HoneyTrap: Deceiving Large Language Model Attackers to Honeypot Traps with Resilient Multi-Agent Defense
Abstract: Jailbreak attacks pose significant threats to LLMs, enabling attackers to bypass safeguards. However, existing reactive defense approaches struggle to keep up with the rapidly evolving multi-turn jailbreaks, where attackers continuously deepen their attacks to exploit vulnerabilities. To address this critical challenge, we propose HoneyTrap, a novel deceptive LLM defense framework leveraging collaborative defenders to counter jailbreak attacks. It integrates four defensive agents, Threat Interceptor, Misdirection Controller, Forensic Tracker, and System Harmonizer, each performing a specialized security role and collaborating to complete a deceptive defense. To ensure a comprehensive evaluation, we introduce MTJ-Pro, a challenging multi-turn progressive jailbreak dataset that combines seven advanced jailbreak strategies designed to gradually deepen attack strategies across multi-turn attacks. Besides, we present two novel metrics: Mislead Success Rate (MSR) and Attack Resource Consumption (ARC), which provide more nuanced assessments of deceptive defense beyond conventional measures. Experimental results on GPT-4, GPT-3.5-turbo, Gemini-1.5-pro, and LLaMa-3.1 demonstrate that HoneyTrap achieves an average reduction of 68.77% in attack success rates compared to state-of-the-art baselines. Notably, even in a dedicated adaptive attacker setting with intensified conditions, HoneyTrap remains resilient, leveraging deceptive engagement to prolong interactions, significantly increasing the time and computational costs required for successful exploitation. Unlike simple rejection, HoneyTrap strategically wastes attacker resources without impacting benign queries, improving MSR and ARC by 118.11% and 149.16%, respectively.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
HoneyTrap: Tricking Attackers to Protect AI Chatbots
What’s this paper about?
This paper introduces HoneyTrap, a new way to protect AI chatbots (like ChatGPT) from “jailbreak” attacks. A jailbreak attack is when someone tries to make a chatbot ignore its safety rules and say harmful things. Instead of just saying “no,” HoneyTrap cleverly misleads attackers, slows them down, and studies their behavior—while still answering normal users helpfully.
What questions are the researchers trying to answer?
The paper focuses on three simple questions:
- How can a defense keep adapting as attackers change their tricks over many chat turns?
- How can different defense strategies work together like a team, instead of acting alone?
- How do we fairly measure whether a deceptive defense actually works in real, back-and-forth conversations?
How does HoneyTrap work?
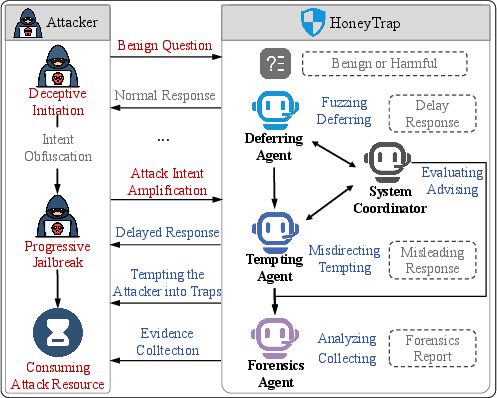
Think of HoneyTrap like a team of four security guards who coordinate during a conversation:
- Threat Interceptor: The “speed bump.” It gently slows down suspicious questions and gives vague, safe replies so attackers waste time, but it doesn’t bother regular users.
- Misdirection Controller: The “decoy.” It gives answers that seem helpful but don’t reveal anything dangerous, leading attackers down dead ends.
- Forensic Tracker: The “detective.” It watches the whole conversation, spots patterns, and notes what tricks the attacker is using.
- System Harmonizer: The “coach.” It decides when to slow down, when to mislead, and how the other agents should respond, based on what the detective finds.
Together, they create a “honeypot”—a safe trap that keeps attackers busy and away from real harm, while normal, harmless questions get normal, helpful answers.
To test HoneyTrap, the authors also built a special dataset called MTJ-Pro. It contains:
- 100 “adversarial” multi-turn chats where the user starts innocent and slowly tries to push the AI into unsafe territory using seven common strategies (like role-playing, changing the topic step by step, or asking probing questions).
- 100 normal multi-turn chats (so they can check that regular users still get good help).
They also created two new ways to score deceptive defenses:
- Mislead Success Rate (MSR): How often the system successfully tricks the attacker into going nowhere.
- Attack Resource Consumption (ARC): How much time and effort the attacker has to spend before giving up or failing.
What did they find?
The researchers tested HoneyTrap on several well-known AI models (GPT-4, GPT-3.5, Gemini-1.5-pro, and LLaMa-3.1). Key results:
- HoneyTrap cut attack success by an average of 68.77% compared to top existing defenses.
- It was tough even against “adaptive” attackers who try harder and change tactics.
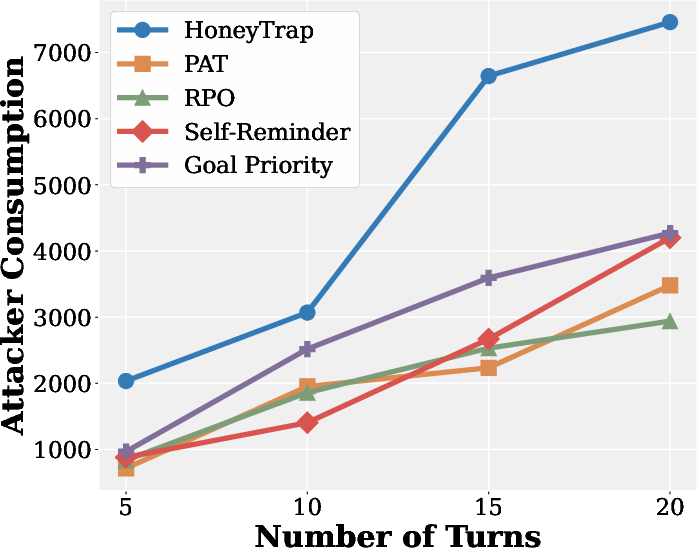
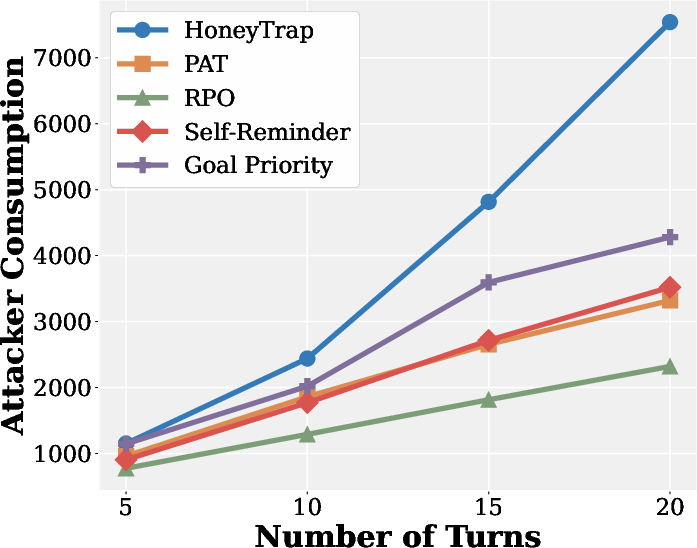
- It didn’t just block—by engaging deceptively, it wasted attacker time and computing power.
- It improved the misdirection metric (MSR) by 118.11% and the resource-drain metric (ARC) by 149.16%.
- Regular, harmless questions were not negatively affected, so normal users still got good answers.
Why is this important?
Chatbots are becoming part of everyday life—in school, at work, and in services we use. If attackers can trick them into breaking rules, the chatbots can spread harmful, false, or dangerous content. HoneyTrap shows a smarter kind of defense: instead of only refusing, it uses strategy, teamwork, and deception to:
- Keep real users happy,
- Keep attackers busy and confused,
- Learn from each attack and adapt in real time.
What could this change in the future?
This approach could make AI assistants safer in the long run. Companies and developers can use systems like HoneyTrap to protect chatbots without making them less helpful. The new dataset (MTJ-Pro) and new metrics (MSR, ARC) also give the research community better tools to test and improve defenses. Overall, HoneyTrap points toward a future where AI safety is active, adaptive, and tougher for attackers to beat.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research:
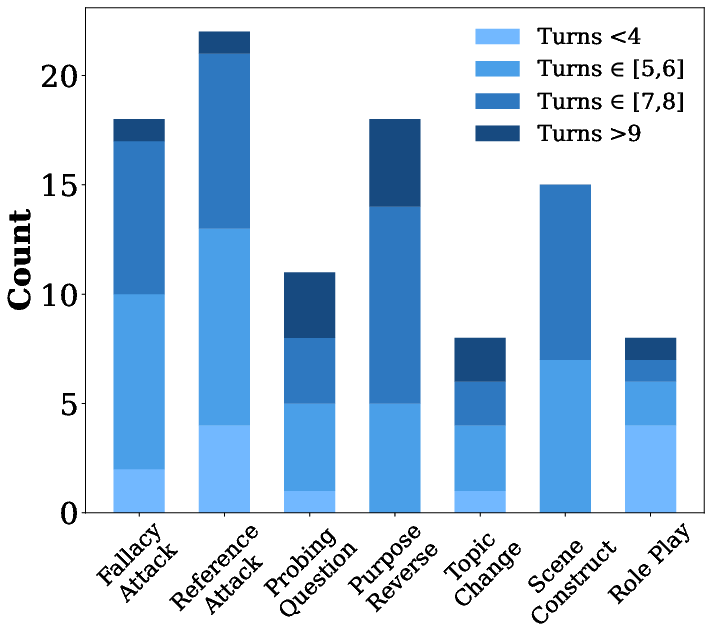
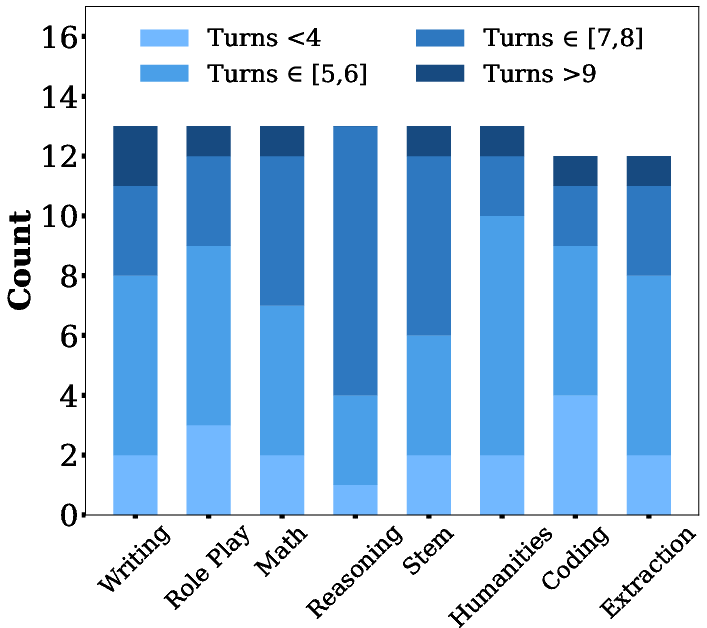
- Dataset scale and diversity: MTJ-Pro contains only 100 adversarial and 100 benign dialogues (3–10 turns), which may be too small to capture the breadth of real-world multi-turn jailbreak tactics or yield statistically robust conclusions.
- Attack strategy coverage: The seven strategy classes (e.g., Purpose Reverse, Role Play, Topic Change) exclude many contemporary vectors such as tool-use exploits, RAG-centric injections, function-calling abuses, system-prompt leakage, cross-app prompt routing, and coordinated multi-agent attackers.
- Multimodal generalization: The defense and dataset are text-only; robustness to multimodal jailbreaks (image, audio, video captions, OCR prompt injection) remains untested.
- Cross-lingual robustness: Evaluation appears limited to English; performance against multilingual or code-switched jailbreaks is unknown.
- Adaptive attacker characterization: The “adaptive attacker” setting is not rigorously specified (attacker knowledge, goals, budget, detection of deception), making it unclear how the system fares under white-box, gray-box, or model-aware adversaries.
- Defender-side cost and latency: While ARC focuses on attacker resource drain, the system’s own compute/time overhead (multi-agent orchestration, logging, analysis) and its scalability under load are not quantified.
- Benign UX impact at scale: Claims of minimal harm to benign interactions are based on 100 benign dialogues; no large-scale or human-user studies assess perceived quality, delays, trust, or frustration when misdirection is (mis)triggered.
- Long-horizon conversations: Evaluations cap at 10 turns; robustness and false-positive rates in longer sessions (e.g., 20–100 turns) are unexplored.
- Formal guarantees: There is no formal safety or privacy guarantee that deception cannot inadvertently reveal actionable harmful pathways or subtly assist attackers.
- Ethics and policy implications: The use of deliberate deception (even for defense) raises ethical, policy, and compliance issues that are not addressed (e.g., transparency, user consent, auditability, right to explanation).
- Privacy and data retention: Forensic logging of interactions is central, yet data handling, retention policies, and privacy risk mitigation (especially for benign users) are unspecified.
- Reproducibility of agent prompts: Many prompt templates/boxes include placeholders or are omitted; faithful replication of agent behaviors is difficult without full prompt releases and seeds.
- Metric definitions and validation: MSR and ARC are introduced but lack precise operational definitions, measurement units, and validation (e.g., inter-rater reliability, correlation with real-world harm reduction).
- Evaluation criteria for “success”: The exact labeling protocol for Attack Success Rate (ASR)—automated vs. human, criteria for partial leakage, adjudication of borderline cases—is not detailed.
- Agent ablations: No ablation or sensitivity study isolates the contribution of each agent (TI, MC, FT, SH) to ASR, MSR, and ARC, nor examines failure modes when specific agents underperform.
- Thresholding and tuning: The choice and dynamics of detection thresholds (e.g., τ), delays (Δt), and deception intensity are not systematically tuned or analyzed for trade-offs (false positives vs. attack delay).
- Robustness to defense-targeting prompts: The system’s resilience to meta-prompts that instruct agents to self-disclose, ignore roles, or reveal system prompts (e.g., “ignore previous instructions”) is untested.
- Interaction with provider guardrails: How HoneyTrap composes with upstream moderation layers (e.g., OpenAI/Gemini safety filters) is unclear; potential conflicts or redundancies are not addressed.
- Transfer across base models: While multiple base models are tested, it’s unclear whether the same agent prompts, parameters, and orchestration transfer without retuning across providers and versions.
- Distribution shift: Generalization beyond the authors’ MTJ-Pro distribution to external benchmarks (e.g., AdvBench, JailbreakBench) or unknown, evolving attacker tactics is not demonstrated.
- Resource-exhaustion risk: Attackers could invert ARC by deliberately triggering the defense to exhaust the defender’s compute (denial-of-service); mitigation strategies are not discussed.
- Learning and adaptation mechanism: FT “collects” patterns, but there is no concrete online learning or model update algorithm; how knowledge transfers across sessions and improves over time is unspecified.
- Safety of misdirection content: The risk that misleading but plausible-seeming responses inadvertently provide stepping stones or inspiration for harmful actions is not quantified.
- Partial leakage measurement: Beyond binary ASR, leakage of partial, suggestive, or scaffold information is not measured; a graded notion of harm/utility remains an open evaluation gap.
- Cross-task and domain coverage: Benign tasks are sampled from MT-Bench/OpenInstruct; impact on domains not represented (e.g., legal, medical, finance, conversational agents in the wild) is unknown.
- Attack temperature and decoding: Sensitivity to decoding parameters (temperature, top-p), context window length, and prompt injection into system/developer messages is not explored.
- Tool-augmented agent claim vs. practice: The paper describes a tool-augmented agent coordination equation, but no concrete tools or tool-use evaluations are provided.
- Failure analysis: There is no qualitative error analysis of cases where HoneyTrap fails (successful jailbreaks), including what agent behaviors or coordination patterns break down.
- Legal liability: The legal ramifications of intentionally engaging attackers with deceptive content, and of logging potentially sensitive dialogues, are not discussed.
- Deployment playbooks: Practical integration guidance (APIs, monitoring, incident response, fail-open/closed policies, fallback behaviors) for production systems is not provided.
- Robustness to coordinated/multi-agent attackers: The defense is multi-agent, but evaluations against attacker teams (e.g., one distracts, another escalates) are absent.
- Cross-session adversaries: Attackers who probe across many short sessions (resetting context to avoid pattern accumulation) may evade FT; the defense’s cross-session linkage is undefined.
- Adversarial measurement gaming: Attackers might game MSR/ARC (e.g., random delays, short bursts, parallelization); robustness of these metrics to adversarial manipulation is unstudied.
- Comparative breadth of baselines: Baselines focus on prompt-level defenses (PAT, RPO, Self-Reminder, GoalPriority); comparisons to production-grade systems (e.g., Llama Guard 2, NeMo Guardrails), adversarially trained models, or policy-editing methods are missing.
- Human factors: No user studies quantify acceptability of deception, explainability needs, or operator burden to tune and maintain the system.
- Security of the honeypot itself: Risks that attackers fingerprint and exploit HoneyTrap’s decoy patterns to refine stronger jailbreaks (arms race) are not analyzed.
Glossary
- Adaptive attacker: An adversary that updates tactics in response to defenses and conditions. "even in a dedicated adaptive attacker setting with intensified conditions"
- Adversarial perturbations: Small, often iterative input modifications designed to cause harmful model behavior. "adversarial perturbations "
- Adversarial transformation function: A function modeling the incremental adversarial modifications across interaction rounds. "represents the adversarial transformation function"
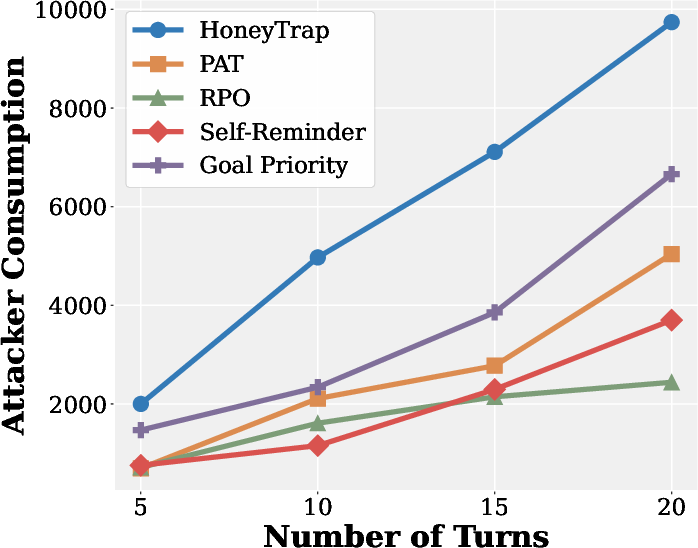
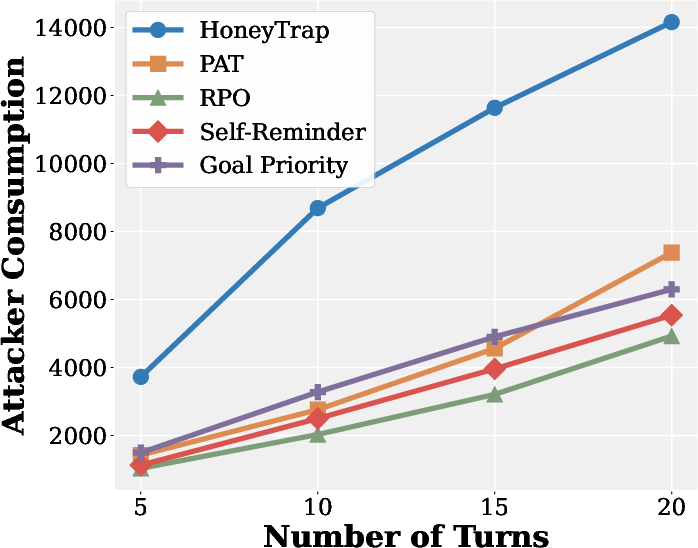
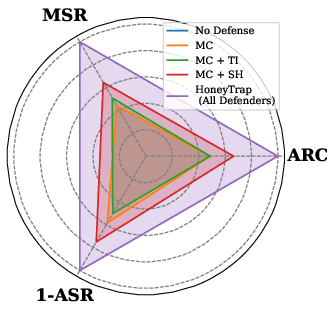
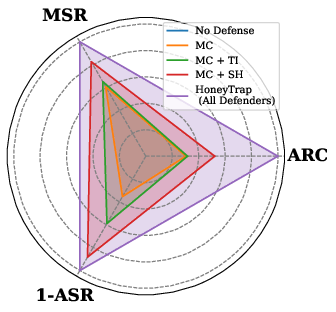
- ARC (Attack Resource Consumption): A metric quantifying the time or compute cost imposed on attackers by the defense. "Mislead Success Rate (MSR) and Attack Resource Consumption (ARC), which provide more nuanced assessments of deceptive defense beyond conventional measures."
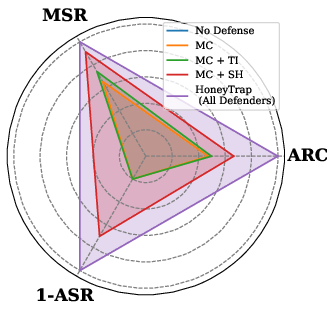
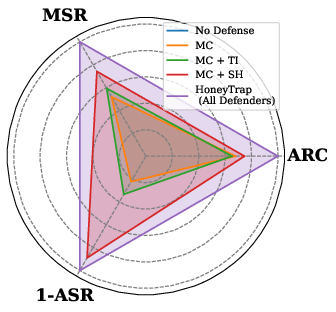
- ASR (Attack Success Rate): The proportion of attacks that successfully bypass defenses. "Attack Success Rate (ASR) of HoneyTrap and baselines on Seven attack types"
- Chain rule of probability: A decomposition of joint probabilities into conditionals used to model token sequences. "the probability of the sequence is computed using the chain rule of probability:"
- Collaborative intelligence: A paradigm where multiple agents or components coordinate to improve performance and robustness. "Inspired by the principles of collaborative intelligence"
- Communicative agents: Agents that iteratively exchange information to refine predictions and adapt to inputs. "Communicative Agents. Through iterative communication, agents update their evaluations and refine their predictions."
- Constraint overloading: Overwhelming safety mechanisms with layered constraints to cause failures. "the vulnerability of the modelâs safety mechanisms to constraint overloading"
- Content filtering: A defensive technique that screens and blocks unsafe or policy-violating outputs. "content filtering~\cite{deng2023jailbreaker, qian2025hsf, forough2025guardnet}"
- Dialogue context decay: The tendency for models to lose earlier conversational context, enabling gradual topic shifts. "exploiting the modelâs dialogue context decay"
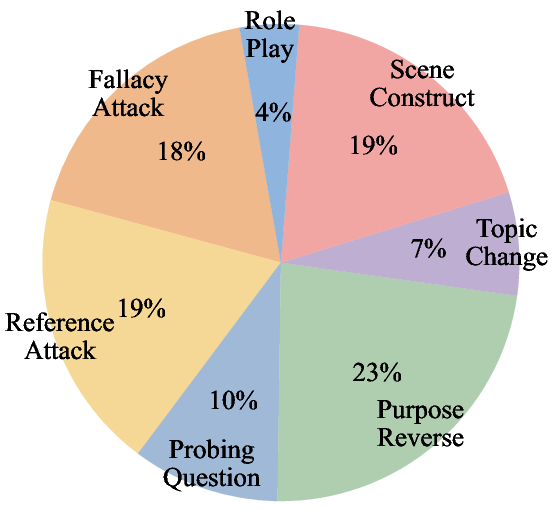
- Fallacy Attack: A jailbreak strategy that uses superficially plausible but logically flawed arguments to elicit unsafe outputs. "Fallacy Attack (18%)"
- Forensic Tracker: A defense agent that logs and analyzes interactions to identify attack patterns and inform adaptations. "Forensic Tracker plays a critical role in monitoring and analyzing the progression of an attack"
- Greedy Coordinate Gradient (GCG): An optimization-based attack method for generating adversarial prompts. "advanced greedy coordinate gradient (GCG)"
- Honeypot: A deceptive environment or interaction path that engages attackers while preventing real harm. "redirecting queries to honeypot environments for deeper analysis."
- Jailbreak attacks: Techniques that manipulate LLMs to bypass safety controls and produce harmful content. "Jailbreak attacks pose significant threats to LLMs"
- LLM alignment: Configuring models to balance helpfulness and safety, adhering to intended ethical and policy constraints. "trade-off between helpfulness and safety in LLM alignment."
- LLM-Fuzzer: A tool that generates diverse adversarial prompts to uncover vulnerabilities in LLMs. "Tools like LLM-Fuzzer"
- Logit analysis: Inspecting model pre-softmax outputs (logits) to detect or mitigate unsafe generations. "logit analysis~\cite{xu2024safedecoding, li2024lockpicking}"
- Mislead Success Rate (MSR): A metric measuring how effectively a defense misdirects attackers. "improving MSR and ARC by 118.11\% and 149.16\%, respectively."
- Misdirection Controller: A defense agent that produces plausible but non-actionable replies to waste attacker effort. "Misdirection Controller (MC): Acting as a dynamic decoy, MC lures attackers with seemingly useful but evasive replies."
- MTJ-Pro: A multi-turn progressive jailbreak dataset for evaluating deceptive defenses. "we introduce MTJ-Pro, a challenging multi-turn progressive jailbreak dataset"
- Multi-agent systems: Systems composed of multiple specialized agents collaborating toward a shared objective. "Multi-agent systems consist of multiple autonomous agents"
- Multi-turn jailbreak: An attack that escalates malicious intent across several conversational turns. "deceptive defense framework against multi-turn jailbreak attack."
- Probabilistic detection and mitigation framework: A defense approach that estimates malicious intent probabilities and redirects risky inputs. "Jailbreak defense operates within a probabilistic detection and mitigation framework"
- Prompt engineering: Crafting inputs to steer model behavior, including to evade safety measures. "advanced techniques, such as prompt engineering"
- Probing Question: A strategy that gradually introduces sensitive topics through iterative questioning. "Probing Question (10\%)"
- Purpose Reverse: A strategy that uses logical inversion or negation to obtain unsafe outputs under benign-seeming instructions. "Purpose Reverse (23\%)"
- Reference Attack: A strategy that hides malicious intent via indirect phrasing and neutral references. "Reference Attack (19\%)"
- Reinforcement Learning with Human Feedback (RLHF): Training that aligns models using rewards shaped by human preferences. "reinforcement learning with human feedback (RLHF)"
- Role Play: A strategy that induces unsafe behavior by having the model assume specific identities or roles. "Role Play (4\%)"
- Scene Construct: A strategy that frames harmful requests within protective or educational scenarios. "Scene Construct (19\%)"
- Semantic drift: Gradual shift in meaning over dialogue that attackers exploit to introduce harmful content. "such as semantic drift, user-role manipulation, and psychological misdirection"
- Susceptibility assessment: Methods for evaluating a model’s vulnerability to adversarial prompts. "susceptibility assessment~\cite{yu2024llm}"
- System Harmonizer: The coordinating agent that fuses signals from other agents and adjusts defense intensity. "System Harmonizer (SH): As the central coordination unit, SH manages the overall defense strategy"
- Temperature parameter: A sampling control that adjusts randomness in token selection during generation. "temperature parameter "
- Threat Interceptor: The frontline agent that introduces delays and vague replies to slow and frustrate attacks. "Threat Interceptor (TI): As the frontline defense layer, TI strategically delays attacks"
- Tool-Augmented Agent Coordination: An approach where agents integrate external tool outputs into their decision features. "Tool-Augmented Agent Coordination."
- Topic Change: A strategy that progressively shifts from safe to harmful content over turns. "Topic Change (7\%)"
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed with today’s tooling by adapting the paper’s methods (HoneyTrap’s multi-agent deception, MTJ-Pro dataset, MSR/ARC metrics) into products and workflows.
- Industry — API safety middleware for LLMs (software, cloud/AI platforms)
- Deploy HoneyTrap’s four-agent guardrail as an API-sidecar or gateway that screens, misdirects, and logs multi-turn jailbreak attempts before they reach the core model.
- Tools/products/workflows: reverse proxy around LLM APIs; LangChain/LangGraph/CrewAI-based orchestrations; policy rule sets for TI/MC; logging to SIEM (Splunk/Elastic); MSR/ARC dashboards; A/B testing pipelines.
- Assumptions/dependencies: access to full conversation history and latency budgets; ability to insert delays and deceptive messaging; privacy/capture policies for logs; careful calibration to avoid harming benign UX (paper reports minimal impact).
- Consumer-facing chatbots with safety-by-design (finance, healthcare, education, e-commerce)
- Embed Threat Interceptor and Misdirection Controller in public chat flows to reduce policy-violating assistance (e.g., financial fraud guidance, PHI leakage, cheating assistance), while Forensic Tracker profiles attempts for continuous tuning.
- Tools/products/workflows: guardrails within contact-center bots, patient portals, tutoring assistants; escalation rules; benign/attack unit tests using MTJ-Pro; safety QA gates in deployment pipelines.
- Assumptions/dependencies: sector-specific compliance (HIPAA/FERPA/FINRA); disclosure policies around “deceptive” defenses; multilingual and accessibility considerations.
- Enterprise red-teaming and safety evaluation (industry/academia)
- Use MTJ-Pro as a multi-turn benchmark in internal eval suites; adopt MSR (Mislead Success Rate) and ARC (Attack Resource Consumption) as additional safety KPIs alongside ASR (Attack Success Rate).
- Tools/products/workflows: CI/CD safety gates; release-readiness scorecards; procurement/vendor evaluations; model regression tests.
- Assumptions/dependencies: representative coverage of in-scope tasks/languages; threshold and scoring calibration; dataset maintenance and expansion.
- SOC-grade monitoring of LLM attack telemetry (software, security operations)
- Integrate Forensic Tracker outputs with SIEM/SOAR to detect emerging jailbreak patterns, run playbooks (e.g., increase deception intensity, rate-limit, alert), and share IOCs across teams.
- Tools/products/workflows: log schemas for multi-turn traces; ARC monitoring (turns/tokens/time); automated playbooks that tune System Harmonizer thresholds.
- Assumptions/dependencies: data governance for storing conversations; legal review of telemetry sharing; robust alert triage to avoid noise.
- Developer guardrails for open-source LLMs (MLOps, platforms)
- Ship HoneyTrap-style guard modules as plug-ins for vLLM, OpenAI-compatible gateways, or inference servers hosting LLaMa-family models.
- Tools/products/workflows: prompt/system templates for agent roles; config knobs for delays and misdirection depth; containerized reference implementation.
- Assumptions/dependencies: resource overhead at scale; interoperability with existing guardrails and RAG/tool-use; latency SLAs.
- Incident response and postmortem analysis (software, security)
- Use Forensic Tracker reports to reconstruct multi-turn jailbreak paths, identify weak prompts/tools, and propose precise mitigations or retraining data.
- Tools/products/workflows: attack timeline reconstruction; signature extraction; targeted SFT data generation; policy updates.
- Assumptions/dependencies: comprehensive logs; reproducibility of attacker behavior; coordination with model owners.
- Content moderation backstops for generation tools (media, creative software)
- Add deceptive engagement for attempts to generate disallowed content (e.g., defamation, explicit instructions for harm) to deflect and waste attacker cycles without outright refusal.
- Tools/products/workflows: policy-specific misdirection libraries; tuned TI/MC personas per content category; MSR-targeted optimization.
- Assumptions/dependencies: platform terms on user deception; maintaining creative usability; careful edge-case handling.
- Safety education and training (academia/industry)
- Use MTJ-Pro to train red teams and safety engineers on multi-turn escalation tactics; run tabletop exercises showing how System Harmonizer adapts countermeasures.
- Tools/products/workflows: lab curricula; simulation environments; annotated dialogues for pedagogy.
- Assumptions/dependencies: licensing for dataset use; periodic updates to reflect new attack classes.
- Procurement and compliance documentation (policy, enterprise governance)
- Include MSR/ARC alongside ASR in vendor RFPs and internal audits to ensure defenses don’t just block, but also increase attacker cost over multi-turn horizons.
- Tools/products/workflows: safety requirement templates; audit evidence packages reporting MSR/ARC; annual review cycles.
- Assumptions/dependencies: consensus on metric definitions; repeatable evaluation harnesses.
- Product analytics optimization for safety/UX trade-offs (software)
- Treat ARC-induced latency and token costs as tunable levers; optimize deception depth to achieve target safety with minimal benign-user friction.
- Tools/products/workflows: multi-objective tuning (safety vs. latency); online experiments; System Harmonizer policy learning from telemetry.
- Assumptions/dependencies: strong experimentation frameworks; guardrails to prevent over-deception.
Long-Term Applications
The following require additional research, scaling, standardization, or ecosystem development before broad deployment.
- Cross-organization jailbreak threat intel sharing (security, policy)
- Share Forensic Tracker-derived attack signatures and multi-turn patterns (e.g., role-play + topic drift chains) in standardized formats, akin to STIX/TAXII for LLM threats.
- Tools/products/workflows: common schema for multi-turn signatures; exchange hubs; reputation systems.
- Assumptions/dependencies: privacy-preserving sharing; legal frameworks; de-identification standards; governance for false positives.
- Safety certification standards using MSR/ARC (policy, accreditation)
- Create industry certifications/rating labels that mandate multi-turn robustness and deceptive-resilience metrics beyond ASR for consumer and enterprise AI products.
- Tools/products/workflows: accreditation bodies; conformance test suites; third-party audits.
- Assumptions/dependencies: regulator/industry consensus; stable benchmark suites; versioned metric definitions.
- Continual safety training loops (ML lifecycle)
- Feed Forensic Tracker logs into auto-curated safety datasets for periodic SFT/RLHF, improving base-model robustness against evolving multi-turn tactics.
- Tools/products/workflows: data distillation pipelines; curriculum schedulers; closed-loop training with System Harmonizer feedback.
- Assumptions/dependencies: safe data handling; avoiding adversarial overfitting; compute/budget; alignment with model provider update cycles.
- Multi-modal and tool-augmented deception defenses (robotics, software agents)
- Extend HoneyTrap to agents with tools (code execution, browsing, robotics control) and modalities (vision/audio), applying misdirection without enabling harmful tool actions.
- Tools/products/workflows: tool-aware deception policies; tool invocation sandboxes; modality-specific TI/MC personas.
- Assumptions/dependencies: reliable tool gating; formal safety constraints; human-in-the-loop overrides; new datasets for non-text jailbreaks.
- SOAR-like autonomous safety orchestration for LLM platforms (security operations)
- Evolve System Harmonizer into a self-optimizing orchestrator that learns playbooks (e.g., adjust thresholds, escalate to human review, quarantine sessions) across fleets of applications.
- Tools/products/workflows: policy learning; cross-app telemetry fusion; fleet-level safety SLAs.
- Assumptions/dependencies: robust off-policy learning from logs; guardrails against self-reinforcing errors; explainability requirements.
- Insurance and risk analytics for AI safety (finance, insurtech)
- Use ARC/MSR profiles to price risk of LLM deployments and reward platforms that demonstrably drain attacker resources and sustain low ASR over time.
- Tools/products/workflows: actuarial models; standardized disclosures; incident datasets.
- Assumptions/dependencies: historical loss data; accepted safety metrics; regulatory acceptance.
- Sector-specific safety playbooks and templates (healthcare, finance, education)
- Curate domain-aligned deception strategies and response libraries (e.g., compliant deflections for medical/financial advice) with proven MSR/ARC improvements.
- Tools/products/workflows: template catalogs; domain ontologies; policy-aligned response generators.
- Assumptions/dependencies: expert input; auditability; clarity about acceptable “deception” vs. guidance in regulated contexts.
- Federated benchmarks and competitions for multi-turn jailbreaks (academia/industry)
- Evolve MTJ-Pro into a living benchmark across languages and domains; host competitions to push defenses against adaptive, multi-turn adversaries.
- Tools/products/workflows: benchmark governance; submission harnesses; leaderboards tracking ASR/MSR/ARC jointly.
- Assumptions/dependencies: community stewardship; dataset licensing; red-team ethics.
- User-transparency and ethics frameworks for deceptive defenses (policy, UX research)
- Develop norms and disclosures that balance attacker misdirection with user trust (e.g., safe-mode notices, post-session transparency).
- Tools/products/workflows: UX experiments; policy guidelines; complaint-handling processes.
- Assumptions/dependencies: stakeholder consensus; legal guidance on acceptable deception; cultural/market differences.
- Marketplace for decoy assets and honeypot prompts (security tooling)
- Offer curated, rotating decoy content/patterns that increase attacker confusion and cost without leaking sensitive information.
- Tools/products/workflows: content rotation services; adversary simulation packs; subscription feeds integrated with System Harmonizer.
- Assumptions/dependencies: quality control; avoiding information hazards; update cadence to outpace attacker adaptation.
Collections
Sign up for free to add this paper to one or more collections.