Explainable AI: Learning from the Learners
Abstract: Artificial intelligence now outperforms humans in several scientific and engineering tasks, yet its internal representations often remain opaque. In this Perspective, we argue that explainable artificial intelligence (XAI), combined with causal reasoning, enables {\it learning from the learners}. Focusing on discovery, optimization and certification, we show how the combination of foundation models and explainability methods allows the extraction of causal mechanisms, guides robust design and control, and supports trust and accountability in high-stakes applications. We discuss challenges in faithfulness, generalization and usability of explanations, and propose XAI as a unifying framework for human-AI collaboration in science and engineering.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explainable AI: Learning from the Learners — A Simple Guide
Overview: What is this paper about?
This paper argues that we can make better science and engineering by learning from powerful AI systems—if we can understand how they think. That is what explainable AI (XAI) does: it turns black-box AI into something humans can inspect and reason about. By combining XAI with “cause-and-effect” thinking (causality), the authors show how AI can help us:
- discover new scientific rules,
- optimize designs and control systems,
- and certify that AI is safe and trustworthy for high-stakes uses.
The big questions the paper asks
In everyday terms, the paper explores:
- How can we peek inside advanced AI to see which pieces of information truly drive its decisions?
- How can that understanding help scientists discover real laws of nature (not just patterns)?
- How can it help engineers improve designs and control systems in a smarter, safer way?
- How can explanations make AI trustworthy enough for critical jobs—like airplanes, medicine, and climate forecasting?
- What are the pitfalls (like misleading “explanations”) and how do we avoid them?
How the research approach works (in plain language)
This is a “Perspective” paper: it brings together many recent ideas and tools into a clear, practical roadmap. Here are the key tools and what they mean:
- Explainability tools:
- SHAP: Imagine a team scoring goals. SHAP fairly splits credit among players. For AI, it splits “credit” among input features to show which ones mattered most.
- Integrated gradients and saliency maps: Like a heat map that highlights the most important pixels or regions that swayed the AI’s decision.
- Causality (cause-and-effect): Instead of just seeing patterns, we ask “what happens if we change X?” New tools can separate information into:
- Unique (only this piece matters),
- Redundant (several pieces say the same thing),
- Synergistic (pieces only matter together).
- This helps tell real causes from coincidences.
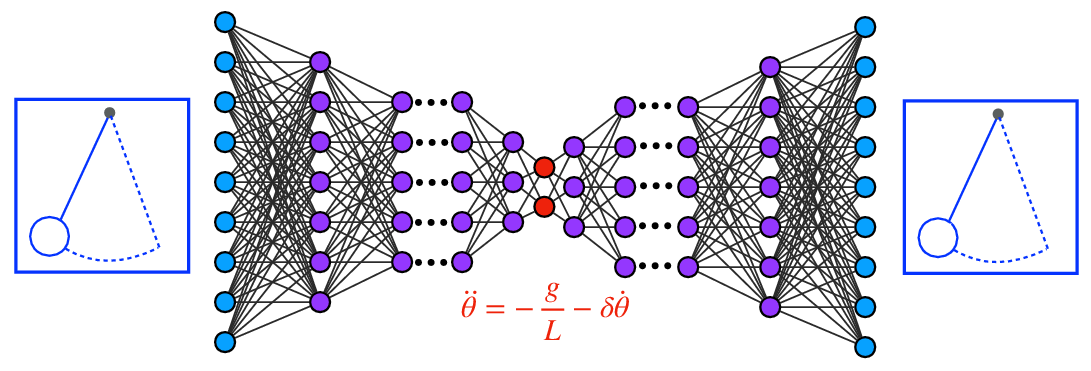
- Finding simple rules (symbolic regression and SINDy): These methods search data to discover short, human-readable equations—like rediscovering “F = m·a” from motion data. SINDy is a smart way to find the few terms that truly govern a system’s behavior.
- Autoencoders and “latent spaces”: Think of zipping a giant photo into a tiny file that still captures the essence. Autoencoders compress complex data into a few “hidden” numbers (latent variables) that act like better coordinates for understanding and prediction.
- Physics-aware AI: Some neural networks are built to respect physics (like energy conservation or symmetries), which makes them more trustworthy and easier to explain.
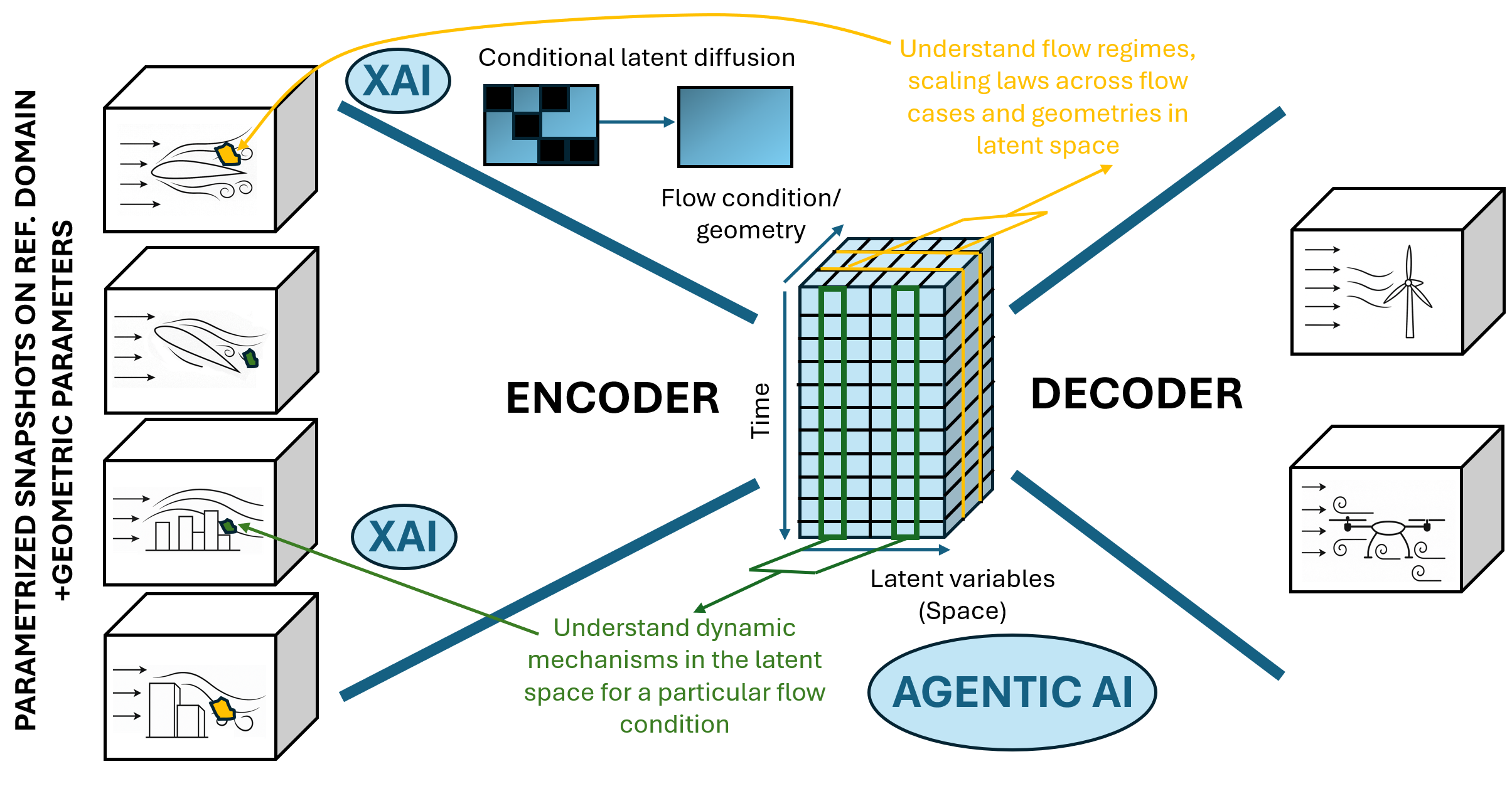
- Foundation models and agents: Big, general models (like ones that generate images or learn across many systems) can discover patterns at scale. Combined with explainability and AI “agents” that plan next steps, they can help automate parts of scientific discovery and design.
- Mapping from “AI-think” back to “human-think”: AI often solves problems in its own compressed language (latent space). Tools like SHAP help translate those hidden decisions back into real-world space (for example, showing which parts of a wing or flow field matter most).
Main takeaways and why they matter
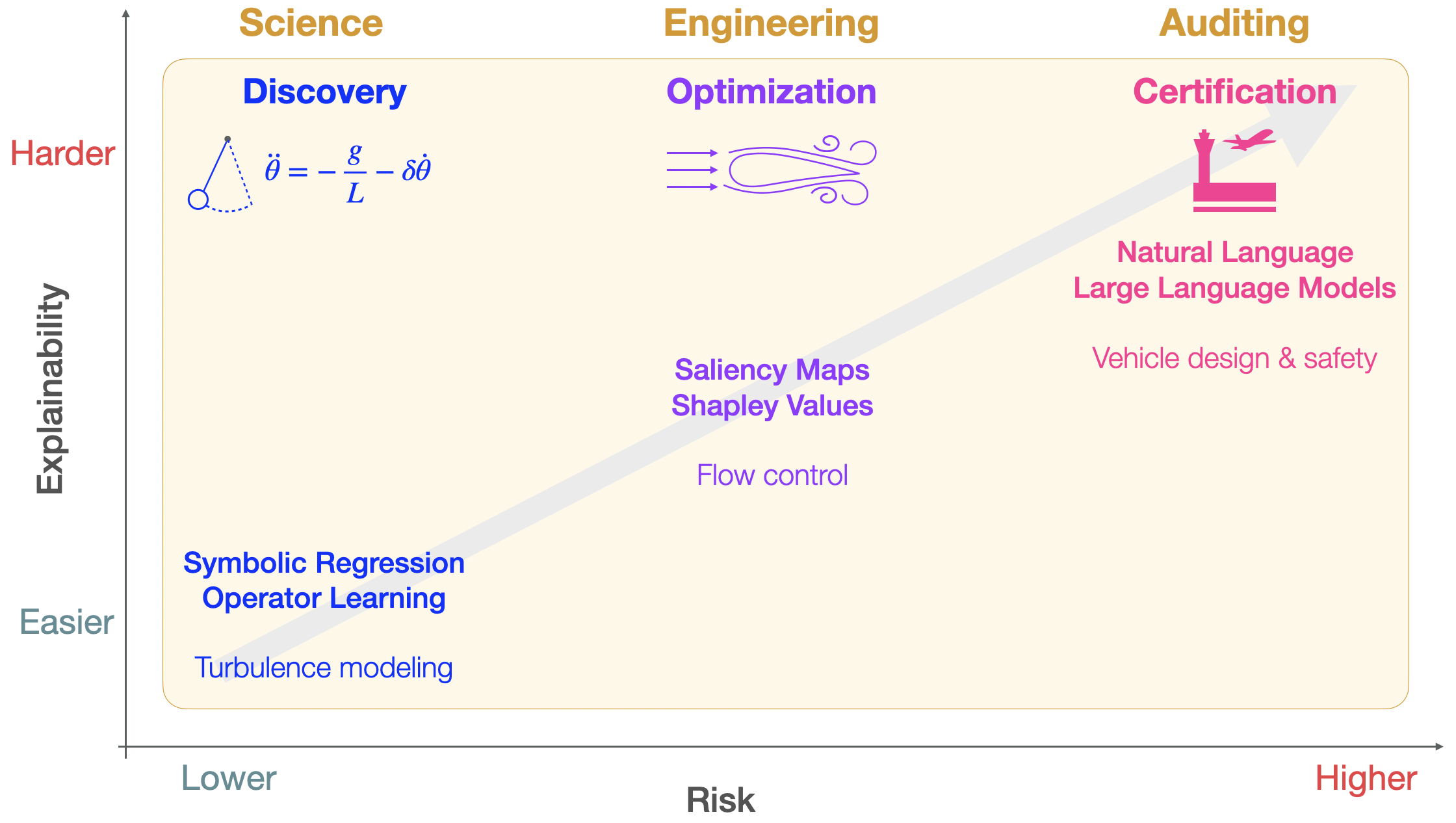
The paper focuses on three connected areas:
- Discovery (science):
- Goal: Find true, simple mechanisms—not just accurate predictions.
- How: Use explainable tools to uncover equations, symmetries, and the right coordinates for a system.
- Why it matters: Simple, causal rules generalize better to new situations and spark new scientific ideas.
- Example idea: An autoencoder can reduce a video of a swinging pendulum to two meaningful numbers (angle and speed), then a method like SINDy can learn the simple rule that governs its motion.
- Optimization (engineering and control):
- Goal: Improve designs and control decisions (like reducing drag on a car or stabilizing turbulent flow).
- How: Use SHAP and causal analysis to see which parts of a system actually cause performance changes.
- Why it matters: You can target the root causes, not just the symptoms. This often works better and is more robust.
- Example idea: Instead of just telling an AI to “minimize drag,” use explanations to identify and weaken the specific flow structures that cause the drag in the first place.
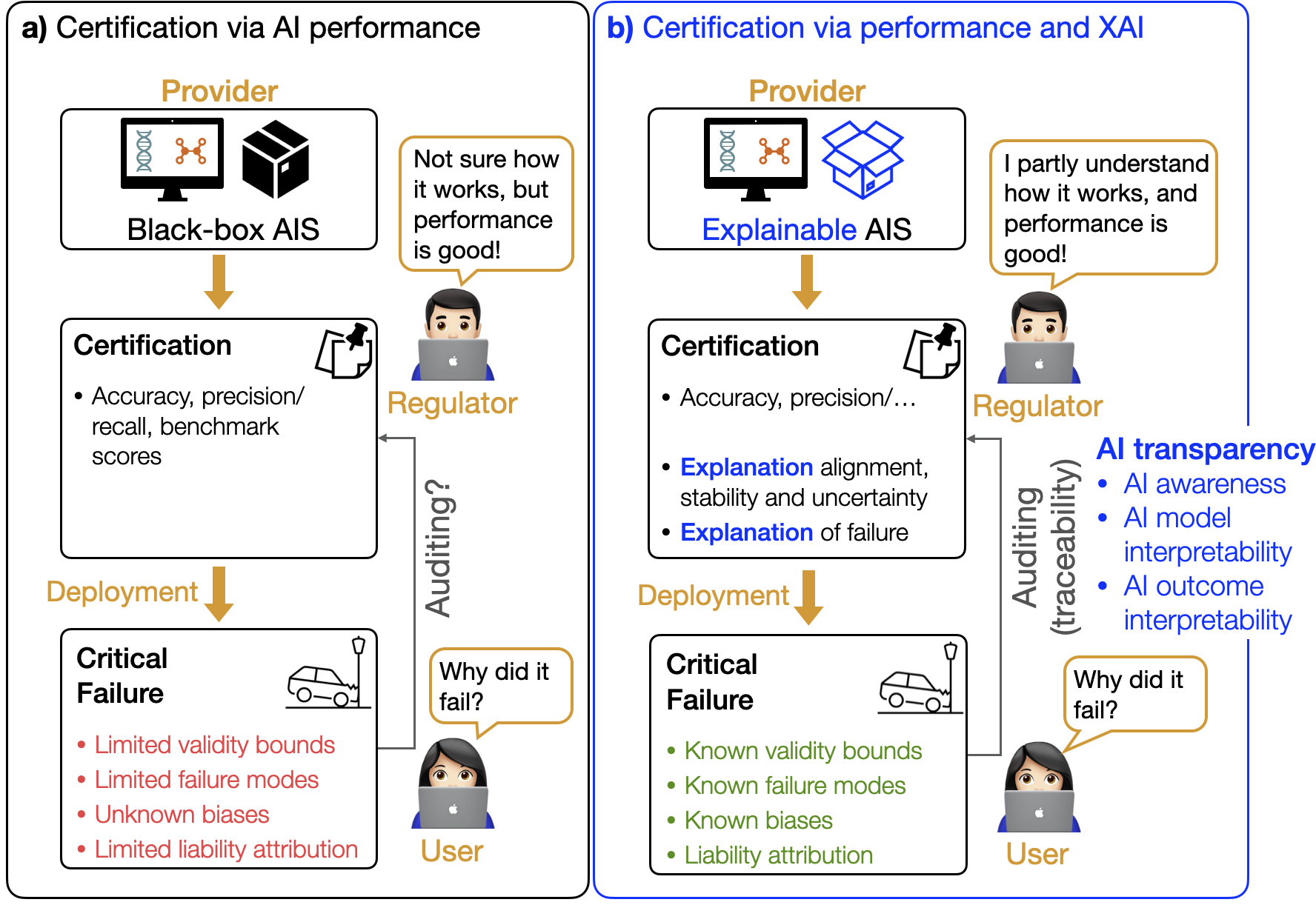
- Certification (trust and safety):
- Goal: Make AI safe and auditable for high-stakes uses (planes, medicine, energy).
- How: Don’t rely only on accuracy tests. Also demand understandable, physics-grounded explanations that hold up under stress.
- Why it matters: Regulators and engineers need to know not just that a model works, but why—and how it behaves when conditions change.
To make certification practical, the authors highlight three pillars:
- Physics-grounded explainability: Do the explanations respect known laws and concepts?
- Stress-testing with interpretable diagnostics: Do explanations stay stable under shifts and edge cases?
- Explanation-driven uncertainty: Do shaky or inconsistent explanations warn us when to be careful?
Challenges and cautions
- Faithfulness: Not every colorful heat map tells the truth. Explanations must match what the model really uses.
- Generalization: A model that only works on familiar conditions isn’t very scientific. Explanations should point to deeper mechanisms that hold up when things change (including rare extreme events).
- Usability: An explanation can be correct but still confusing. It must match how humans think in that field (e.g., engineers, doctors).
- Performance vs transparency: The best-performing model may be hard to explain. Aim for the right level of explanation (mechanisms and invariances), even if the internal details stay complex.
- Scale: As models get bigger (foundation models), we need scalable ways to discover causal structure inside their learned representations.
So what’s the impact?
If we can “learn from the learners,” AI becomes more than a tool—it becomes a partner. With explainability and causality:
- Scientists can extract new laws and understand extreme events better.
- Engineers can design and control systems by focusing on what truly causes improvements.
- Society can certify and audit AI in critical areas with “trust by understanding,” not just “trust by performance.”
In short, this paper lays out a path where humans and AI co-create knowledge: AI learns from data at massive scale, and XAI translates those insights into human terms we can test, trust, and build upon.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored, formulated as concrete, actionable gaps for future research:
- Lack of standardized, domain-specific benchmarks with ground-truth causal mechanisms to rigorously evaluate XAI faithfulness in scientific and engineering settings (e.g., known PDEs, controllable synthetic flows, instrumented experiments).
- Absence of interventional evaluation protocols that connect attribution methods (e.g., SHAP, integrated gradients) to measurable causal effects via controlled perturbations in physical or high-fidelity simulation environments.
- Unclear conditions under which latent representations learned by autoencoders or diffusion/transformer models are causally identifiable and map to true physical factors; need identifiability criteria and diagnostics.
- No formal guarantees that “dual-space” interpretability (causal discovery in latent space followed by SHAP mapping to physical space) preserves causal structure and intervention efficacy after decoding.
- Open question of how to design and validate explanation metrics that simultaneously assess faithfulness, stability, and human usability in scientific workflows, beyond accuracy-oriented metrics.
- Limited understanding of SHAP’s reliability in high-dimensional, spatiotemporal, and highly correlated scientific data (baseline/reference selection, feature dependence, attributions over continuous fields).
- Scalability limitations for causal-decomposition methods (e.g., SURD) in large, multivariate, spatiotemporal systems; need approximate estimators with provable error bounds and sample-complexity analyses.
- Missing procedures to quantify and propagate uncertainty from latent-space causal graphs through decoding to physical-space attributions and to downstream control/design decisions.
- Sparse evidence that attribution-guided interventions consistently improve closed-loop control performance and robustness; need controlled studies linking explanations to guaranteed performance gains.
- Lack of standardized tests for “explainability illusions” and post-hoc rationalizations in scientific ML (e.g., stress tests that detect attribution instability, adversarial explanation shifts, or anthropomorphic misreadings).
- Insufficient methods for explanation calibration: quantifying confidence intervals for attributions and correlating explanation variance with epistemic uncertainty and distribution shift.
- Weak theoretical guidance on when parsimonious, symbolic models (e.g., SINDy, PDE discovery) retain validity across regimes, boundary conditions, and multi-physics couplings; need extrapolation guarantees and failure detectors.
- Persistent sensitivity of PDE learning to noise, sparse/irregular sampling, and discontinuities; scalable, physics-aware derivative estimation and weak-form learning need stronger guarantees and field validations.
- Underspecified procedures to encode, learn, and verify symmetries/invariances in large foundation models; need automated symmetry discovery with enforcement and post hoc validation tools.
- Unresolved trade-offs between performance and transparency for foundation models in science: how much interpretability can be injected (via constraints, architecture, or training objectives) without compromising accuracy and speed.
- No validated methodology for “causal dimensionality reduction” in physical space using attribution (e.g., SHAP) that guarantees controllability/observability and closed-loop stability of reduced-order controllers.
- Incomplete understanding of how explanation methods behave for rare/extreme events (data scarcity, long-tail generalization, false positives); need synthetic-data augmentation, stress tests, and event-specific metrics.
- Lack of principled mappings from attributions to actuator-level interventions (e.g., how to translate high-importance regions into implementable actuation policies with safety and energy constraints).
- Missing alignment metrics between latent-space causal structures and physical-space attribution fields to verify cross-representation consistency.
- Limited investigation of explanation robustness under domain shifts (geometry changes, Reynolds/Mach regimes, materials, multi-physics couplings); need protocols for out-of-domain, cross-system generalization tests.
- No consensus on human-centered evaluation of explanation “intuitiveness” in scientific practice (task performance, cognitive load, trust calibration, decision quality); need standardized user-study paradigms.
- Unclear governance and regulatory pathways for “trust by understanding”: how to operationalize explanation-based certification (acceptance thresholds, test suites, audit trails, versioning, incident reporting).
- Unspecified liability frameworks linking explanation quality to accountability in failures; need legal-technical standards for explanation logging, provenance, and forensics.
- Computational constraints for real-time explainability in control loops (latency, memory, parallelism); need approximate, hardware-accelerated XAI with bounded error for time-critical operations.
- Insufficient study of adversarial and spurious-correlation risks specific to scientific ML (e.g., physically plausible but misleading attributions); need defenses and red-teaming for explanations.
- Gaps in data infrastructure for scientific foundation models (quality control, coverage across geometries/conditions, uncertainty metadata, bias audits, privacy for proprietary designs).
- No clear recipes for integrating explanation objectives into training (multi-objective losses, causal regularizers, invariance penalties) with guarantees on faithfulness and performance.
- Underexplored pipeline for agentic-AI/LLM systems in science: verification of proposed experiments/designs, prevention of hallucinated mechanistic claims, and explanation-aware decision checks.
- Open question of how to couple explanation signals across scales (micro/meso/macro) and modalities (vision, spectra, sensors) to produce coherent multi-scale mechanistic understanding.
- Limited reproducibility standards for XAI in science (random seeds, data splits, hyperparameters, baselines); need community protocols and leaderboards focused on explanation quality.
- Environmental and resource costs of training and explaining large foundation models for scientific tasks; need reporting standards and efficiency methods for sustainable, explainable science at scale.
Glossary
- Actuation: The application of control inputs to influence a system's dynamics. "with variants that incorporate actuation and control~\cite{zolman2024sindy}."
- Active matter: Systems composed of energy-consuming units that exhibit collective behavior far from equilibrium. "active matter~\cite{supekar2023learning}"
- Adjoint methods: Techniques that compute sensitivities efficiently for optimization, especially in PDE-constrained problems, by solving associated adjoint equations. "Classical optimization methods typically rely on gradient-based sensitivity analysis~\cite{martins2013multidisciplinary} or adjoint methods~\cite{jameson1988adjoint} to identify influential parameters."
- Agentic-AI: AI systems that autonomously plan, decide, and act (often orchestrating tools or models) toward goals. "an agentic-AI system based on LLMs~\cite{gottweis2025towards,vinuesa2026balancing}."
- Anthropomorphic metaphors: Human-like descriptors (e.g., “attend,” “reason”) applied to AI models that can misleadingly suggest human reasoning. "Anthropomorphic metaphors (e.g., describing networks as
attending'' orreasoning'') may obscure what a model actually computes~\cite{ameisen2025circuittracing,mengaldo2024explain}." - Autoencoder (AE): A neural architecture that learns compressed latent representations by reconstructing inputs through an encoder–decoder bottleneck. "This has led to one of the most important tools for explainable AI: the autoencoder (AE)~\cite{kingma2013auto,Lusch2018natcomm,Champion2019pnas,lee2020model,conti2023reduced,mounayer2024rank}."
- Bessel functions: Families of special functions that solve common differential equations in physics and engineering. "For example, the Bessel functions are defined by recursion relations to solve classes of differential equations that occur frequently in science and engineering, providing a compact and interpretable abstraction for otherwise complex behavior."
- β-VAE (Beta-Variational Autoencoder): A VAE variant that emphasizes disentanglement by scaling the KL-divergence term, promoting factorized latent representations. "Autoencoders~\cite{hinton2006reducing, lusch2018deep}, -variational autoencoders (-VAEs)~\cite{solera2024beta,vae,bvae} or other manifold-learning architectures naturally produce such representations."
- Black-box architectures: Highly expressive models whose internal decision processes are opaque to human inspection. "While black-box architectures outperform interpretable surrogates, they also contain within them rich representations of physical phenomena."
- Causal dimensionality reduction: Reducing system dimensionality guided by causal importance, preserving interpretability in physical coordinates. "Beyond attribution, gradient SHAP can act as a form of causal dimensionality reduction."
- Causal inference: Methods to identify cause–effect relationships (often under intervention) from data and models. "Recent developments in causal inference and information theory allow decomposition of causal effects into unique, redundant, and synergistic components~\cite{martinez-sanchez2024surd}."
- Causal priors: Assumptions or constraints embedding causal structure into learning to guide models toward mechanistic explanations. "Interpretable training signals, causal priors and physically meaningful embeddings are therefore essential for ensuring that generalization arises from the identified mechanisms and not by coincidence."
- Causal reasoning: Logical processes for analyzing interventions and cause–effect chains in systems. "explainable artificial intelligence (XAI), combined with causal reasoning, enables {\it learning from the learners}."
- Causal-discovery frameworks: Algorithms that infer causal graphs or structures from observational or interventional data. "Attribution tools such as saliency maps, and causal-discovery frameworks can reveal whether an AI system relies on physically meaningful features rather than spurious correlations."
- Closure modeling (turbulence): Modeling unresolved terms (e.g., Reynolds stresses) in reduced fluid-dynamics equations. "We have already seen this in the example of turbulence closure modeling, where the focus is put on modeling a specific physical mechanism, such as the Reynolds stresses~\cite{Ling2016jfm}."
- Coherent vortical regions: Organized rotational flow structures that dominate dynamics in fluids. "mapping the compressed reasoning of the machine back into interpretable physical structures, such as coherent vortical regions, thermal layers, reactive fronts or stress concentrations~\cite{Cremades2024,Cremades2025}."
- Conditional latent diffusion: Generative diffusion modeling performed in latent spaces conditioned on context (e.g., parameters), enabling synthesis under new conditions. "Conditional latent diffusion~\cite{Vishwasrao2025DiffSPORT,Du2024CoNFiLD} is used to learn the distribution of the different slices of the latent space, potentially generalizing to new (unseen) conditions"
- Conservation constraints: Physical constraints enforcing conserved quantities (e.g., mass, energy) within learning architectures. "By embedding physics into such architectures (through inductive biases, conservation constraints or equivariance principles) these models can capture the latent organization of complex systems."
- Cooperative game theory: A mathematical framework (e.g., Shapley values) for fairly attributing contributions among players/features. "The SHapley Additive exPlanation (SHAP)~\cite{shapley1953} framework, with its theoretical foundation in cooperative game theory, has become a cornerstone of post-hoc attribution methods for complex models."
- Deep reinforcement learning (DRL): Reinforcement learning using deep networks to approximate policies/value functions for complex control tasks. "For example, deep reinforcement learning~\cite{Guastoni2023_drl,verma2018efficient} or diffusion-based design models~\cite{Vishwasrao2025DiffSPORT} often solve a control or optimization task in latent spaces"
- Diffusion models: Generative models that learn to reverse a noise-adding diffusion process to generate data samples. "Recent advances in self-supervised learning and diffusion models~\cite{yang2023diffusion} further expand the scope of explainability."
- Disentangled sparsity: A principle where each latent variable depends on a sparse subset of inputs, aiding interpretability. "Cranmer et al.~\cite{cranmer2021disentangled} introduced the notion of disentangled sparsity to derive symbolic expressions for each of the latent variables in terms of a sparse subset of the high-dimensional input variables."
- Ensemble learning: Combining multiple models/estimators to improve robustness and performance. "and ensemble learning~\cite{fasel2022ensemble} to dramatically improve noise robustness."
- Epistemic uncertainty: Uncertainty arising from limited knowledge or model inadequacies, reducible with more data or better models. "Third, explanation-driven uncertainty quantification, where inconsistencies in attribution patterns serve as indicators of epistemic uncertainty."
- Equivariance principles: Architectural properties ensuring outputs transform predictably under input transformations (e.g., rotations). "through inductive biases, conservation constraints or equivariance principles"
- Extreme events: Rare, high-impact occurrences (e.g., extreme weather) often underrepresented in data. "Explainability also plays a decisive role in identifying the mechanisms behind extreme events."
- Foundation models: Large models trained on broad data that can be adapted to many downstream tasks. "we show how the combination of foundation models and explainability methods allows the extraction of causal mechanisms"
- Free energy: A thermodynamic potential used in computational chemistry and ML to impose physically meaningful objectives. "through the use of free energy and related concepts to impose physical meaning on deep learning models~\cite{Noe2019science}."
- Galerkin models: Reduced-order models obtained by projecting dynamics onto a chosen set of basis functions. "Galerkin models~\cite{Loiseau2017jfm}"
- Genetic programming (GP): An evolutionary algorithm that evolves program expressions (e.g., equations) to fit data. "Genetic programming (GP) grows increasingly sophisticated function expressions through composition of simpler basis functions"
- Gradient-based SHAP: A scalable SHAP variant using backpropagation to compute feature attributions in deep nets. "gradient-based SHAP~\cite{erion2021} offers scalability by exploiting backpropagation."
- Hamiltonian neural networks: Networks that learn dynamics consistent with Hamiltonian mechanics (energy-conserving structure). "Related examples include Lagrangian and Hamiltonian neural networks~\cite{greydanus2019hamiltonian,cranmer2020lagrangian}"
- Inductive biases: Built-in architectural or objective preferences that guide learning toward certain solutions. "By embedding physics into such architectures (through inductive biases, conservation constraints or equivariance principles)"
- Information bottleneck: A constraint that forces representations to compress input information while preserving task-relevant content. "Autoencoders operate by reconstructing input data while imposing an information bottleneck, typically through a low-dimensional latent space"
- Integrated gradients: An attribution method that integrates gradients along a path from a baseline to the input to assign feature importance. "When combined with XAI techniques such as SHapley Additive exPlanations (SHAP)~\cite{lundberg2017} or integrated gradients~\cite{sundararajan2017axiomatic}"
- Kernel SHAP: A model-agnostic SHAP approximation using weighted linear regression to estimate Shapley values. "Kernel SHAP~\cite{lundberg2017} provides a flexible (although computationally expensive) approximation"
- Lagrangian neural networks: Networks that learn dynamics consistent with Lagrangian mechanics (least-action principles). "Related examples include Lagrangian and Hamiltonian neural networks~\cite{greydanus2019hamiltonian,cranmer2020lagrangian}"
- Latent space: The compressed representation learned by models (e.g., AEs/VAEs) capturing essential variables of data. "Autoencoders operate by reconstructing input data while imposing an information bottleneck, typically through a low-dimensional latent space"
- Low-dimensional manifolds: Compact geometric structures on which high-dimensional data or dynamics effectively lie. "latent spaces that compress the dynamics into low-dimensional manifolds."
- Mach number: A dimensionless speed ratio relative to the speed of sound, relevant in compressible flows. "flow conditions (Reynolds number, Mach number, flow orientation...)"
- Navier--Stokes equations: Fundamental PDEs governing fluid motion under conservation of mass and momentum. "from Newton’s laws to the Navier--Stokes equations, which encode mechanistic understanding and enable prediction, control and design."
- Pareto frontier: The set of solutions that optimally trade off competing objectives (e.g., simplicity vs. accuracy). "using the Pareto frontier of model complexity versus accuracy to identify expressions that are both simple and descriptive."
- Partial differential equations (PDEs): Equations involving multivariable functions and their partial derivatives, central to continuum physics. "One of the most important applications of sparse symbolic regression for scientific discovery is its extension to partial differential equations (PDEs)~\cite{Rudy2017sciadv, Schaeffer2017prsa}."
- Parsimony (Occam's razor): Preference for the simplest model that adequately explains data, aiding interpretability and generalization. "This principle of parsimony, also known as Occam's razor, has been the gold standard in physics for 2,000 years"
- Reynolds number: A dimensionless quantity characterizing flow regime (laminar vs. turbulent) via inertial-to-viscous force ratio. "flow conditions (Reynolds number, Mach number, flow orientation...)"
- Reynolds stresses: Turbulence-induced momentum fluxes requiring modeling in averaged flow equations. "such as the Reynolds stresses~\cite{Ling2016jfm}."
- Saliency maps: Pixel/feature-level attributions indicating which inputs most affect a model’s output. "Other relevant XAI methods are integrated gradients~\cite{sundararajan2017axiomatic} and saliency maps~\cite{simonyan2014deep}."
- Self-supervised learning: Learning from data structure or context without explicit labels, often via predictive pretext tasks. "Recent advances in self-supervised learning and diffusion models~\cite{yang2023diffusion} further expand the scope of explainability."
- SHAP (SHapley Additive exPlanations): A unified framework based on Shapley values to attribute feature contributions in model predictions. "The SHapley Additive exPlanation (SHAP)~\cite{shapley1953} framework, with its theoretical foundation in cooperative game theory, has become a cornerstone of post-hoc attribution methods for complex models."
- SINDy (Sparse Identification of Nonlinear Dynamics): A sparse-regression method that discovers governing equations from data. "The sparse identification of nonlinear dynamics (SINDy) algorithm identifies the fewest terms in a library of candidates functions needed to describe a given system"
- Singular value decomposition (SVD): A matrix factorization yielding orthogonal modes; a linear method for dimensionality reduction. "In this sense, AEs may be viewed as a nonlinear generalization of the singular value decomposition (SVD), which is itself a data-driven generalization of the Fourier transform~\cite{Brunton2022book}."
- Sparse regression: Regression techniques that enforce sparsity to select a small set of explanatory terms/features. "two main approaches to symbolic regression: genetic programming to grow function trees compositionally, and sparse regression in a library of candidate terms."
- SURD (Synergistic, Unique and Redundant Decomposition): An information-theoretic framework that decomposes causal contributions into unique, redundant, and synergistic parts. "such as the SURD (synergistic, unique and redundant decomposition) framework~\cite{martinez-sanchez2024surd}, provide a richer decomposition of causal interactions."
- Symbolic regression: Searching over symbolic expressions to find interpretable equations that fit data. "Symbolic regression is a particularly useful technique in machine learning for scientific discovery, resulting in models that take the form of parsimonious symbolic expressions."
- Transformer: A sequence model using self-attention mechanisms for capturing long-range dependencies. "and a transformer~\cite{ref_easy} (which perform the temporal predictions)."
- Verification and validation (V&V) frameworks: Formal processes for ensuring models are correctly implemented (verification) and accurate for intended use (validation). "analogous to verification and validation (V{paper_content}V) frameworks used in engineering certification."
- Weak formulation: A variational reformulation of PDEs enabling more robust numerical estimation (e.g., under noise). "it has been augmented with the weak formulation~\cite{messenger2021weak,reinbold2021robust} to dramatically improve noise robustness."
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage the paper’s methods (e.g., SHAP, integrated gradients, SINDy, symbolic regression, autoencoders/β-VAEs, causal SURD), organized by sector with actionable workflows, and the key assumptions/dependencies to watch.
- SHAP-guided flow-control and drag-reduction — sector: aerospace, automotive, energy (wind)
- What: Use gradient-based SHAP on trained CFD surrogates or DRL controllers to locate causally important flow structures; shape rewards and place actuators (e.g., synthetic jets) where SHAP indicates largest leverage.
- Tools/workflows: Train DRL/latent models; run gradient SHAP at field resolution; redesign reward to target physical mechanisms, not just end metrics.
- Assumptions/dependencies: High-fidelity data or reliable surrogates; differentiability/access to gradients; actuator feasibility; compute budget for high-res attribution.
- Explanation-augmented topology/thermal design — sector: electronics cooling, HVAC, manufacturing
- What: Apply SHAP/integrated gradients to heat-transfer surrogates to identify bottlenecks and inform fin topology, heat-spreader layout, or sensor placement.
- Tools/workflows: Surrogate-assisted topology optimization coupled with post-hoc attribution; iterate design where attributions consistently highlight thermal choke points.
- Assumptions/dependencies: Surrogate validity across operating envelope; meshing consistency; temperature sensor accuracy.
- Combustion and propulsion tuning via causal attributions — sector: energy, aerospace
- What: Attribute ignition stability, NOx formation, or blowoff risk to specific spatial/temporal regions; adjust injector timing, mixture fraction, or swirl.
- Tools/workflows: Saliency/SHAP overlays on reacting-flow fields; explanation-driven control setpoint updates.
- Assumptions/dependencies: Chemkin/LES-calibrated surrogates; safety envelopes; domain shift checks.
- Wake-aware wind farm operation — sector: renewable energy
- What: Use SHAP to weigh turbine–turbine interactions and guide yaw/induction control for power/cycling trade-offs; improve sensor placement.
- Tools/workflows: Farm-level surrogate + SHAP for causal mapping; closed-loop controller prioritizing high-importance regions/turbines.
- Assumptions/dependencies: Real-time SCADA data; robust generalization to atmospheric stability shifts; operator procedures for overrides.
- Symbolic regression for reduced-order models (ROMs) — sector: academia, aerospace, process industries
- What: Use SINDy/symbolic regression to derive parsimonious dynamic models from experiments/simulations for diagnostics, control, and insight.
- Tools/workflows: Derivative estimation/weak-form SINDy; constraint-enforced discovery (e.g., energy conservation).
- Assumptions/dependencies: Sufficiently informative time-series; noise-robust derivative estimates; physical constraints available.
- Latent linear models for monitoring and control — sector: robotics, manufacturing, healthcare devices
- What: Autoencoders/β-VAEs to compress sensor fields; apply linear/Koopman-like dynamics in latent for prediction/control; expose interpretable latent axes via disentanglement.
- Tools/workflows: AE training with bottleneck; linear controller/MPC in latent; map latent attributions back to physical space for interventions.
- Assumptions/dependencies: Stable training; representation consistency under distribution shift; real-time decoding latency.
- Early warning for extremes with interpretable precursors — sector: climate, hydrology, infrastructure
- What: Identify weak but causally dominant precursors of extreme weather or structural failures; trigger alerts and targeted observations.
- Tools/workflows: XAI on spatiotemporal predictors; causality checks on precursor stability; thresholding and alert pipelines.
- Assumptions/dependencies: Reanalysis/observational coverage; class imbalance handling; precautionary principle in false-alarm policy.
- XAI-based certification checklist inside V&V — sector: aerospace, medical devices, autonomous systems
- What: Add physics-grounded explainability tests (invariance, conservation, stability), explanation-stability under perturbations, and explanation-driven UQ to existing validation.
- Tools/workflows: Audit trail storing attributions, counterfactuals, stress tests; pass/fail gates tied to domain concepts.
- Assumptions/dependencies: Regulator acceptance; access to model internals/gradients; standard metrics for explanation faithfulness/stability.
- Model risk management with explanation stress tests — sector: finance, insurance
- What: Use SHAP consistency under covariate and outcome perturbations to detect spurious features and hidden biases; document reliance on economically meaningful drivers.
- Tools/workflows: Challenge datasets, scenario perturbations, and explanation drift dashboards in MLOps.
- Assumptions/dependencies: Governance buy-in; sensitive-feature handling; performance/explainability trade-off.
- Production monitoring via explanation drift — sector: software/MLOps (cross-industry)
- What: Log attributions alongside predictions; alert on shifts in feature-importance profiles before accuracy degrades.
- Tools/workflows: XAI telemetry pipeline; time-series analysis of attribution vectors; rollback/playbook triggers.
- Assumptions/dependencies: Privacy/PII controls; compute overhead budgets; stable feature schemas.
- Clinician-in-the-loop explanation QA — sector: healthcare (radiology, pathology, triage)
- What: Require that saliency/attributions localize known lesions or pathognomonic patterns before surfacing AI suggestions; route cases to human review on explanation anomalies.
- Tools/workflows: PACS integration; per-case explanation snapshots; adjudication workflows.
- Assumptions/dependencies: DICOM interoperability; clinician training; liability clarity for overrides.
- Explanation-informed sensor/actuator placement — sector: industrial IoT, smart buildings, process control
- What: Place sensors and actuators where attribution indicates highest causal leverage on KPIs; prune low-importance regions for cost reduction.
- Tools/workflows: SHAP-weighted facility maps; iterative placement optimization; revalidation after changes.
- Assumptions/dependencies: Accurate plant/simulation models; installation constraints; seasonal/operational shifts.
- Education and training with interpretable models — sector: education, workforce upskilling
- What: Use autoencoders + SINDy labs to teach mechanistic modeling, causality, and control; compare black-box vs parsimonious models on the same systems.
- Tools/workflows: Open datasets + notebooks; rubric for explanation faithfulness and usability.
- Assumptions/dependencies: Curriculum time; instructor familiarity with XAI/causality.
Long-Term Applications
These opportunities require further research, scaling, cross-organization datasets, standardization, or integration with hardware/regulation.
- Physics foundation models with XAI bridges to physical space — sector: aerospace, energy, climate, materials
- What: Multi-geometry spatiotemporal foundation models (β-VAEs + transformers + conditional latent diffusion) whose latent causal structure (SURD) is mapped to physical mechanisms via SHAP for design/control and hypothesis generation.
- Tools/products: “Physics FM” platforms; attribution-driven simulators; latent-to-physical causal translators.
- Assumptions/dependencies: Curated cross-geometry datasets and parameterizations; massive compute; robust causal discovery at scale; data sharing/IP frameworks.
- Agentic AI for autonomous scientific discovery and design — sector: academia, R&D, advanced engineering
- What: LLM-driven planners that design new experiments/simulations, analyze latent causal mechanisms, propose next conditions, and iterate—closing the loop from discovery to optimization with human oversight.
- Tools/products: Lab orchestration agents; hypothesis generators with explanation constraints; active-learning benches.
- Assumptions/dependencies: Safe sandboxes; reliable simulators/robots; governance for autonomous exploration; experiment–model fidelity.
- Standardized XAI-based certification for safety-critical AI — sector: regulators (FAA/EASA, FDA, NHTSA), standards bodies (ISO/IEC)
- What: Normative requirements for physics-grounded explanations, stability under shifts, explanation-driven UQ, and audit trails as conditions for approval.
- Tools/products: Compliance test suites, explanation benchmarks, conformance reports.
- Assumptions/dependencies: Multi-stakeholder consensus; measurement protocols for faithfulness/usability; liability allocations.
- Explanation-driven uncertainty and safety monitors — sector: healthcare devices, autonomous vehicles, robotics
- What: Real-time monitors that flag inconsistent/unstable attributions as proxy for epistemic uncertainty; trigger safe modes and human handover.
- Tools/products: Edge-capable attribution engines; explanation consistency metrics; safety interlocks.
- Assumptions/dependencies: Efficient attribution computation; validated thresholds; human-in-the-loop availability.
- SHAP-driven “physical-space ROMs” for control hardware — sector: industrial control, energy, aerospace
- What: Replace generic latent compression with SHAP-weighted physical-domain reduction to retain actuator/sensor interpretability; deploy on embedded controllers.
- Tools/products: Hardware-friendly ROM compilers; explainable MPC libraries.
- Assumptions/dependencies: Hardware constraints; robustness to aging and wear; standardized actuator interfaces.
- Causal-latent actuation design — sector: process industries, microgrids, robotics
- What: Use SURD to isolate synergistic/unique latent directions that most effectively move a system toward targets; synthesize minimal, energy-efficient interventions.
- Tools/products: Causal control design suites; synergy maps for multi-actuator coordination.
- Assumptions/dependencies: Reliable causal inference under partial observability; confounder control; pilot deployments.
- Scalable PDE discovery for new regimes — sector: plasmas, geophysics, biophysics
- What: Weak-form SINDy + ensemble learning on petascale data to uncover closure laws or governing PDEs in under-modeled regimes.
- Tools/products: Discovery-as-a-service platforms; hybrid solvers embedding learned terms with stability guarantees.
- Assumptions/dependencies: High-quality multi-scale data; rigorous noise handling; stability/consistency proofs.
- Cross-domain explainable digital twins with audit trails — sector: infrastructure (bridges, offshore), smart grids, aviation
- What: Digital twins embedding explainable components and certified explanation logs for maintenance, incident forensics, and regulatory reporting.
- Tools/products: Twin platforms with XAI-native logging; regulator dashboards; incident replay with causal narratives.
- Assumptions/dependencies: Dense sensor networks; lifecycle data governance; cybersecurity.
- Explanation-aware RL standards — sector: autonomy, logistics, defense
- What: Requirements that RL policies expose causal rationales, avoid reward hacking, and pass intervention-based explanation tests before deployment.
- Tools/products: RL evaluation harnesses with causal perturbations; policy certification badges.
- Assumptions/dependencies: Benchmarks and ground-truth mechanisms; sim-to-real fidelity; stakeholder acceptance.
- Human-centered explanation design and training — sector: education, regulation, enterprise adoption
- What: Curricula and certification for engineers/clinicians/regulators to interpret explanations, judge faithfulness, and act on them; UX standards for explanation usability.
- Tools/products: Training modules, interactive explanation sandboxes, domain-specific “explanation glossaries.”
- Assumptions/dependencies: Time and incentives for upskilling; empirical studies linking explanation design to outcomes.
- Consumer-grade transparent assistants — sector: daily life, enterprise productivity
- What: Assistants that justify suggestions with causal chains (e.g., home energy savings tied to explainable precursors) and flag uncertainty via explanation instability.
- Tools/products: Explanation-first UIs; personal data causal maps; opt-in telemetry for model improvement.
- Assumptions/dependencies: Privacy-preserving attribution; on-device compute or efficient cloud; user trust and comprehension.
Cross-cutting assumptions and dependencies
- Data quality and breadth: diverse, well-parameterized datasets across regimes/geometries; robust labels or physical constraints.
- Faithfulness and stability of explanations: validated metrics; defenses against post-hoc rationalizations.
- Compute and tooling: scalable, efficient attribution (e.g., gradient SHAP) and causal discovery; integration into MLOps/V&V.
- Physical constraints and priors: conservation, symmetries, and invariances embedded in models to enhance generalization and interpretability.
- Human factors and usability: explanations aligned with domain concepts; training for end-users and regulators.
- Governance and liability: clear audit trails; standards for explanation sufficiency; IP/privacy protections for shared data/models.
These applications operationalize the paper’s central thesis—using explainability and causality to learn from ML “learners”—by turning internal model representations into mechanisms for discovery, optimization, and certification across real-world domains.
Collections
Sign up for free to add this paper to one or more collections.