UltraLogic: Enhancing LLM Reasoning through Large-Scale Data Synthesis and Bipolar Float Reward
Abstract: While LLMs have demonstrated significant potential in natural language processing , complex general-purpose reasoning requiring multi-step logic, planning, and verification remains a critical bottleneck. Although Reinforcement Learning with Verifiable Rewards (RLVR) has succeeded in specific domains , the field lacks large-scale, high-quality, and difficulty-calibrated data for general reasoning. To address this, we propose UltraLogic, a framework that decouples the logical core of a problem from its natural language expression through a Code-based Solving methodology to automate high-quality data production. The framework comprises hundreds of unique task types and an automated calibration pipeline across ten difficulty levels. Furthermore, to mitigate binary reward sparsity and the Non-negative Reward Trap, we introduce the Bipolar Float Reward (BFR) mechanism, utilizing graded penalties to effectively distinguish perfect responses from those with logical flaws. Our experiments demonstrate that task diversity is the primary driver for reasoning enhancement , and that BFR, combined with a difficulty matching strategy, significantly improves training efficiency, guiding models toward global logical optima.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces UltraLogic, a “puzzle factory” for training LLMs to think better. It creates tons of high-quality, automatically checkable reasoning problems at different difficulty levels. The paper also proposes a new way to score the model’s answers, called Bipolar Float Reward (BFR), which helps the model learn faster and aim for truly correct solutions, not “almost right” ones.
Key Objectives and Questions
The paper focuses on two big goals:
- How can we build a huge, diverse set of reasoning problems—beyond just math or coding—that have guaranteed correct answers and well-controlled difficulty levels?
- How can we improve the “reward” signals during training so the model doesn’t get stuck on partially correct answers and instead learns to produce perfect logical solutions?
Methods and Approach
The researchers tackle the problem in two parts.
Building lots of thinking problems (the UltraLogic data framework)
Think of this like a puzzle-making system that separates the puzzle’s logic from the story around it:
- Input code: A small program creates the key details of a puzzle (like numbers, steps, or rules) based on a chosen difficulty level. This is like filling in blanks for a puzzle template.
- Solution code: Another program computes the exact correct answer from those details. This guarantees that every puzzle has a correct, checkable solution.
- Templates: Each puzzle type has multiple “skins” (different story settings like sci-fi or logistics) so the model doesn’t just memorize wording.
- Difficulty ladder (levels 1–10): The system automatically adjusts puzzle complexity until a target model (like a well-known LLM) solves each level at a specific success rate (e.g., 100% for level 1, ~50% for level 5, ~0% for level 10). This creates consistent, calibrated difficulty across many task types.
- Quality gate: Before mass-producing data, samples at easy levels are tested to ensure the wording and logic match perfectly. Flawed tasks are removed.
In short: UltraLogic is a controlled, scalable factory that produces thousands of different, checkable reasoning puzzles across many kinds of thinking skills.
Teaching models with smarter rewards (Bipolar Float Reward)
LLMs are trained using reinforcement learning (RL), which gives “rewards” when the model’s answer is correct. But simple binary rewards (1 for correct, 0 for wrong) can be too blunt:
- Problem: If an answer is almost right, it still gets 0—same as a totally wrong answer—so the model can’t tell how close it was.
- First try: Use graded scores from 0 to 1 (like partial credit). This helped a bit but caused a new issue—models learned to settle for “good enough” instead of perfect logic.
- Final solution: Bipolar Float Reward (BFR). Only a perfect answer gets +1. Any imperfect answer gets a negative score (between −1 and 0), with bigger penalties for bigger mistakes. Think of it like a game where near-misses still cost you points, which pushes you to aim for truly flawless solutions.
This “push-pull” setup gives clear signals: strong positive feedback for perfect logic, and graded negative feedback that discourages sloppy reasoning.
Main Findings and Why They’re Important
Here are the most important results from the experiments:
- Task diversity matters most: Training on many different kinds of reasoning tasks gives bigger improvements than just making a single task type larger. Variety teaches the model to think flexibly.
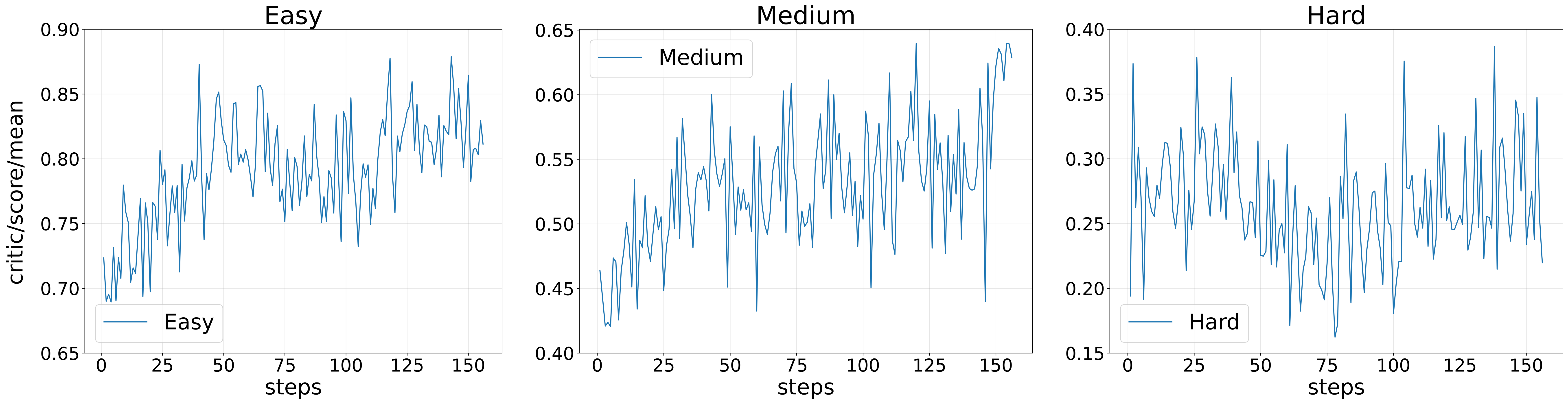
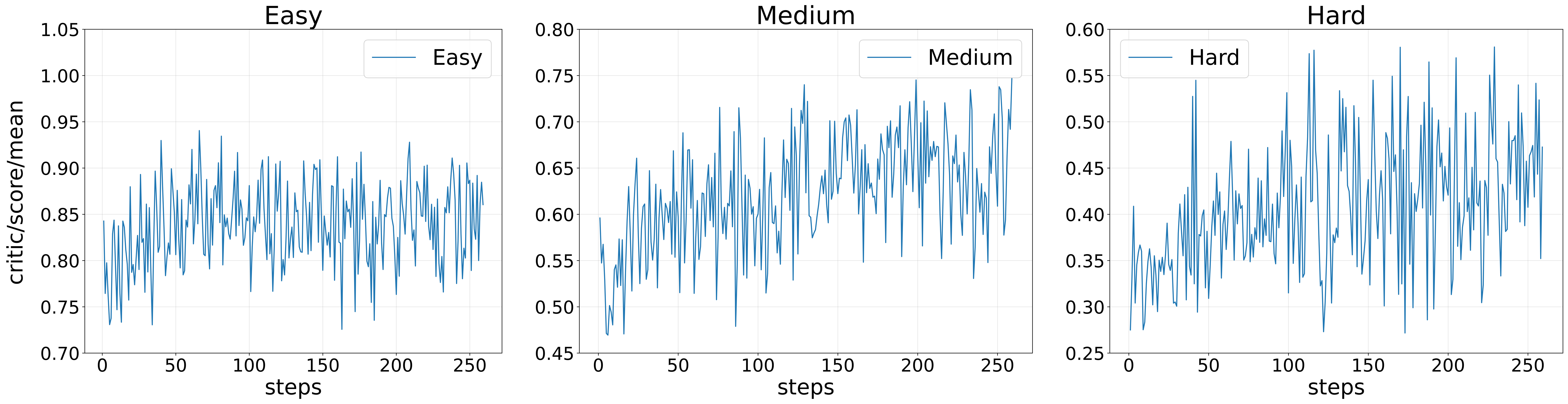
- Difficulty matching boosts learning: Each model size learns best when trained at the difficulty level where it succeeds about 40–60% of the time. Too easy adds little; too hard adds noise and can even break training. This is like learning in your “sweet spot”—challenging but achievable.
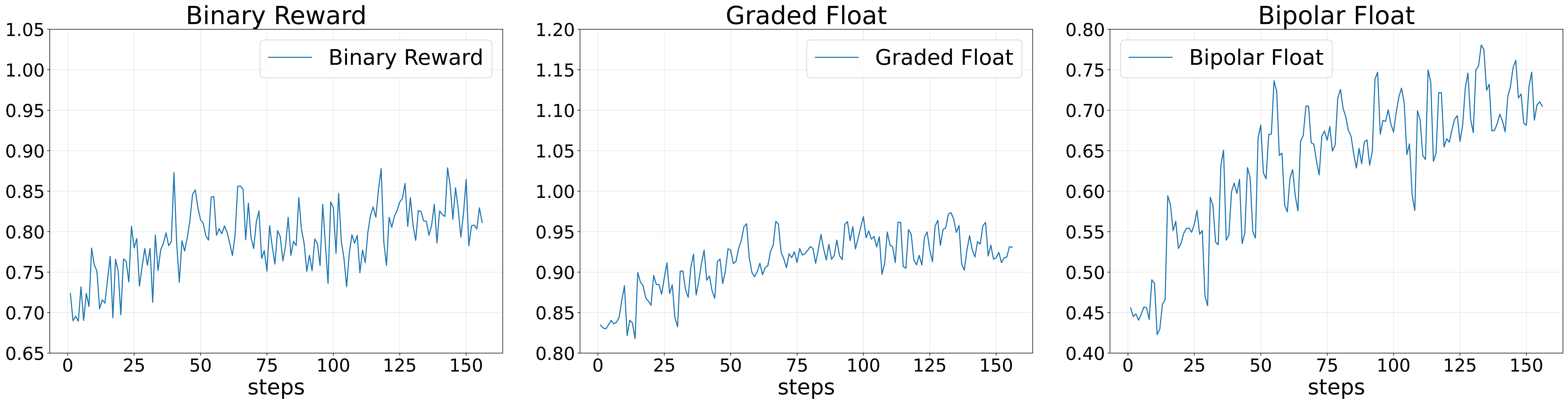
- BFR beats other rewards: Compared to binary and standard “partial credit” rewards, BFR led to faster training and higher scores on tough reasoning benchmarks (like AIME and BBH). Graded penalties help the model fix small logic gaps and avoid getting stuck at “almost right.”
- Data quality is crucial: RL training is very sensitive to errors. Even a few buggy tasks can derail learning. The validation step in UltraLogic is essential to keep training stable.
These findings matter because they show how to scale up reasoning training reliably and efficiently, not just for math or code but for general thinking.
Implications and Potential Impact
UltraLogic and BFR together provide a blueprint for building smarter, more careful thinkers:
- For researchers and companies: They offer a way to mass-produce reliable, varied reasoning data and train models with clearer, more effective learning signals.
- For future models: The difficulty ladder and BFR help models steadily climb toward perfect logic, reducing “almost right” answers in high-stakes tasks.
- For broader AI progress: Better general-purpose reasoning can improve planning, multi-step problem solving, and verification—key skills for trustworthy AI.
In short, UltraLogic supplies the right kind of puzzles, and BFR supplies the right kind of feedback. Together, they help LLMs learn to reason more precisely and confidently.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to be actionable for future research.
- Dataset transparency and release: the paper references “hundreds” of task types but does not specify the exact number, total instances, per-task instance counts, or whether code/data/prompts will be released; reproducible details (seed control, versioning, licensing) are absent.
- Taxonomy coverage and validation: the three-dimensional “orthogonal” classification is not quantitatively validated (e.g., overlap analysis across dimensions, inter-annotator agreement, or mapping to established reasoning taxonomies); no per-ability improvement analysis.
- Diversity vs. scale vs. difficulty ablations: the claim that “task diversity is the primary driver” is not directly supported by controlled experiments disentangling diversity from data volume and difficulty; required ablations (constant size, varying diversity; constant diversity, varying size; matched difficulty) are missing.
- Natural language surface-form robustness: while templates aim to avoid textual shortcuts, there is no evaluation of robustness to paraphrasing, style transfer, or adversarial rewordings beyond the built templates; risk of template artifacts remains unquantified.
- Cross-lingual generalization: templates are bilingual (EN/ZH), but no experiments report cross-lingual transfer, language-specific gains, or language balance effects during training and evaluation.
- Data quality validation methodology: the “>90% success at lower difficulty on a flagship model” gate risks model-specific biases and false negatives/positives; no human audit rate, unit test coverage, or formal verification of input/solution code is reported.
- Ambiguity and multiple-correct-answer handling: the framework assumes deterministic ground truth; the paper does not describe canonicalization, equivalence-class matching, or normalization pipelines for tasks with legitimately multiple correct outputs.
- Parsing robustness for reward computation: BFR requires structured extraction from free-form outputs; the paper does not detail robust parsing strategies, failure modes, or how formatting errors and hallucinations are handled beyond a fixed “format bonus.”
- Reward hacking risks: no adversarial testing shows whether models can inflate similarity/F1/accuracy proxies without correct reasoning (e.g., by emitting token patterns), or how BFR mitigates such behavior across different scoring functions.
- BFR theoretical guarantees under GRPO normalization: because GRPO advantage is group-normalized, imperfect samples can still receive positive advantage if above the batch mean; the paper does not analyze when BFR guarantees strictly negative advantages for all imperfect responses, or how group size affects this.
- Metric comparability across task types: the four scoring functions (accuracy, F1, similarity, absolute difference rate) may have different sensitivities and ranges; no normalization or calibration is described to ensure consistent penalty magnitudes across heterogeneous tasks.
- Reward scale sensitivity: the paper acknowledges heuristic reward scaling but provides no sensitivity analysis (e.g., effects of shifting/temperature of penalties, or reward clipping thresholds) and no automated method to tune per-task reward maps.
- Interaction with other RL algorithms: all results use GRPO; compatibility and benefits of BFR with PPO, TRPO, AWR, or preference-based methods (DPO/RLAIF) are unexplored.
- Process-level signals vs. final-only scoring: BFR scores only outputs, not intermediate reasoning traces; the paper does not explore combining BFR with process reward models (PRMs), decomposed credit assignment, or step-level penalties.
- Difficulty calibration generality: calibration anchors difficulty to success rates of unspecified “flagship models”; cross-model consistency, calibrator set diversity, sample sizes, and stability over time (as models improve) are not reported.
- Online/adaptive curricula: the “Zone of Proximal Development” finding is static; no experiments evaluate dynamic difficulty scheduling, data mixing strategies, or on-the-fly calibration during training.
- Long-horizon and interactive tasks: the framework focuses on single-turn, verifiable tasks; applicability to interactive planning, tool use, multi-turn dialog, or environment-based reasoning is untested.
- Transfer to human-authored benchmarks: the dataset is synthetic; while AIME/BBH/BBEH/ARC-AGI are reported, broader transfer to diverse, human-authored corpora (e.g., GPQA-Diamond, MMLU-Pro, complex QA) and long-form CoT-heavy settings is not evaluated.
- Negative-reward side effects: potential side effects of pervasive penalties (e.g., mode collapse, risk-averse behavior, reduced exploration) are not analyzed; no safeguards (entropy bonuses, KL constraints, value clipping) are discussed beyond empirical convergence.
- Noise tolerance and robustness: RLVR brittleness is noted, but noise-injection studies (controlled error rates in solutions/templates) and techniques for robustness (confidence filtering, ensemble verifiers, data reweighting) are absent.
- Scaling laws and compute: training uses only 2 epochs, 50 tasks, and two model sizes (8B/14B); no scaling-law analysis over data volume, number of tasks, compute budget, or longer training horizons is provided.
- Architecture generality: MoE instabilities are observed but not systematically studied; the interaction between BFR and architecture choices (Dense vs. MoE, decoder-only vs. encoder-decoder) remains open.
- Evaluation rigor: results are reported without confidence intervals, seed variance, or statistical significance tests; per-benchmark breakdowns and failure analyses are not provided.
- De-duplication and contamination: the pipeline claims to exclude benchmark-like tasks, but there is no documented de-duplication method (e.g., embedding similarity screening) or contamination audit against evaluation sets.
- Template/program synthesis reliability: LLM-generated input/solution code is only “debugged” by annotators; test coverage, differential testing, metamorphic testing, and fuzzing for logic correctness are not described.
- Difficulty ladder assumptions: success-rate-based difficulty may confound surface features with true cognitive complexity; there is no independent validation that levels correspond to independently measurable reasoning depth (e.g., required steps, branching factor).
- Generalization to additional modalities: UltraLogic is text-only; extensions to code+vision, diagrams, tables, or multimodal reasoning are not addressed.
- Practical costs and efficiency: despite claims of “low-cost,” there is no accounting of human hours, compute costs, or cost-performance relative to SFT/PRM pipelines.
- Ethical and safety considerations: the paper does not discuss bias propagation from synthetic templates, content safety in generated tasks, or the impact of dense penalties on safety-related behaviors.
Practical Applications
Immediate Applications
Below is a concise list of practical, deployable applications that leverage UltraLogic’s data synthesis framework and the Bipolar Float Reward (BFR) mechanism.
- UltraLogic-based reasoning dataset production for LLM training (software/AI, academia)
- Tools/products/workflows: “UltraLogic Studio” to author input/solution code, bilingual templates, and run programmatic expansion; automated difficulty calibration (1–10 ladder); QA gate requiring ≥90% low-level success.
- Assumptions/dependencies: Verifiable ground truth per task; human-in-the-loop for seed tasks and QA; reproducible pipelines; compute for large-scale synthesis.
- BFR reward shaping in RLVR pipelines to speed convergence and avoid sub-optimal plateaus (software/AI)
- Tools/products/workflows: “RewardShaper-BFR” plugin for GRPO/PPO-style training; task-specific scoring metrics (accuracy, F1, similarity, absolute difference rate) with bipolar mapping S→S−1 for imperfect outputs.
- Assumptions/dependencies: RL frameworks that accept negative rewards; tasks must admit objective, automated correctness scoring; careful tuning to maintain stable gradients.
- Difficulty-matched curriculum scheduling to keep training in the “zone of proximal development” (software/AI, academia)
- Tools/products/workflows: “Difficulty Calibrator” service that targets 40–60% success; adaptive rollout allocation (synergy with E3-RL4LLMs/SEELE-style schedulers).
- Assumptions/dependencies: Continuous evaluation against representative benchmarks; live success-rate monitoring; access to multiple model scales.
- Creation of difficulty-stratified benchmarks for model evaluation and procurement (academia, enterprise, policy)
- Tools/products/workflows: “Difficulty Ladder Benchmark Pack” with calibrated levels; evaluation harness averaging accuracy over multiple samples.
- Assumptions/dependencies: Transparent calibration against flagship models; standardized scoring; community buy-in for comparability.
- Adaptive practice engines for education and exam prep (education, daily life)
- Tools/products/workflows: “Adaptive Practice Generator” delivering bilingual, verifiable problems; teacher dashboards that align tasks to student ability via the 1–10 ladder.
- Assumptions/dependencies: Alignment with curriculum standards; psychometric review; safeguards against data leakage and harmful content.
- Corporate logic assessments for hiring and upskilling (enterprise/HR)
- Tools/products/workflows: “Logic Assessment Generator” with verifiable scoring and controllable difficulty; anti-cheating measures via template diversity.
- Assumptions/dependencies: Validity/fairness audits; role-specific task libraries; privacy and compliance policies.
- Software QA and code-model training using verifiable tasks and graded penalties (software)
- Tools/products/workflows: Template-driven unit test synthesizer and bug reproduction tasks; BFR to penalize partial test passes and push toward perfect solutions.
- Assumptions/dependencies: High-quality unit tests; mapping correctness to automated metrics; integration with CI/CD.
- AI safety red-teaming via adversarial task synthesis and penalty-driven training (software/AI safety)
- Tools/products/workflows: “Red-team Task Synthesizer” for logic-intensive stress tests; BFR-based training to discourage “keyword salad” responses.
- Assumptions/dependencies: Coverage of diverse failure modes; robust QA; oversight to prevent unintended capability amplification.
- DataOps quality gate for RL datasets to prevent training collapse (software/AI)
- Tools/products/workflows: “Reasoning QA Gate” enforcing template/solution integrity with low-tier checks ≥90% success; automated detection of noisy tasks.
- Assumptions/dependencies: Access to reference models; dedicated annotator cycles; versioned data and audit trails.
- Multilingual reasoning data expansion (software/AI, education)
- Tools/products/workflows: Bilingual template repositories; cross-lingual calibration for difficulty.
- Assumptions/dependencies: High-quality translation; cross-lingual consistency; cultural/educational context awareness.
Long-Term Applications
The following applications are feasible with further research, scaling, domain formalization, and/or regulatory alignment.
- Clinical decision-support training via simulated patients and verifiable guidelines (healthcare)
- Tools/products/workflows: Clinical simulators with ground-truth protocols; difficulty-ladder curricula; BFR to penalize near-miss diagnoses.
- Assumptions/dependencies: Validated simulators, gold-standard guidelines, bias and safety audits, regulatory approval.
- Robotics planning/control with simulator-backed verifiable tasks (robotics)
- Tools/products/workflows: Task libraries grounded in physics simulators; curricula from constrained to open-ended planning; BFR to penalize suboptimal trajectories.
- Assumptions/dependencies: High-fidelity simulators; robust language-to-control interfaces; sample-efficient training.
- Finance risk/compliance agents trained on rule-verifiable scenarios (finance)
- Tools/products/workflows: Codified policy/regulatory rule-sets; scenario generators with deterministic compliance checks; BFR for strict adherence to constraints.
- Assumptions/dependencies: Accurate formalization of regulations; backtesting infrastructure; governance and regulator acceptance.
- Grid operation and energy scheduling with simulator-verifiable objectives (energy)
- Tools/products/workflows: Grid simulators, constraint satisfaction tasks with clear pass/fail; difficulty-aware training for multi-step optimization.
- Assumptions/dependencies: Domain-accurate simulators; safety-critical guardrails; operator-in-the-loop validation.
- Legal reasoning and contract compliance via formalized verifiable checks (legal)
- Tools/products/workflows: Clause and statute compliance tasks with deterministic checks; BFR to discourage partial compliance; difficulty-calibrated training.
- Assumptions/dependencies: Formal ground truth (ontologies, rule engines); licensing and confidentiality; fairness and accountability frameworks.
- National-scale adaptive testing standards grounded in difficulty ladders (education, policy)
- Tools/products/workflows: Standardized, calibrated item banks; psychometric validation; adaptive test delivery aligned with the 1–10 scale.
- Assumptions/dependencies: Multi-stakeholder consensus; fairness audits; curriculum alignment; secure delivery.
- Agentic multi-step reasoning frameworks combining BFR with process reward models (software/AI)
- Tools/products/workflows: Hybrid PRM+BFR training to couple step-level guidance with final strict correctness; automated partial-correctness metrics beyond math/code.
- Assumptions/dependencies: Low-cost, generalizable process-scoring; trace alignment; scalability across domains.
- Auto-curricula orchestration with live difficulty and rollout budget management (software/AI)
- Tools/products/workflows: “Curriculum Orchestrator” that monitors success rates and dynamically adjusts difficulty and sampling budgets to maximize learning efficiency.
- Assumptions/dependencies: Reliable telemetry and monitoring; robust scheduling algorithms; safeguards against mode collapse.
- Standards and certification for verifiable reasoning datasets and training QA (policy, industry consortia)
- Tools/products/workflows: Certification criteria for difficulty calibration, data provenance, QA thresholds; procurement guidelines referencing verifiability and brittleness to noise.
- Assumptions/dependencies: Industry/academic coalition; transparent measurement protocols; periodic audits.
- Consumer puzzle and brain-training products using calibrated logical tasks (daily life, gaming/edtech)
- Tools/products/workflows: Apps offering adaptive logic puzzles with verified solutions; bilingual content; progress tracking aligned to the difficulty ladder.
- Assumptions/dependencies: Content moderation; user safety; commercialization and platform integration.
Glossary
- 1--10 difficulty ladder: A calibrated scale used to grade and control task difficulty across discrete levels. "a unified 1--10 difficulty ladder."
- Absolute Difference Rate: A task-specific scoring metric that quantifies how far a model’s output deviates from the ground truth on a normalized scale. "Accuracy, F1-score, Similarity, and Absolute Difference Rate"
- Advantage function: In policy-gradient RL, a measure of how much better a sampled action is compared to the group mean, shaping gradient updates. "In the GRPO framework, the advantage function measures how much better a specific sample is compared to the group average."
- AIME: A competitive mathematics benchmark (American Invitational Mathematics Examination) used to evaluate reasoning performance. "We evaluate models on five benchmarks: AIME (2024 {paper_content} 2025)"
- ARC-AGI: A benchmark from the Abstraction and Reasoning Corpus aimed at assessing general intelligence-like reasoning. "and ARC-AGI"
- BBEH: Big-Bench Extra Hard, a challenging reasoning benchmark suite. "BBEH~\cite{kazemi-etal-2025-big}"
- BBH: BIG-bench Hard, a suite of difficult tasks for evaluating advanced reasoning. "BBH~\cite{suzgun2022challenging}"
- Bipolar Float Reward (BFR): A reward design mapping perfect solutions to +1 and all imperfect solutions to graded negatives, encouraging exact correctness. "we introduce the Bipolar Float Reward (BFR) mechanism"
- Code-based Solving Framework: A methodology that decouples logical cores from natural language, generating problems and answers via code. "we term the "Code-based Solving Framework.""
- Curriculum learning: A training strategy that sequences tasks by difficulty to improve learning efficiency and stability. "Given the sensitivity to difficulty, curriculum learning has become essential"
- Data Synthesis Pipeline: The core engine that programmatically generates task instances, answers, and difficulty annotations. "the Data Synthesis Pipeline which acts as the core engine."
- Dense models: Non-MoE architectures where all parameters are active per token; used here for more stable RL training. "we transitioned to Dense models (e.g., Qwen3-8B and 14B), which proved significantly more robust"
- DG-PRM: Dynamic and Generalizable Process Reward Model, an automated process-level reward modeling approach. "and DG-PRM \cite{yin2025dynamicgeneralizableprocessreward} derive granular signals"
- Difficulty Control Module: The component that calibrates and maintains task difficulty according to target success rates. "Input Code, Solution Code, and a Difficulty Control Module."
- Difficulty Matching Phenomenon: The observation that RL is most effective when task difficulty aligns with model capability. "We further identify a "Difficulty Matching Phenomenon," proving RL is most effective within the "Zone of Proximal Development""
- Diverse Task Template Repository: A library of varied natural-language templates for each task type to prevent overfitting to phrasing. "a Diverse Task Template Repository"
- E3-RL4LLMs: A curriculum/difficulty-aware RL framework for LLMs focusing on efficient exploration and training. "E3-RL4LLMs \cite{liao2025enhancingefficiencyexplorationreinforcement}"
- F1-Score: The harmonic mean of precision and recall, used here as a graded correctness metric. "using metrics such as accuracy or F1-Score"
- Format bonus: A small additive reward encouraging correct output formatting independent of logical correctness. "include a 0.1 format bonus"
- Group Relative Policy Optimization (GRPO): A policy optimization algorithm that normalizes rewards within sampled groups to compute advantages. "Group Relative Policy Optimization (GRPO)~\cite{shao2024deepseekmathpushinglimitsmathematical}"
- HMMT 2025: Harvard-MIT Math Tournament benchmark set used for evaluating mathematical reasoning. "HMMT 2025\footnote{\url{https://www.hmmt.org/www/archive/problems}"
- Mixture-of-Experts (MoE) architectures: Models with multiple expert subnetworks, which can be harder to stabilize under RL in this setting. "Initial trials with Mixture-of-Experts (MoE) architectures showed frequent divergence during the GRPO process."
- MorphoBench: A benchmark with difficulty adaptable to model capability for dynamic evaluation and training. "MorphoBench \cite{wang2025morphobench}"
- Non-negative reward trap: A failure mode where non-negative rewards for imperfect answers cause convergence to sub-optimal, partially correct policies. "This leads to the Non-negative reward trap, where the model tends to converge to a sub-optimal policy"
- OpenPRM: An open-domain process reward modeling framework that derives step-level signals without heavy human annotation. "OpenPRM \cite{zhang2025openprm}"
- OpenSIR: An open-ended self-improving reasoner framework that leverages difficulty to guide training or evaluation. "OpenSIR \cite{kwan2025opensir}"
- Original Task Repository: The collection of seed task types providing logical diversity and coverage for data synthesis. "an Original Task Repository, a Diverse Task Template Repository, and the Data Synthesis Pipeline"
- Penalty-Driven Correction (Push-Pull Dynamics): The BFR mechanism’s dynamic where negative penalties push away flawed reasoning and positive rewards pull toward perfect logic. "Penalty-Driven Correction (Push-Pull Dynamics)."
- Programmatic Expansion (PE): Automated generation of numerous task variants from seed tasks via code-driven transformations. "Programmatic Expansion (PE) techniques"
- Process Reward Models (PRMs): Reward models that score intermediate reasoning steps rather than only final answers. "Process Reward Models (PRMs) \cite{lightman2023letsverifystepstep}"
- Process-level scoring: Assigning rewards based on inferred intermediate solution structure rather than only end outputs. "for "process-level scoring" without accessing model reasoning traces"
- ReAct paradigm: A prompting/interaction approach combining reasoning and acting that informs the difficulty calibration loop. "follows the ReAct paradigm to achieve precise difficulty alignment"
- Reinforcement Learning with Verifiable Rewards (RLVR): An RL setup where tasks provide automatically checkable rewards (e.g., unit tests, exact answers). "Reinforcement Learning with Verifiable Rewards (RLVR)"
- Reward Cliff: The sharp discontinuity between the reward for perfect answers (+1) and all non-perfect answers (negative), enforced by BFR. "creates a significant Reward Cliff between a perfect response ($1.0$) and all imperfect ones."
- Slot-filling data: Structured parameters produced by input code to populate template slots and define the problem instance. "``slot-filling data''"
- Zone of Proximal Development: The difficulty region where learning signals are most effective relative to a model’s current capability. ""Zone of Proximal Development""
Collections
Sign up for free to add this paper to one or more collections.