- The paper introduces Coconut, a continuous latent reasoning paradigm replacing token-level CoT with iterative hidden state updates.
- It employs a multi-stage curriculum that gradually shifts from language supervision to latent reasoning, reducing hallucinations and enhancing accuracy.
- Empirical evaluations on ProsQA and GSM8k demonstrate improved planning and search efficiency through latent BFS dynamics and adaptive computation.
Training LLMs to Reason in a Continuous Latent Space
Introduction and Motivation
Current reasoning paradigms in LLMs primarily rely on autoregressive generation in the language token space, typified by Chain-of-Thought (CoT) prompting. However, linguistic reasoning is fundamentally constrained by the granularity and structure of natural language, where most tokens ensure textual coherence rather than facilitate true intermediate computation. Inspired by neurocognitive evidence that reasoning and language are neurally dissociated, this paper introduces a new reasoning paradigm wherein LLMs operate in continuous latent space rather than word token space, termed Chain of Continuous Thought (Coconut).
Coconut proposes using the hidden state representations—a "continuous thought"—as direct reasoning states. These representations are iteratively fed back to the model, enabling non-linguistic, differentiable latent reasoning. Contrary to classical CoT's strictly sequential, token-level reasoning, continuous thoughts can encode multiple potential next steps simultaneously, supporting implicit breadth-first search (BFS) behaviors and evading the greedy commitment pathologies endemic to linguistic reasoning.
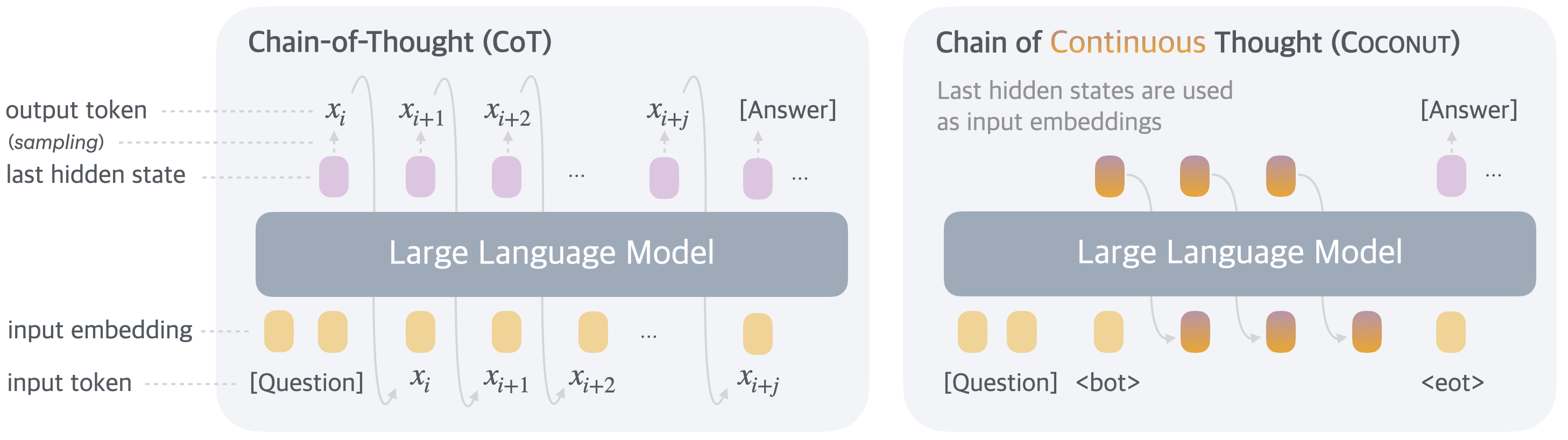
Figure 1: Chain of Continuous Thought (Coconut) reasons by propagating hidden state vectors, in contrast to CoT’s sequential token emission.
Coconut Architecture and Training
Coconut extends standard generative transformer architectures with a bi-modal operation: language mode (standard autoregressive text generation) and latent mode (reasoning via hidden state recurrence). Special <bot> and <eot> tokens mark transitions between these modes. While in latent mode, the model's input at time t is the prior hidden state ht−1, removing the language output head and vocabulary bottleneck from the inner reasoning loop.
Training is conducted in a multi-stage curriculum inspired by knowledge distillation and chain "internalization." Early training stages bias toward language-targeted supervision; subsequent stages replace increasing numbers of language reasoning steps with continuous thoughts. The cross-entropy objective is masked over latent thoughts, ensuring supervision is only applied to language regions. This approach prevents degenerate compression and incentivizes the construction of effective, predictive continuous representations, not mere text reconstructions.
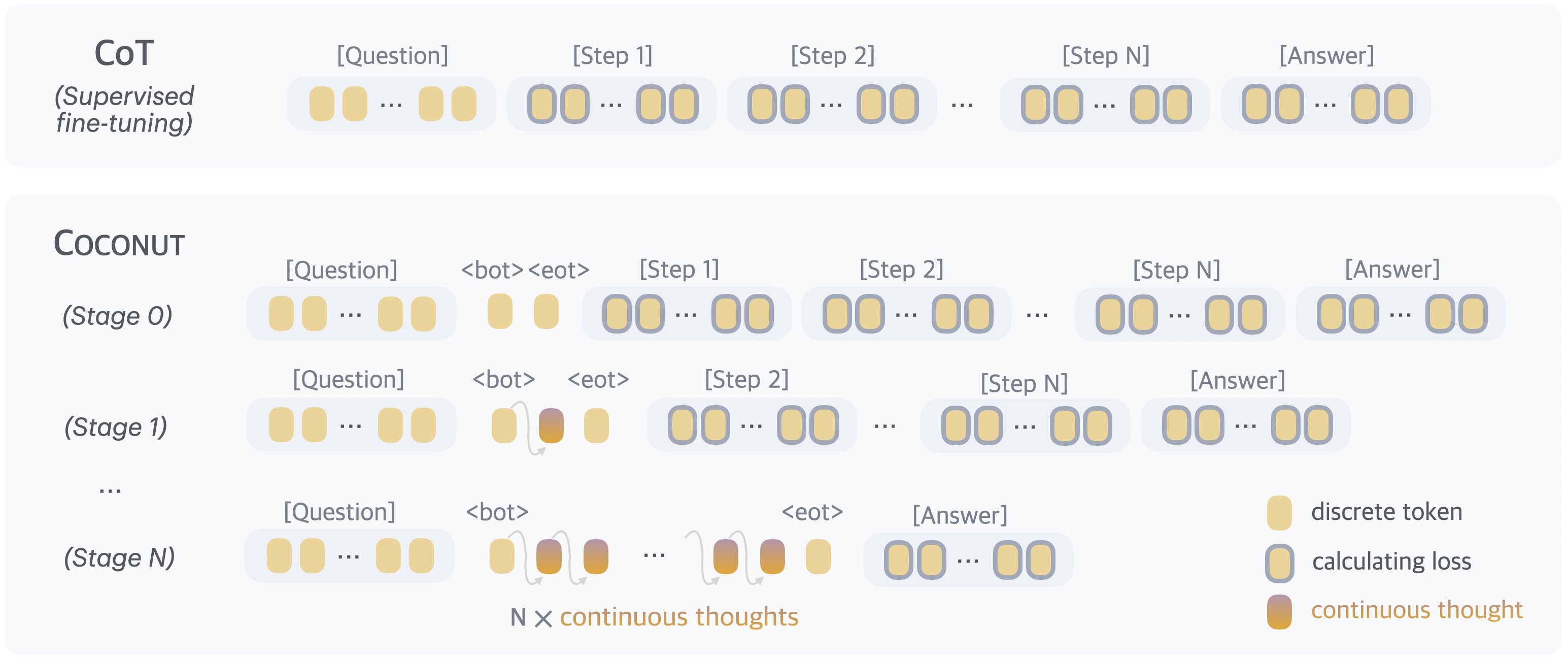
Figure 2: Schematic of the Coconut training procedure, where language steps are replaced progressively by continuous thoughts and loss computed only on remaining tokens.
During inference, Coconut supports both fixed-length latent reasoning and termination via a learned binary classifier on latent states. Integration with established prompting and decoding heuristics is seamless.
Latent Reasoning and Emergent Planning Behavior
To evaluate Coconut, the authors design ProsQA, a domain-agnostic logical reasoning task based on directed acyclic graphs (DAGs) that require planning and search to connect entities and concepts. ProsQA is more challenging than existing benchmarks as it explicitly penalizes greedy or myopic search strategies and necessitates sophisticated path exploration.
Empirical results on ProsQA demonstrate that traditional CoT often hallucinates non-existent paths or gets irrecoverably trapped after local errors. Coconut, in contrast, substantially reduces hallucinations and wrong-target errors as more reasoning is shifted to latent space. Notably, answer accuracy improves monotonically with the use of additional continuous thoughts, underscoring the efficiency and expressivity of continuous-space reasoning.
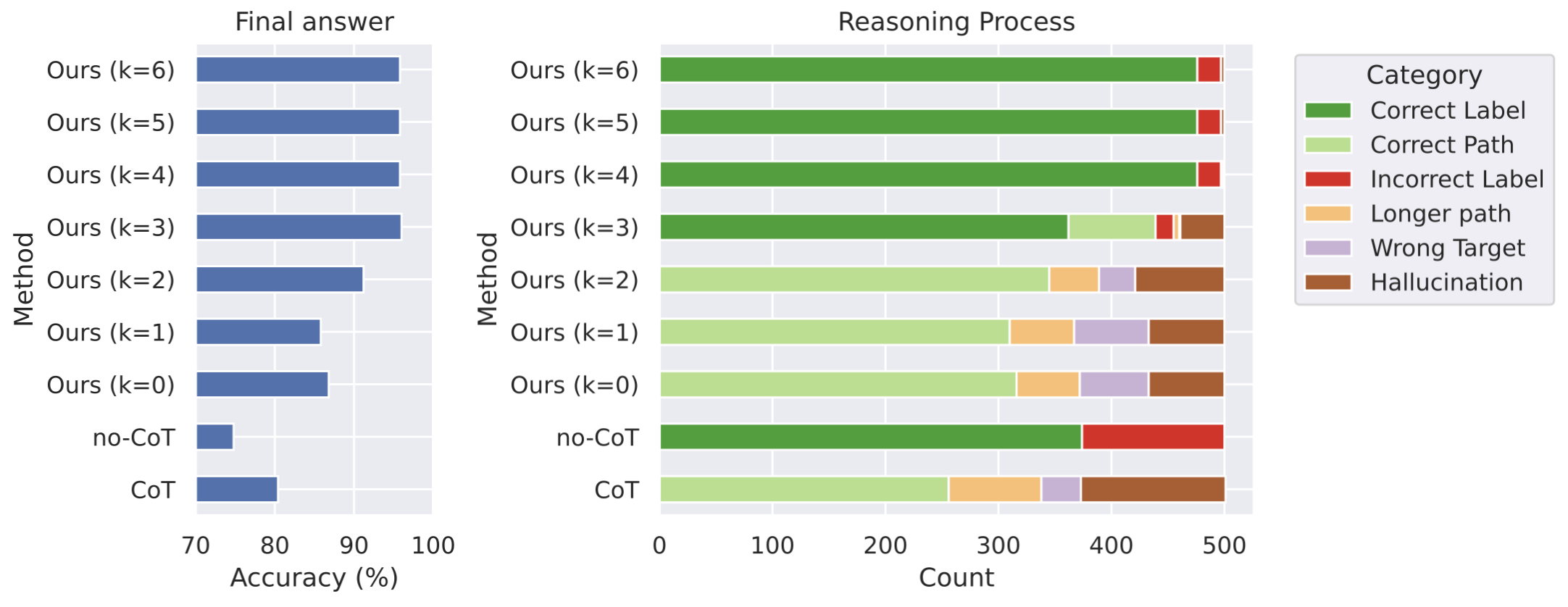
Figure 3: Coconut with increasing reasoning in latent space outperforms CoT on final and intermediate reasoning accuracy on ProsQA; hallucinations are reduced.
A detailed case analysis shows that Coconut enables the model to avoid premature path commitments and instead backtracks or explores alternative paths when necessary—behavior impossible in strict token-level CoT inference.
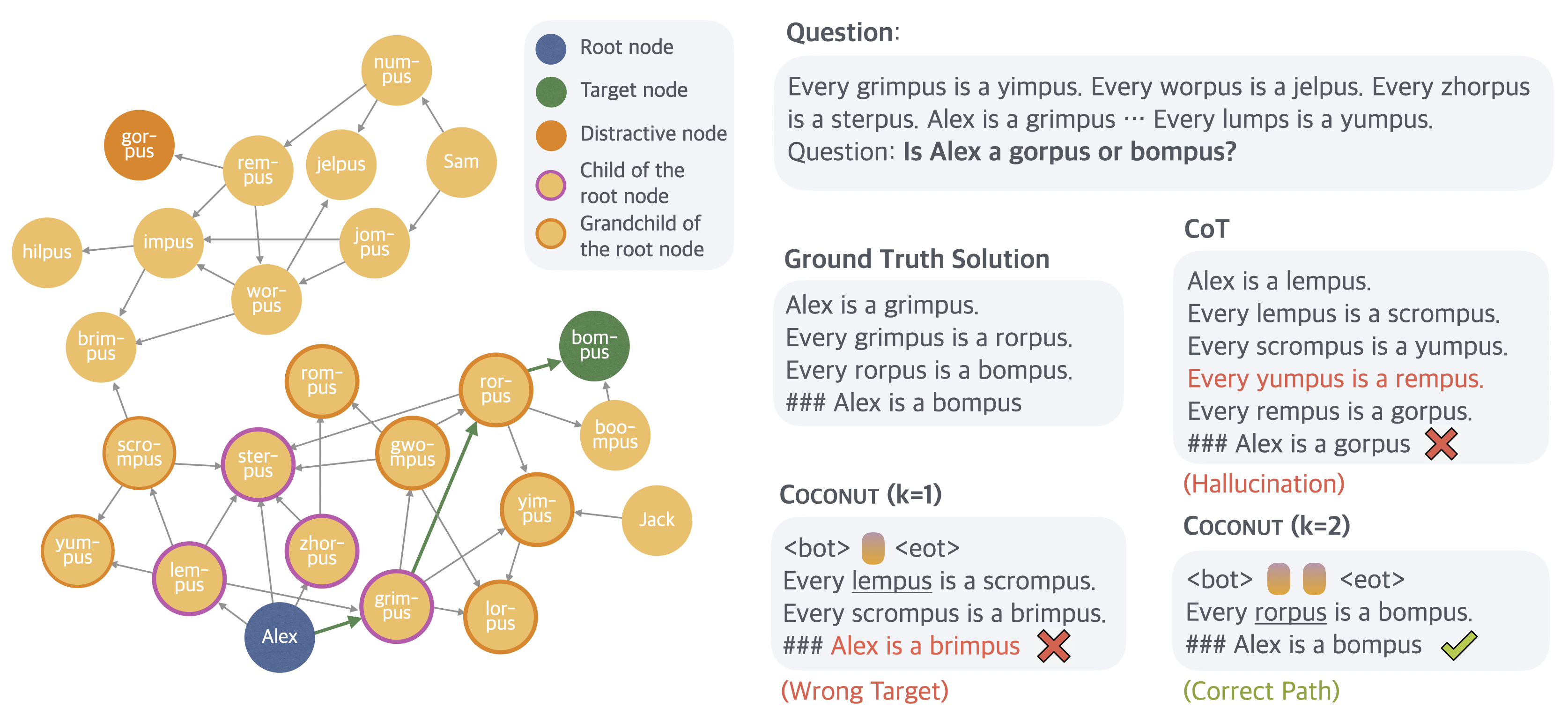
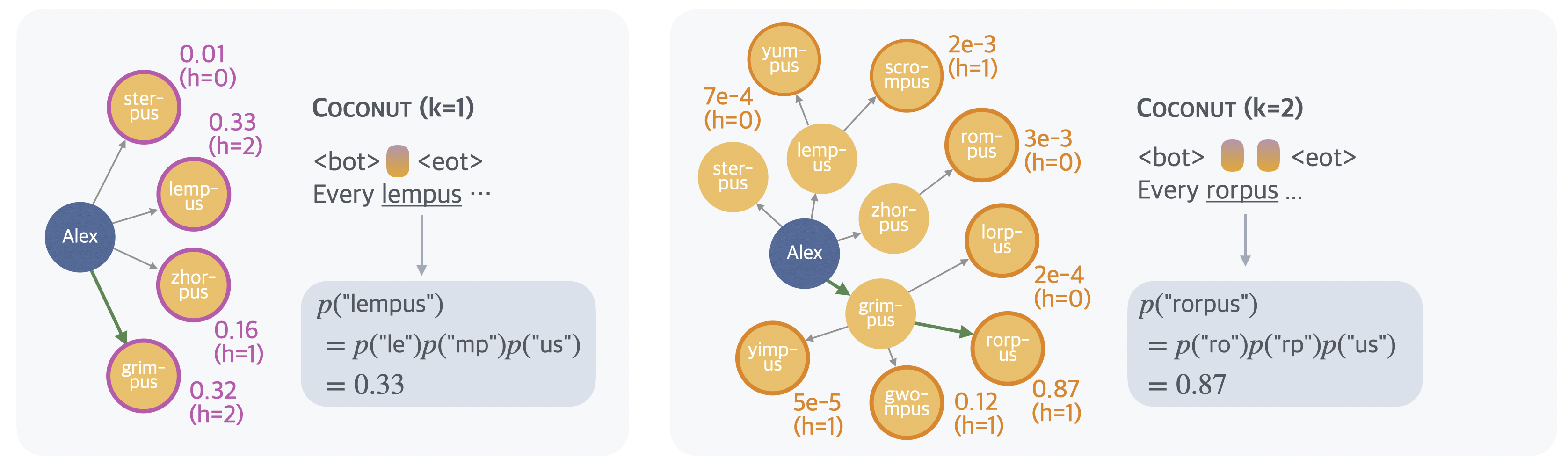
Figure 4: In-depth comparison: CoT gets stuck and hallucinates, while Coconut with appropriate reasoning depth converges to the correct solution.
Further analysis of the model’s behavior postulates a latent BFS dynamic. By "decoding" the hidden states after each continuous thought (by probing the next likely language token), it is observed that continuous thoughts in early steps encode distributions over multiple candidate paths, whose diversity collapses as more latent reasoning steps are taken.
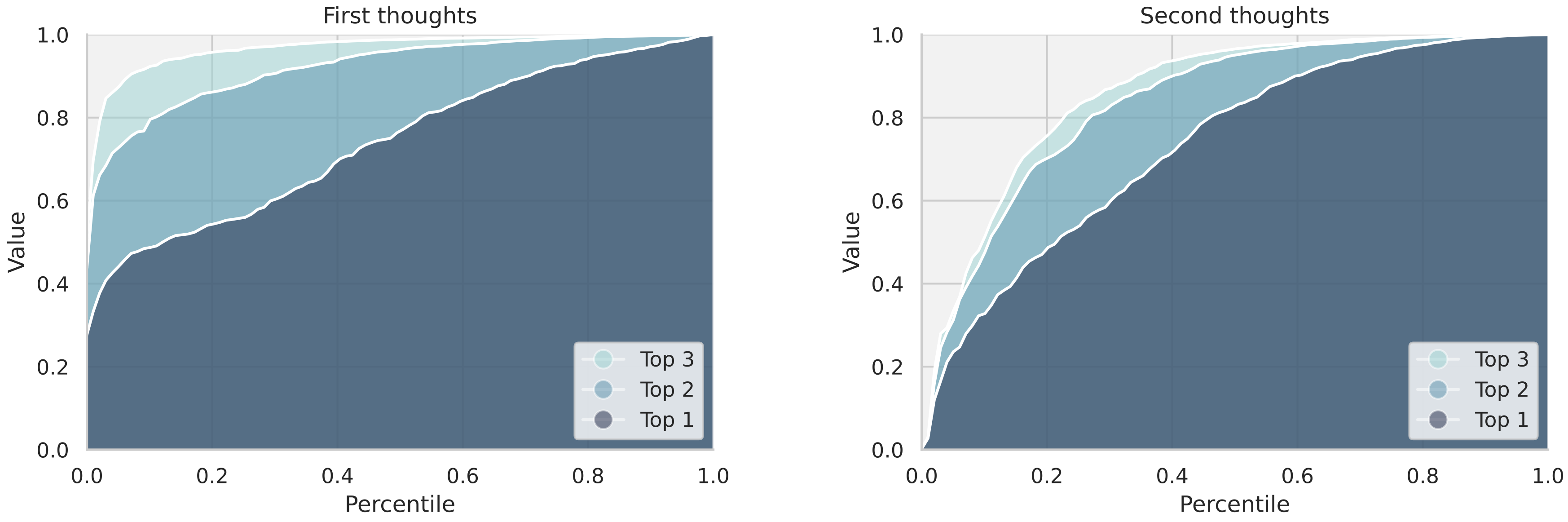
Figure 5: Cumulative value distribution over top candidate nodes shows that the model maintains broader uncertainty (exploration) initially, collapsing as reasoning proceeds.
This emergent balancing act between exploration and focus is an essential property for generalizable planning and suggests latent state recurrence as an effective search mechanism.
Empirical Evaluation and Efficiency
Extensive evaluation of Coconut on GSM8k (mathematical reasoning), ProntoQA, and ProsQA reveals strong task-level benefits. On ProsQA, Coconut achieves a substantial increase in answer accuracy and reasoning path fidelity using fewer language tokens than vanilla CoT, showing a more efficient allocation of compute to semantically substantive reasoning steps.
Moreover, models trained without multi-stage curricula or language-based scaffolding do not match CoT or curriculum-based Coconut performance. The supervision transition strategy is critical for successful latent reasoning induction. Pause token-based baselines or architectures with fixed intermediate computation allocation, such as iCoT, underperform relative to Coconut’s continuous latent reasoning, highlighting the importance of representational flexibility.
Empirically, Coconut exhibits strong test-time scaling, with increased depth (number of latent thoughts per step) monotonically improving task performance. Clock-time and token budget analyses show Coconut delivers better accuracy-efficiency tradeoffs compared to long-form CoT reasoning, particularly for tasks demanding substantial intermediate computation.
Implications and Future Directions
Coconut reframes LLM reasoning as a differentiable latent-space process, enabling behaviors (such as parallel search and late commitment) fundamentally inaccessible to standard CoT paradigms. This work implies that the intrinsic reasoning capabilities of LLMs are currently bottlenecked by linguistic generation constraints, and that unbinding inner reasoning from language tokens provides both theoretical and practical improvements for complex search and planning tasks.
The observed superposition principle, where continuous thoughts encode multiple alternative explorations, is substantiated by theoretical follow-up work demonstrating exponential efficiency gains for certain classes of problems. Coconut also points to promising directions for test-time compute allocation and dynamic adaptive depth.
Further advancements are needed to generalize latent reasoning induction beyond finetuning and curriculum-supervised settings, especially toward robust pretraining strategies that internalize search and planning dynamics at scale. Integration with other latent-space modeling and more generalized BFS/DFS-style computation modules is a natural direction. The alignment of latent reasoning with interpretability, faithfulness, and controllability in LLMs also warrants further investigation.
Conclusion
Coconut demonstrates that LLMs equipped with continuous latent space reasoning exhibit superior planning, search, and computation capabilities compared to classical language-based CoT. By leveraging hidden state recurrence and multi-stage curriculum training, models achieve improved efficiency, accuracy, and expressivity, especially on tasks requiring substantial search. These findings chart a course for reimagining LLM reasoning systems not as sequence generators but as planners and searchers over latent computational graphs, with substantial implications for both AI system design and cognitive modeling.

