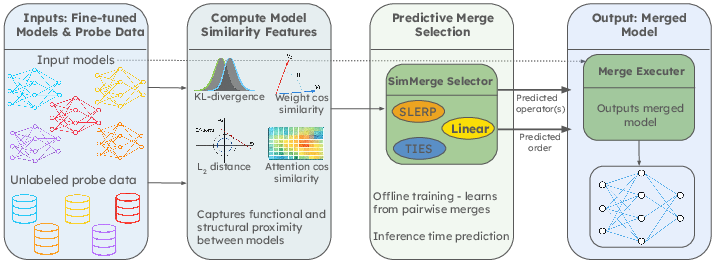
SimMerge: Learning to Select Merge Operators from Similarity Signals
Abstract: Model merging enables multiple LLMs to be combined into a single model while preserving performance. This makes it a valuable tool in LLM development, offering a competitive alternative to multi-task training. However, merging can be difficult at scale, as successful merging requires choosing the right merge operator, selecting the right models, and merging them in the right order. This often leads researchers to run expensive merge-and-evaluate searches to select the best merge. In this work, we provide an alternative by introducing \simmerge{}, \emph{a predictive merge-selection method} that selects the best merge using inexpensive, task-agnostic similarity signals between models. From a small set of unlabeled probes, we compute functional and structural features and use them to predict the performance of a given 2-way merge. Using these predictions, \simmerge{} selects the best merge operator, the subset of models to merge, and the merge order, eliminating the expensive merge-and-evaluate loop. We demonstrate that we surpass standard merge-operator performance on 2-way merges of 7B-parameter LLMs, and that \simmerge{} generalizes to multi-way merges and 111B-parameter LLM merges without retraining. Additionally, we present a bandit variant that supports adding new tasks, models, and operators on the fly. Our results suggest that learning how to merge is a practical route to scalable model composition when checkpoint catalogs are large and evaluation budgets are tight.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about a smart way to combine different specialized AI LLMs into one stronger model. Instead of blindly trying lots of ways to mix models (which is slow and expensive), the authors build a tool called SimMerge that quickly predicts the best way to merge models by checking how similar they are—before doing the merge.
The big idea in one line
SimMerge doesn’t invent a new mixing method; it learns when to use existing mixing methods by reading “similarity signals” between models, saving time and compute while keeping performance high.
What were the researchers trying to find out?
In simple terms, they wanted to solve three questions that come up when you have many fine‑tuned models (for code, math, languages, etc.) and you want one model that can do a lot:
- Which models should we combine?
- Which “mixing rule” (merge operator) should we use for each pair?
- If we combine more than two models, in what order should we merge them?
They asked: Can we predict these choices cheaply and accurately using signals that don’t require labeled data or lots of test runs?
How did they approach the problem?
Think of each model like a student with a specialty—one’s great at math, another at coding, another at reading many languages. Combining them is like creating a study group. But how you combine them matters: some methods blend better than others, and the order you add students to the group can affect the final result.
SimMerge works in three main steps:
- It measures similarity between models using quick, inexpensive checks:
- Functional similarity: Give both models the same small set of inputs (like a mini, unlabeled quiz) and compare their answers. If they answer similarly, they’re functionally close.
- Structural similarity: Compare the “shape” of their internal settings (their parameters/weights), a bit like seeing how similar two engines are on the inside.
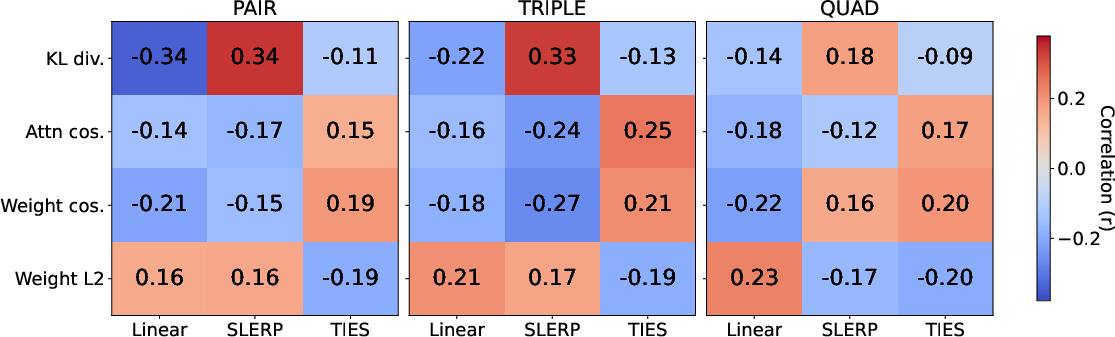
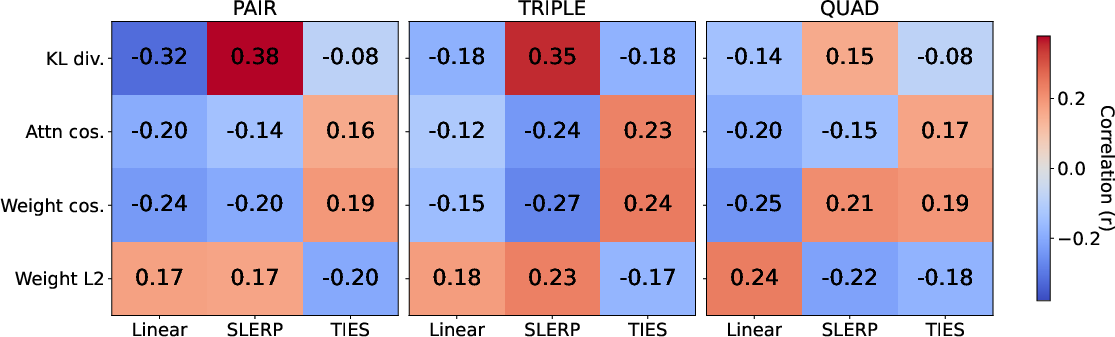
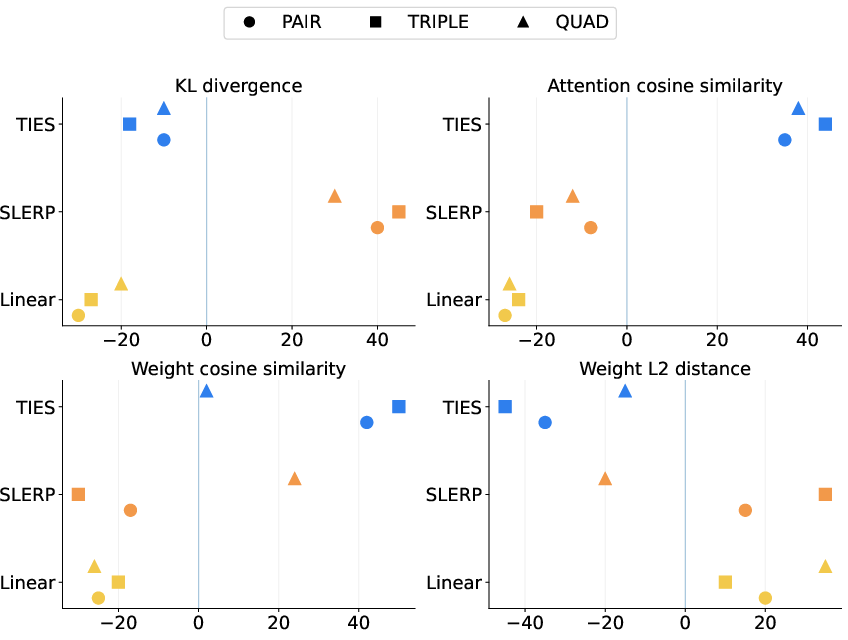
- These measurements include distances and angles between weight vectors and how similar the models’ output distributions are—don’t worry about the math names; they’re just ways to measure “how alike” two models are.
- It trains a small predictor to choose a merge operator:
- Merge operators are different ways to mix two sets of model parameters, like:
- Linear interpolation: a simple halfway blend.
- SLERP: a “curved” blend that keeps the overall scale consistent.
- TIES: a rule that tries to reduce interference by aligning signs and trimming unhelpful parts.
- SimMerge learns, from past examples, which operator works best given the similarity signals for a model pair.
- It plans the order for multi‑model merges:
- Merging isn’t “order-insensitive.” Like cooking, adding ingredients in a different order can change the outcome.
- SimMerge scores different merge orders using the same similarity features and picks the best plan—without testing every possibility.
- It also includes an online “bandit” version (think of it like trying options and learning from feedback) that adapts when new models or tasks appear.
Why this is efficient: All the similarity signals come from small unlabeled “probe” inputs and simple weight comparisons—no full training runs or large evaluations needed. That makes it much cheaper than brute-force “try everything and evaluate.”
What did they find?
Here are the main results and why they matter:
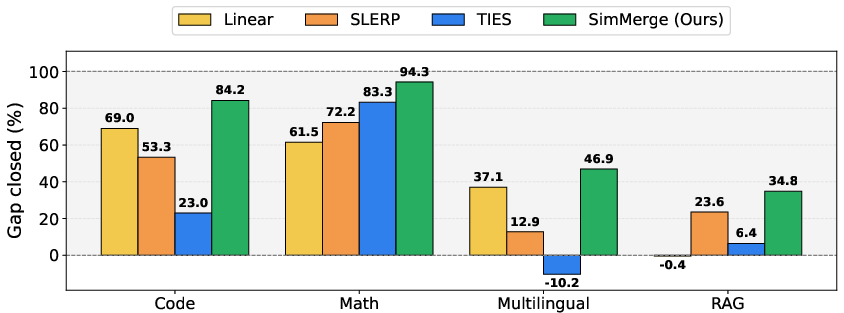
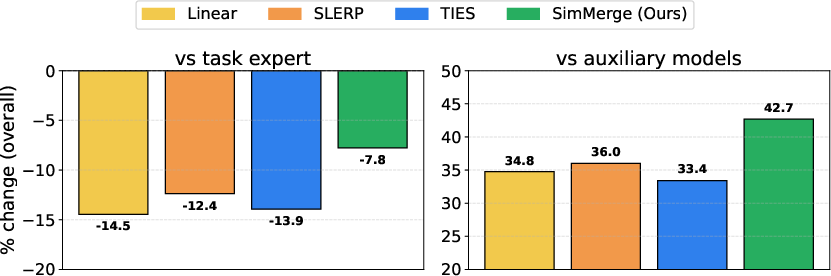
- It beats fixed rules for 2‑model merges:
- Across tasks like code, math, multilingual, and retrieval (RAG), SimMerge consistently chose better operators than always using the same rule.
- On average, it recovered 65% of the performance gap between off‑task models and the task expert, compared to 41.8% for the best single fixed operator. This means it got much closer to expert-level performance without expensive search.
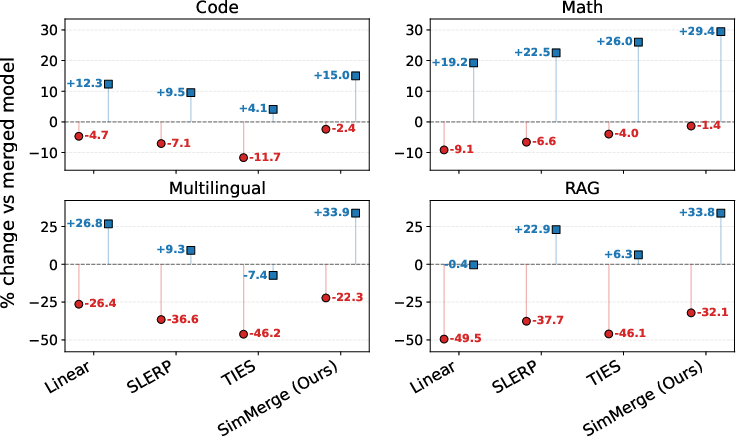
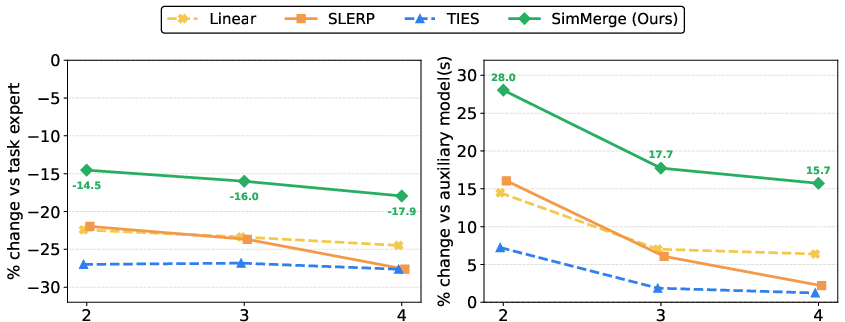
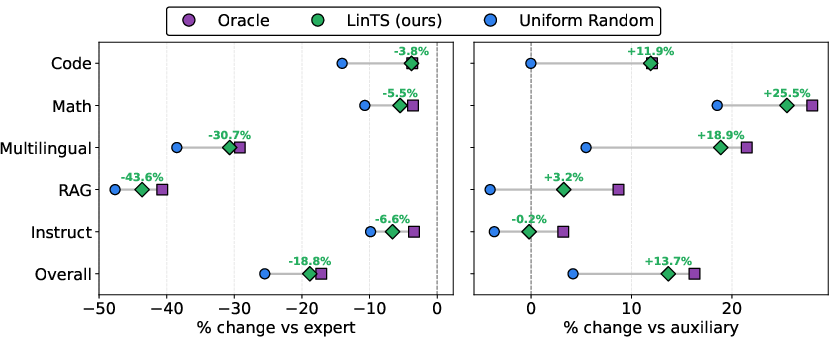
- It works for merging 3 and 4 models too:
- Even though the selector was trained only on 2‑model cases, it generalized well to 3‑ and 4‑way merges by scoring merge plans from pairwise similarities.
- As merging more models naturally gets harder, SimMerge still kept the best balance: smaller drop from the expert model and bigger gain over non-experts.
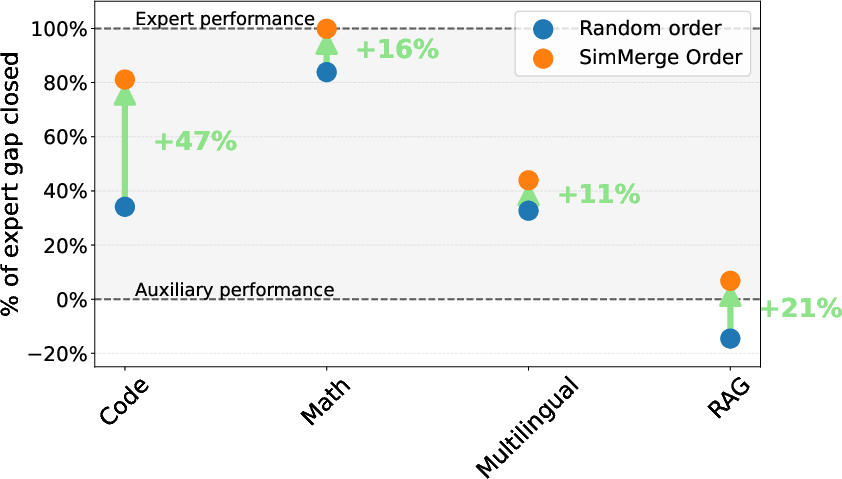
- Order matters—and SimMerge picks better orders:
- Using the same operators but a smarter order, SimMerge closed notably more of the expert gap than random orderings (e.g., +47% more on code, +21% on RAG). So choosing the right sequence really helps.
- It scales to much larger models without retraining:
- A selector trained on 7‑billion‑parameter models worked on 111‑billion‑parameter models and still outperformed fixed rules—showing strong transfer.
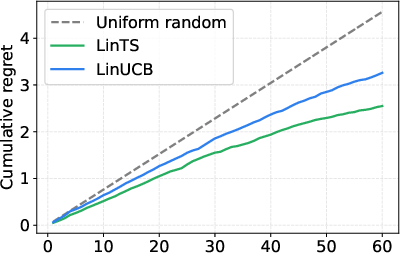
- It adapts online when things change:
- The bandit variant quickly learned to pick good operators as new tasks/models were added, getting close to an “oracle” that always knows the best choice.
Why does this matter?
- Saves a lot of time and compute: Instead of merging and testing many combinations, SimMerge predicts good choices upfront using cheap signals.
- More reliable model building: As organizations collect many specialized models, they need fast, scalable ways to combine them. SimMerge makes that practical.
- Flexible and future‑proof: It can add new merge operators, tasks, or models without starting from scratch, especially with the online bandit version.
- Better performance with fewer surprises: Because it adapts per case, it avoids the “one rule fits all” pitfalls where a single method works great on one task but harms another.
In short, SimMerge shows that “learning how to merge” models—using simple similarity checks—can reliably create strong, multi‑skill AI systems without the usual trial‑and‑error grind.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper. Each item is specific and actionable for future researchers.
- Generalization beyond a shared base: The method is only evaluated on checkpoints sharing the same pretrained base and architecture (Command-A 7B/111B). It remains unclear how SimMerge behaves when merging across different base families, architectures, tokenizer vocabularies, or training pipelines (e.g., LLaMA/Mistral vs. Command-A; different RoPE settings; adapter-based models).
- Operator coverage is narrow: Selection is limited to {Linear, SLERP, TIES}. Performance and feasibility with additional operators (e.g., EMR, ZipIt, Fisher merging, permutation/alignment-based operators, LoRA adapter merges) are not tested. How does SimMerge scale (sample complexity, feature requirements, accuracy) as the number and diversity of operators increases?
- Mixing coefficient fixed at α=0.5: The approach does not tune α per merge, per layer, or per operator. What is the joint benefit of learning α alongside operator selection, and does per-layer α improve outcomes? How does operator choice interact with α and with per-module mixing?
- Intermediate-merge feature propagation accuracy: Multi-way plan scoring relies on approximate propagation of similarity metrics for intermediate merges (convex bounds, triangle inequality). The accuracy of these approximations vs. recomputation is not quantified, especially for non-linear operators (e.g., TIES sign selection, SLERP geometry) and α≠0.5.
- Scalability to large catalogs and k≫4: The method is only evaluated up to 4-way merges. For catalogs with hundreds or thousands of checkpoints, computing pairwise features is O(N²), and plan enumeration grows factorially. What selection heuristics, pruning strategies, or submodular formulations can make plan scoring scalable for large k?
- Probe-set dependence and robustness: Similarity features depend on unlabeled probes drawn from each task’s input distribution (10k tokens). Sensitivity to probe size, domain mismatch, selection bias, privacy constraints, and distribution shift is not characterized. What are the minimal probe sizes, cross-task probe reuse strategies, and robustness under noisy/misaligned probes?
- Multi-task objective weighting: Plan selection aggregates predicted utility via macro-averaging over tasks, which may favor majority tasks or dilute minority-task objectives. How should task weights or Pareto-optimal objectives be set, and can SimMerge support constrained optimization (e.g., minimum acceptable performance on specified tasks)?
- Feature ablation and interpretability: The paper lacks a thorough, public ablation of feature channels (logit KL, activation cosine, weight cosine, attention similarity, norms). Which features drive operator/order selection per domain, and how robust are selections to feature noise or adversarial perturbations?
- Per-layer/operator granularity: Operator choice is made per merge step, not per layer/module. Would per-layer operator selection (or operator mixtures within a step) yield better results, and can the similarity signals support that finer granularity?
- Handling permutation misalignment: The selection does not explicitly address neuron/permutation alignment between finetuned models. How does SimMerge perform when models are substantially permuted, and can alignment-aware features or pre-alignment steps improve selection?
- Bandit variant practical constraints: The online bandit requires downstream evaluation to obtain rewards, reintroducing evaluation costs. Open questions include handling delayed/noisy rewards, non-stationarity (task drift), cold-start for new operators/models, contextual covariate shift, and multi-objective rewards (across several tasks simultaneously).
- Transfer across model families and scales: While 7B→111B transfer on the same base is promising, broader transfer (to different families, smaller/larger capacities, sparse/mixture-of-experts, quantized or pruned models) remains untested.
- Task coverage gaps: Evaluations omit safety/toxicity, factuality, long-context, tool-use, dialog quality, calibration, and robustness (adversarial or OOD). How does merging affect these properties, and can features be augmented to anticipate safety/regulatory risks?
- Selection cost vs. merge-and-evaluate: The paper does not provide end-to-end time/memory benchmarks of the selection pipeline (feature computation + plan scoring) vs. standard merge-and-evaluate searches, especially at large N and k. What are the cost curves and practical speed-ups?
- Multi-way plan search strategy: The number of candidate plans scored at test time, sampling/enumeration policies, and their impact on quality vs. compute are not specified. What sampling strategies or learned proposal mechanisms best trade off performance and cost?
- Operator hyperparameters: Operators like TIES often have tunable hyperparameters (e.g., thresholds/masks). SimMerge does not select/tune operator-specific hyperparameters. Can selection extend to per-operator hyperparameter optimization without reintroducing expensive search?
- Reliability across seeds and settings: While task evaluations use three seeds, the sensitivity of selection outcomes to random seeds, temperature, decoding strategies, and feature computation settings is not analyzed. What reproducibility guarantees and confidence intervals can be provided?
- Functional features for long generation: Logit KL and short-probe activations may not capture long-form generation behaviors (e.g., multi-step reasoning chains, code execution correctness beyond pass@1). What functional metrics better reflect long-horizon generation and composeability?
- Fairness and cross-lingual interference: Merging could disproportionately harm minority languages or underrepresented domains. There is no analysis of cross-lingual interference, bias amplification, or fairness impacts. How should selection incorporate fairness constraints or per-language safeguards?
- Public reproducibility: The paper references internal datasets and probe construction; code, data, and detailed protocols for feature computation, plan scoring, and bandit warm-start are not provided. Releasing artifacts would enable external validation and stress testing across diverse settings.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging SimMerge’s similarity-driven operator and merge-order selection to compose fine-tuned LLM checkpoints without expensive merge-and-evaluate loops.
- Bold: Model catalog auto-composer for MLOps
- Description: Automatically select merge operators and orders to consolidate many domain-specialized checkpoints (e.g., code, math, multilingual, RAG) into a single, versatile model release.
- Sectors: Software, enterprise AI platforms
- Tools/workflows: Merge planner integrated with a checkpoint registry (e.g., internal catalog, Hugging Face Hub), pre-merge feature computation pipelines using 10k-token unlabeled probes per task, cached forward-pass outputs, one-shot merge execution
- Assumptions/Dependencies: Models share a common pretrained base/architecture; candidate operators available (Linear, SLERP, TIES); unlabeled probes representative of target tasks; licensing allows parameter-space composition; monitoring for performance regressions on new domains
- Bold: Enterprise LLM consolidation (single model for multi-department use)
- Description: Compose department-specific fine-tunes (support, code-assist, multilingual QA, retrieval) into a unified production model to simplify deployment, ops, and governance.
- Sectors: Enterprise software, customer support, knowledge management
- Tools/workflows: CI/CD pipeline step that computes similarity signals, selects a multiway plan (order + operator per step), executes merges, and validates with spot checks
- Assumptions/Dependencies: Non-associativity requires careful order selection; equal-weight merges assumed; some performance trade-offs vs. per-domain experts; downstream spot-evaluation remains advisable
- Bold: RAG + instruction specialists merge for enterprise search
- Description: Merge instruction-following and RAG specialists to improve retrieval-augmented answering without retraining multi-task models.
- Sectors: Information retrieval, enterprise search, compliance knowledge bases
- Tools/workflows: Probe-set construction from typical query distributions; similarity-feature caching per checkpoint; periodic recomposition as new RAG specialists are added
- Assumptions/Dependencies: RAG tasks require representative probes (queries and contexts); care with data privacy in probe selection; retrieval stack remains unchanged
- Bold: Continuous task onboarding via bandit SimMerge
- Description: Use the contextual bandit variant to select merge operators online when new tasks/models appear, reducing regret vs. random choice and avoiding full retraining.
- Sectors: MLOps, platform teams
- Tools/workflows: Neural-linear bandit on top of learned features; warm-start from logged pairwise merges; LinTS policy for online adaptation under partial feedback
- Assumptions/Dependencies: Logged full-information pairwise data available; limited operator set; partial-feedback regime (no counterfactuals); ongoing minimal downstream evaluation for rewards
- Bold: Academic baseline composition for multi-task studies
- Description: Replace multi-task training with low-cost composition of domain experts to create strong baselines across math, code, multilingual, and RAG.
- Sectors: Academia, research labs
- Tools/workflows: Reproducible pipelines (MergeKit + SimMerge); probe sets derived from public benchmarks; macro-averaged reporting across tasks
- Assumptions/Dependencies: Shared base checkpoints; benchmark-aligned probe sets; published artifacts allow parameter merging and re-distribution
- Bold: Healthcare subdomain consolidation (clinical assistant)
- Description: Merge fine-tunes from subdomains (radiology report summarization, oncology QA, general clinical notes) into a single assistant to reduce model sprawl.
- Sectors: Healthcare
- Tools/workflows: De-identified, unlabeled probe sets per subdomain; strict audit of downstream performance; human-in-the-loop validation for safety-critical tasks
- Assumptions/Dependencies: Regulatory compliance (HIPAA/GDPR); domain shifts may require task encodings; safety and bias evaluation mandatory; legal permissions to merge checkpoints from different sources
- Bold: Multilingual tutor composition for education
- Description: Merge math-reasoning and multilingual understanding checkpoints to deliver a multilingual, step-by-step tutoring assistant.
- Sectors: Education
- Tools/workflows: Task encodings for language coverage; plan scorer to choose order (to avoid high interference); periodic recomposition as curricula evolve
- Assumptions/Dependencies: Representative probes per language and subject; careful evaluation for low-resource languages; maintaining consistency in pedagogy tone/style
- Bold: Finance coding assistant with domain QA
- Description: Combine code-generation specialists with financial QA models to support analytics scripting and compliance-aware explanations.
- Sectors: Finance, FinTech
- Tools/workflows: Probe sets from typical notebooks/queries; operator selection to balance reasoning and code robustness; governance checks for compliance and hallucination risks
- Assumptions/Dependencies: Proprietary data cannot be used for probes without safeguards; license compatibility; performance monitoring on high-stakes tasks
- Bold: Government/NGO low-compute composition
- Description: Resource-efficient way for agencies to compose vendor-provided checkpoints into a single model without large evaluation budgets.
- Sectors: Public sector, policy
- Tools/workflows: Lightweight similarity-feature pipelines; merge plan selection using unlabeled task probes; minimal downstream validation
- Assumptions/Dependencies: IP/contractual rights to merge; clear documentation and audit trails; conservative deployment with staged rollouts
- Bold: On-device/edge assistant consolidation
- Description: Merge small specialized models (home automation, calendar, shopping) into a single on-device assistant to reduce memory and update complexity.
- Sectors: Consumer apps, IoT
- Tools/workflows: Tiny probe sets reflecting local usage; compute-efficient feature extraction; offline merge execution before OTA updates
- Assumptions/Dependencies: Shared base architecture across small models; memory constraints favor equal-weight merges; careful privacy handling for probes
Long-Term Applications
The following applications are feasible but require further research, scaling, or development, such as broader operator support, multi-modal generalization, safety instrumentation, and governance frameworks.
- Bold: AutoMerge platform integrated with model registries and orchestration
- Description: End-to-end “Merge as a Service” that scores candidate plans, selects orders/operators, manages probe sets, and produces versioned composite artifacts with lineage.
- Sectors: Software platforms, cloud AI
- Tools/products: Registry plugins (MLflow, Hugging Face Hub), UI for plan scoring, lineage tracking, cost/performance trade-off dashboards
- Assumptions/Dependencies: Rich operator catalogs (EMR, ZipIt, TIES variants), scalable feature caching, robust metric propagation for intermediate merges, enterprise-grade observability
- Bold: Federated and cross-organization model composition
- Description: Compose models across institutions (e.g., hospital consortiums, educational cooperatives) without sharing raw data, using agreed probe protocols.
- Sectors: Healthcare, education, public sector
- Tools/products: Privacy-preserving probe exchange, audit logs, differential privacy for probe outputs, secure parameter-space composition
- Assumptions/Dependencies: Legal frameworks for cross-entity parameter merging; privacy guarantees; alignment of base architectures; governance over attribution and liability
- Bold: Safety-aligned composition (capability + alignment specialists)
- Description: Merge capability experts with safety/alignment-tuned checkpoints while preserving guardrails, using similarity signals and safety-specific features.
- Sectors: All regulated domains
- Tools/products: Safety-aware plan scorer (features for toxicity, jailbreak resistance), evaluation harnesses for red-teaming, policy-driven merge approvals
- Assumptions/Dependencies: New similarity channels capturing safety metrics; formal risk thresholds; cross-domain validation; potential need for non-equal mixing or layer-selective merges
- Bold: Multi-modal expansion (vision, speech, action) of similarity-driven merging
- Description: Extend SimMerge to VLMs and speech models with modality-specific similarity features and operators.
- Sectors: Robotics, accessibility tech, media
- Tools/products: Modality-aware probe sets (images, audio), multi-modal feature encoders, operator generalizations beyond LLMs
- Assumptions/Dependencies: Research on cross-modal parameter alignment, permutation matching, and functional metrics; careful treatment of attention patterns across modalities
- Bold: Robotics policy and language-conditioned controller composition
- Description: Compose task-specific policies or language-conditioned controllers to expand skill repertoires without full multi-task retraining.
- Sectors: Robotics, industrial automation
- Tools/products: Policy-feature analogs (trajectory divergence, activation similarity), safe merge validators, sim-to-real test benches
- Assumptions/Dependencies: Operators and features adapted to policy networks; safety constraints (collision, compliance); verified order selection to avoid catastrophic interference
- Bold: Energy and climate forecasting model composition
- Description: Merge domain forecasters (demand, weather, grid operations) to improve holistic planning and anomaly handling.
- Sectors: Energy, utilities
- Tools/products: Time-series probes, cross-model feature channels; cost-aware plan selection to meet latency and memory budgets
- Assumptions/Dependencies: Extend similarity signals to time-series architectures; new operators for non-LLM models; strong validation on rare-event regimes
- Bold: Cost/latency-aware merge planning for production SLAs
- Description: Integrate resource constraints into plan scoring to choose merges that optimize accuracy and runtime/memory for specific deployment targets (edge vs. cloud).
- Sectors: Cloud, mobile, IoT
- Tools/products: Multi-objective plan scorer (accuracy, memory, latency), hardware-aware operators, deployment profilers
- Assumptions/Dependencies: Accurate cost models; operator-level performance profiles; potential non-equal α tuning; CI pipelines for A/B validation
- Bold: Governance, audit, and IP policy for composed models
- Description: Establish standards to document derivations, licenses, data-use constraints, and safety attestations for merged checkpoints.
- Sectors: Policy, legal, compliance
- Tools/products: Model lineage watermarks, license compatibility checkers, audit trails, conformance tests
- Assumptions/Dependencies: Consensus on attribution norms; tooling to track provenance through weight-space merges; sector-specific regulations (e.g., medical device AI)
- Bold: District-/enterprise-scale education assistants across curricula
- Description: Maintain hundreds of curriculum-specific fine-tunes and compose them into unified assistants per grade/subject with controlled interference via optimized orders.
- Sectors: Education
- Tools/products: Curriculum-aware probe libraries, plan selection services, teacher-in-the-loop evaluation portals
- Assumptions/Dependencies: Scaling plan scorer to large K; improved metric propagation; continual monitoring for pedagogical consistency and bias
- Bold: Regulatory validation pipelines for safety-critical domains
- Description: Formalize pre-merge similarity thresholds and post-merge validation protocols as risk indicators and certification steps.
- Sectors: Healthcare, finance, aviation
- Tools/products: Validation suites mapping similarity scores to expected risk, standardized reporting, external certification hooks
- Assumptions/Dependencies: Empirical links between similarity signals and failure modes; sector standards; independent auditing capacity
- Bold: Training pipeline re-architecture (compose instead of multi-task train)
- Description: Adopt merge-centric model development: train domain experts, then compose at scale to ship variants per market/task without re-training monoliths.
- Sectors: AI product companies, platforms
- Tools/products: AutoMerge schedulers, operator catalogs, routine recomposition workflows, artifact management and rollback
- Assumptions/Dependencies: Robustness under frequent recomposition; improved operators (associativity, interference control); systematic probe maintenance as tasks evolve
Notes on general feasibility:
- SimMerge currently assumes shared pretrained bases and architectures, equal-weight merges, and a fixed operator set; extensions may require new operators, non-equal mixing, or layer-selective strategies.
- Unlabeled probe sets are critical; their representativeness and privacy/safety implications must be addressed per domain.
- Non-associativity makes order selection central; multiway scoring relies on metric propagation approximations that should be validated in edge cases.
- Even with prediction-based selection, minimal downstream evaluation is recommended for high-stakes deployments.
Glossary
- Adam optimization: A gradient-based optimizer that adapts learning rates per parameter using estimates of first and second moments. "We use a two-layer network with ReLU activations and Adam optimization."
- Attention patterns: The structures of attention weights in transformer models that indicate how tokens attend to each other. "cosine similarity of weights and attention patterns"
- Auxiliary model: A checkpoint not fine-tuned on the target task, merged to broaden capabilities. "We refer to any model that is not fine-tuned on t as an auxiliary (off-domain) model for task t."
- Bayesian linear regression: A probabilistic linear model that maintains a posterior distribution over parameters, updated with observed data. "a Gaussian posterior maintained via Bayesian linear regression."
- Cauchy-Schwarz: An inequality in inner-product spaces used to bound similarities. "bounds derived from Cauchy-Schwarz."
- Context vector: The feature representation describing a merge step for decision-making. "We observe a context vector derived from pre-merge similarity features."
- Contextual bandit: A learning framework where an agent chooses actions based on context and observes only the chosen action’s reward. "We develop an online variant based on a contextual bandit that updates under partial feedback"
- Convexity: A property of functions or sets used to derive bounds and mixtures. "convexity of -divergences yields upper bounds"
- Cosine similarity: A measure of angle-based similarity between vectors (e.g., weights or activations). "cosine similarities between intermediate activations and "
- Counterfactual rewards: The unobserved rewards of actions not taken in bandit settings. "counterfactual rewards for unchosen operators are not observed."
- Cross-entropy loss: A classification loss measuring the divergence between predicted and true distributions. "and is trained with a cross-entropy loss to predict ."
- Distribution shift: A change in data or task distribution between training and deployment. "we introduce a distribution shift by adding a checkpoint trained on a different task that did not appear in the logged data."
- Exact match: An evaluation metric where predictions must exactly match the ground truth. "Math is evaluated on MATH and GSM8K using exact match."
- Equal-weight mixture: A combination of models or distributions with uniform mixing coefficients. "we treat the intermediate model as an equal-weight mixture of its two parents on the probe set"
- Euclidean distance: The L2 norm distance between parameter vectors. "Euclidean distance "
- f-divergences: A family of divergences measuring differences between probability distributions. "convexity of -divergences yields upper bounds"
- GapClosed: A normalized metric indicating how much of the expert–auxiliary gap a merge recovers. "reported in terms of GapClosed."
- Instruction-following: Tasks where models must comply with natural-language instructions. "In the instruction-following setting used for the bandit experiments, we report scores on IFEval"
- Kullback–Leibler divergence: A measure of how one probability distribution diverges from another. "including the Kullback-Leibler divergence $D_{\mathrm{KL}(p_a \,\|\, p_b)$ between predictive distributions"
- Layerwise: Operating per model layer rather than on the whole parameter vector at once. "We work with layerwise binary merge operators indexed by ."
- LinTS: Linear Thompson sampling; a Bayesian bandit algorithm that samples from arm posteriors to balance exploration and exploitation. "We consider both LinUCB and linear Thompson sampling (LinTS)"
- LinUCB: A linear upper-confidence-bound bandit algorithm that selects actions by optimistic estimates over uncertainty. "We consider both LinUCB and linear Thompson sampling (LinTS)"
- Logits: Pre-softmax model outputs representing unnormalized log probabilities. "KL divergence between model logits, cosine similarity of weights and attention patterns"
- Macro-averaging: Averaging metrics equally across tasks or classes to produce a single aggregate score. "using macro-averaging over ."
- Merge-and-evaluate search: An empirical procedure that tries many merge configurations and evaluates each downstream. "run expensive merge-and-evaluate searches to select the best merge."
- Merge operator: A rule that combines two models’ parameters into merged parameters. "Common merge operators are not associative"
- Merge order: The sequence in which models are merged, affecting non-associative operators’ outcomes. "For the merge order affects the result"
- Merge plan: An ordered sequence describing a k-way merge’s steps and operators. "a -way merge plan is an ordered sequence"
- MLP: Multi-layer perceptron; a feedforward neural network used for scoring or classification. "In practice $f_{\mathrm{plan}$ is an MLP"
- Multiway merging: Merging more than two models in sequence (e.g., 3-way, 4-way). "Predictive selection is especially valuable for multiway merging"
- Neural-linear: A bandit architecture combining neural feature maps with linear posterior models for arms. "We adopt a neural-linear design."
- Non-associative: An operation where grouping changes the result, so order matters. "Common merge operators are not associative"
- Oracle policy: An idealized policy that always picks the best action with full information. "an oracle that, for each round, plays the best operator in hindsight given full knowledge of all utilities."
- Parameter averaging: Combining model parameters by averaging, often used to merge checkpoints. "Early approaches such as simple parameter averaging and related weight-space operations"
- Parameter space: The high-dimensional space of model parameters in which merging operates. "composing models in parameter space"
- Pass@1: A code-generation metric measuring if the first attempt passes unit tests. "Code generation is evaluated with pass@1 on HumanEval_Python and MBPP+ benchmark"
- Permutation alignment: Aligning neuron permutations across models to facilitate merging. "subspace matching and permutation alignment"
- Probe set: A small unlabeled dataset drawn from a task’s input distribution used to compute similarity features. "we draw an unlabeled probe set "
- Probe tokens: The number of tokens in probe inputs used to compute functional similarity. "we use only 10000 probe tokens per task"
- RAG: Retrieval-augmented generation; models use external documents retrieved at inference to produce answers. "across multilingual, code, math, and RAG"
- Rank-one updates: Efficient posterior updates using low-rank corrections in Bayesian linear models. "posterior updates can be done with rank-one updates in time per round"
- ReLU activations: Rectified Linear Unit nonlinearity used in neural networks. "We use a two-layer network with ReLU activations"
- Regret: The performance difference between the learner and an oracle over time. "minimizes regret with respect to an oracle"
- Reward: The scalar utility observed after selecting a merge operator in bandit rounds. "observe a scalar reward "
- Sign-consistent merge: A merging method that enforces consistent weight signs across models. "Ties (trim, elect sign and merge) is a sign-consistent merge."
- SLERP: Spherical linear interpolation; merges parameters along a geodesic on a hypersphere. "spherical linear interpolation (SLERP)"
- Subspace matching: Aligning representational subspaces across models to enable more reliable merging. "subspace matching and permutation alignment"
- Task-agnostic: Methods or features not tailored to a specific task, usable across tasks. "task-agnostic similarity measurements"
- Thompson sampling: A Bayesian bandit strategy that samples from the posterior to select actions. "We consider both LinUCB and linear Thompson sampling (LinTS)"
- TIES merging: A merge operator that trims, elects a sign, and merges to reduce interference. "SimMerge selects among linear interpolation, spherical linear interpolation (SLERP), and TIES merging."
- Triangle inequality: A norm property used to bound distances when propagating metrics. "the triangle inequality gives"
- Unlabeled probes: Data without ground-truth labels used to compute pre-merge similarity signals. "From a small set of unlabeled probes"
- Warm-start: Initializing model parameters or posteriors using pre-collected data before online adaptation. "We initialize and warm-start it using the logged pairwise data"
- Weight-based measures: Similarity metrics computed directly on model parameters rather than outputs. "We then compute weight-based measures that compare models directly in parameter space"
- Win-rate: An evaluation metric indicating the percentage of test cases where a model’s output is judged better. "using win-rates and accuracy."
Collections
Sign up for free to add this paper to one or more collections.