- The paper introduces CLIMP, a fully Mamba-based framework replacing transformers to achieve sub-quadratic complexity in processing both images and text.
- It demonstrates superior retrieval performance with enhanced alignment, reduced hubness, and improved OOD robustness across various benchmarks.
- Empirical results show that CLIMP scales efficiently to high-resolution images and extended textual sequences while reducing memory overhead and FLOPs.
Contrastive Language-Image Mamba Pretraining: CLIMP Architecture and Empirical Analysis
Introduction and Motivation
The paper "CLIMP: Contrastive Language-Image Mamba Pretraining" (2601.06891) introduces CLIMP, a vision-LLM that leverages state-space models (SSMs)—specifically Mamba—for both image and text encoding, supplanting the conventional Transformer architecture in this domain. The motivation derives from two key challenges faced by transformer-based CLIP models: quadratic complexity in sequence length (impeding scalability with high-resolution images), and vulnerability to spurious feature correlations in self-attention, resulting in suboptimal robustness under distribution shift and limitations in handling variable input lengths.
CLIMP integrates VMamba as the vision backbone and Mamba-1/Mamba-2 LLMs as the text tower, instantiating a fully SSM-based framework. The SSM paradigm, with selective state updates and sequential aggregation, brings critical advantages: sub-quadratic scaling (O(L) vs O(L2) for Transformers), native support for arbitrary input resolutions, and improved inductive biases favoring spatial locality and smoothness—attributes that directly impact sample efficiency and cross-modal retrieval performance.
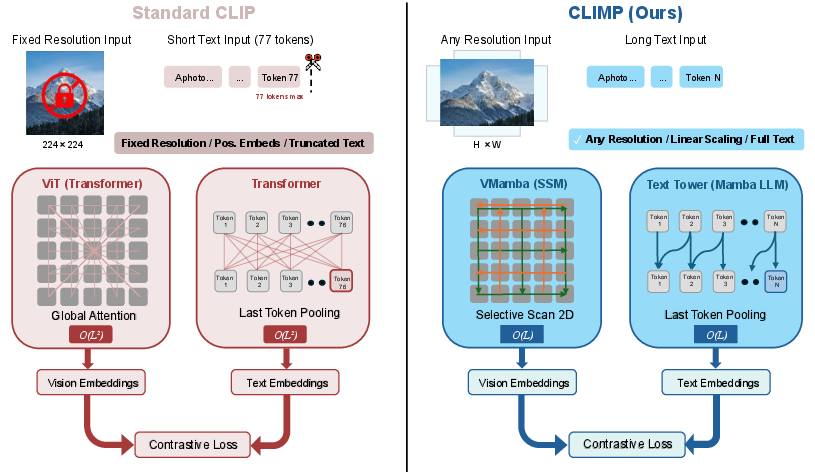
Figure 1: CLIP vs. CLIMP. By replacing Transformer encoders with Mamba-based models, CLIMP achieves sub-quadratic O(L) complexity instead of quadratic O(L2), while removing the fixed resolution and 77-token text limitations inherent to standard CLIP.
Model Architecture
CLIMP's architecture follows CLIP's dual-encoder paradigm, with both towers based on Mamba SSMs. VMamba processes image patches in four spatial traversals using the SS2D module, obtaining hierarchical features mapped into a joint multimodal embedding via learned projections. This yields an encoder with strong spatial inductive bias and linear complexity w.r.t. resolution, natively supporting high-resolution inputs and obviating the need for specialized positional encodings or patch-size augmentation strategies required by ViT-based variants.
The text encoder employs pretrained Mamba LLMs with causal state aggregation and last-token pooling, overcoming the fixed-context window limitation of CLIP's Transformer (77 tokens) and supporting dense caption retrieval for extended textual inputs. The dual Mamba towers are aligned through contrastive learning using image-text pairs, establishing a shared embedding space.
Empirical Results and Key Claims
Retrieval and Classification
CLIMP demonstrates superior results on CLIP-Benchmark (31 tasks). Mamba-1 yields image recall@5 of 65.5% and text recall@5 of 77.0%, surpassing transformer baselines (e.g., RoPE-ViT achieves 63.4% and 72.9%, respectively). Top-1 classification accuracy with CLIMP-Mamba-1 is 29.6%, outperforming all transformer baselines by at least +2.3%. These gains are attributed to the SSM's representation geometry, reflected in improved alignment and reduced hubness in the multimodal embedding space.
Out-of-Distribution Robustness
CLIMP sets a strong precedent in OOD generalization, achieving top results on all five ImageNet variant benchmarks. On ImageNet-O, both CLIMP variants outperform OpenAI CLIP-ViT-B/16 by 7.5% on top-1 accuracy, with a smaller training dataset (CC12M vs LAION-2B), challenging the established notion that sheer data scale compensates for architectural inductive bias.
High-Resolution and Dense Captioning
Owing to linear memory and compute complexity, CLIMP scales to 896×896 input without accuracy degradation, while transformer models' performance collapses. Memory overhead is reduced by 5×, and FLOPs by 1.8× compared to ViT. For dense captioning retrieval, CLIMP handles captions averaging 134–142 tokens—well above CLIP's token limit—and maintains state-of-the-art retrieval accuracy, demonstrating versatility for tasks requiring extended text modeling.




Figure 2: Visualization of Image-Text similarity for the caption: "A large porch with a wooden fence and no roof." CLIMP (similarity: 0.545) produces spatially coherent attention focused on the porch and fence, while RoPE-ViT (0.501) and FlexViT (0.452) show scattered, less interpretable patterns. Warmer colors indicate higher similarity.
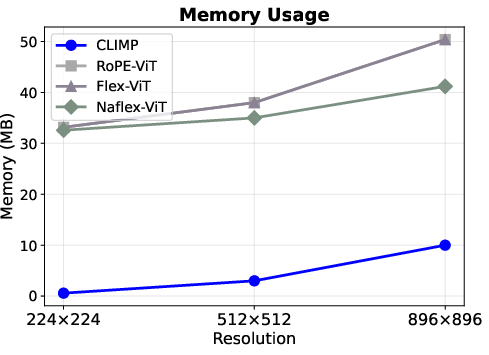
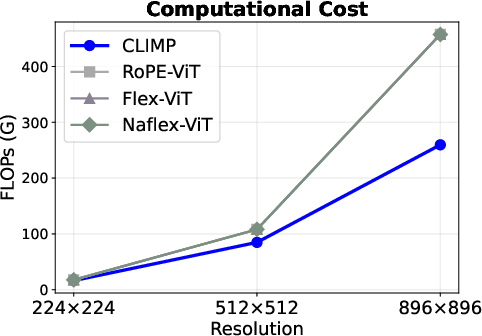
Figure 3: CLIMP achieves superior memory and computational efficiency across all resolutions. (Left) Memory overhead is 4–57× lower. (Right) FLOPs scale linearly, yielding up to 1.8× reduction—a gap that widens with resolution.
Analysis: Inductive Bias, Embedding Geometry, and Scaling Laws
VMamba's sequential scan mechanism induces a strong locality bias, encouraging sample-efficient learning, as verified in synthetic spatial distortion experiments. Embedding geometry analysis reveals CLIMP's embeddings are more uniformly distributed and less prone to hubness, yielding improved cross-modal retrieval, alignment, and OOD robustness relative to transformer-based encoders.
Scaling analysis further demonstrates unsaturated performance gains as the model and dataset size increase, suggesting that CLIMP's advantages persist and even amplify at higher scales.
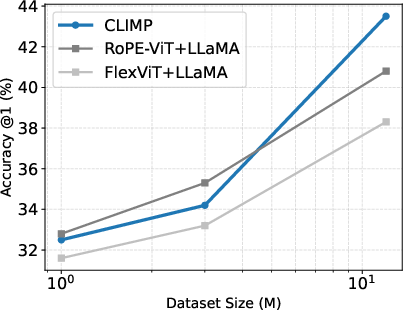
Figure 4: Scaling laws of CLIMP trained on CC dataset and evaluated on ImageNet-1K Acc@1. Performance improves consistently as training data scales from 1M to 12M samples.
Theoretical and Practical Implications
CLIMP advances the contrastive vision-language paradigm by demonstrating that state-space models are effective alternatives to transformers for high-resolution, long-context, and resource-constrained settings. The robustness benefits stem from architectural bias, not merely data scale, challenging conventions in model scaling. The ability to process high-resolution images and long textual sequences without auxiliary schemes or training transformations streamlines practical deployment in retrieval, dense captioning, and zero-shot classification.
Architectural ablations support the hypothesis of synergy between vision and language towers when both are SSMs, leading to more compatible cross-modal representations. These insights encourage exploration of further hybrid Mamba-transformer architectures and expansion to generative and agentic reasoning tasks.
Conclusion
CLIMP establishes fully Mamba-based state-space architectures as a compelling alternative to transformers for contrastive vision-language pretraining. Key findings include superior retrieval performance, OOD robustness even with limited data, memory and computational efficiency at scale, and flexibility for long-context and high-resolution applications. The architecture's spatial inductive bias and embedding geometry favor robust generalization, and scaling trends indicate continued dividends with increased model and corpus size. Theoretical advances and empirical validation inspire future research directions in multimodal AI, particularly in hybrid SSM-attention models and agentic systems.