- The paper introduces a novel geometry-guided framework that leverages plane-aware depth maps and generative priors for accurate 3D scene reconstruction.
- It employs robust techniques like K-means clustering and RANSAC to achieve scale-accurate depth estimation even in unobserved regions.
- Experimental results on multiple datasets demonstrate significant improvements in geometric fidelity and rendering quality over existing methods.
Geometry-Guided Gaussian Splatting with Generative Prior: Technical Summary
Introduction and Motivation
The paper introduces G4Splat, a geometry-guided generative framework for 3D scene reconstruction that integrates scale-accurate geometric constraints with generative priors from diffusion models. The motivation stems from two critical limitations in prior generative 3DGS approaches: (1) unreliable geometric supervision, which impairs reconstruction quality in both observed and unobserved regions, and (2) multi-view inconsistencies in generative outputs, leading to shape–appearance ambiguities and degraded geometry. G4Splat addresses these by leveraging the prevalence of planar structures in man-made environments to derive accurate metric-scale depth maps and by incorporating geometry guidance throughout the generative pipeline.
Plane-Aware Geometry Modeling
G4Splat’s core innovation is the extraction and utilization of global 3D planes for scale-accurate depth supervision. The method first segments planar regions in each input image using normal maps and instance masks (SAM), followed by K-means clustering. These 2D plane masks are then merged across views using a 3D point cloud to form globally consistent 3D planes, fitted via RANSAC. For each view, depth for planar regions is computed by ray-plane intersection, while non-planar regions use a monocular depth estimator aligned to the plane depths via linear transformation. This yields plane-aware depth maps that provide robust geometric supervision even in unobserved regions.



Figure 1: Visualization of intermediate results. G4Splat corrects errors in non-overlapping regions, improves visibility mask estimation, and enhances novel view selection for seamless reconstruction.
Geometry-Guided Generative Pipeline
The generative pipeline is tightly coupled with geometry guidance:
Training Strategy
The training process consists of an initialization stage (using MAtCha chart alignment for initial depth and Gaussian parameters) followed by iterative geometry-guided generative loops. Each loop updates the visibility grid, selects novel views, inpaints missing regions, and retrains the Gaussian representation with updated supervision. The loss function extends MAtCha’s formulation, enhancing the structure loss with plane-aware depth and normals.
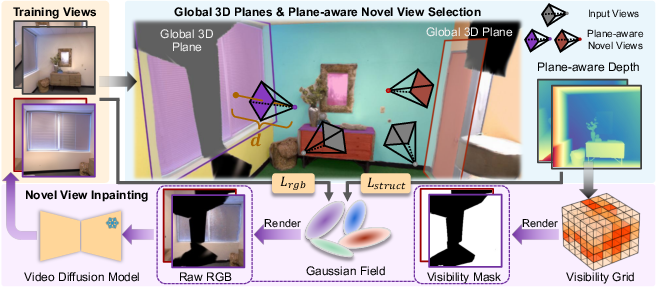
Figure 3: Overview of the G4Splat training loop, integrating plane extraction, visibility grid construction, novel view selection, inpainting, and iterative refinement.
Experimental Results
G4Splat is evaluated on Replica, ScanNet++, and DeepBlending datasets, outperforming all baselines (3DGS, 2DGS, FSGS, InstantSplat, MAtCha, GenFusion, Difix3D+, GuidedVD, See3D) in both geometry and appearance metrics, especially in unobserved regions. Quantitative results show significant improvements in Chamfer Distance, F-Score, Normal Consistency, PSNR, SSIM, and LPIPS. Ablation studies confirm the necessity of each component: generative prior alone improves rendering but not geometry; plane-aware modeling is essential for geometric fidelity; and the geometry-guided pipeline further enhances consistency and appearance.

Figure 4: Any-view scene reconstruction. G4Splat generalizes to indoor/outdoor, unposed, and single-view scenes.

Figure 5: More results of single-view reconstruction. High-quality geometry and realistic texture recovery are achieved from a single input image.

Figure 6: Dense view reconstruction comparison. G4Splat maintains high fidelity even with dense input views and complex lighting.

Figure 7: Training results with inconsistent vs. consistent multi-view inpainting. Geometry guidance reduces artifacts and improves rendering sharpness.

Figure 8: More qualitative results. G4Splat consistently alleviates shape–appearance ambiguities across diverse scenarios.
Discussion and Limitations
The plane representation is chosen for its prevalence in man-made environments, generalization capability, and computational efficiency. G4Splat’s memory footprint is lower than chart-based methods, and its CUDA-parallelized computations enable scalability. However, limitations remain: generative models may produce color inconsistencies in completed regions, and heavily occluded areas are challenging. The reliance on plane representations may limit accuracy in non-planar regions, suggesting future work on more general surface models.

Figure 9: Failure cases. Limitations include color inconsistencies from generative models and difficulties with heavily occluded regions.
Implications and Future Directions
G4Splat demonstrates that robust geometry guidance is fundamental for exploiting generative priors in 3D scene reconstruction. The integration of plane-aware depth with generative inpainting sets a new standard for fidelity and consistency, especially in sparse-view and unposed scenarios. The method’s generalizability to single-view and video inputs opens avenues for practical deployment in robotics, embodied AI, and VFX. Future research may focus on extending geometric representations beyond planes, improving generative model consistency, and incorporating object-level priors for occlusion handling.
Conclusion
G4Splat presents a geometry-guided generative framework that leverages plane representations for scale-accurate depth and integrates this guidance throughout the generative pipeline. The approach achieves state-of-the-art results in both geometry and appearance reconstruction, particularly in unobserved regions, and generalizes to diverse input scenarios. The method’s design and empirical performance suggest strong potential for real-world applications and further advances in generative 3D scene reconstruction.
