- The paper demonstrates that incorporating the transfer gap quantifies the balance between pre-training and fine-tuning efficiency.
- Experimental results on diverse datasets validate a scaling law with robust parameter estimation using the Pythia model suite.
- Findings guide efficient resource allocation, influencing training strategies for large-scale transformer models.
An Empirical Study of Scaling Laws for Transfer
This essay discusses the paper "An Empirical Study of Scaling Laws for Transfer" (2408.16947), which presents a detailed examination of scaling laws, particularly focusing on transfer learning in transformer models. The study explores how various factors such as pre-training and fine-tuning data affect model performance, providing insights into efficient data allocation for optimal model performance.
Overview and Objectives
The paper addresses the significant question of how data allocation between pre-training and fine-tuning affects transfer learning outcomes. The authors introduce a scaling law that incorporates a "transfer gap" term, which measures the effectiveness of pre-training on one distribution for optimizing downstream performance on another. The main objective is to determine under which conditions pre-training or fine-tuning is more effective, based on empirical observations from diverse datasets.
Experimental Setup and Methodology
The authors employ the Pythia model suite, leveraging a 2.8 billion parameter transformer model pre-trained on the Pile, and conduct extensive fine-tuning experiments across a variety of datasets. The investigation focuses on fitting a scaling law to empirical data, where the primary variables are the number of pre-training steps p and the number of fine-tuning data points f.
The key scaling law proposed is:
L(p,f)=(A⋅p−α+G)⋅f−β+E
Here, A, G, E, α, and β are the parameters fitted to the data, with G representing the transfer gap—a measure of pre-training effectiveness.
Results and Observations
Key Findings:
- Transfer Gap Analysis: The transfer gap G varies significantly across datasets, indicating that the degree of transfer is contingent upon the specific fine-tuning task. This reflects how pre-training can be more cost-effective in certain scenarios vis-à-vis high-quality fine-tuning data.
- Pre-training vs. Fine-tuning:
For datasets such as the fictional encyclopedia, pre-training was found to be more beneficial at lower levels, whereas datasets like the math arXiv showed sustained benefits even at higher pre-training levels. This suggests the strategic allocation of computational resources depending on G.
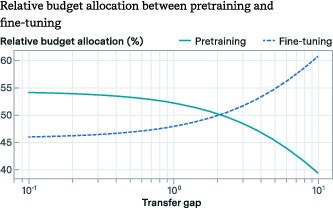
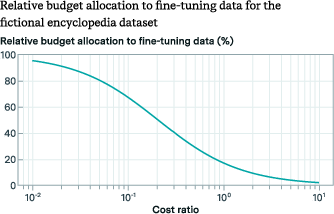
Figure 1: Budget allocation vs. transfer gap G.
Parameter Estimation:
Despite the limited experimental setup (150 data points per dataset), the achieved parameter estimates were robust, as indicated by narrow confidence intervals. This reinforces the potential of the proposed scaling law to guide data allocation strategies with relatively modest computational resources.
Discussion on Practical Implications
The empirical study highlights significant implications for designing training strategies for large-scale models. Understanding the transfer gap can direct the decision between allocating resources to pre-training versus extensive fine-tuning. For tasks where transfer gaps are minimal, large-scale pre-training on diverse data can be more cost-efficient than gathering extensive fine-tuning datasets.
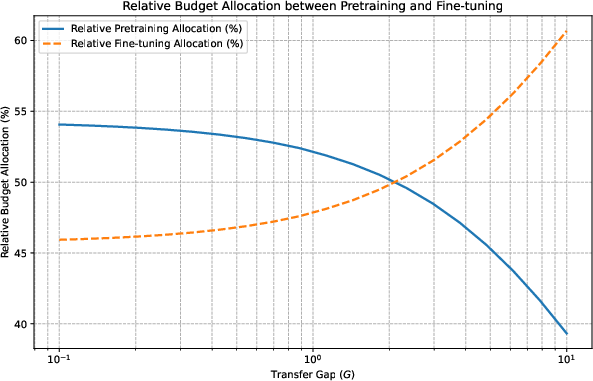
Figure 2: Optimal budget allocation as transfer gap G increases.
Moreover, the authors speculate that the transfer gap could intuitively inform challenges in domains like robotics, where data diversity from pre-training sources is critical. The study suggests future work may explore the interplay between model size and transfer gaps, potentially influencing pre-training dynamics.
Conclusion
In conclusion, the paper offers a comprehensive empirical analysis of scaling laws for transfer learning, providing valuable insights into optimizing data strategies for training transformer models. The introduced concept of the transfer gap serves as a pivotal mechanism to assess the relative cost-effectiveness of pre-training versus fine-tuning, underscoring its critical role in designing efficient machine learning models. The findings indicate promising avenues for continued research, such as exploring model size impacts on transfer efficiency and validating these scaling laws on more complex tasks and models.