- The paper presents PPD and PPVD, advanced models that leverage diffusion transformers to achieve pixel-perfect depth estimation from monocular and video inputs.
- The methodology integrates Semantics-Prompted DiT and a Cascade DiT architecture to capture both global image structures and fine-grained details.
- Experimental results show state-of-the-art performance with clean point clouds, indicating strong potential for robotic and AR/VR applications.
Pixel-Perfect Visual Geometry Estimation
Introduction
The paper "Pixel-Perfect Visual Geometry Estimation" (2601.05246) introduces novel methodologies for recovering clean and accurate geometry from monocular and video inputs. Existing geometry foundation models suffer from flying pixels and loss of fine details, which impedes their application in areas such as robotics and augmented reality. To address these issues, the authors present Pixel-Perfect Depth (PPD) and Pixel-Perfect Video Depth (PPVD) models, which leverage generative modeling in the pixel space through diffusion transformers (DiT). These models aim to produce high-quality, flying-pixel-free point clouds without requiring additional refinement or post-processing.

Figure 1: Visual comparison with existing depth foundation models.
Methodology
Monocular Depth Estimation: Pixel-Perfect Depth (PPD)
The paper introduces Pixel-Perfect Depth (PPD), a monocular depth foundation model that utilizes pixel-space diffusion transformers to predict depth maps directly in the pixel space. PPD consists of key components such as Semantics-Prompted DiT and Cascade DiT architecture:
- Semantics-Prompted DiT incorporates semantic representations extracted from vision foundation models to prompt the diffusion process. This aids in preserving global semantics and enhancing fine-grained visual details.
- Cascade DiT architecture progressively increases the number of image tokens, prioritizing global image structure learning in early stages while focusing on high-frequency details in later stages. This design improves efficiency and accuracy significantly.
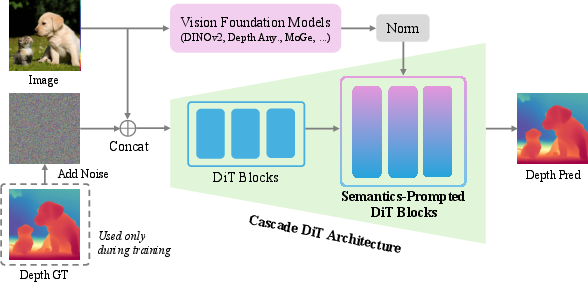
Figure 2: Overview of Pixel-Perfect Depth.
Video Depth Estimation: Pixel-Perfect Video Depth (PPVD)
PPVD extends the monocular depth model to video sequences by introducing Semantics-Consistent DiT and a Reference-Guided Token Propagation strategy.
- Semantics-Consistent DiT captures temporally consistent semantics using a multi-view geometry-based model. This allows for the integration of view-consistent semantics into the diffusion process.
- Reference-Guided Token Propagation ensures temporal coherence within video frames by propagating scale and shift information through sparse reference tokens. This strategy maintains temporal consistency with minimal computational overhead.
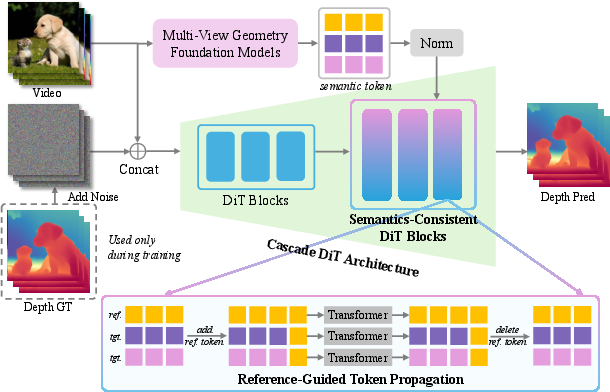
Figure 3: Overview of Pixel-Perfect Video Depth.
Experimental Results
The authors present state-of-the-art performance for both monocular and video depth estimation models. PPD and PPVD outperform all existing generative depth estimation models across multiple benchmarks, demonstrating strong zero-shot generalization abilities. The models produce significantly cleaner point clouds, highlighting their efficacy in addressing the flying pixel issue.

Figure 4: Comparison with existing depth foundation models.
Implications and Future Work
The implications of this research are significant for practical applications in fields requiring precise depth estimation, such as robotic manipulation and immersive AR/VR experiences. The development of diffusion transformers capable of operating directly in pixel space marks an advancement in handling high-resolution depth estimation tasks. Future work could explore further optimizations for large-scale deployment and integration with real-world robotic systems. Additionally, adapting the models for outdoor environments with dynamic lighting conditions and diverse weather scenarios could extend their applicability.
Conclusion
In summary, the paper presents advanced models for visual geometry estimation that overcome key limitations of existing methods. By leveraging pixel-space diffusion and integrating semantic prompting techniques, the authors establish a robust framework for high-quality monocular and video depth estimation. This work lays the groundwork for future exploration of diffusion-based models in similar high-dimensional tasks, pushing the boundaries of depth foundation modeling.