Diffusion Knows Transparency: Repurposing Video Diffusion for Transparent Object Depth and Normal Estimation
Abstract: Transparent objects remain notoriously hard for perception systems: refraction, reflection and transmission break the assumptions behind stereo, ToF and purely discriminative monocular depth, causing holes and temporally unstable estimates. Our key observation is that modern video diffusion models already synthesize convincing transparent phenomena, suggesting they have internalized the optical rules. We build TransPhy3D, a synthetic video corpus of transparent/reflective scenes: 11k sequences rendered with Blender/Cycles. Scenes are assembled from a curated bank of category-rich static assets and shape-rich procedural assets paired with glass/plastic/metal materials. We render RGB + depth + normals with physically based ray tracing and OptiX denoising. Starting from a large video diffusion model, we learn a video-to-video translator for depth (and normals) via lightweight LoRA adapters. During training we concatenate RGB and (noisy) depth latents in the DiT backbone and co-train on TransPhy3D and existing frame-wise synthetic datasets, yielding temporally consistent predictions for arbitrary-length input videos. The resulting model, DKT, achieves zero-shot SOTA on real and synthetic video benchmarks involving transparency: ClearPose, DREDS (CatKnown/CatNovel), and TransPhy3D-Test. It improves accuracy and temporal consistency over strong image/video baselines, and a normal variant sets the best video normal estimation results on ClearPose. A compact 1.3B version runs at ~0.17 s/frame. Integrated into a grasping stack, DKT's depth boosts success rates across translucent, reflective and diffuse surfaces, outperforming prior estimators. Together, these results support a broader claim: "Diffusion knows transparency." Generative video priors can be repurposed, efficiently and label-free, into robust, temporally coherent perception for challenging real-world manipulation.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
The paper tackles a tricky problem: figuring out how far away see‑through and shiny objects are in videos. Think of a glass cup, a plastic bottle, or a chrome kettle. Usual depth cameras and many AI models get confused by these because light bends and reflects in strange ways, so their “distance maps” end up full of holes or jumpy from frame to frame.
The authors show that a new kind of AI that’s great at making videos—called a video diffusion model—already “understands” how light behaves in glass and metal. They repurpose that knowledge to build a tool, called DKT, that turns normal videos into smooth, accurate depth maps (and surface directions) even when transparent or reflective objects are in the scene.
What the researchers wanted to find out
- Can a generative video model (one that creates videos) be turned into a reliable “measuring tool” that estimates depth for glassy or shiny objects in real videos?
- Will it stay stable over time (no flickering or sudden jumps) across long video sequences?
- Can it work on new, real scenes without extra training on real-world labels (called “zero-shot”)?
- Will better depth actually help robots pick up objects more successfully?
How they did it (in everyday terms)
Before we dive in, here are a few simple definitions:
- Depth: how far each pixel in the image is from the camera (like a “distance picture”).
- Surface normal: a tiny arrow that points out of a surface, telling you which way it’s facing.
- Video diffusion model: a model that learns to make videos by starting from noisy frames and gradually “cleaning” them into realistic videos—like sharpening a foggy picture step by step.
- Synthetic data: data made in a 3D graphics program (like a video game engine), not captured by a camera.
- LoRA: a lightweight way to fine‑tune a big model by adding small “plug‑in” adapters instead of changing the whole thing.
What they built and trained:
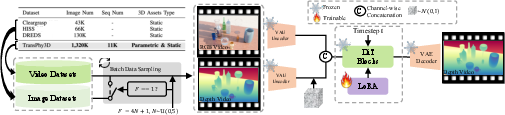
- A large, realistic synthetic video dataset called TransPhy3D:
- They used Blender (a 3D tool) to render 11,000 short videos (1.32 million frames) of scenes with transparent or reflective objects.
- They collected two kinds of 3D objects: many categories of hand‑crafted models (like bottles, cups, lamps) and procedurally generated shapes (to cover lots of geometries).
- They let objects fall and settle with physics so scenes look natural.
- They moved the camera smoothly around the objects.
- Each frame includes normal color images (RGB), depth (distance), and surface normals.
- A training approach that turns video generation into video translation:
- Instead of making new videos from scratch, the diffusion model learns to “translate” an input RGB video into a depth (or normals) video.
- They fine‑tune only small LoRA adapters so the original video knowledge (like how glass looks) isn’t forgotten.
- They mix video data with single-frame synthetic image datasets using a careful sampling schedule so the model learns from both.
- They process videos in overlapping chunks and stitch outputs together for any video length, helping the results stay stable over time.
In short: They taught a video‑making AI to be a video‑to‑depth translator by training it on tons of realistic, computer‑rendered glass/metal scenes—without needing extra real-world labels.
What they found (main results and why they matter)
- Strong performance without extra real-world labels:
- The model, DKT, is “zero-shot”: it wasn’t trained on the test videos—but still achieved state‑of‑the‑art results on tough benchmarks, including:
- ClearPose (real videos of transparent objects),
- DREDS (real scenes with transparent/specular items),
- and their own TransPhy3D test set.
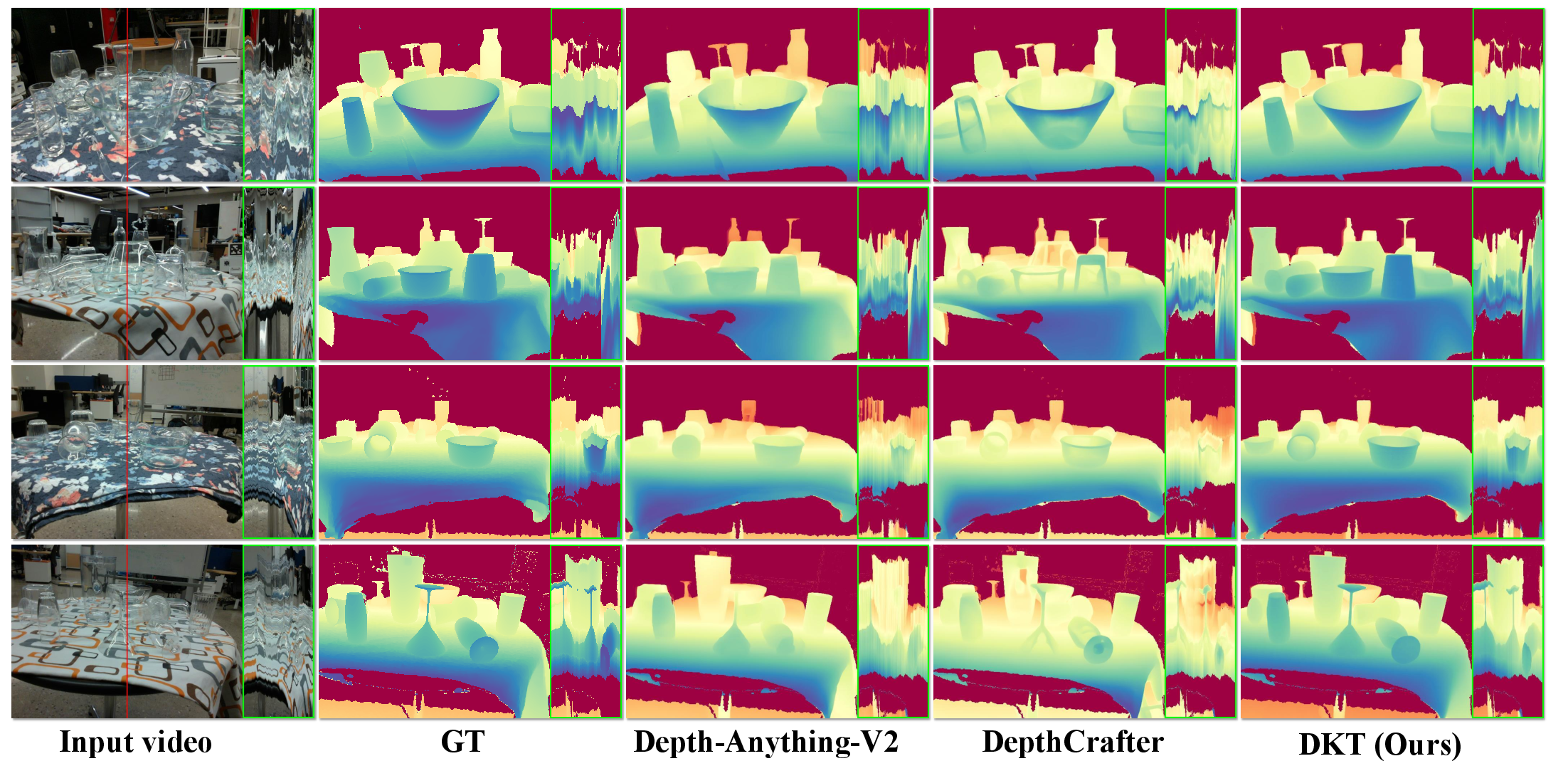
- More accurate and more stable over time:
- DKT gives better depth accuracy and smoother frame‑to‑frame predictions than strong baselines like Depth‑Anything v2 and DepthCrafter—especially where transparency and reflections usually break other methods.
- Also works for surface normals:
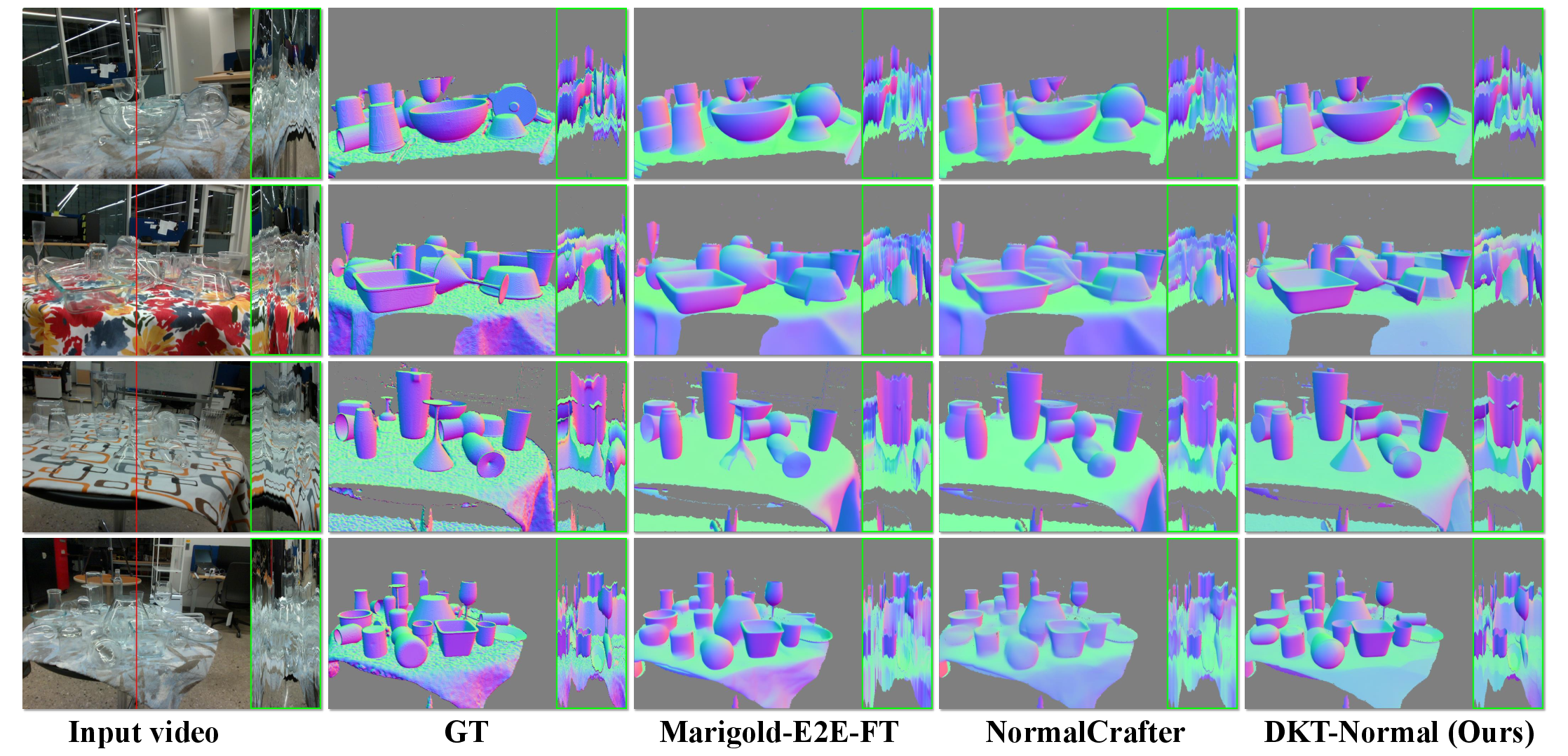
- A version called DKT‑Normal provides top video normal estimation on ClearPose, making surface directions sharp and consistent across frames.
- Fast enough for real use:
- A compact version (about 1.3B parameters) runs at roughly 0.17 seconds per frame at 832×480 resolution on a modern GPU.
- Helps robots grasp better:
- In real-world tests, using DKT’s depth boosted a robot’s grasp success on see‑through, reflective, and normal surfaces, clearly outperforming other methods. In practice: better depth means better object handling.
Why this matters: Transparent and reflective objects are everywhere—kitchens, labs, factories—and they’ve long been a headache for cameras and AI. This work shows that “diffusion knows transparency”: generative video models have internalized the rules of light, and that understanding can be turned into reliable perception for real tasks.
What it means going forward
- Better robots and AR: More reliable depth for glass and metal means improved robotic manipulation, 3D scanning, and augmented reality overlays in everyday environments.
- Less need for hard‑to‑get labels: Training with purely synthetic videos plus a powerful generative prior can produce models that generalize well to the real world.
- A new recipe for perception: Instead of building task‑specific models from scratch, we can repurpose large generative video models—with small add‑on adapters—to solve tough vision problems with temporal consistency.
In simple terms: The team found a smart shortcut. Rather than teaching a camera how to “see through” glass from zero, they borrowed a model that already knows how glass looks in motion—and taught it to measure. The result is a fast, stable, and practical tool that makes computers and robots much better at understanding the real world, even when it’s shiny or see‑through.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a focused list of what remains missing, uncertain, or unexplored, distilled to guide follow-up research and engineering work.
- Dataset realism and coverage
- TransPhy3D scenes are built with Blender/Cycles and OptiX denoising but do not model real sensor artifacts (e.g., rolling shutter, motion blur, depth quantization, multipath interference, IR/NIR behavior), limiting realism for deployment across camera types.
- Scene diversity is largely tabletop/container setups with circular camera trajectories; generalization to handheld/mobile cameras, non-circular trajectories, rapid pans/tilts, and cluttered indoor/outdoor environments is not evaluated.
- The asset curation via Qwen2.5-VL and material pairing may bias toward certain categories and surface finishes; breadth across micro-roughness, coated optics (thin films), frosted/etched glass, liquids with bubbles, multi-layer composites, and anisotropic materials is unclear.
- Label semantics for depth under transparency are not specified (e.g., nearest-surface geometry vs. perceived refracted background depth), creating ambiguity about training targets and evaluation consistency across datasets.
- Evaluation scope and fairness
- ClearPose evaluation masks background, so performance on backgrounds seen through refraction/partial occlusion remains unknown; error modes outside foreground objects are unquantified.
- Metrics rely on global scale/shift alignment, so absolute metric scale remains unaddressed; robustness of metric scaling without AprilTag or external references is not analyzed.
- Temporal consistency is shown qualitatively and via temporal profiles, but systematic metrics for flicker and inter-frame drift (e.g., optical-flow-based consistency or temporal RMSE) are not reported.
- No breakdown of performance by material type, thickness, curvature, refraction index, or lighting condition; a stratified error analysis is needed to identify failure modes.
- Normal estimation is evaluated only on ClearPose; cross-dataset validation (e.g., DREDS subsets, TransPhy3D-Test) and downstream utility (e.g., grasp orientation refinement) are missing.
- Robotic grasping results lack trial counts, variance, and statistical significance; configuration-specific confounds (object set, lighting, camera placement) and ablations (with/without AprilTag scaling, single vs multi-frame) are not provided.
- Model design and training
- The effect of LoRA rank, insertion points, and adapter capacity on catastrophic forgetting and target-task performance is not studied; quantitative evidence that video generation priors are preserved is missing.
- Co-training with mixed image/video data is proposed but not ablated in detail (e.g., mixture ratios, frame-length distribution F=4N+1, curriculum scheduling); scaling laws for data volume vs. performance are not explored.
- The method uses only RGB conditioning; potential gains from multi-modal cues (e.g., polarization, NIR, stereo, ToF) or language prompts specifying materials/scene context are untested.
- No explicit physics constraints are used (e.g., Snell’s law priors, specular consistency, multi-view geometry); whether such constraints can further reduce ambiguities remains open.
- The inference stitching strategy (overlapping segments with complementary weights) is adopted from prior work; boundary artifacts, long-horizon accumulation, and optimal segment length are not analyzed.
- The claim “Diffusion knows transparency” is not substantiated with interpretability or controlled physics tests (e.g., varying refractive indices, Fresnel effects, multi-layer refraction), leaving the nature of learned priors unresolved.
- Robustness and generalization
- Sensitivity to camera intrinsics/extrinsics changes, different resolutions than 832×480, video compression artifacts, and changes in exposure/HDR is not quantified.
- Performance under dynamic scenes with moving objects, changing lighting, specular highlights/glare, or active manipulation is not evaluated (TransPhy3D simulates static settled scenes).
- Failure modes in highly curved thin-walled objects (e.g., wine glasses), strong lensing effects, hollow/stacked transparent objects, and transparent occluders are not analyzed.
- Cross-sensor generalization (e.g., RealSense L515 vs. D435 vs. mobile phone RGB) and cross-domain settings (industrial, outdoor, underwater) remain unexplored.
- Scaling, efficiency, and deployment
- The trade-offs between inference steps and detail loss are shown qualitatively; a principled analysis of sampler choice, schedule, and step count is missing.
- Memory/runtime comparisons are limited to specific GPUs; scaling behavior on embedded or edge hardware, and strategies for quantization/distillation, are not addressed.
- Arbitrary-length inference is claimed, but stability on very long videos (minutes) and streaming latency constraints in closed-loop robotics are not evaluated.
- Data and reproducibility
- Release status, licensing, and reproducibility details for TransPhy3D (assets, materials, scripts, seeds) are not specified; open replication requires clear distribution and documentation.
- The asset scoring pipeline using Qwen2.5-VL may be non-deterministic; transparency class labels used for selection should be documented to allow reproducible curation.
- Downstream integration
- The grasping pipeline uses single-frame depth with AprilTag-based metric scaling; benefits of leveraging temporal consistency (multi-frame fusion) for planning and control are not evaluated.
- Interactions with 3D reconstruction (e.g., TSDF/NeRF fusion on transparent scenes), SLAM in refractive environments, and contact-rich manipulation are not studied.
- Theoretical and empirical validation
- No formal analysis links the diffusion model’s training data to physical correctness under transparency; controlled experiments that vary only optical parameters (index of refraction, roughness, subsurface scattering) are needed.
- Ambiguity in multi-path visual cues (reflection vs. refraction vs. transmission) is not explicitly handled; a principled approach to disambiguation is an open problem.
- Safety and failure reporting
- Safety considerations in robotic deployment (e.g., false positives near hazardous transparent surfaces) and recovery strategies for perception failure are not discussed.
- Comprehensive failure case cataloging (qualitative examples, diagnostics, and mitigation strategies) is absent.
These gaps suggest concrete next steps: expand dataset realism and stratified evaluations, introduce physics-aware constraints, analyze LoRA adaptation dynamics, test across sensors and dynamic scenarios, evaluate long-horizon streaming, and document reproducibility and deployment practices.
Practical Applications
Practical Applications of “Diffusion Knows Transparency (DKT)”
Below are actionable applications derived from the paper’s findings, methods, and innovations, grouped by deployment horizon. Each entry notes sector(s), potential tools/products/workflows, and key assumptions/dependencies.
Immediate Applications
- Robotics and Manufacturing: Reliable grasping of transparent/reflective objects
- Sectors: Robotics, Manufacturing, Logistics, Retail
- Use case: Bin-picking and tabletop manipulation of glassware, shrink‑wrapped items, metal parts on reflective/translucent/diffuse surfaces.
- Workflow/tools: RGB video → DKT depth → metric scaling (AprilTag/known-size targets) → AnyGrasp for 7‑DoF grasp → CuRobo motion plan. Demonstrated mean grasp success: 0.73 vs 0.38–0.48 for baselines.
- Dependencies/assumptions: GPU (≈11 GB for 1.3B variant), good lighting and moderate motion blur, monocular video stream, a metricization step (tags, known baselines, or SLAM), integration with existing grasping stacks.
- Depth “hole-filling” for RGB‑D sensors on transparent/reflective surfaces
- Sectors: Robotics, Industrial Vision, Warehousing, Home Robotics
- Use case: Complements ToF/stereo depth by filling missing regions on glass/metal; improves path planning, obstacle avoidance, and manipulation.
- Workflow/tools: ROS2 node that fuses DKT monocular depth with raw depth (RGB‑D) to repair invalid regions; 5 denoising steps for real-time performance at 832×480 (~0.17 s/frame for 1.3B).
- Dependencies/assumptions: Time sync of RGB/Depth, calibration, GPU or high-end edge accelerator, modest camera motion.
- Visual inspection of transparent/reflective parts via normals
- Sectors: Manufacturing QA, Consumer Electronics, Automotive
- Use case: Surface normal maps (DKT‑Normal) for defect detection (dents, waviness, coatings) on glass, polished metal, and ceramics.
- Workflow/tools: RGB video → DKT‑Normal → normal-based anomaly scoring; integration into existing AOI toolchains.
- Dependencies/assumptions: Stable camera pose or controlled motion; metric scale optional; good illumination to avoid saturation.
- AR/MR occlusion and scene understanding around glass
- Sectors: Software, Entertainment, Architecture/Real Estate
- Use case: Correct occlusion and placement on/behind glass walls, displays, and windows; improved anchors near reflective surfaces.
- Workflow/tools: Unity/Unreal plugin wrapping DKT for temporally consistent depth; metric scale from ARKit/ARCore VIO or single fiducial.
- Dependencies/assumptions: Mobile/edge compute budget (may require model distillation/quantization), consistent frame rate, camera intrinsics.
- 3D scanning/reconstruction of spaces with significant transparency
- Sectors: AEC (Architecture/Engineering/Construction), Cultural Heritage, VFX
- Use case: Better reconstruction of interiors with glass partitions, display cases, glossy floors.
- Workflow/tools: Multiview capture → DKT depth priors per frame → fusion with SfM/MVS; plug-in for COLMAP or open-source pipelines.
- Dependencies/assumptions: Accurate extrinsics, temporal consistency exploited across turns; metric scaling from known baselines.
- Retail/Autonomous Store operations near glass fixtures
- Sectors: Retail Tech, Robotics
- Use case: Navigation and manipulation near glass doors/shelves; handling reflective packaging.
- Workflow/tools: On‑cart monocular cameras → DKT depth for obstacle/collision avoidance and item interaction; depth repair for transparency.
- Dependencies/assumptions: Controlled lighting, compute module, occasional scale anchors (fiducials or map-based scaling).
- Solar panel and reflective asset inspection
- Sectors: Energy, Industrial Inspection
- Use case: Depth/normal cues on specular surfaces improve defect/soiling detection; better robot/drone proximity sensing on shiny assets.
- Workflow/tools: DKT depth + DKT‑Normal integrated into inspection pipelines; threshold-based alerts on normal discontinuities.
- Dependencies/assumptions: Outdoor illumination variability; stabilization for drones; metric scaling using known geometry.
- Academic benchmarking and data generation with TransPhy3D
- Sectors: Academia, R&D
- Use case: Train/benchmark transparency-aware depth/normal methods; ablation of optical phenomena and motion patterns.
- Workflow/tools: TransPhy3D dataset, Blender/Cycles rendering scripts, DKT LoRA adapters for rapid fine-tuning.
- Dependencies/assumptions: Compute for rendering/model training; license compliance for WAN-like video diffusion backbones.
- Policy and procurement guidance for transparency-safe robotics
- Sectors: Policy, Safety, Standards, Enterprise IT/OT
- Use case: Update internal test protocols and acceptance criteria to include transparent-object benchmarks (e.g., ClearPose/DREDS/TransPhy3D‑Test).
- Workflow/tools: Standardized test scenes with glass/semi‑transparent items; require temporal consistency metrics (δ thresholds, REL, RMSE) in vendor evaluations.
- Dependencies/assumptions: Access to test datasets/scenes; agreement on evaluation metrics and scale setting.
Long-Term Applications
- Edge‑native, real-time transparent-object perception
- Sectors: Robotics, AR/MR, Mobile
- Use case: Sub‑100 ms/frame at HD on ARM/edge NPUs for household robots, AR glasses, mobile apps.
- Enablers: Model distillation, pruning, TensorRT/ONNX runtimes, 8‑bit/4‑bit quantization, architecture search.
- Dependencies/assumptions: Maintained temporal consistency under compression; hardware‑specific kernels.
- Monocular‑first depth sensors (“software depth cameras”)
- Sectors: Vision Hardware, OEMs
- Use case: Cameras bundling a DKT‑like engine to provide transparency‑robust depth without ToF/LiDAR.
- Enablers: Co‑designed ISP + NN accelerators; on‑sensor metric scaling (markerless SLAM or scene priors).
- Dependencies/assumptions: Energy/thermal budget; privacy and on‑device inference constraints.
- Generalized generative perception stacks (depth, normals, optical flow, albedo)
- Sectors: Robotics, Autonomous Systems, Media
- Use case: Multi‑task video diffusion backbones repurposed with LoRA for multiple dense perception heads with temporal coherence.
- Enablers: Joint co‑training on synthetic video corpora (e.g., TransPhy3D‑like) plus real‑world self‑supervision.
- Dependencies/assumptions: Avoiding catastrophic forgetting; unified latency budgets.
- Self‑calibrating metric depth without markers
- Sectors: Robotics, AR/MR, Mapping
- Use case: Automatic metric scaling via joint visual‑inertial odometry, known-object priors, or learned scale estimators.
- Enablers: Fusion of DKT with SLAM/VIO; geometric consistency constraints across long trajectories.
- Dependencies/assumptions: Sufficient parallax/baseline; stable IMU and calibration.
- Standardization of transparency perception benchmarks
- Sectors: Standards Bodies, Industry Consortia
- Use case: ISO/ASTM‑like test suites and scorecards for robots and cameras in transparency‑rich environments.
- Enablers: Open datasets (ClearPose, DREDS, TransPhy3D), unified metrics (δ, REL, temporal profiles), repeatable scenes.
- Dependencies/assumptions: Cross‑industry collaboration; align on metric scaling protocols.
- Safer human‑robot collaboration around glass/metal
- Sectors: Industrial Robotics, Facilities
- Use case: Risk‑aware planning and speed/separation monitoring that remain reliable near transparent barriers and shiny floors.
- Enablers: DKT‑based occupancy and free‑space estimation with consistency checks; redundancy with conventional sensors.
- Dependencies/assumptions: Functional safety certification; fail‑safe design and monitoring.
- Advanced AR content authoring and VFX with transparency‑aware geometry
- Sectors: Media, VFX, Design
- Use case: Precise virtual‑real compositing around glass/fluids; automatic capture of normals for relighting and reflection control.
- Enablers: DKT‑Normal + depth integrated into DCC tools (Maya, Blender, Nuke) and game engines.
- Dependencies/assumptions: Toolchain plug‑ins; temporal stability for long shots.
- Healthcare and laboratory automation
- Sectors: Healthcare, Biotech
- Use case: Handling transparent labware (pipettes, tubes), reflective surgical instruments; robot perception in sterile glassware environments.
- Enablers: Sterile‑safe robots with monocular perception; DKT‑Normal for tool orientation and surface quality checks.
- Dependencies/assumptions: Medical certifications, strict reliability, cleanroom lighting constraints.
- Infrastructure inspection of transparent/reflective assets
- Sectors: Transportation, Buildings, Energy
- Use case: Drones/UGVs assessing glass facades, mirrors, and PV arrays under varying lighting with robust depth/normal estimates.
- Enablers: Sensor fusion (polarization, HDR), trajectory planning to maximize observability.
- Dependencies/assumptions: Domain generalization to outdoor specularities and caustics; compute on airborne platforms.
- Synthetic-to-real transfer platforms for material-aware robotics
- Sectors: Robotics R&D, Simulation
- Use case: Use TransPhy3D‑style physics‑aware rendering to train perception/manipulation policies that generalize to real transparent/reflective objects.
- Enablers: Differentiable/simulation toolchains, domain randomization across materials, co‑training strategies that mix frames and videos (as in DKT).
- Dependencies/assumptions: Expanded simulators for complex refraction/fluids; sample‑efficient sim2real adaptation.
Notes on feasibility across applications:
- Compute: The reported DKT‑1.3B runs at ~0.17 s/frame at 832×480 with ~11 GB GPU memory; larger models improve accuracy but raise latency/memory.
- Metric scale: DKT yields relative depth; converting to metric requires tags, known dimensions, VIO/SLAM, or sensor fusion.
- Generalization: Training included circular camera trajectories; extreme motion blur, low light, or out‑of‑distribution materials/liquids may degrade performance.
- Licensing and IP: Availability and licensing of base video diffusion backbones (e.g., WAN) and LoRA adaptations determine deployability.
- Safety and validation: For safety‑critical use (industrial/medical), formal validation, redundancy, and certification are prerequisites.
Glossary
- 6-DOF (six-degree-of-freedom): The six independent parameters defining an object's pose (three for position, three for orientation). "six-degree-of-freedom (6-DOF) poses"
- 7-DoF grasp pose: A robotic grasp specification including the end-effector’s full pose and gripper width. "generate a 7-DoF grasp pose (end-effector pose + gripper width)."
- AdamW: An optimizer variant of Adam with decoupled weight decay for improved regularization. "using AdamW~\cite{loshchilov2017decoupled}"
- AprilTag: A visual fiducial system used for pose estimation and scene scaling/calibration. "These are then rescaled to metric depth using AprilTag~\cite{wang2016apriltag}."
- CAD model recovery: Reconstructing object geometry by fitting or retrieving CAD models from RGB-D data. "RGB-D capture followed by CAD model recoveryâfails to account for background information"
- Co-training: Jointly training on heterogeneous datasets (e.g., image- and video-based) to improve generalization. "we introduce a co-training strategy that enables joint training on a mixture of frame-wise and video data."
- Complementary weight (for segment stitching): A weighting scheme applied to overlapping regions when merging video segments to ensure smooth transitions. "stitched together using a complementary weight applied to the overlapping regions."
- Cycles (Blender’s ray tracing engine): Blender’s path-tracing renderer used for physically accurate light transport. "We then utilize Blender's ray tracing engine, Cycles, to perform physically accurate lighting calculations and material rendering."
- Denoising diffusion process: A generative process that iteratively removes noise to recover data samples from latent variables. "to model a unified denoising diffusion process."
- DiT (Diffusion Transformer): A transformer architecture for diffusion modeling that operates over latent representations. "a diffusion transformer consisting of multiple DiT blocks,"
- DINO: A self-supervised vision transformer producing robust visual features for downstream tasks. "such as DINO \cite{caron2021emerging},"
- Disparity: The inverse of depth or pixel shift between stereo views, often used as an alternative target to depth. "the depth video in one pair is converted to disparity."
- Domain randomization: Systematic variation of scene parameters in simulation to improve real-world generalization. "relied on physically-based rendering (PBR) and careful domain randomization."
- Flow matching: A training framework that learns vector fields to match probability flows, unifying diffusion-style denoising. "WAN leverages the flow matching framework~\cite{lipman2024flow}"
- Global alignment: A post-processing step that adjusts predictions to align with ground truth across an entire sequence. "as even a minor error can lead to a significant decline in prediction accuracy after global alignment."
- Global scale and shift (alignment): A normalization applied to predicted depth to match ground-truth scale and offset. "the predictions are aligned with the ground truth using a global scale and shift."
- Latent space: A compressed representation space where models encode and process data for generation or translation. "The VAE compresses input videos into latent space and decodes predicted latents back to image space."
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning technique that injects trainable low-rank updates. "All model components remain frozen except for a small set of trainable LoRA \cite{hu2022lora} parameters in the DiT, which learn low-rank weight adaptations."
- Metric depth: Depth measured in physical units (e.g., meters), as opposed to relative or arbitrary scales. "These are then rescaled to metric depth using AprilTag~\cite{wang2016apriltag}."
- NVIDIA OptiX-Denoiser: A GPU-accelerated denoising tool that reduces noise in ray-traced images. "As a final step, we use the NVIDIA OptiX-Denoiser to optimize image quality."
- Optical priors: Learned assumptions about light transport and material interactions that guide perception. "These approaches implicitly learn optical priors,"
- Physically Based Rendering (PBR): Rendering that models physical light-material interactions for realism. "physically-based rendering (PBR) and careful domain randomization."
- Physically based ray tracing: Light transport simulation via ray tracing that adheres to physical laws (e.g., reflection, refraction). "render RGB + depth + normals with physically based ray tracing and OptiX denoising."
- Procedural assets: Algorithmically generated 3D models whose shapes vary by parameters for rich diversity. "shape-rich procedural assets"
- RealSense L515: A LiDAR-based depth camera used for capturing real-world RGB-D sequences. "using the RealSense L515 depth camera."
- Stereo correspondence: Matching features across stereo image pairs to infer disparity and depth. "rely on time-of-flight measurements or stereo correspondence \cite{11128401, wei2024d}."
- Temporal consistency: Stability of predictions across consecutive frames in a video sequence. "they continue to suffer from a lack of temporal consistency across frame sequences"
- Temporal profile: A visualization that slices predictions over time to assess consistency. "we present a temporal profile to better illustrate the temporal consistency of the predicted video depth."
- Time-of-flight (ToF): A sensing modality estimating depth by measuring the travel time of emitted light. "behind stereo, ToF and purely discriminative monocular depth"
- VAE (Variational Autoencoder): A generative model that encodes data into latents and decodes them back, facilitating diffusion. "a VAE, a diffusion transformer consisting of multiple DiT blocks, and a text encoder."
- VDM (Video Diffusion Model): A diffusion-based generative model that synthesizes or translates video sequences. "With recent advances in Video Diffusion Model (VDM) \cite{deepmind2024veo, wan2025},"
- Velocity predictor: The network component that estimates the velocity (time derivative) in flow matching. "The loss function is MSE between the output of a velocity predictor and "
- Video-to-video translation: Transforming an input video into another modality (e.g., RGB to depth) while preserving temporal structure. "reframing it from a discriminative estimation task to a video-to-video translation problem."
- Zero-shot: Evaluating a model on new datasets or tasks without further supervised fine-tuning on them. "achieves zero-shot SOTA on real and synthetic video benchmarks"
Collections
Sign up for free to add this paper to one or more collections.

