- The paper presents the Language Model Compressor (LMC) that uses byte-grouping and Huffman encoding to achieve efficient tensor snapshot compression.
- It demonstrates significant reductions in storage and GPU idle time by exploiting the evolving entropy in LLM checkpoint data.
- Experiments on over 28 TiB of data confirm LMC’s order-of-magnitude improvement over traditional methods such as BZ2 and LZ4.
Lossless Compression for LLM Tensor Incremental Snapshots
Introduction
The paper "Lossless Compression for LLM Tensor Incremental Snapshots" addresses the challenge of efficiently checkpointing LLMs during training. By analyzing the compressibility of tensor data that evolves throughout training, the paper proposes a novel compression technique tailored for these incremental snapshots. The significance lies in the substantial amount of data that needs storage during checkpointing, which, without efficient compression, imposes considerable overhead in terms of storage and network bandwidth.
Background: LLM Tensor Characteristics
Tensors, integral to LLMs, represent neuron parameters—weights and biases—which are adjusted during training. Predominantly using floating-point formats like IEEE 32-bit float and Google's 16-bit brain float (bfloat16), these tensor representations require careful consideration for efficient storage. The paper explores the nature of tensor data transitions and proposes efficient data storage methods, leveraging byte-grouping and Run-Length Encoding (RLE).
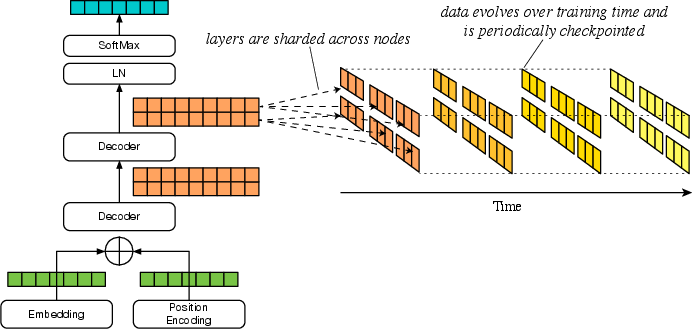
Figure 1: Tensor Data Shards Evolving
Proposed Compression Algorithm
The core contribution of the paper is the LLM Compressor (LMC), designed to provide high throughput and effective compression tailored for tensor data. By utilizing byte-grouping and Huffman encoding, LMC achieves significant compression performance. The byte-grouping strategy, illustrated in the paper, reorganizes data to enable more effective RLE by aligning similarly stable bytes contiguously in memory.
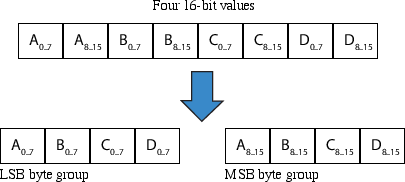
Figure 2: Example Byte-Grouping of four 16-bit values
Analysis of LLM Checkpoint Data
The analysis focuses on tensor data from six LLM checkpoint sequences, totaling over 28 TiB. The models include both bfloat16 and float32 formats. The paper presents extensive experiments on the changing entropy of tensor data, highlighting the potential for lossless compression using existing and novel coding techniques. Notably, the paper's examination of self-attention weights over time illustrates how convergence reduces data variability, enhancing compressibility.
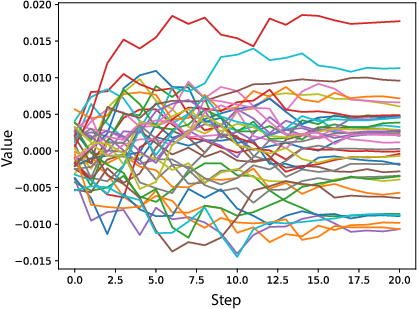
Figure 3: Sample Self-Attention Weights over Time from BLOOM Data Set
LMC's performance is benchmarked against standard compression engines like BZ2 and LZ4. The results demonstrate LMC's superior compression performance and throughput, particularly emphasizing the order-of-magnitude reduction in compression times compared to traditional methods. This performance is critical in reducing GPU idle time during checkpointing, thereby enhancing training efficiency.
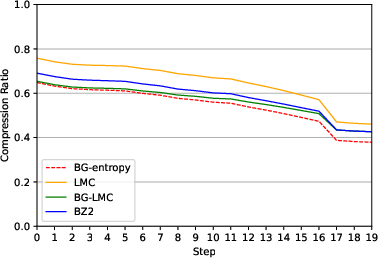
Figure 4: Comparison of BZ2, LMC, BG-LMC compression ratios vs. entropy of BLOOM data
Practical Implications and Future Developments
The efficient compression of tensor snapshots holds substantial practical value in large-scale model training, where checkpointing is pivotal to mitigate training disruptions due to hardware failures. By reducing the overhead associated with checkpoint data storage and transfer, training pipelines can be optimized for speed and resource utilities.
Future developments may involve refining these compression techniques further, potentially incorporating more adaptive coding schemes or parallel processing strategies to scale with even larger tensor datasets. Exploring lossy compression methods, under controlled precision-loss scenarios, could also be a promising direction to strike a balance between performance and data fidelity.
Conclusion
The "Lossless Compression for LLM Tensor Incremental Snapshots" paper presents a comprehensive study and a practical solution for minimizing the storage footprint of LLM checkpoints. By adopting an entropy-based approach combined with byte-grouping and Huffman encoding, the proposed LMC demonstrates significant improvements over existing compression methods. This work paves the way for more efficient and robust management of LLM training processes, essential in today's data-driven AI research landscape.