- The paper introduces a unified omnimodal model that leverages discrete flow matching to integrate text, image, video, and audio modalities.
- It employs a single transformer backbone with modality-specific encoders and multi-codebook quantization for deep multimodal fusion and efficient parallel decoding.
- Experimental results demonstrate a 3.2-point improvement over OpenOmni on retrieval benchmarks and a 1.2× inference speedup compared to autoregressive models.
NExT-OMNI: Unified Any-to-Any Omnimodal Foundation Models via Discrete Flow Matching
Introduction and Motivation
NExT-OMNI introduces a unified omnimodal foundation model architecture that leverages discrete flow matching (DFM) to support any-to-any multimodal understanding, generation, and retrieval across text, image, video, and audio modalities. The work addresses the limitations of autoregressive (AR) and hybrid decoupling approaches, which suffer from granularity mismatches, increased complexity, and suboptimal feature fusion for cross-modal tasks. By adopting DFM, NExT-OMNI achieves bidirectional information integration, parallel decoding, and concise unified representations, enabling accelerated inference and broader applicability.
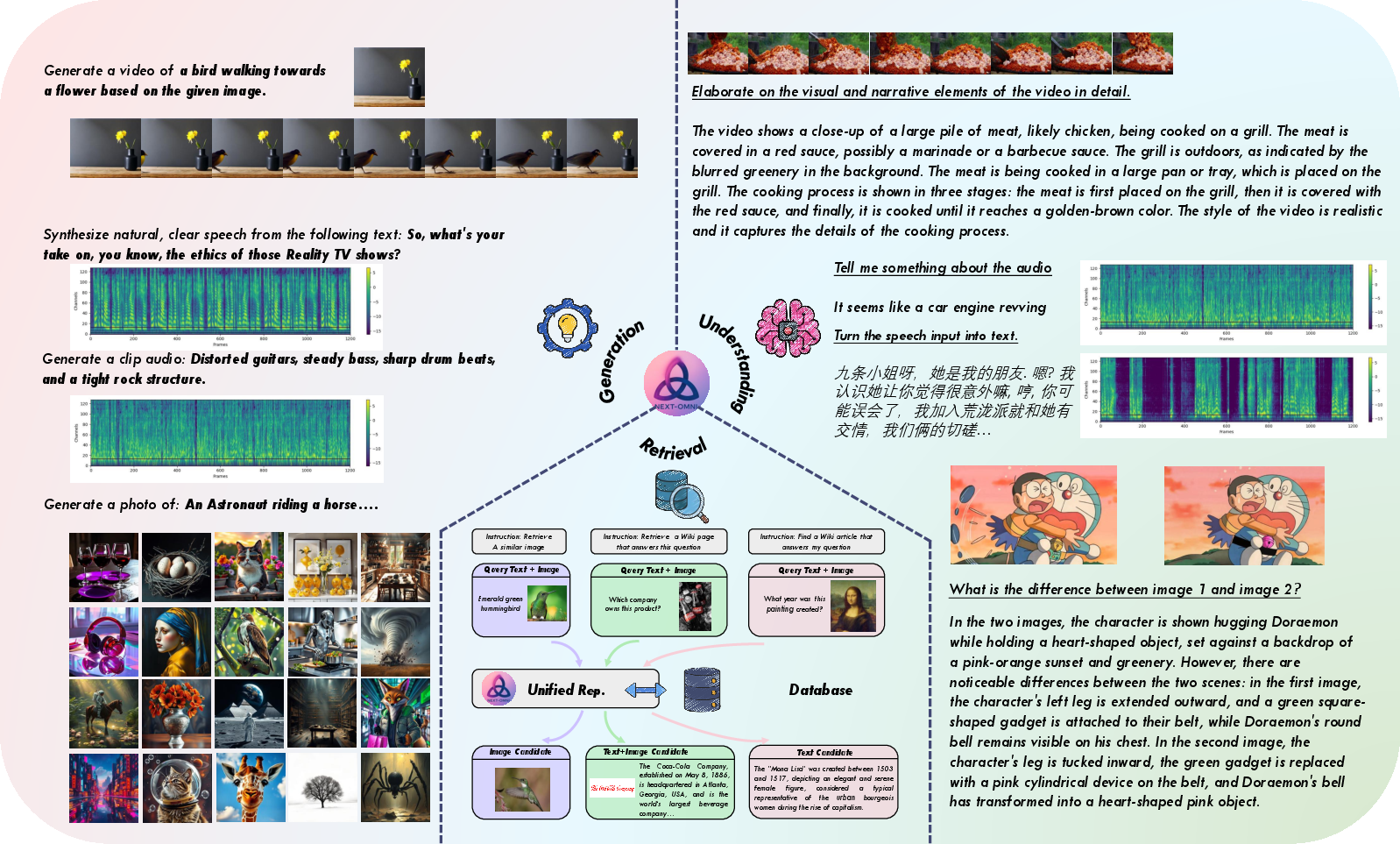
Figure 1: Overview of the NExT-OMNI framework, illustrating unified any-to-any multimodal operations and cross-modal retrieval via deeply fused representations.
Architecture and Training Paradigm
NExT-OMNI employs a single transformer backbone initialized from AR-based LLM weights, with modality-specific encoders for vision and audio, both trained for unified representation via self-supervised reconstruction and semantic alignment. The model utilizes multi-codebook quantization (MCQ) for both vision and audio, balancing fine-grained reconstruction and semantic granularity. The architecture eschews multiple encoders or mixture-of-experts, instead relying on multimodal self-attention at every layer for deep fusion.
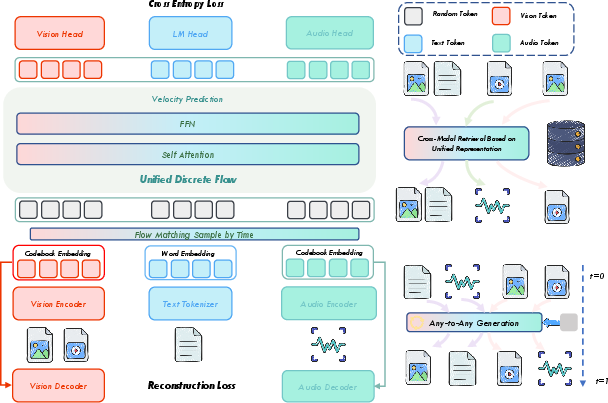
Figure 2: Pipeline of NExT-OMNI, showing DFM-based unified training and multimodal self-attention for deep cross-modal fusion.
The training procedure consists of three progressive stages: warmup for modality encoders, joint omnimodal pre-training, and supervised fine-tuning on diverse instruction data. DFM is applied to discrete token sequences, with metric-induced probability paths and kinetic-optimal velocities guiding the denoising process. The model is trained to minimize a composite loss comprising cross-entropy for DFM, reconstruction losses for each modality, and semantic alignment objectives, with dynamic loss balancing via GradNorm.
Dynamic Generation and Inference Acceleration
To address dynamic-length generation requirements, NExT-OMNI pads response sequences to block-size multiples during training and extends generation lengths in block-size increments during inference, guided by <EOS> token confidence. The vanilla adaptive cache design caches instruction features and selectively updates response features based on cosine similarity, exploiting the minimal change in features during iterative denoising. This, combined with parallel decoding, yields a 1.2× speedup over AR models.
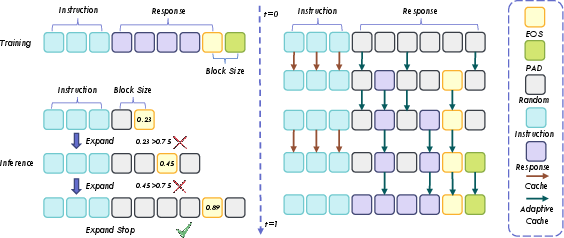
Figure 3: Dynamic generation strategy and vanilla adaptive cache design for efficient inference and accelerated decoding.
Modality Encoders and Heads
The vision encoder is initialized from CLIP-ViT-Large and trained on 70M image-text pairs, optimizing pixel-level, perceptual, discriminator, and vector quantization losses, as well as image-text contrastive alignment. The audio encoder is initialized from Whisper-Turbo and trained on 102K hours of audio-text pairs, optimizing mel-spectrum reconstruction, feature matching, discriminator, and vector quantization losses, plus token-level caption alignment. MCQ is used for both, with vocabulary sizes of 4×4096 (vision) and 2×2048 (audio).
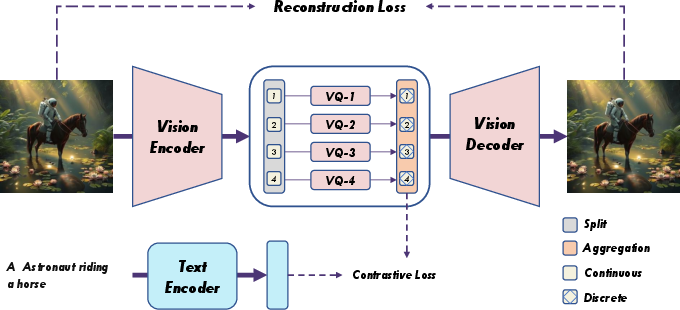
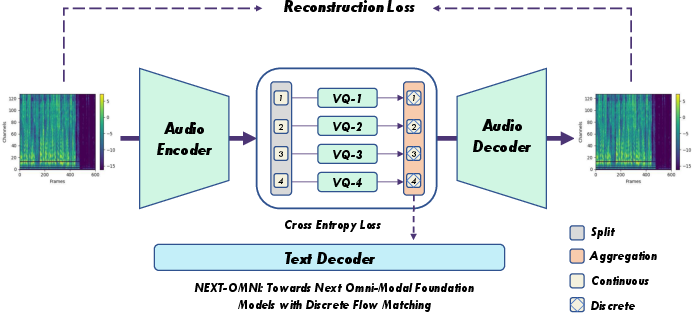
Figure 4: Warmup training pipelines for vision and audio encoders, combining self-supervised reconstruction and semantic alignment.
Modality heads are designed for multi-sub-codebook index prediction, with both next-token and multi-token prediction structures evaluated. The next-token paradigm is adopted for stability.
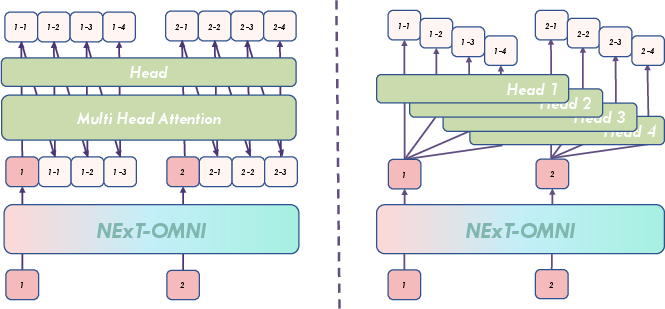
Figure 5: Modality head architectures for multi-sub-codebook index prediction.
Experimental Results
Omnimodal Understanding
NExT-OMNI achieves superior or comparable performance to state-of-the-art OLLMs on OmniBench, WorldSense, and AV-Odyssey, with a 3.2-point average improvement over OpenOmni. The DFM paradigm demonstrates strong generalization and bidirectional fusion for omnimodal tasks.

Figure 6: Visualization of omnimodal understanding, showing effective comprehension and response to complex multimodal queries.
Multi-Turn Vision and Speech Interaction
On OpenING, NExT-OMNI outperforms AR and hybrid models in multi-turn vision-language interaction, demonstrating natural determination of image generation locations and contextual consistency.

Figure 7: Multi-turn vision-language interaction, with both predefined and spontaneous image generation locations.
For multi-turn speech-language interaction, NExT-OMNI matches or exceeds AR-based models on Spoken QA, supporting flexible text and speech input/output.
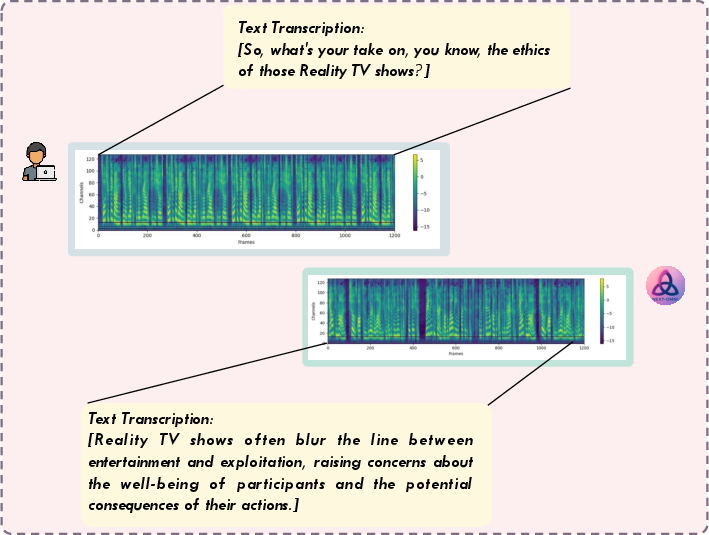
Figure 8: Multi-turn speech-language interaction, enabling seamless text-speech exchanges.
Multimodal Retrieval
NExT-OMNI, using unified DFM-based representations, achieves top-5 retrieval accuracy surpassing both AR and hybrid models on InfoSeek, OVEN, FashionIQ, and CIRR. Unified representations and bidirectional encoding are shown to be critical for feature similarity-based retrieval.
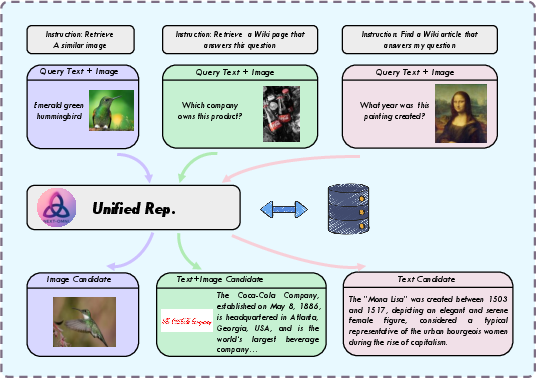
Figure 9: Multimodal retrieval via unified representations, highlighting DFM's advantage over AR for cross-modal tasks.
Generation and Understanding Across Modalities
NExT-OMNI demonstrates competitive or superior results in text-to-image (GenEval, DPG-Bench), text-to-audio, and text-to-video generation, as well as image, audio, and video understanding. The model supports iterative refinement for generation in any modality.

Figure 10: Text-to-image generation sampled from GenEval, showing semantic and aesthetic alignment.
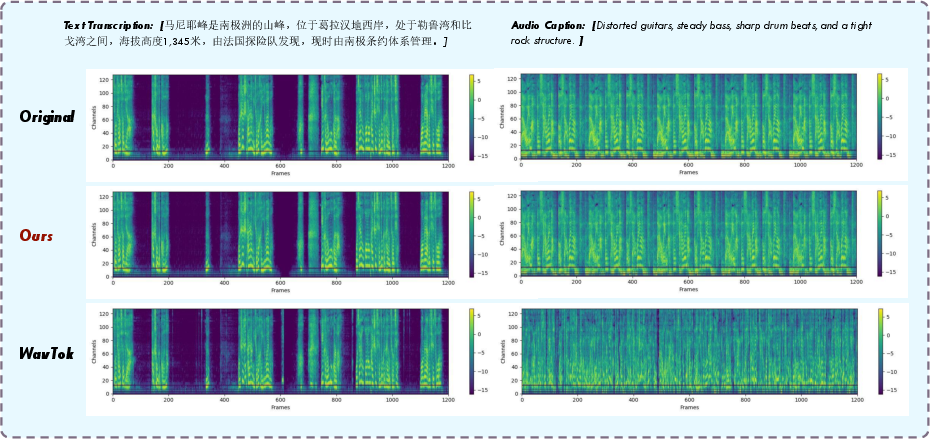
Figure 11: Text-to-audio generation, including speech synthesis and music.

Figure 12: Text-to-video generation, demonstrating scalability and quality.

Figure 13: Image understanding with accurate and well-aligned reasoning responses.
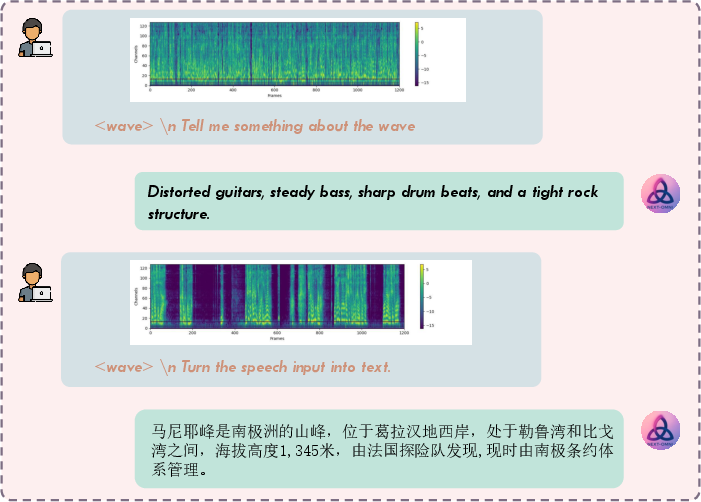
Figure 14: Audio understanding, including transcription and captioning.

Figure 15: Video understanding, with spatiotemporal perception.
Cross-Modal and Zero-Shot Generation
NExT-OMNI supports zero-shot cross-modal generation, enabling outputs in any modality from arbitrary inputs, and demonstrates deep alignment across modalities.
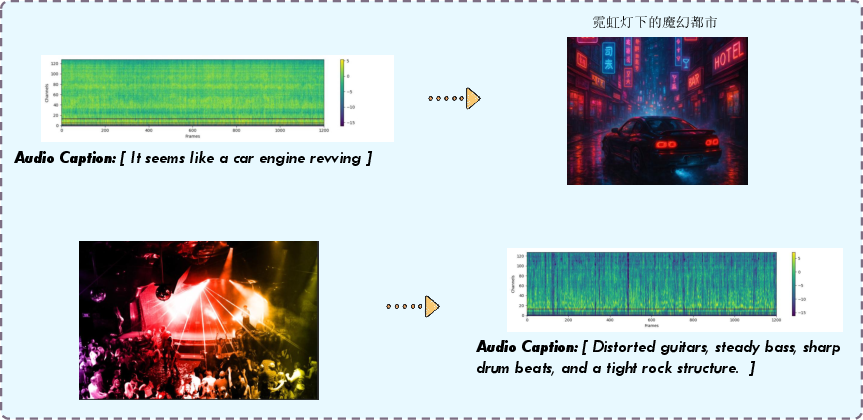
Figure 16: Zero-shot cross-modal generation, illustrating any-to-any capability.
Speed and Scalability
DFM-based parallel decoding and caching yield significant inference acceleration over AR models, as shown in VBench speed comparisons.
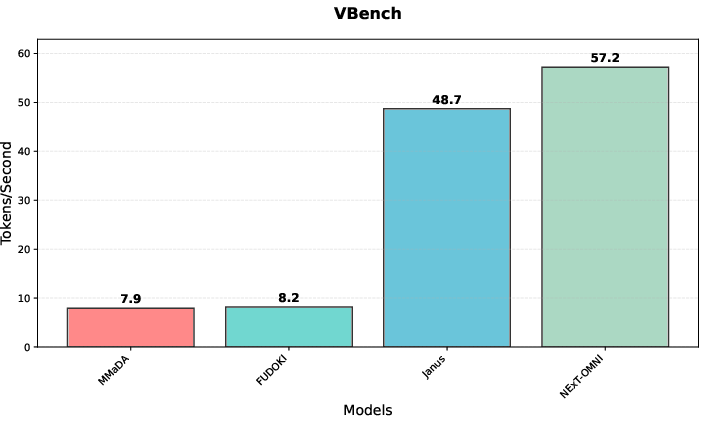
Figure 17: Speed comparison on VBench, demonstrating DFM's parallel decoding advantage.
Ablation studies confirm that DFM and unified representations enhance generation and retrieval, while dynamic generation strategies and reconstruction losses improve understanding and fine-grained feature integration. Scalability is validated with increasing data and model size.
Implications and Future Directions
NExT-OMNI establishes DFM as a viable alternative to AR for unified multimodal modeling, with strong empirical results in understanding, generation, retrieval, and interaction tasks. The architecture's concise design and bidirectional fusion enable broader applicability, including world modeling, action trajectory generation, and physical AI domains. The work suggests that unified omnimodal models, despite potential trade-offs in specialized task performance, offer superior generalizability and are essential for AGI systems capable of real-world interaction and iterative self-improvement.
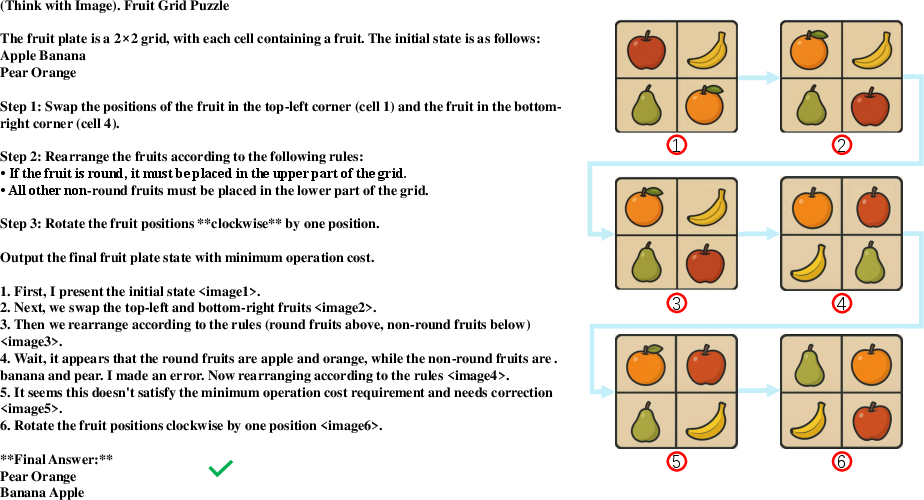
Figure 18: Thinking with images, integrating visual cues into intermediate reasoning for improved interpretability and problem-solving.
Conclusion
NExT-OMNI demonstrates that discrete flow matching, combined with reconstruction-enhanced unified representations and dynamic generation strategies, enables efficient, scalable, and generalizable any-to-any omnimodal modeling. The model achieves strong results across understanding, generation, and retrieval tasks, with accelerated inference and deep multimodal fusion. The findings advocate for further exploration of DFM-based unified architectures in broader domains, including world models and embodied AI, where general capability and flexible interaction are paramount.

