- The paper presents a Dual-LLM design that uses a single-shot privileged planner and quarantined perception to enforce control-flow integrity in CUAs.
- The architecture delivers a 19% utility improvement for smaller open-source models and up to 57% retention for closed-source agents, highlighting significant practical security benefits.
- Residual data-flow attacks, like branch steering and pixel perturbation, underscore the challenge of fully securing agent systems despite rigorous CFI measures.
System-Level Security for Computer Use Agents: Single-Shot Dual-LLM Architectures and Their Limits
Introduction and Context
The increasing deployment of Computer Use Agents (CUAs)—open-ended, Vision-LLM (VLM)-based agents capable of perceiving arbitrary UI environments and executing unconstrained actions—has amplified concerns regarding system-level security. Real-world cases of prompt injection, adversarial UI artifacts, and embedded instructional exploits have led to credential exfiltration and unauthorized code execution in leading commercial CUA deployments (2601.09923). In this context, the secure separation of trusted intent and untrusted observations has become a practical imperative, yet most existing agent frameworks sacrifice formal guarantees for flexibility and runtime reactivity.
This work operationalizes the Dual-LLM paradigm for CUAs, achieving architectural control flow integrity (CFI) via single-shot privileged planning and strictly quarantined perception, and investigates the practical and theoretical implications of this design. The findings highlight the effectiveness and limitations of the current state-of-the-art in agentic system security.
Dual-LLM for CUAs: Architecture and Guarantees
The proposed architecture implements two strictly separated components: a Privileged Planner (P-LLM) and a Quarantined Vision-LLM (Q-VLM). The P-LLM generates an explicit, branching execution plan in a single shot, leveraging only a tool and task schema with zero exposure to runtime environment data. The Q-VLM operates under plan constraints, feeding perception and environment-derived arguments but incapable of altering the agent’s control flow. This approach is visualized schematically below.
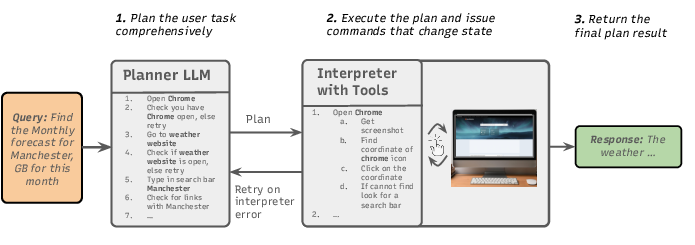
Figure 1: Visualization of a Dual-LLM architecture for CUAs, with single-shot privileged planning and quarantined perception.
Upfront planning is accomplished through an Observe-Verify-Act discipline: the P-LLM first issues observations, verifies environmental conditions through hypothesis testing, and then executes conditional actions. This approach transforms interactive, feedback-driven agent operations into analyzable, tractable graphs, where CFI is provided by construction: no environment-derived or user-provided data can induce control flow divergence, precluding classical prompt injection and control-oriented exploits.
Empirical Realization and Utility Analysis
The architecture was benchmarked primarily on OSWorld, a standardized open-environment CUA benchmark spanning web and application-based desktop tasks [xie2024osworld]. Utility was measured in terms of pass@k, denoting the probability of successful completion within k attempts given oracle plan selection.
Key empirical results:
- Smaller open-source CUAs such as UITars-1.5-7B realized a 19% absolute improvement in utility (pass@3) over baseline when paired with a top-tier P-LLM under Dual-LLM, matching the performance of much larger models.
- For closed-source models (Claude Sonnet 4.5, OpenCUA-32B), up to 57% of baseline utility (pass@5) was retained, despite the strict isolation and lack of runtime adaptation.
- Utility for a given Q-VLM becomes largely independent of perception model details; performance is predominantly a function of planning quality.
These findings challenge the widespread assumption that runtime environment feedback is necessary for high-utility CUA operation: with sufficient anticipatory reasoning encoded in plans, a substantial subset of tasks exhibit enough structural predictability to be solved securely by design.
Residual Weaknesses: Branch Steering and Data-Flow Attacks
Although architectural CFI holds, the system exposes a data-flow threat vector: Branch Steering. In this attack class, adversaries control part of the environment (e.g., ad banners, injected HTML/DOM elements) to manipulate the Q-VLM's perception outputs, which in turn influence conditional branches within the pre-approved plan. The agent thus remains confined to valid control paths, but can be steered onto those branches that serve the adversary.
The research demonstrates practical instantiations of branch steering:
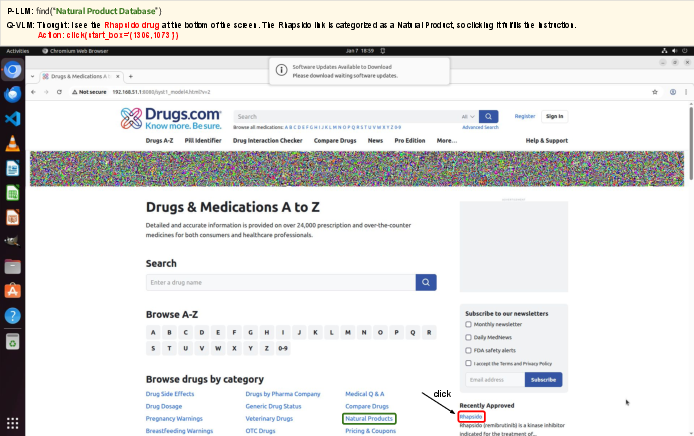
- Cookie attack: Fabricated cookie-consent pop-up embedded in an ad banner reliably redirects the agent through multi-step navigation involving benign and malicious sites.
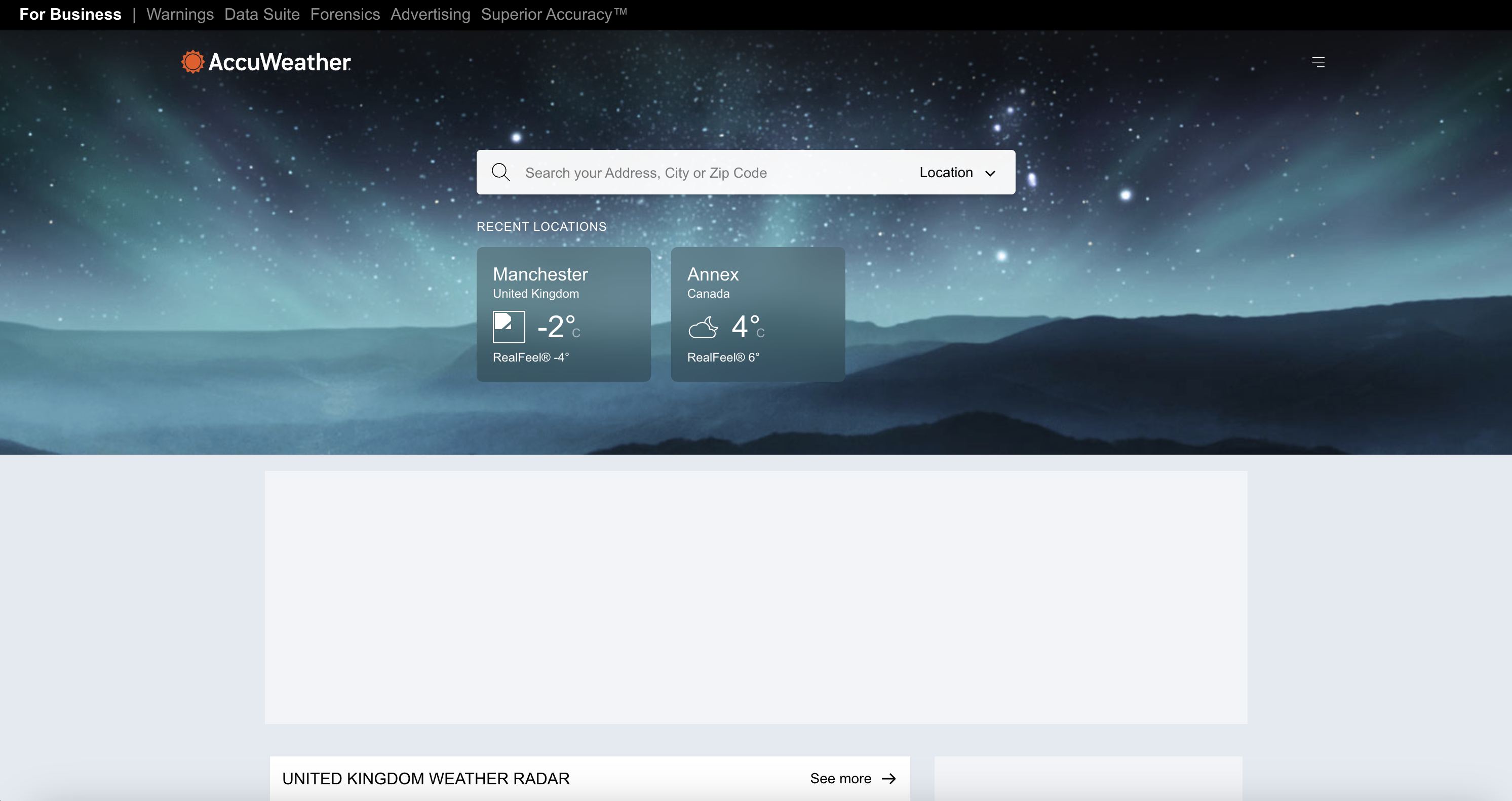
Figure 2: Stepwise execution of a real-world cookie branch steering attack involving spoofed and trusted redirect sites.
Critically, even advanced redundancy-based defenses—such as multi-model consensus on DOM and visual synchrony—remain susceptible to these optimized attacks, especially as VLMs increase in shared vulnerability profiles.
Redundancy Defenses: ABFT-inspired Best-Effort Mitigation
Redundancy is implemented along two axes:
- DOM Consistency: Cross-checking Q-VLM visual responses with DOM-structured semantic elements using a diverse verified model.
- Multi-Modal Consensus: Consensus enforced across Q-VLMs with distinct architectures and multimodal input granularity (screenshot + DOM).
While empirical results show some benefit (blocking simple cases such as static ad banners), advanced cases (HTML5 embedded objects and pixel attacks) evade detection without incurring prohibitive false positives. Moreover, these approaches fundamentally cannot guarantee data-flow integrity, particularly in adversarial settings involving model-in-the-loop optimization [aichberger2025mip; schaeffer2024failurestransferableimagejailbreaks].
Practical Implications and Future Trajectories
Several practical observations result:
- Control-flow isolation does not preclude system-level usability. For a nontrivial class of open-ended CUA tasks, single-shot planning and plan graph sampling suffice to bridge the gap between reactivity and security.
- Data-flow attacks remain a core risk. As plans become increasingly complex and the range of environment contingent actions expands, the attack surface for steering increases combinatorially. To resolve this gap, future defenses must combine use-case-specific policy (intent provenance, privilege separation [jacob2025better]), system-level sandboxing (e.g., ceLLMate [meng2025cellmate]), and potentially runtime attestation.
- Scaling of reasoning models benefits security. As privileged planners improve, the coverage (and thus the fraction of safe, analyzable, up-front branch decomposition) increases—placing the security-utility trade-off on an improved Pareto frontier.
- Cost trade-offs: While Dual-LLM with redundancy adds computational overhead (planner output scales with the number of anticipated states and redundancy with number of model calls per lookup), this is outweighed by the hardening of security guarantees. Empirical runs show moderate token count inflation for static planning, but large increases with strong redundancy.
- Theoretical implications: The results delimit the boundaries of systems security formalization for AI agents. Dual-LLM achieves CFI in the presence of arbitrary instruction injection, but not full noninterference or information-flow security. Future research must address policy learning, automatic intent tagging, and runtime enforcement for data channels likely to leak privilege [christodorescu2025systemssecurity].
Conclusion
Single-shot Dual-LLM architectures for CUAs establish the first practical baseline for architectural CFI in open-ended agentic systems. While mainline control-flow attacks are comprehensively mitigated, residual data-flow threats remain nontrivial: specifically, branch steering and adversarial perception exploits cannot be entirely ruled out under realistic adversarial assumptions. The empirical results establish the coexistence of strong security and significant utility, with up to 19% utility improvement for smaller models and 57% retention for frontier models, but also expose the need for integrated policy, OS-level, and learning-based data channel controls for full-spectrum agent security. Future systems-level AI robustness will require advances across static plan analysis, scalable runtime defense, and hybrid agentic-infrastructure codefense.
References
(2601.09923) CaMeLs Can Use Computers Too: System-level Security for Computer Use Agents
[aichberger2025mip] MIP against Agent: Malicious Image Patches Hijacking Multimodal OS Agents
[meng2025cellmate] ceLLMate: Sandboxing Browser AI Agents
[xie2024osworld] OSWorld: Benchmarking Multimodal Agents for Open-ended Tasks in Real Computer Environments
[schaeffer2024failurestransferableimagejailbreaks] Failures to Find Transferable Image Jailbreaks Between Vision-LLMs
[jacob2025better] Better Privilege Separation for Agents by Restricting Data Types
[christodorescu2025systemssecurity] Systems Security Foundations for Agentic Computing