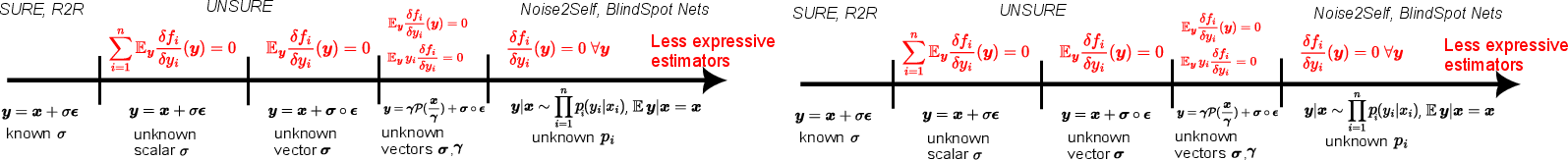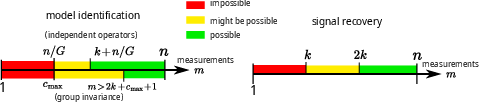Self-Supervised Learning from Noisy and Incomplete Data
Published 6 Jan 2026 in stat.ML, cs.LG, and eess.IV | (2601.03244v1)
Abstract: Many important problems in science and engineering involve inferring a signal from noisy and/or incomplete observations, where the observation process is known. Historically, this problem has been tackled using hand-crafted regularization (e.g., sparsity, total-variation) to obtain meaningful estimates. Recent data-driven methods often offer better solutions by directly learning a solver from examples of ground-truth signals and associated observations. However, in many real-world applications, obtaining ground-truth references for training is expensive or impossible. Self-supervised learning methods offer a promising alternative by learning a solver from measurement data alone, bypassing the need for ground-truth references. This manuscript provides a comprehensive summary of different self-supervised methods for inverse problems, with a special emphasis on their theoretical underpinnings, and presents practical applications in imaging inverse problems.
The paper presents a systematic replacement of supervised losses with self-supervised surrogates, enabling neural inverse solvers to train using only measurement data.
It proposes a taxonomy of loss functions—from unbiased to constrained approaches—with detailed analysis of noise models and architectural strategies in imaging and engineering.
The work rigorously evaluates identifiability and sample complexity, demonstrating asymptotic equivalence between self-supervised and traditional supervised methods under certain conditions.
Self-Supervised Learning from Noisy and Incomplete Data: Theory and Methodological Advances
Introduction and Motivation
The manuscript "Self-Supervised Learning from Noisy and Incomplete Data" (2601.03244) presents an extensive and rigorous treatment of self-supervised learning (SSL) methods for inverse problems, with a focus on scenarios where ground-truth (reference) data is unavailable or unattainable. The work bridges theoretical analysis, loss construction, and algorithmic strategies, with applications spanning imaging, scientific experiments, and engineering systems where noisy and incomplete measurements are ubiquitous.
The central thesis is the systematic replacement of conventional supervised losses with self-supervised surrogates that permit end-to-end training of neural inverse solvers using only measurement data. The text emphasizes the statistical and geometric foundations underpinning these approaches, quantifying precisely when and to what extent self-supervised methods match or approximate the performance of their supervised counterparts.
Background: Inverse Problems and the Need for Self-Supervision
Inverse problems in computational imaging, physics, and related fields deal with the recovery of a ground-truth signal, x, from corrupted or incomplete observations y=A(x)+ϵ, where A is a known forward operator and ϵ models noise. Classical solutions resort to hand-crafted regularizers (e.g., sparsity, total variation), whereas modern frameworks employ supervised deep learning, mapping noisy measurements to clean images by leveraging datasets paired with ground-truths.
However, supervised deep learning severely limits applicability in domains lacking high-fidelity reference data. Distribution shift between train and test input distributions further exacerbates problems in transferability. These constraints motivate the SSL approach: constructing theoretically justified loss functions that operate without any paired clean data, enabling data-driven learning even under measurement-only regimes.
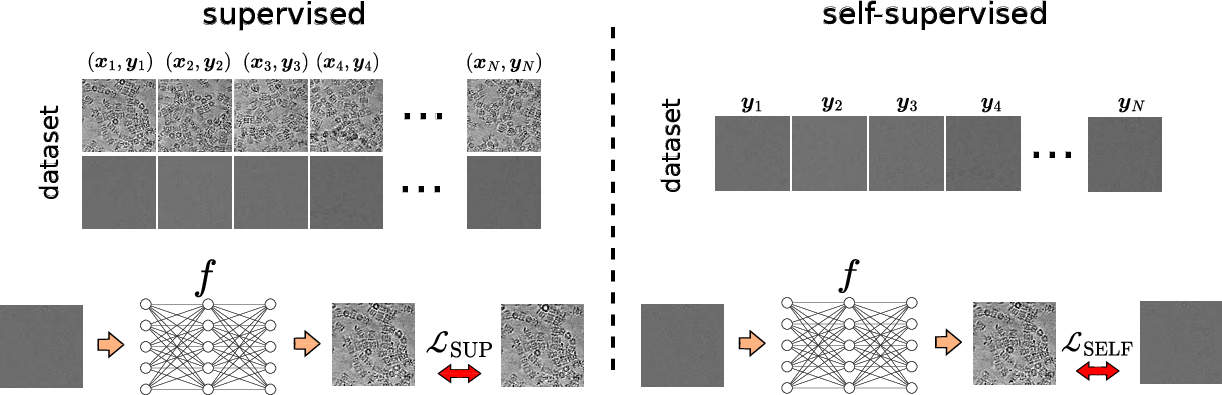
Figure 1: Supervised learning requires labeled pairs (xi,yi), whereas self-supervised learning works directly on measurements {yi}, building suitable data-only losses.
Self-Supervised Loss Construction: Noise Models and Expressivity Constraints
A core contribution of the manuscript is a taxonomy of SSL losses, classified by their statistical assumptions on the measurement noise and the structural constraints imposed on the learned estimators.
Unbiased Losses: For settings with known noise distributions, or with access to independent repeated noisy measurements of the same underlying signal (as in Noise2Noise), there exist unbiased surrogates for the supervised loss. When the noise distribution is fully characterized (e.g., Gaussian with known variance), estimators such as Stein's Unbiased Risk Estimator (SURE) and its generalizations achieve risk-unbiasedness.
Figure 2: The expressivity-robustness trade-off: decreasing noise model knowledge necessitates stronger architecture or loss-form constraints for provable self-supervised learning.
Constrained Losses: In cases of partial knowledge (e.g., known noise form but unknown variance), the range of admissible neural estimators is restricted (e.g., zero-expected divergence constraints in UNSURE). For even weaker assumptions (e.g., unknown or non-i.i.d. noise), only highly constrained function classes (e.g., blind-spot architectures in Noise2Void) avoid overfitting, sacrificing optimality with respect to the true posterior mean estimator.
Losses with Shared Minima: In some cases, although the self-supervised loss is not an unbiased estimator of the supervised loss, the minimizers coincide, guaranteeing asymptotic performance equivalence at sufficiently high sample complexity.
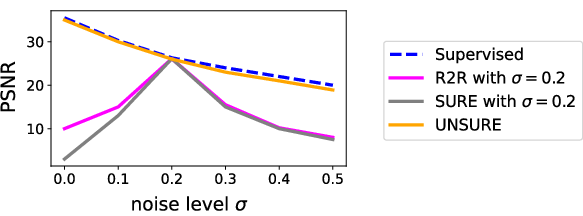
Figure 3: Empirical robustness of different SSL losses under varying noise level misspecification; only appropriately constrained approaches (e.g., UNSURE) remain close to the supervised baseline under model mismatch.
Architectural and Algorithmic Strategies
The paper categorizes neural inverse mapping architectures relevant for SSL:
Back-projection Networks: Measurement preprocessing via pseudo-inverse A† followed by image-domain networks (e.g., UNet, ResNet).
Unrolled Architectures: Learning by unrolling iterative regularization or optimization algorithms, with proximal operators learned in a data-driven manner.
Blind-spot and Splitting Methods: Architectures structured to remove direct access to certain entries (e.g., pixels) from their own predictions, implemented via masking or receptive field restrictions, thus enforcing the necessary independence for unbiased self-supervised losses.
Figure 4: Pixel splitting strategies for cross-validation based SSL denoising: Losses are estimated by leaving out target pixels/clusters from the network input to avoid degenerate solutions.
Learning from Incomplete and Ambiguous Observations
The paper addresses the fundamental ill-posedness when A is non-invertible, leading to measurement nullspaces where the data reveals no information. Two strategies are highlighted:
Multiple Operators / Data Fission: Training on data with a diversity of forward operators ({Ag}) whose nullspaces vary across samples (such as different inpainting masks or MRI undersampling patterns); this enlarges the observable subspace, permitting unique recovery of more signal components.
Figure 5: Learning with multiple forward operators—each masking scheme provides a distinct partial observation, and coverage across masks mitigates the irretrievability of certain features.
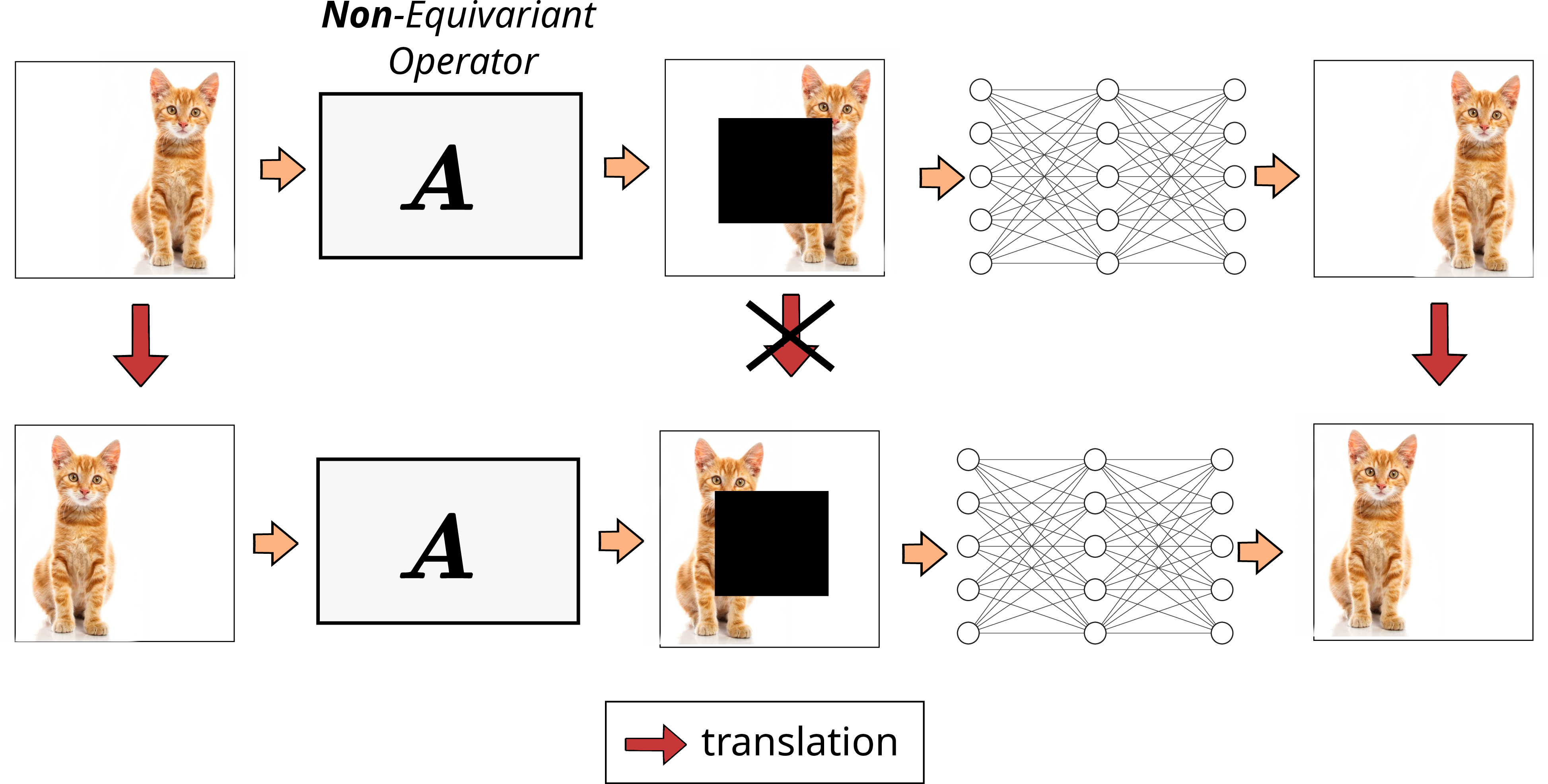
Group Invariance and Equivariance: When only a single A is available, but the data distribution is invariant under a group Tg (e.g., translations, rotations), exploiting this symmetry can generate virtual multiple operators and enable identifiability of signal features even in the nullspace. The framework employs equivariant losses and consistency under group transformations.
Figure 6: Equivariant imaging example: only via distributional invariance (bottom row) can the model learn features in masked-out regions.
Figure 7: The equivariant imaging loss enforces system-level equivariance to group actions, unlocking estimation in otherwise unobservable portions of the data.
Theoretical Analysis of Identifiability and Sample Complexity
A rigorous geometric and statistical analysis determines sufficient measurement regimes, minimal operator diversity, and intrinsic signal dimension necessary for SSL identifiability and learning guarantees. The results extend classical Cramér–Wold and compressed sensing results to SSL, showing uniqueness of model recovery when certain operator covering and manifold dimension conditions are met.
Figure 8: Visualization of model identifiability (left) and signal recovery (right) as a function of number of measurements per sample, number of operators, and latent signal dimensionality.
Sample complexity is further investigated, establishing that for finite noisy datasets, the excess error between SSL and supervised estimators scales as O(σ2/N), with efficiency approaching optimal in high SNR or large-data regimes.
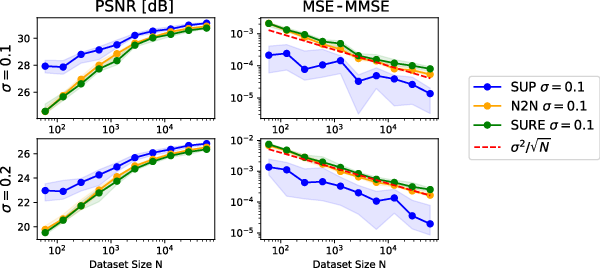
Figure 9: Empirical sample complexity for Noise2Noise and SURE; the suboptimality gap decreases as N−1/2, confirming theoretical predictions.
Practical Considerations: Validation, Generalization, and Fine-Tuning
The work discusses practical methodologies applicable to SSL with finite datasets:
Leveraging self-supervised hold-out and cross-validation to tune hyperparameters and avoid overfitting in the absence of ground-truth.
Quantifying the additional variance and bias in SSL loss gradients.
Strategies for efficient fine-tuning of pretrained models on out-of-distribution or adaptation tasks using SSL objectives.
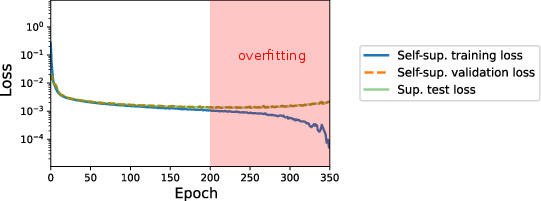
Figure 10: Self-supervised training/validation enables early stopping and generalization assessment without access to reference images.
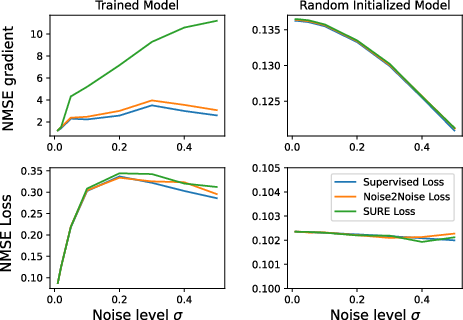
Figure 11: Analysis of the variance in estimates and gradients for supervised and SSL losses; Noise2Noise and SURE demonstrate controlled excess error.
Extensions and Open Problems
Broad implications and future research directions highlighted include:
Extension of the SSL theory to nonlinear and high-dimensional inverse problems (e.g., phase retrieval, quantized sampling).
Efficient adaptation of SSL to large-scale imaging and computational constraints.
Robust SSL under misspecified or partially defined noise/forward models.
Systematic investigation of loss functions beyond ℓ2 (e.g., ℓ1, Bregman divergences), uncertainty quantification, and generative posterior sampling from measurement-only data.
Conclusion
This monograph delivers a detailed and mathematically coherent framework for self-supervised learning in noisy and incomplete inverse problems. The presented taxonomy of SSL losses, accompanied by strong theoretical analysis of identifiability and practical insights on algorithm implementation, positions this work as a foundational reference for the field. It rigorously delineates when self-supervised estimators rival supervised ones and provides precise prescriptions for loss construction, modeling assumptions, and measurement strategies. The implications span across computational imaging, scientific data analysis, and any application where data incompleteness or the absence of ground-truth labels is a key limitation.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.