- The paper demonstrates that combining reinforcement learning with a robust multimodal verifier significantly enhances complex image editing tasks.
- The comparison shows that supervised fine-tuning excels in simple edits while RL post-training greatly improves performance for challenging edits.
- Using the Emu3 model and Qwen2.5-VL-72B verifier, the EARL model achieves higher VIEScore metrics than diffusion-based baselines.
The Promise of RL for Autoregressive Image Editing
Introduction
The paper "The Promise of RL for Autoregressive Image Editing" (2508.01119) investigates three strategies to enhance the performance of image editing tasks guided by textual prompts: supervised fine-tuning (SFT), reinforcement learning (RL), and Chain-of-Thought (CoT) reasoning. The central focus is on exploring these strategies within a consistent framework using an autoregressive multimodal model that processes textual and visual tokens. The findings indicate that combining RL with a robust multimodal LLM verifier is most effective, leading to the development of the EARL model. EARL pushes the frontier of autoregressive models in image editing despite utilizing less training data.
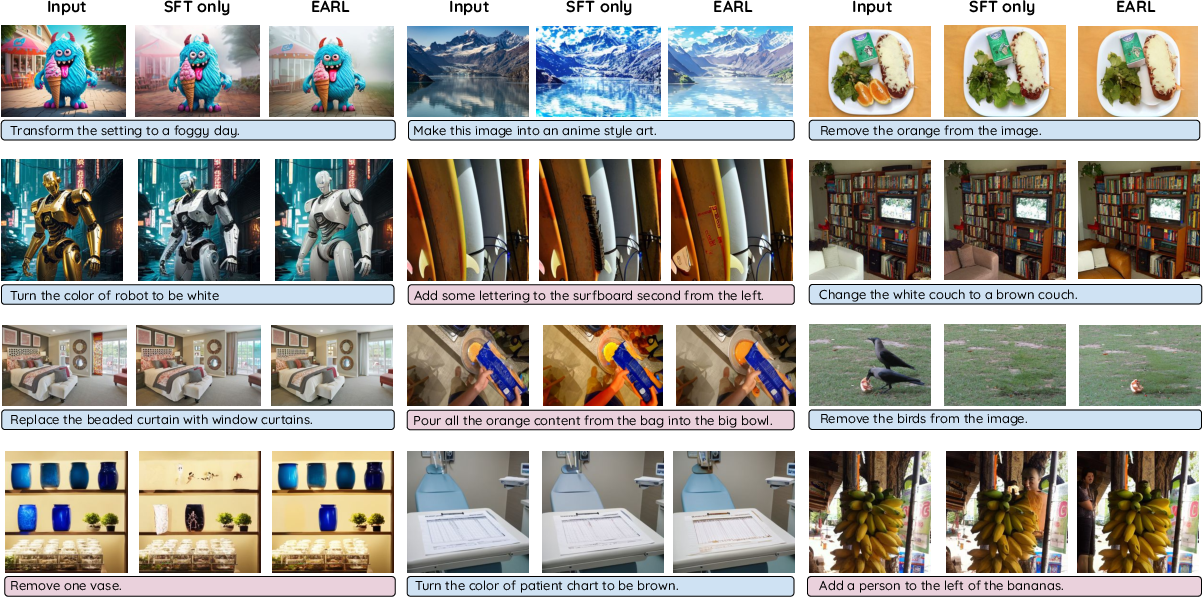
Figure 1: Qualitative comparison between SFT-only and EARL across diverse editing instructions. EARL shows improvements in complex edits requiring precise modifications.
Methodology
The paper adopts Emu3, a unified autoregressive generative model pre-trained on captioning and image generation, as the foundation for the study. The RL approach implemented is Group Relative Policy Optimization (GRPO), initialized from the SFT checkpoint. The notion of verification comes into play using large MLLMs to evaluate the quality of image edits, specifically Qwen2.5-VL-72B as the verifier. Three distinct training paradigms are explored:
- Supervised Fine-Tuning (SFT): This involves next-token prediction minimizing cross-entropy loss on interleaved image-text sequences.
- Reinforcement Learning (RL) Post-Training: GRPO leverages a multimodal verifier to compute rewards based on editing quality, effectively optimizing the RL object for generating higher-quality edits.
- Chain-of-Thought (CoT) Reasoning: The exploration extends to integrating CoT reasoning by finetuning Emu3 with structured, tokenized reasoning chains preceding actual edits.
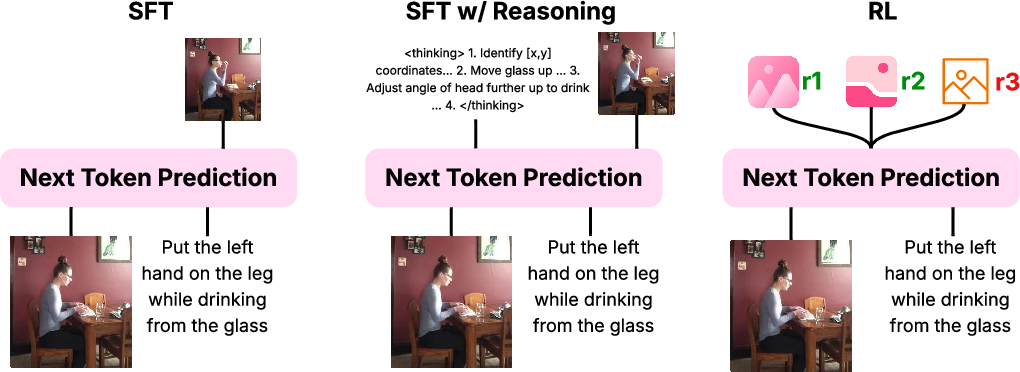
Figure 2: Autoregressive Image Editing Approaches depict SFT, SFT with reasoning, and RL training of the SFT checkpoint using verifiers.
Experimental Setup
The experimental setup involves training on varied datasets embracing both simple and complex edit types. Evaluation utilizes VIEScore, a metric with high human correlation, to assess edits across OmniEdit, MagicBrush, Aurora, VisMin, and disparate complex editing benchmarks. The comprehensive evaluation compares EARL to diffusion-based baselines such as MagicBrush, Aurora, and Omnigen, establishing EARLâs competitive performance.

Figure 3: Example of generating step-by-step reasoning with Qwen2.5-VL-72B, producing structured reasoning for the editing process.
Results
Empirical results demonstrate RLâs substantial advantage in improving model performance. EARL outstrips multiple baselines, achieving superior scores across several benchmarks on diverse edit types. While SFT alone was insufficient for complex edits, integrating RL provided necessary enhancement for spatial and dynamic interactions, proving the modelâs adaptability to handling complex tasks.
- Supervised Fine-Tuning: SFT (S) performs well on simple tasks but struggles with complex ones.
- Reinforcement Learning: RL post-training leads to marked improvements, notably with the best setup, SFT(S) â RL(S+C), which surpasses previous models.
- Chain-of-Thought Reasoning: Despite successful reasoning, explicit CoT reasoning did not bring consistent improvements in performance, indicating a need for further exploration in reasoning capabilities within autoregressive models.
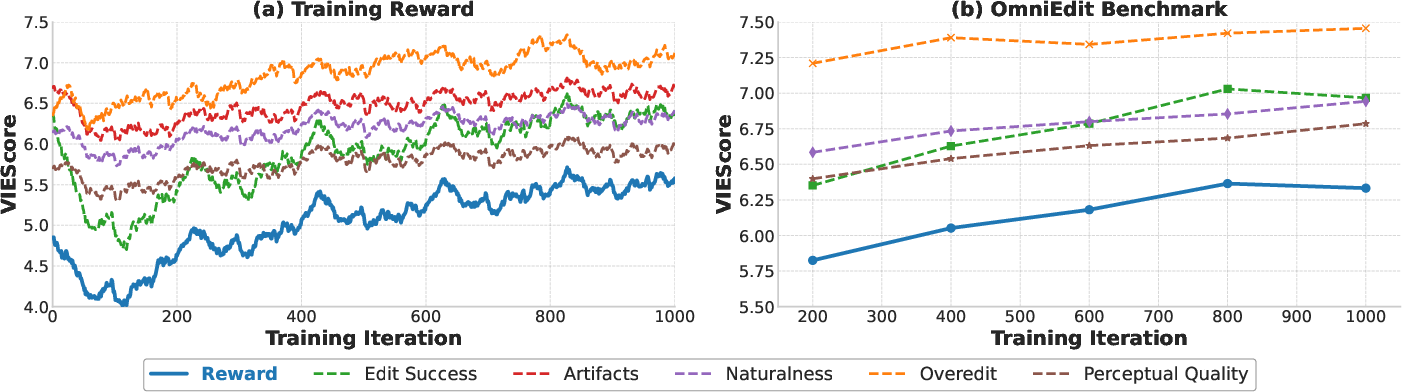
Figure 4: Training curves illustrating the progression of reward with different aspects, showing increased VIEScore during RL iterations.
Implications and Future Work
The strategies highlighted in this paper set a precedent for employing RL and autoregressive models in text-guided image editing. Future developments can focus on enhancing reasoning methods within autoregressive architectures, campaigning for more robust models capable of sophisticated reasoning and adaptability to unseen edits. Addressing the limitations of MLLM verifiers and extending RL methodologies could drive improvements in encoding finer details in complex editing tasks.
Conclusion
The "Promise of RL for Autoregressive Image Editing" delineates a path for unifying autoregressive strategies with reinforcement learning to advance image editing capabilities. These innovations demonstrate the strength of combining RL with autoregressive generation, underscoring their competitive positioning against diffusion models. While RL bolstered complex edit execution, the research warrants deeper exploration of reasoning integration to further elevate model proficiency.

Figure 5: Reward scores for various image edits indicating alignment with the edit prompt, showcasing EARLâs improvements.

