- The paper introduces a large-scale synthetic persona framework that enhances LLMs for customized role-playing dialogue generation.
- It details two response strategies—rewriting and generation—demonstrating improved persona consistency and linguistic habits using fine-tuning on LLaMA-3 8B models.
- Evaluations on the PersonaGym benchmark show significant advancements over baselines, highlighting practical benefits for virtual assistants and game NPCs.
OpenCharacter: Training Customizable Role-Playing LLMs with Large-Scale Synthetic Personas
Introduction
The research addresses the challenge of equipping LLMs with character generalization capabilities to handle customizable role-playing dialogue tasks. As applications like game NPCs and virtual assistants demand versatile models, synthesizing character data becomes vital. This study utilizes synthetic data to expand the abilities of LLMs beyond pre-set characters, allowing adaptability to user-customized characters. The approach hinges on leveraging data synthesis to create diverse character profiles and dialogue enriched with character-specific styles and knowledge.
Data Synthesis Framework
A central facet of this approach is synthesizing character data at scale. Persona Hub, a repository containing large-scale synthetic personas, serves as the foundation for creating detailed character profiles that embody unique personas. The process involves two main strategies:
- Character Profile Synthesis: This begins with a persona's brief description, from which a detailed profile including aspects like personality and experience is generated. This synthesis forms the backbone of character-specific responses.
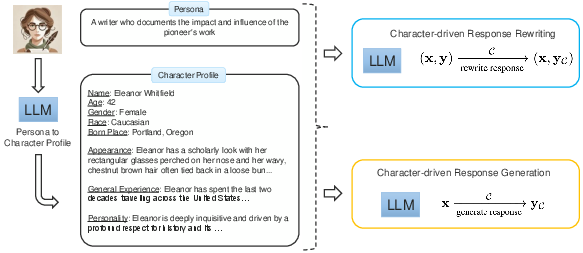
Figure 1: Our overall data synthesis approach. As an example, we start with character profile synthesis using a persona from Persona Hub, and then explore character-driven response rewriting and generation.
- Response Strategies:
Implementation and Training
The trained models utilize the LLaMA-3 8B model fine-tuned with character-enriched dialogues to evaluate character generalization capabilities. The process critically examines the model's ability to adapt to unseen character profiles provided during the inference stage. By encompassing a vast dataset of human-like synthetic characters and dialogue pairs, the models are equipped to perform in out-of-domain scenarios.
The models' effectiveness is assessed using the PersonaGym benchmark, which tests across multiple metrics such as linguistical habits and persona consistency. OpenCharacter models demonstrate superior performance compared to baseline models and some GPT variants, notably improving persona consistency and linguistic habits without additional manual fine-tuning data.
Table comparisons reveal advancements over standard LLMs, where the OpenCharacter approaches, particularly those leveraging OpenCharacter-G, excel in offering richness in character-driven dialogues, even with smaller models like LLaMA-3-8B-Instruct versus larger counterparts.
Conclusion
This study contributes to AI by demonstrating the feasibility of character generalization through large-scale synthetic data, thus enabling more adaptable and context-aware dialogue systems. The role of synthetic character data in enhancing LLMs underscores potential advancements in virtual environments, where domain-specific reasoning and character consistency are crucial. Future inquiries may explore resolving domain-specific knowledge discrepancies and optimizing character synthesis for particular applications, marking a leap forward in AI's applicability in enriched narrative contexts.
