXL backbone, SAM segmentation, VNE labeling via a VLM, and standard GPU/TPU inference).
- E-commerce and Retail (Software, Marketing)
- Product variant generation and visual configurators: Automatically render color/material/texture variants of catalog products (e.g., “iPhone 16 Pro in titanium blue,” “IKEA LACK table in walnut”) while preserving product identity.
- Workflow: Ingest product imagery → object segmentation (SAM) → apply Alterbute with attribute prompts → publish variants via CMS/PIM systems.
- Tools/products: “Catalog Variants Generator” microservice; Shopify/BigCommerce plugins; DAM integrations.
- Assumptions/dependencies: Accurate segmentation masks; reliable VNE alignment with brand definitions; disclosure for edited images.
- Regional and seasonal campaign adaptation: Rapidly recolor finishes (holiday red, summer pastel) and materials for market-specific campaigns without reshoots.
- Dependencies: Brand compliance rules; prompt-crafting guidelines; editorial QA for artifacts.
- Advertising, Creative Production, and Post-Production (Media/Entertainment, Software)
- Identity-preserving prop edits: Change the texture/material/color of on-set objects in stills without altering scene context (e.g., a mug’s glaze, a lamp’s finish).
- Workflow: Ingest production stills → select target object → apply single-attribute prompts → compositor review.
- Tools/products: Photoshop/After Effects plugin using Alterbute API; “Post-Production Editor” pipeline.
- Dependencies: High-quality masks; background consistency checks (bounding-box masks may produce minor artifacts).
- Automotive and Consumer Electronics (Retail, Marketing)
- Dealer/brand configurators: Create color/trim/material previews of vehicles and devices while preserving model identity (e.g., “Porsche 911 Carrera interior in Alcantara”).
- Tools/products: Web configurator SDK embedding Alterbute; dealer CMS integration.
- Dependencies: Legal requirements for disclaimers; identity fidelity under brand guidelines.
- Interior Design and Architecture (Design, AR/VR)
- Material and finish visualization: Preview fabrics, woods, stone finishes on furniture and fixtures in client photos; generate mood boards with consistent identity.
- Tools/products: Figma/Photoshop plugin; “Designer’s Material Preview” app.
- Dependencies: Mask quality, lighting compatibility; client sign-off on non-physical combinations.
- Fashion and Apparel (Retail, Marketing)
- Fabric/print recolor and texture substitutions for product photos while preserving style identity (e.g., a specific sneaker model with alternate uppers).
- Assumptions: Shape edits remain conservative; textile realism depends on prompt specificity.
- Robotics and Vision ML (Robotics, Software)
- Domain randomization for robustness: Augment datasets by varying color/material/texture of objects while preserving identity, reducing spurious correlations.
- Workflow: Select identity-labeled assets → batch intrinsic edits → retrain models → evaluate invariance.
- Dependencies: Clear identity definitions; consistent annotation across augmented data.
- Academia and Research (Education, Vision)
- Controlled datasets for identity-versus-attribute studies: Generate paired images varying intrinsic attributes to study invariance, perception, and recognition models.
- Use cases: Cognitive experiments; benchmarking recognition under intrinsic changes.
- Dependencies: Human-aligned VNE definitions; public datasets with appropriate licensing.
- Social Media and Daily Use (Consumer Software)
- Aesthetic object edits: Non-destructive recoloring and material tweaks in photos (e.g., phone case finish, furniture color) for personal posts and home planning.
- Tools/products: Mobile photo-editing app feature; “Alterbute Lite” consumer editor.
- Dependencies: On-device segmentation; simplified prompts; disclaimers for realism.
- Digital Asset Management and Brand Governance (Software, Marketing)
- Identity-preserving asset harmonization: Standardize material/finish across asset libraries without sacrificing identity fidelity.
- Tools/products: DAM plugin for batch edits with VNE consistency checks.
- Dependencies: Brand policy alignment; review workflows.
Long-Term Applications
These applications require further research, scaling, or development (e.g., real-time inference, 3D/video consistency, robust shape edits for rigid objects, provenance standards).
- Real-time AR/VR Object Editing (Software, AR/VR, Retail)
- On-device, low-latency intrinsic edits in live camera feeds (e.g., try different finishes on furniture in AR).
- Needs: Model distillation/quantization; fast segmentation; streaming inference; temporal coherence.
- Dependencies: Mobile hardware acceleration; temporal mask tracking; video diffusion consistency.
- Video Post-Production and Broadcasting (Media/Entertainment)
- Temporally consistent identity-preserving intrinsic edits across frames, minimizing flicker and maintaining scene continuity.
- Needs: Video diffusion/backbones with temporal attention; consistent background constraints.
- Dependencies: Robust multi-frame segmentation; scene lighting/pose invariance modules.
- Robust Shape Editing for Rigid Objects (Design, Manufacturing)
- Reliable, realistic shape edits that maintain identity-defining features of rigid objects (cars, appliances).
- Needs: Identity-aware geometric constraints; 3D priors; physics/material realism coupling.
- Dependencies: Training data covering shape variability; hybrid 2D–3D supervision; PBR-aware generation.
- CAD/Digital Twin Integration (Software, Manufacturing, Energy)
- Attribute edits synced to CAD models and digital twins for design iteration, material procurement, and simulation workflows.
- Tools/products: “Alterbute-to-CAD” bridge; PBR parameter mapping (albedo, roughness, metallic).
- Dependencies: Standardized material libraries; metadata linking between 2D and 3D assets.
- Material Realism and PBR Consistency (Rendering, Design)
- Physically-based material edits with controllable reflectance (albedo, roughness, anisotropy) for photo-realistic product previews.
- Needs: Joint training with PBR datasets; validated material models.
- Dependencies: Lighting estimation; scene relighting; standardized material descriptors.
- Synthetic Data Platforms for Vision (Robotics, Healthcare, Security)
- Identity-preserving intrinsic variations to train detectors/classifiers in safety-critical domains (tools, devices), while avoiding confounds.
- Needs: Domain-specific VNE taxonomies (e.g., medical instruments); bias auditing.
- Dependencies: Compliance review in regulated sectors; careful use to avoid misleading depictions.
- Policy, Compliance, and Content Provenance (Policy, Legal, Marketing)
- Transparent disclosure of identity-preserving edits in advertising and retail; watermarking/provenance (C2PA) for edited images to protect consumers and brands.
- Tools/products: “Alterbute Provenance SDK” for embedding edit metadata; brand audit dashboards.
- Dependencies: Industry standards adoption; legal guidelines on edited imagery; user education.
- Brand-Protection and Counterfeit Detection (Security, Policy)
- Detection services for identity-preserving edits used in brand spoofing or counterfeit listings, leveraging VNE identity signatures.
- Needs: Forensic detectors tailored to intrinsic edits; marketplace monitoring pipelines.
- Dependencies: Access to platform data; collaboration with marketplaces; evolving threat models.
- Sector-Specific VNE Taxonomies and Multilingual Labeling (Software, Data)
- Curated VNEs for specialized domains (industrial components, medical devices), multilingual support, and alignment with product information systems (PIM).
- Tools/products: “VNE Labeler” service; taxonomy management UI; API for PIM/DAM sync.
- Dependencies: Expert curation; continuous dataset updates; cross-lingual consistency.
- Constraint-Aware Multi-Attribute Editing (Software, Design)
- UI that enforces physically and semantically valid multi-attribute combinations (e.g., “gold” material implies color constraints).
- Needs: Learned constraint models; validation against material physics and brand rules.
- Dependencies: Knowledge bases of allowed combos; user feedback loops.
- Automated Background Cleanup for Shape Edits (Media, Software)
- Integrated object removal and background inpainting to eliminate artifacts from coarse bounding-box masks during reshaping.
- Tools/products: Pre-removal stage (e.g., ObjectDrop) + Alterbute; “Clean-Reshape” pipeline.
- Dependencies: High-quality inpainting; scene lighting and texture continuity.
Cross-Cutting Assumptions and Dependencies
- Identity definition depends on VNE quality: Human-aligned, fine-grained labels are critical; mislabeled or overly broad VNEs reduce identity fidelity.
- Mask accuracy matters: Precise segmentation yields best results; bounding-box masks enable shape edits but risk background artifacts.
- Prompt clarity: Attribute prompts must be specific (e.g., “material: brushed aluminum,” “texture: herringbone fabric”) to avoid ambiguous edits.
- Data coverage: Success depends on having VNE clusters with intrinsic variability; long-tailed categories may require targeted curation.
- Compute and latency: Real-time or batch throughput depends on hardware; mobile use cases require model compression.
- Legal and ethical considerations: Edited product images may require disclosures; avoid deceptive representations in regulated sectors; adopt provenance standards.
- Scene constraints: Lighting and pose are reused to preserve extrinsic context; extreme scene variations may require relighting or pose-aware models.
These applications translate Alterbute’s identity-preserving intrinsic editing into concrete tools, workflows, and sector-specific value, while acknowledging the practical dependencies and responsible deployment considerations.
Collections
Sign up for free to add this paper to one or more collections.