- The paper introduces a Universal Head Avatar Prior (UHAP) that encodes both geometric and dynamic appearance variations for photorealistic avatar synthesis.
- It employs a monocular encoder for efficient personalization, enabling rapid adaptation to new subjects with minimal data.
- The diffusion-based speech model maps audio features to latent expression codes, achieving lifelike facial animations with high lip-sync accuracy.
Audio-Driven Universal Gaussian Head Avatars
The paper "Audio-Driven Universal Gaussian Head Avatars" proposes a novel framework for synthesizing photorealistic 3D head avatars driven by speech input. This work introduces a Universal Head Avatar Prior (UHAP), enabling the generation of high-fidelity avatars with effective lip synchronization and expressive facial motions across multiple identities. The authors address the limitations of previous approaches that generally focus only on geometric deformations, neglecting dynamic appearance variations induced by audio.
Key Contributions
Universal Head Avatar Prior (UHAP)
UHAP is a person-agnostic model trained on cross-identity multi-view videos that captures identity-specific details from neutral scans, facilitating the synthesis of avatars with high fidelity. Unlike traditional methods, UHAP encodes both geometric and appearance variations within its latent expression space. This allows for nuanced animations, including eyebrow movements, gaze shifts, and mouth interior dynamics.
Monocular Encoder for Efficient Personalization
For efficient personalization to new subjects, the authors employ a monocular encoder that performs lightweight regression of dynamic expression variations from video frames. This process facilitates rapid adaptation of the UHAP model to new identities, requiring only minimal data inputs such as a static scan or short video.
Audio-Driven Synthesis
The proposed diffusion-based speech model maps raw audio features directly into the UHAP's latent expression space. By decoding these audio-driven expression codes via UHAP, the system generates avatars that are not only realistic in motion but also visually compelling with dynamic appearance changes synchronized to the audio input.
Implementation Overview
Architecture
- Expression Encoder: Utilizes variational autoencoder techniques to map deviations from neutral texture and geometry states into a latent expression code.
- UHAP Decoder: Comprises three components—Neutral Decoder for identity features, Guide Mesh Decoder for vertex positions, and Gaussian Avatar Decoder for rendering the avatars.
- Speech Model: Adopts a diffusion model to predict expression codes from audio features, leveraging self-attention and cross-attention mechanisms.
Training and Personalization
The framework relies on large-scale multi-view video datasets, ensuring high-fidelity synthesis. The personalization process involves fine-tuning the UHAP decoder with new subject-specific data, optimizing for identity and expression dynamics efficiently.
Experimental Evaluation
Qualitative and Quantitative Results
The method outperforms state-of-the-art geometry-only methods across lip-sync accuracy, image quality, and perceptual realism metrics. Qualitative assessments demonstrate the system's ability to produce sharp and detailed facial animations, including difficult-to-model regions such as the mouth interior and facial hair.
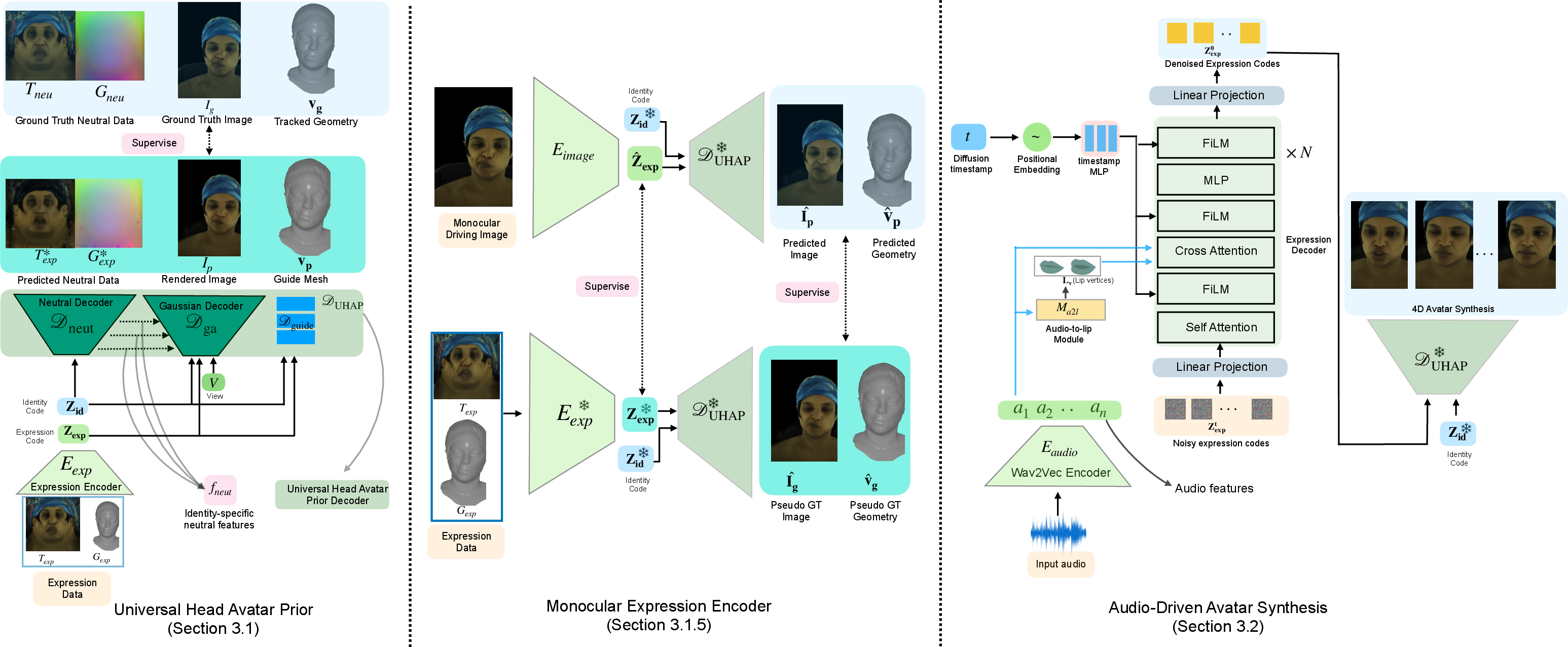
Figure 1: Overview of our Audio-Driven Universal Gaussian Avatar pipeline.
Ablation Studies
The paper conducts thorough ablation studies to assess the contributions of the neutral features and the pretraining of the monocular encoder. These studies reveal the importance of disentangling identity-specific details during training for achieving high-quality avatar synthesis.
Conclusion
The proposed framework sets a new benchmark for audio-driven avatar synthesis, combining high-fidelity geometric and appearance modeling. It demonstrates versatility in synthesizing realistic humanoid avatars from audio inputs while being adaptable to new identities with sparse data. Future work may focus on enhancing the system's robustness to challenging capture conditions, potentially driving further advancements in virtual communication and digital entertainment applications.

