- The paper demonstrates that single-stage fixed-codebook Huffman encoding achieves near-optimal compression within 0.5% of per-shard Huffman performance.
- It leverages high statistical similarity across tensor shards in distributed LLM training to eliminate dynamic frequency analysis and codebook generation.
- Results indicate significant reductions in communication latency and network overhead while maintaining compressibility near the Shannon optimum.
Single-Stage Huffman Encoder for ML Compression: A Technical Overview
Introduction
The scaling of LLM training and inference across distributed accelerators exacerbates network bandwidth bottlenecks, particularly during collective communication of large tensors such as activations, weights, and gradients. Traditional three-stage Huffman coding pipelines, while entropy-optimal, are limited by on-the-fly frequency estimation, dynamic codebook generation, and the necessity to transmit codebooks alongside payload data, introducing unacceptably high overheads in low-latency domains including die-to-die interconnects. This work proposes a single-stage, fixed-codebook Huffman encoding approach specifically tailored to ML contexts, leveraging high statistical similarity across tensor shards and layers to eliminate dynamic codebook computation and distribution costs while retaining competitive compressibility.
Background and Motivation
Multi-accelerator model parallelism in LLMs (e.g., Gemini, Gemma, LLaMA, GPT) involves sharding parameters and activations, which demands frequent collective operations like AllReduce and AllToAll. Network communication quickly becomes a major limiting factor. Compression via lossless coding, particularly Huffman codes, offers effective bandwidth reduction but typically at the cost of considerable runtime overhead due to the necessity of computing per-chunk or per-shard symbol histograms and synchronizing variable codebooks with receivers. For latency-sensitive communication scenarios frequently characteristic of ML system inter-chip messaging, these overheads render classic three-stage Huffman schemes impractical.
Statistical Analysis of Gemma 2B Tensors
Empirical investigations were performed using the Gemma 2B model during SFT, analyzing FFN1 activations across 18 layers distributed over 64 TPU shards (total 1152 shards per tensor type). Compressibility was evaluated under multiple numerical representations (bfloat16, e4m3, e3m2, etc.), with detailed results presented for bfloat16.
The distribution of FFN1 activations, when binned into 8-bit symbol resolution, exhibits a highly skewed PMF (Shannon entropy ≈ 6.25 bits, ideal compressibility ∼21.9%). Compressibility achieved through per-shard Huffman coding closely approaches the theoretical optimum (∼21.6%).
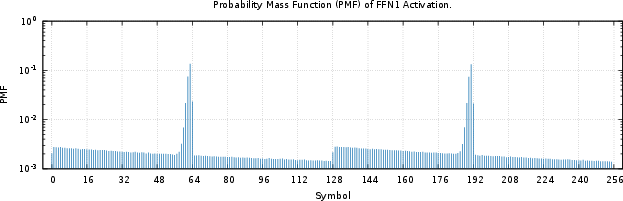
Figure 1: Probability mass function (PMF) of FFN1 activation, showing pronounced skew in symbol frequencies.
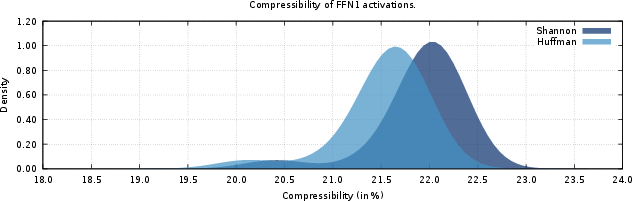
Figure 2: Histogram of compressibility for FFN1 activation shards, baseline per-shard Huffman.
Codebook Reuse via Distributional Similarity
A critical observation is the low KL divergence (<0.06) of per-shard PMFs relative to the global average PMF. This substantial distributional homogeneity implies that a global or per-tensor codebook is an effective substitute for dynamically per-shard codebooks.

Figure 3: KL divergence distribution of FFN1 activation shards relative to the mean PMF, confirming high cross-shard similarity.
Applying fixed, precomputed Huffman codebooks derived from previous batch averages, the observed compressibility across all tested shards consistently falls within 0.5% of per-shard Huffman encoders and within 1% of optimal Shannon bounds.
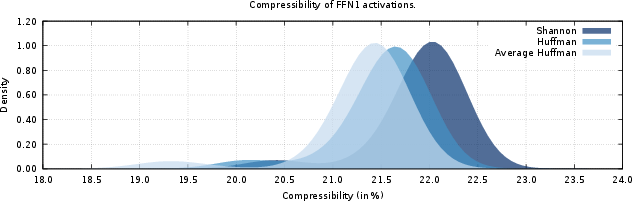
Figure 4: Histogram of compressibility using codebooks derived from average distributions, showing negligible loss relative to per-shard codings.
Implementation Considerations
Global codebooks for major tensor types and datatypes can be computed offline or during model warmup, maintained for each relevant tensor (e.g., FFN1 activation, FFN2 weight gradient). System nodes cache these codebooks and transmit only encoded values plus a compact codebook identifier, eliminating codebook transfer and frequency analysis from the critical communication path. Both software and hardware implementations are viable; for the latter, several codebooks may be benchmarked in parallel for compressibility, retaining only a small overhead for codebook selection.
Strong Numerical Findings
- Compressibility via average-distribution fixed codebooks achieves within 0.5% of per-shard Huffman performance and within 1% of Shannon compressibility (∼21–23% reduction).
- KL divergence analysis reveals cross-shard symbol distributions are highly similar (KL < 0.06), supporting codebook reusability.
- Results generalize to other tensor types and numeric formats, albeit with varying absolute compressibility, but similar distributional properties.
Theoretical and Practical Implications
This approach demonstrates that repeated tensor statistics across distributed LLM training suffice for constructing highly efficient, fixed Huffman codebooks, challenging the perceived necessity of dynamic, shard-local frequency analysis. Practically, single-stage fixed-codebook Huffman encoding enables uncompromised, low-latency, on-the-fly lossless compression for both inter-device and intra-package ML communication fabrics. By minimizing encoding latency and eliminating control traffic, total communication time is significantly reduced in large-scale ML deployments.
On the theoretical plane, these findings point toward the viability of further specialized, communication-efficient codecs for ML infrastructure, exploiting the concentration of tensor activation and parameter statistics. Future architectural directions may explore even more aggressive forms of codebook sharing and specialization—spanning tensor types, layers, or even entire models—to further reduce memory footprint and control-plane complexity.
Conclusion
Single-stage Huffman encoding using fixed codebooks derived from average batch-wise distributions is nearly as effective as conventional per-shard optimal encoders in the context of LLM training and inference, with a negligible penalty in compression ratio (≤0.5% overhead) and significant reductions in codec latency and network overhead. These results indicate a paradigm shift in how ML system designers may deploy lossless compression, particularly for communication-critical and low-latency environments.
Reference: "Single-Stage Huffman Encoder for ML Compression" (2601.10673)

