- The paper introduces a modular, agent-based approach that uses MLLM agents to dynamically compose model-level tools for precise instruction-based image editing.
- It employs a three-stage reinforcement learning curriculum to optimize tool composition, achieving superior performance on standardized image editing benchmarks.
- The framework enhances extensibility and interpretability by allowing seamless integration of new tools without retraining and providing transparent workflow execution.
Lego-Edit: A Modular Agent-Based Framework for Generalized Instruction-Based Image Editing
Introduction
Lego-Edit introduces a modular, agent-based approach to instruction-based image editing, addressing the limitations of both end-to-end and curated workflow agent paradigms. The framework leverages a Multi-modal LLM (MLLM) as a reasoning agent (the "Builder") to dynamically compose and invoke a suite of specialized, model-level editing tools ("Bricks"). This design enables robust generalization to open-domain, flexible user instructions and supports seamless integration of new editing capabilities without retraining the agent. The system is trained via a three-stage progressive reinforcement learning (RL) curriculum, culminating in strong empirical performance on established image editing benchmarks.
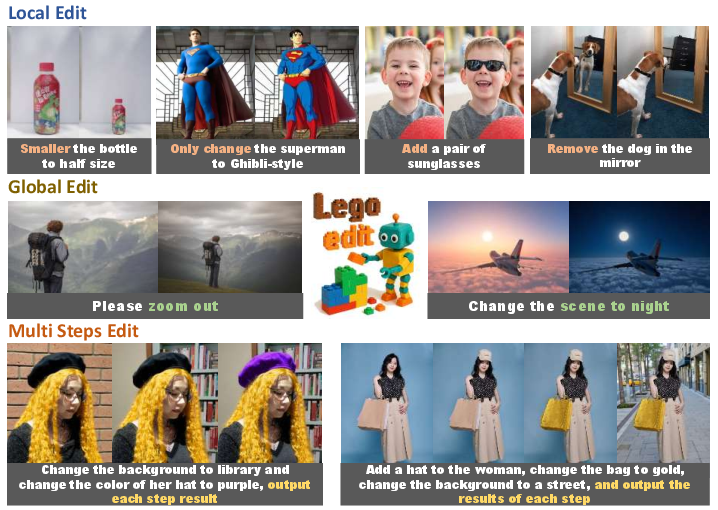
Figure 1: Comparison of end-to-end approach, API-based agent with curated workflows, and the Lego-Edit method.
Framework Architecture
Lego-Edit's architecture consists of three principal components:
- Builder (MLLM Agent): Receives an input image and a natural language instruction, then generates a structured workflow (as a tool invocation graph) specifying which tools to use, their parameters, and their execution order.
- Executor: Parses and executes the workflow, invoking the appropriate Bricks and managing data dependencies.
- Bricks (Model-Level Tools): A library of specialized models, each encapsulating a distinct editing or prediction function (e.g., segmentation, inpainting, style transfer, color/material change).
The workflow is represented as a directed acyclic graph, where nodes correspond to tool invocations and edges encode data dependencies. This explicit compositionality enables the system to decompose complex instructions into atomic operations, facilitating both interpretability and extensibility.
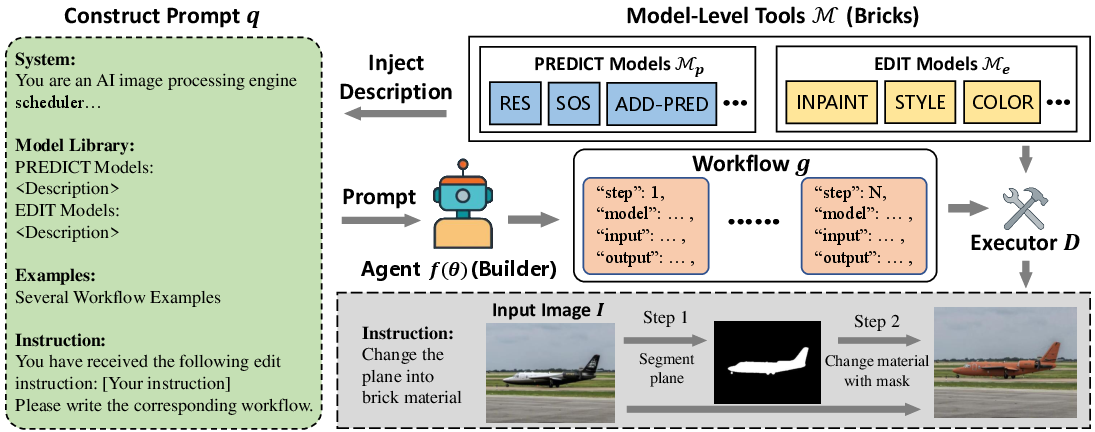
Figure 2: Overall framework of Lego-Edit. The Builder generates a tool invocation workflow, which the Executor executes to produce the edited image.
The Bricks are divided into two categories:
- Predictive Models: Tools that extract spatial or semantic information (e.g., object segmentation, region prediction, captioning) without modifying the image.
- Editing Models: Tools that perform pixel-level modifications (e.g., inpainting, object addition, style transfer, color/material replacement).
Each editing function is implemented as a dedicated model, typically via LoRA adapters fine-tuned for specific tasks. This specialization avoids the task confusion observed in unified, multi-task models and enables high-fidelity, targeted edits. The Builder can compose these tools, using outputs from predictive models (e.g., masks) to constrain the scope of editing models, thereby achieving precise and localized modifications.
Progressive Reinforcement Learning for Agent Training
Lego-Edit employs a three-stage RL curriculum to endow the Builder with robust reasoning and tool composition capabilities:
- Supervised Fine-Tuning (SFT): The Builder is initialized via SFT on a small set of expert-annotated instruction-image-workflow triplets, learning to map instructions to valid tool invocation sequences.
- GT-Based RL (Stage 2): The agent is further refined using RL with ground-truth workflows, optimizing for both workflow executability and similarity to expert solutions via a hierarchical graph-matching reward.
- GT-Free RL (Stage 3): To generalize beyond the training distribution, the agent is trained on open-domain instructions using a reward signal from an MLLM-based critic, which evaluates the semantic alignment between the workflow's effect and the instruction, without requiring ground-truth workflows.
The RL algorithm is based on Group Relative Policy Optimization (GRPO), which stabilizes training by normalizing rewards within sampled groups and regularizing policy updates.
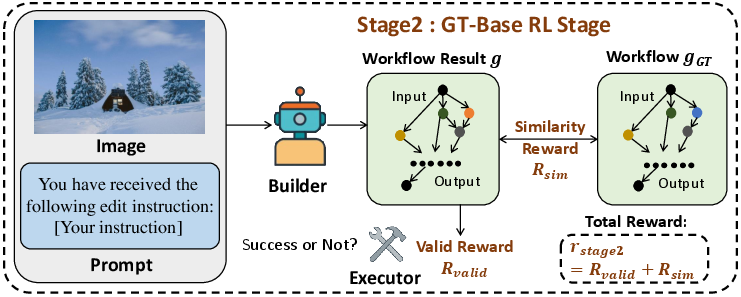
Figure 3: Reward design in Stage 2 (GT-based RL training), combining executability and workflow similarity.
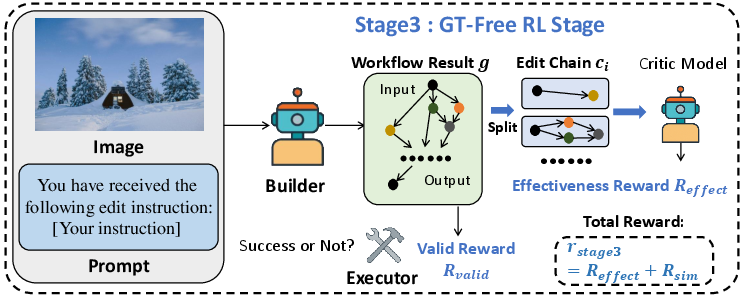
Figure 4: Reward design in Stage 3 (GT-free RL training), using an MLLM critic to assess semantic alignment.
Empirical Results
Lego-Edit demonstrates strong zero-shot generalization to complex, compositional instructions not seen during training. The Builder can decompose novel tasks (e.g., "swap object A with object B") into sequences of atomic tool invocations, leveraging the modularity of the Bricks.
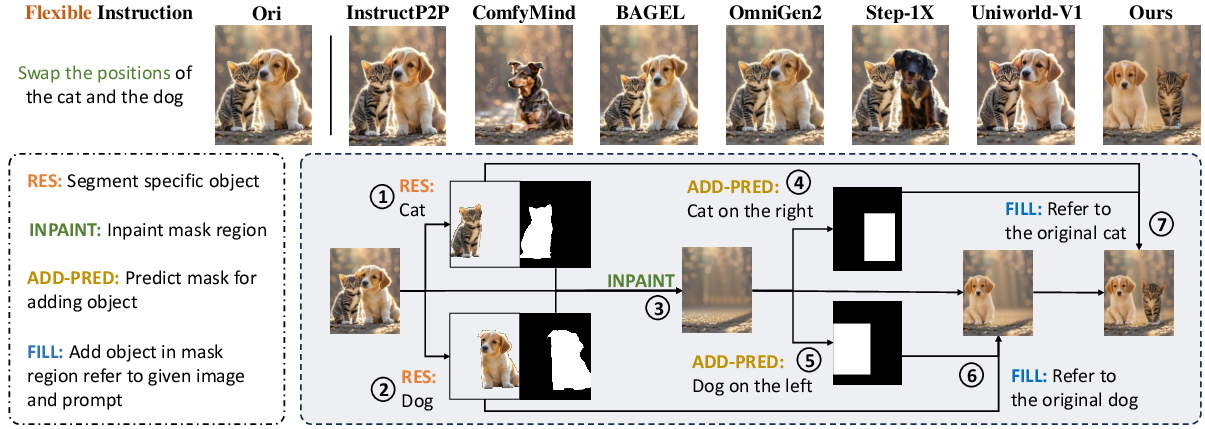
Figure 5: Comparison with other methods on complex edits (top) and the tool composition workflow generated by Lego-Edit (bottom).
The system also supports zero-shot adaptation to user feedback and the integration of new tools. For example, when a segmentation tool fails on a reflection removal task, user feedback can prompt the Builder to revise its workflow or incorporate a newly introduced reflection-removal tool, all without retraining.
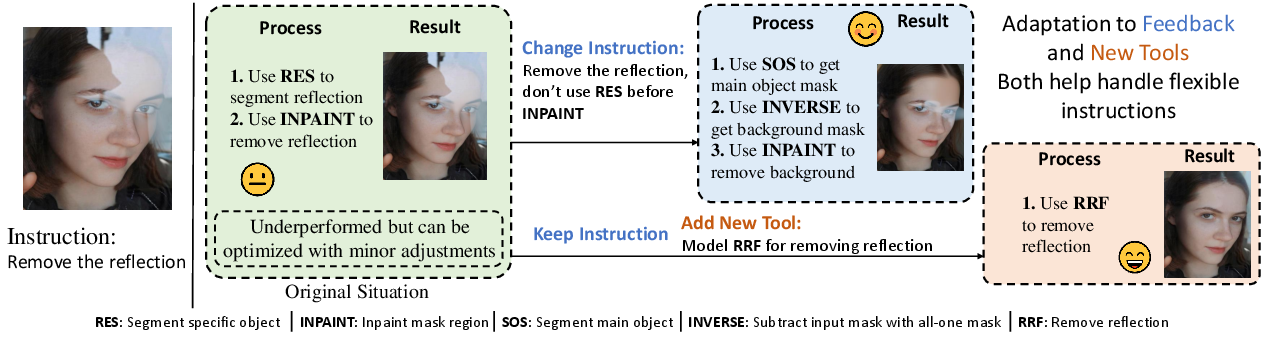
Figure 6: Example of zero-shot adaptation via feedback and tool insertion in reflection removal.
Quantitative and Qualitative Benchmarking
On GEdit-Bench and ImgEdit-Bench, Lego-Edit achieves state-of-the-art performance across multiple metrics, including image preservation and overall edit quality, as measured by VIEScore (GPT-4o-based evaluation). Notably, the system excels in fine-grained and hybrid editing tasks, outperforming both end-to-end and curated workflow agent baselines.
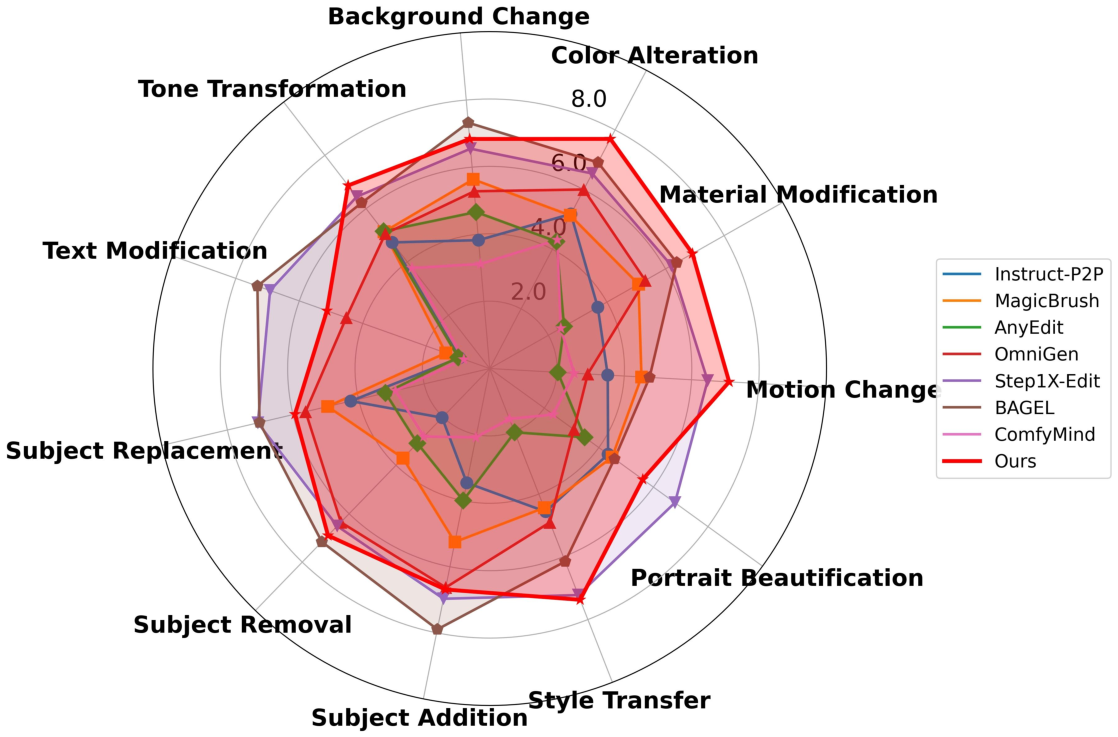
Figure 7: Quantitative evaluation on GEdit-Bench-EN. All metrics are higher-is-better.
Qualitative comparisons further highlight the system's ability to produce edits that are both semantically faithful and visually realistic, with precise localization and minimal artifacts.

Figure 8: Qualitative results compared to other methods.

Figure 9: Qualitative comparison with state-of-the-art methods.
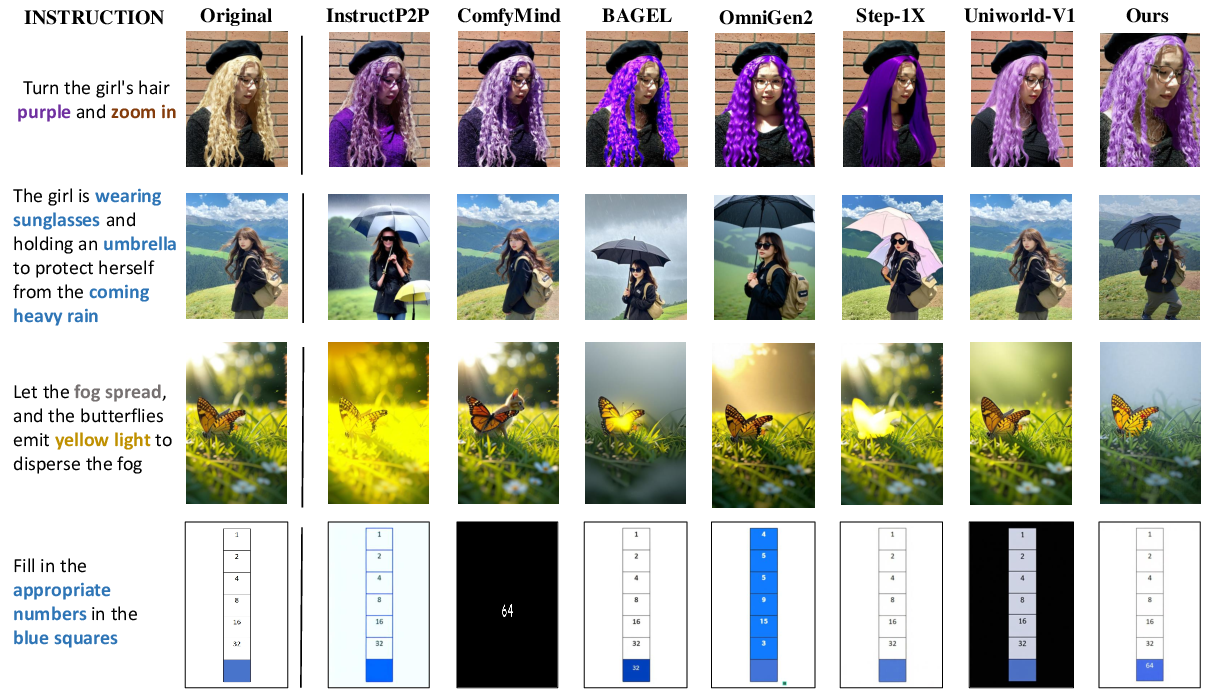
Figure 10: Qualitative results of handling complex and flexible editing instructions.

Figure 11: Qualitative results for image editing at varying aspect ratios.
Ablation and Analysis
Ablation studies confirm that task-specialized LoRA adapters outperform unified multi-task adapters, both quantitatively and qualitatively. The unified approach suffers from task confusion, leading to degraded edit fidelity and semantic drift.

Figure 12: Qualitative examples of task confusion arising from joint model training.
Explicit composition of predictive and editing tools (e.g., using segmentation masks to constrain color/material changes) yields measurable improvements in both objective metrics and perceptual quality.

Figure 13: Qualitative improvements achieved through strategic composition of model-level tools.
RL Training Efficacy
Progressive RL training, especially the GT-free stage, substantially improves the Builder's ability to generate valid, semantically aligned workflows for complex, open-domain instructions. The final agent achieves near-perfect execution success rates and the highest VIEScores on challenging benchmarks.
Practical and Theoretical Implications
Lego-Edit's modular, agent-based paradigm offers several practical advantages:
- Extensibility: New editing tools can be integrated without retraining the agent, supporting rapid capability expansion.
- Interpretability: Explicit workflows provide transparency and facilitate debugging, auditing, and user feedback incorporation.
- Generalization: The RL curriculum, especially with GT-free feedback, enables robust handling of diverse, real-world instructions.
Theoretically, the work demonstrates the efficacy of combining MLLM-based reasoning with modular tool composition and RL-based curriculum learning for complex, multi-step visual tasks. The approach bridges the gap between monolithic generative models and rigid, curated agent pipelines, offering a scalable path toward general-purpose, instruction-following visual agents.
Conclusion
Lego-Edit establishes a new state-of-the-art in instruction-based image editing by combining an RL-finetuned MLLM agent with a library of specialized, composable model-level tools. The framework achieves superior generalization, edit fidelity, and extensibility compared to both end-to-end and curated workflow agent baselines. Future directions include expanding the tool set, further automating tool integration, and exploring more sophisticated agent feedback mechanisms to enhance robustness and autonomy.