Vision-based Goal-Reaching Control for Mobile Robots Using a Hierarchical Learning Framework
Abstract: Reinforcement learning (RL) is effective in many robotic applications, but it requires extensive exploration of the state-action space, during which behaviors can be unsafe. This significantly limits its applicability to large robots with complex actuators operating on unstable terrain. Hence, to design a safe goal-reaching control framework for large-scale robots, this paper decomposes the whole system into a set of tightly coupled functional modules. 1) A real-time visual pose estimation approach is employed to provide accurate robot states to 2) an RL motion planner for goal-reaching tasks that explicitly respects robot specifications. The RL module generates real-time smooth motion commands for the actuator system, independent of its underlying dynamic complexity. 3) In the actuation mechanism, a supervised deep learning model is trained to capture the complex dynamics of the robot and provide this model to 4) a model-based robust adaptive controller that guarantees the wheels track the RL motion commands even on slip-prone terrain. 5) Finally, to reduce human intervention, a mathematical safety supervisor monitors the robot, stops it on unsafe faults, and autonomously guides it back to a safe inspection area. The proposed framework guarantees uniform exponential stability of the actuation system and safety of the whole operation. Experiments on a 6,000 kg robot in different scenarios confirm the effectiveness of the proposed framework.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows how to make a very big, heavy robot (about 6,000 kg) drive itself to chosen spots safely and accurately, even on slippery, uneven ground. The key idea is to split the problem into simple parts that work together: seeing where the robot is, planning a smooth path, making the wheels follow that plan despite tricky physics, and keeping everything safe.
What questions did the researchers ask?
In simple terms, they asked:
- How can a large robot find and reach a goal safely without a human steering it all the time?
- Can we use learning methods (like reinforcement learning) but still guarantee safety and stability?
- How do we make the robot’s wheels follow the plan correctly when the ground is slippery or bumpy?
- Can the system notice danger on its own and move the robot back to a safe area?
How did they do it?
Think of the robot as a team of four roles that work together: See, Plan, Move, and Stay Safe.
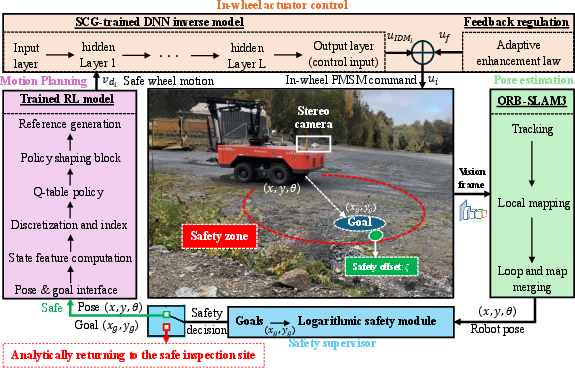
1) See: Where am I right now?
The robot uses two cameras and a method called visual SLAM (specifically, ORB-SLAM3). Imagine walking through a new place and building a mental map while keeping track of your position—SLAM does that with images. It continuously estimates the robot’s position and direction so the planner always knows where the robot is.
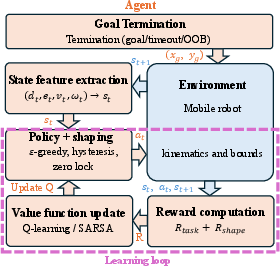
2) Plan: What should I do next?
They use reinforcement learning (RL) to plan how to move toward a goal. RL is like learning by trial and error with rewards. Here’s how they made it safe and smooth:
- Instead of directly choosing speeds, the RL planner chooses gentle changes in speed and turning (accelerations). That’s like pressing the gas or turning the wheel gradually, not suddenly jerking.
- It keeps the robot within real-world limits (like maximum speed and turn rate) and uses rewards that encourage steady, non-wiggly motion and getting closer to the goal.
- It uses simple, reliable RL methods (Q-learning and SARSA) that store what works best in a table and improve it over time.
- Near the goal or when already aligned, it adds small “rules” to prevent tiny back-and-forth motions.
Result: a high-level, smooth motion command telling how fast to move forward and how fast to turn.
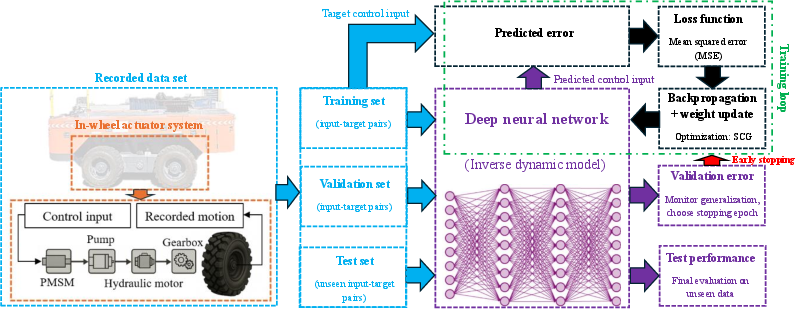
3) Move: Make the wheels do it—accurately
Big robots have complicated, powerful wheels and motors that don’t always respond perfectly—especially on soft soil where wheels slip. To handle this:
- A deep neural network (DNN) is trained as a “translator.” It learns: “If we want the wheel to go this fast, how much motor command should we send?” This is called an inverse dynamics model.
- Then a robust adaptive controller is added. Think of it as a smart cruise control that automatically adjusts when the ground gets slippery or conditions change. It uses feedback (the actual wheel speed) to correct errors in real time.
- The team proves mathematically that this control layer is stable. In everyday words: the wheel speeds settle down quickly to the desired values and don’t spiral out of control even when things get tough.
4) Stay Safe: Watchdog and safe return
On top of everything, there’s a safety supervisor—like an invisible safety bubble. If the robot starts getting into an unsafe situation (for example, due to a sensor fault), it:
- Slows and stops the robot,
- Then automatically guides it back to a known “safe inspection area” without needing a human to intervene.
What did they find?
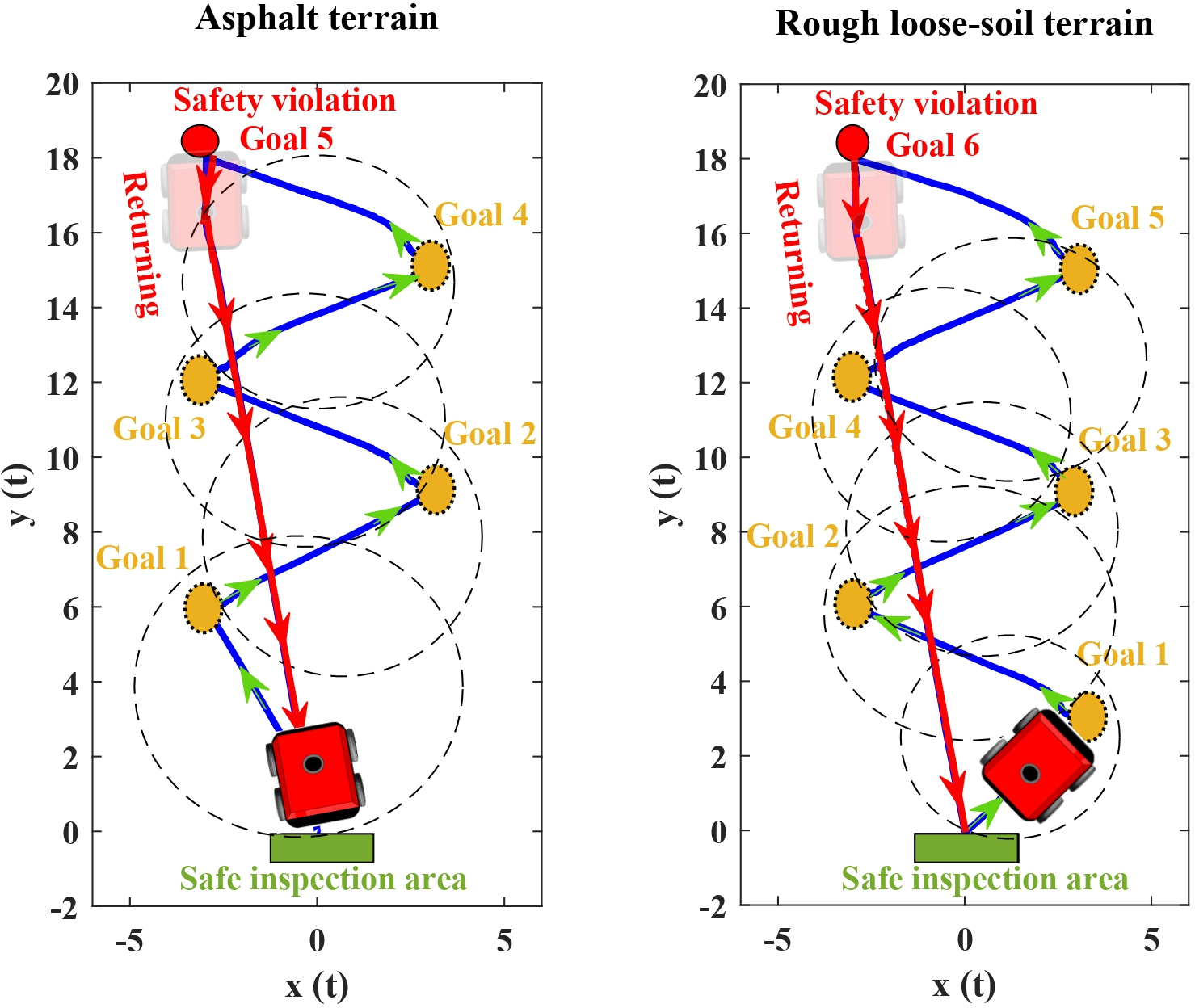
They tested the full system on a real 6,000 kg off-road robot on two surfaces:
- Smooth asphalt (low slip),
- Soft, loose soil (high slip and harder to control).
Across multiple goals on both terrains:
- The robot consistently reached its goals with about 3 cm average position error (very accurate for such a heavy machine).
- The controller handled slippery ground well; performance on soft soil was nearly as good as on asphalt.
- When they intentionally introduced a fault (to mimic a sensor problem), the safety supervisor detected the issue and guided the robot back to the safe area automatically.
- The new wheel-control method (DNN + adaptive controller) outperformed other advanced controllers in how quickly and smoothly it reached the commanded speeds.
Why this matters: It shows that you can mix learning (for planning) with strong safety and control (for execution) to run big robots autonomously, safely, and accurately in the real world.
Why does this matter?
- Safer autonomy for heavy machines: Mines, construction sites, and forests are risky places. Robots that can move themselves safely reduce danger for people.
- Reliable performance on tough ground: The system works even when wheels slip, which is common off-road.
- Less human supervision: The robot can detect problems and return to safety on its own.
- A new combo that’s rare: Using two learning layers—an RL planner and a learned model of the robot’s actuators—together with proven safety and stability is unusual, especially for large, heavy robots. This framework shows a practical way to make advanced autonomy both smart and safe.
In short, this research is a step toward dependable, real-world autonomous robots that can “see, think, move, and stay safe” on their own.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes what remains missing, uncertain, or unexplored in the paper, with concrete directions for future research:
- RL scope and scalability
- The tabular, discretized Q/SARSA planner scales poorly with state/action resolution and does not address larger workspaces, richer goal sets, or higher-speed regimes; a study of function approximation (e.g., deep RL) and its safety would be needed to scale.
- The planner ignores obstacles and dynamic agents; integrating obstacle-aware mapping, collision avoidance, and multi-goal routing remains open.
- The MDP transitions are deterministic and purely kinematic, omitting stochastic slippage, terrain variability, and model uncertainty; the impact of stochastic, non-Markov dynamics on policy robustness is unquantified.
- Sensitivity to reward shaping is not analyzed; no ablations quantify which shaping terms matter, how weight choices affect convergence/behavior, or how to tune them systematically.
- Sample efficiency and convergence behavior (learning curves, variance across seeds, exploration schedules) are not reported; it is unclear how much data and time are required to obtain a reliable policy.
- Sim-to-real transfer and generalization
- The RL policy is trained in a MATLAB simulator and deployed on a 6,000 kg robot without a documented sim-to-real methodology (e.g., domain randomization, dynamics noise, slip models); robustness to mismatch is not quantified.
- Generalization is only tested on two terrain types at very low speeds; behavior under higher speeds, slopes, payload changes, wet/muddy surfaces, ruts, or rapid terrain transitions is unknown.
- No analysis of long-term drift in the DNN inverse dynamics due to actuator wear/temperature/pressure; there is no framework for online adaptation or continual learning of the inverse model.
- Actuator modeling and control assumptions
- The DNN inverse model uses only wheel rim speed v_i as input and outputs u_i, ignoring key covariates (e.g., normal load, slope, temperature, hydraulic pressure, wheel slip estimates, interaction forces), which limits identifiability and generalization; the benefit of richer inputs remains untested.
- Wheels are controlled independently with no explicit coupling terms; skid-steer coupling, load transfer, and terrain-induced cross-effects are not modeled in either the DNN or RAC, leaving multi-wheel interaction compensation unexplored.
- The RAC stability proof assumes bounded, locally Lipschitz uncertainties and unknown positive gains but does not validate these assumptions experimentally or quantify realistic bounds.
- Input saturation, actuator delays, and rate limits are not incorporated in the RAC analysis; closed-loop stability and tracking under hard input constraints are unaddressed.
- Safety guarantees and supervisor design
- Safety is enforced via a logarithmic barrier on a circular set defined by a heuristic E(t) and O, but forward invariance and completeness (i.e., no false trips or missed hazards) are not proven for the full robot state; the safety set is not tied to obstacles, terrain hazards, or kinematic constraints.
- The safety supervisor’s state machine, braking profile, and latching logic are not formally specified or verified; worst-case stopping distances and guarantees that the robot halts within the safe set at any speed are not analyzed.
- The “fault injection” is an unspecified alteration of SLAM output; the detection logic, thresholds, false-positive/negative rates, and response time under realistic sensor/communication faults are not characterized.
- There is no end-to-end safety proof for the combined SLAM–RL–DNN–RAC–supervisor system; only wheel-level tracking stability is analyzed.
- SLAM robustness and integration
- ORB-SLAM3 is used in stereo mode without inertial fusion in the loop (despite an available INS); resilience to low-texture scenes, strong vibrations, lighting variability, dust/fog, and dynamic objects is not evaluated.
- Loop-closure corrections can induce abrupt pose jumps; the downstream effect on the planner/controller (e.g., transient spikes in commands) and mitigation strategies (e.g., pose smoothing) are not discussed.
- Computational load, latency, and synchronization across SLAM, planner, and controller threads are not reported; timing jitter and its control impact are unknown.
- Mission-level functionality
- The framework addresses point-to-point goal reaching but not coverage tasks, patrol missions, or multi-goal optimization (e.g., ordering, time windows); integrating higher-level task planning is an open step.
- There is no mechanism for on-the-fly goal generation or re-planning around newly detected hazards/obstacles.
- Evaluation design and metrics
- Experiments are limited to centimeter-level accuracy metrics; time-to-goal, energy use, path efficiency/suboptimality, control effort, and robustness under disturbances are not reported.
- No comparisons are provided against standard planning/control baselines (e.g., pure pursuit, DWA, MPC, model-based planners) at the mission level; only actuator controllers are compared.
- The reported speeds and accelerations are low (v_max=0.25 m/s, ω_max=0.15 rad/s); performance and safety at operationally relevant speeds for heavy robots remain untested.
- Reproducibility is hindered by missing details (e.g., number of distance bins N_d, start/goal sampling distributions, dataset sizes for DNN training, coverage of operating conditions) and lack of released code/data.
- Theoretical gaps
- The shaping includes terms that are not potential-based; thus, the optimal policy set is altered, but there is no theoretical analysis of the induced trade-offs (e.g., stability vs. optimality).
- The MDP is modified near the goal (state-dependent action constraints, zero-lock), yet the impact on convergence guarantees of Q/SARSA and on closed-loop stability is not analyzed.
- There is no analysis of robustness margins (gain/phase, input-to-state stability) for the combined kinematic planner and dynamic tracking controller under SLAM noise and delays.
- Sensing and estimation opportunities
- The approach does not leverage slip estimation, terrain classification, or force/torque/proprioceptive cues to adapt either the planner or actuator controller online; incorporating such feedback remains open.
- Fusion of stereo with IMU, wheel odometry, and other exteroceptive sensors (e.g., LiDAR) for improved robustness in harsh environments is not explored.
- Safety set and recovery strategy generality
- The choice of safe area at (0,0) and the circular safety set may be infeasible or unsafe in cluttered, uneven, or constrained environments; methods for environment-aware safety set definition and guaranteed safe recovery paths are needed.
- Human factors and operational readiness
- The framework’s behavior under operator intervention, mode switching, and supervisory overrides is not described; fail-operational vs. fail-safe modes and HRI protocols remain unspecified.
- Cybersecurity aspects (e.g., resilience to spoofed visual features or sensor data injection) are not considered.
These gaps outline a roadmap for extending the framework toward scalable, obstacle-aware, verifiably safe, and operationally robust deployment in real-world heavy-robot settings.
Glossary
- Actor–critic: A reinforcement learning architecture with separate policy (actor) and value (critic) components; "combined with an actorâcritic update."
- Atlas structure: A SLAM component that manages multiple submaps for multi-session mapping and later merging; "An Atlas structure manages multiple maps for multi-session reuse and later merging"
- Backstepping RAC: A robust adaptive control design using backstepping techniques; "Backstepping RAC \cite{zuo2022adaptive}"
- Bundle adjustment: An optimization method that jointly refines camera poses and 3D points to reduce reprojection error; "trigger global bundle adjustment to refine the entire map"
- Cartesian product: The set formed by pairing all elements of two sets (used to define a discrete action space grid); "the Cartesian product of these sets."
- Constrained Markov decision process (MDP): An MDP augmented with constraints on states/actions to ensure safety or performance limits; "constrained Markov decision process (MDP) framework"
- Control Barrier Function (CBF): A control-theoretic tool that enforces forward invariance of a safe set by constraining inputs; "Control Barrier Functions (CBFs)"
- Deadband: A small region around zero where commands or responses are suppressed to avoid oscillations; "deadbands $\omega_{\mathrm{db}$ and $e_{\mathrm{db}$"
- DBoW2: A bag-of-words library for visual place recognition used in SLAM; "via DBoW2"
- EPnP: Efficient Perspective-n-Point, an algorithm to estimate camera pose from 2D–3D correspondences; "relocalization performed using EPnP."
- EuRoC: A standard SLAM/VO benchmarking dataset of micro aerial vehicle sequences; "EuRoC"
- Global shutter: A camera sensor readout that exposes all pixels simultaneously to avoid motion distortion; "global shutter"
- Hysteresis: A control mechanism that uses different thresholds for engaging/disengaging to prevent chattering; "a hysteresis term that suppresses residual angular velocity"
- INS-RTK: Inertial Navigation System with Real-Time Kinematic corrections for high-accuracy positioning; "INS-RTK"
- Inverse dynamics: Modeling or control that computes required inputs to achieve desired motion outputs; "inverse-dynamics modeling of the actuator system"
- Kalibr: A toolbox for calibrating multi-camera and camera–IMU systems; "Kalibr"
- Keyframe: Selected frames stored in SLAM that anchor mapping and optimization; "decides when to insert new keyframes."
- Lipschitz continuity: A regularity property bounding how fast a function can change, aiding stability/robustness analysis; "bounded and locally Lipschitz continuous."
- Logarithmic barrier function: A barrier term that grows to infinity at a safety boundary to prevent constraint violation; "a logarithmic barrier function is incorporated"
- Loop closing: The SLAM process of detecting a previously visited place to reduce accumulated drift; "provides reliable loop closing"
- Lyapunov function: A scalar energy-like function used to analyze or guarantee stability of dynamical systems; "embedding Lyapunov functions in a constrained Markov decision process (MDP) framework"
- Maximum a posteriori (MAP) optimization: An estimation approach maximizing the posterior probability given priors and measurements; "maximum a posteriori optimization"
- Off-policy learning: RL that learns the value of the optimal (or target) policy while following a different behavior policy; "Q-learning (off-policy):"
- On-policy learning: RL that learns the value of the policy being executed; "SARSA (on-policy):"
- ORB features: Oriented FAST and Rotated BRIEF keypoints/descriptors used for robust feature matching; "extracts ORB features"
- ORB-SLAM3: A state-of-the-art visual SLAM system supporting monocular, stereo, and visual–inertial setups; "ORB-SLAM3"
- Place recognition: Detecting that the current view corresponds to a previously visited location; "place recognition"
- Potential-based shaping: Reward shaping technique that adds the discounted difference of a potential function to preserve optimal policies; "Classical potential-based shaping"
- Q-learning: A value-based off-policy RL algorithm that learns action values via bootstrapping; "Q-learning and SARSA"
- Relocalization: Recovering camera pose after tracking loss by matching to the map; "relocalization performed using EPnP."
- Robust adaptive controller (RAC): A controller that adapts to uncertainties and disturbances while providing robustness guarantees; "a model-based robust adaptive controller (RAC)"
- Saturation operator: A function that clamps a variable within specified bounds; "is a saturation operator"
- Scaled Conjugate Gradient (SCG): A second-order optimization algorithm for training neural networks without line searches; "Scaled Conjugate Gradient (SCG) method"
- SE(3): The Special Euclidean group representing 3D rigid body poses (rotation and translation); "S E(3)"
- Skid-steered vehicle: A wheeled vehicle that turns by differential wheel speeds causing lateral tire slip; "skid-steered off-road vehicle"
- SLAM (Simultaneous Localization and Mapping): The process of building a map of an environment while localizing within it; "visual SLAM"
- SO(3): The Special Orthogonal group of 3D rotations; "S O(3)"
- Soft Actor-Critic (SAC): An entropy-regularized actor–critic RL algorithm promoting exploration and stability; "soft actor-critic algorithm"
- Stereo SLAM: SLAM that uses stereo image pairs for depth estimation and tracking; "runs stereo SLAM in real time"
- Temporal-difference (TD) update: An RL update that bootstraps from current estimates to reduce prediction error; "a temporal-difference (TD) update is applied"
- Transition kernel: The probability (or rule) describing state transitions under actions in an MDP; "the transition kernel is deterministic."
- Uniform exponential stability: A strong form of stability where the state converges to equilibrium at an exponential rate uniformly over initial conditions; "guarantees uniform exponential stability of the actuation system"
- Wheel slip ratio: A measure of wheel ground slip comparing wheel rotation to vehicle speed; "wheel slip ratio"
Practical Applications
Practical Applications Derived from the Paper’s Findings
Below is a consolidated set of actionable applications that follow directly from the paper’s hierarchical framework (visual SLAM → smooth RL goal-reaching → DNN inverse dynamics → robust adaptive controller → safety supervisor). Each item specifies a use case, maps to relevant sectors, and notes assumptions or dependencies that affect feasibility.
Immediate Applications
- Autonomous goal-reaching for heavy mobile robots in hazardous worksites
- Sector: mining, construction, forestry, agriculture
- Use case: centimeter-level docking and positioning of heavy vehicles (e.g., aligning haul trucks at loading points, positioning skid-steered platforms at drill rigs, aligning forestry machines for tool attachment) in GNSS-degraded or GNSS-denied areas.
- Tools/workflow: stereo RGB cameras + ORB-SLAM3 for robust pose; tabular Q-learning/SARSA with acceleration-based action space for smooth motion; per-wheel DNN inverse dynamics; robust adaptive controller (RAC) for slip compensation; safety supervisor state machine with barrier function.
- Dependencies/assumptions: adequate visual features and lighting for SLAM; reliable wheel speed sensing; site-specific RL reward/constraint tuning; actuator data collection for DNN training; compute capable of real-time SLAM and control.
- GNSS-free inspection and relocalization for large robots
- Sector: energy (pipelines, solar farms), underground construction, tunneling, warehouse logistics
- Use case: routine inspection runs and waypoint reaching where GNSS is unreliable; SLAM-based loop closure and relocalization enables long runs with drift reduction.
- Tools/workflow: ORB-SLAM3 Atlas and loop closure; goal-reaching RL planner; safety supervisor to handle faults and guide robot back to “safe area.”
- Dependencies/assumptions: camera calibration quality; stable frame-rate; geometric texture in environment; RTK/INS can be used for validation but not required for operation.
- Slip-resilient motion tracking on soft soils
- Sector: agriculture, forestry, off-road utilities
- Use case: robust adherence to motion commands despite variable slip ratios on loose or muddy surfaces; consistent goal accuracy demonstrated on asphalt and soft soil.
- Tools/workflow: feedforward DNN inverse dynamics per wheel; RAC compensates out-of-distribution disturbances; hysteresis and zero-lock shaping reduce oscillations.
- Dependencies/assumptions: slip within RAC’s bounded uncertainty; sufficient actuator telemetry; per-wheel model fidelity maintained via periodic recalibration.
- Precision tool alignment and autonomous docking
- Sector: construction (attachments), ports/logistics (tug docking), municipal services (snowplows, street sweepers)
- Use case: high-precision approach and alignment for coupling tools, fueling/charging, or loading bays; repeatable positioning reduces human intervention.
- Tools/workflow: RL acceleration commands respecting speed/acc limits; safety supervisor clamps angular motion near goal to eliminate heading wiggles; centimeter-level final approach.
- Dependencies/assumptions: obstacle-free final approach; goal tolerances configured; deadband parameters tuned to platform dynamics.
- Fault-tolerant recovery to a safe inspection area
- Sector: industrial safety/compliance, operations
- Use case: automatic halt and guided return to safe zone upon detected pose faults or constraint violations; reduces downtime and human risk exposure.
- Tools/workflow: logarithmic barrier safety supervisor monitors pose relative to safety circle; deterministic braking and latched recovery mode; state machine for re-entry.
- Dependencies/assumptions: safe zone pre-defined and reachable; recovery path unobstructed; fault detection thresholds calibrated to avoid false positives/negatives.
- “Autonomy retrofit kit” for legacy heavy vehicles
- Sector: OEMs, system integrators
- Use case: upgrade existing skid-steer/independently driven platforms with a modular stack combining vision SLAM, RL planner, DNN actuator modeling, and RAC.
- Tools/workflow: ROS2 integration of ORB-SLAM3; Q-table export from MATLAB training; embedded inference of “myTrainedNetFunction” for actuator commands; controller parameterization guide; safety supervisor SDK.
- Dependencies/assumptions: mechanical interface to actuators; sensor and compute mounting; organizational process for data collection and model training.
- Operator-assist “point-and-go” mode
- Sector: construction, agriculture, logistics
- Use case: operators set a local goal; the robot performs smooth, bounded acceleration-based approach under safety constraints—reducing fatigue and improving repeatability.
- Tools/workflow: UI for goal selection; greedy policy execution with hysteresis/zero-lock; RAC ensures tracking; safety supervisor overrides unsafe actions.
- Dependencies/assumptions: human-machine interface; goal set within workspace bounds; training covers typical approach scenarios.
- Academic benchmarking and hardware-in-the-loop validation for safe RL + adaptive control
- Sector: academia, industrial R&D
- Use case: reproducible stack to study safety-supervised RL on real heavy platforms; validating uniform exponential stability guarantees with DNN feedforward + RAC feedback.
- Tools/workflow: controlled experiments on 6,000 kg robot; dataset protocols for actuator inverse dynamics; public configurations for SLAM and RL reward shaping.
- Dependencies/assumptions: access to testbed; adherence to experimental parameters; safety oversight for trials.
Long-Term Applications
- Full navigation with obstacle avoidance and dynamic environment handling
- Sector: construction, mining, urban services
- Use case: end-to-end autonomy that includes perception-driven obstacle avoidance, path planning, and multi-goal routing beyond rectangular workspaces.
- Tools/workflow: integrate LiDAR/radar/thermal with visual SLAM; expand RL to include obstacle-aware policies or hybrid MPC; extend safety supervisor to dynamic limits.
- Dependencies/assumptions: sensor fusion stack; computational scaling; certified planning algorithms; extensive field validation.
- Certification frameworks and standards for safe RL in heavy machinery
- Sector: policy, regulatory, insurance, OEM compliance
- Use case: standards that mandate safety supervisors, action deadbands, barrier functions, and formal stability proofs for RL-based controllers in safety-critical deployments.
- Tools/workflow: conformance test suites; audit logging of safety events; documentation of training datasets and reward shaping; hazard analyses.
- Dependencies/assumptions: cross-industry consensus; regulator engagement; traceability from sim to real.
- Fleet-level autonomy and multi-robot coordination
- Sector: mining (load-haul-dump), ports, large-scale agriculture
- Use case: coordinated goal-reaching among multiple heavy robots with task allocation, convoying, and shared mapping.
- Tools/workflow: multi-agent RL with safety constraints; map server and Atlas fusion across sessions; fleet dashboard with health and safety metrics.
- Dependencies/assumptions: reliable comms; conflict-free policies; centralized/decentralized coordination strategies; site infrastructure.
- Scalable RL beyond tabular Q (function approximation and continuous control)
- Sector: robotics, software
- Use case: replacing discretized states/actions with neural policy/value functions to handle richer dynamics, larger workspaces, and varied tasks.
- Tools/workflow: actor-critic with Lyapunov/CBF augmentations; curriculum learning; domain randomization; safe exploration strategies.
- Dependencies/assumptions: stability-preserving architectures; compute and sample efficiency; rigorous safety guarantees.
- Online adaptive inverse dynamics and lifelong learning
- Sector: maintenance, operations
- Use case: continuously adapting DNN actuator models to wear, temperature, payload changes, and extreme slip—reducing manual recalibration.
- Tools/workflow: online identification; meta-learning; uncertainty estimation; safety-aware model updates gated by the supervisor.
- Dependencies/assumptions: robust online training pipelines; monitoring for catastrophic forgetting; safeguards against unsafe parameter drift.
- Predictive maintenance from actuator model residuals
- Sector: industrial analytics
- Use case: using discrepancies between measured and expected wheel dynamics to flag degrading components (motors, hydraulics, sensors).
- Tools/workflow: residual trend analysis; anomaly detection; integration with CMMS; maintenance scheduling.
- Dependencies/assumptions: sufficient sensor fidelity; labeled fault data; threshold calibration to balance false alarms vs misses.
- Human–robot shared autonomy and collaborative tasks
- Sector: construction, logistics, agriculture
- Use case: blending operator inputs with safe goal-reaching autopilot and adaptive actuation, enabling efficient task sharing in tight spaces.
- Tools/workflow: arbitration policies; intent inference; real-time safety overlays; haptic feedback.
- Dependencies/assumptions: ergonomic HMIs; robust intent detection; training for operators.
- Extreme environment SLAM enhancements
- Sector: mining (dust), energy (night ops), disaster response
- Use case: augmenting the pipeline to operate reliably under dust, low light, reflective surfaces, and dynamic backgrounds.
- Tools/workflow: multimodal sensors (LiDAR/radar/thermal); robust feature extraction; adaptive SLAM loops; map quality monitoring.
- Dependencies/assumptions: sensor budget; environmental testing; fusion algorithm maturity.
- Digital twin simulation and sim-to-real training
- Sector: software, robotics R&D
- Use case: high-fidelity simulation of heavy robot dynamics and terrain slip to pre-train RL and DNN models, reducing field data needs.
- Tools/workflow: physics-based soft-soil simulators; terrain parameter randomization; transfer learning; scenario libraries.
- Dependencies/assumptions: credible simulators; domain gap mitigation; validation plans.
- Insurance and risk governance for autonomous heavy systems
- Sector: policy, finance
- Use case: structured risk models that incorporate safety supervisor behavior, fault recovery rates, and stability guarantees in underwriting and compliance.
- Tools/workflow: standardized reporting of incidents; safety KPIs; third-party audits; incident replay and traceability.
- Dependencies/assumptions: data-sharing agreements; privacy/security; agreement on metrics.
- Educational curricula and open-source benchmarks for safe hierarchical control
- Sector: academia, workforce development
- Use case: teaching materials and reference implementations to train engineers on combining SLAM, safe RL, inverse dynamics modeling, and RAC.
- Tools/workflow: modular ROS2 packages, reproducible training configurations, datasets, evaluation suites.
- Dependencies/assumptions: community maintenance; licensing; accessible hardware.
Notes on feasibility across applications:
- The current RL planner addresses goal-reaching without explicit obstacle avoidance; extensions are required for cluttered or dynamic environments.
- Visual SLAM performance depends on calibration, frame rate, feature richness, and environmental conditions (dust, glare, darkness).
- The DNN inverse dynamics and RAC depend on quality actuator telemetry and may require periodic retraining as hardware ages or tasks change.
- Safety supervisor parameters (barrier offsets, deadbands) must be site- and platform-specific, and validated under local regulations and safety standards.
Collections
Sign up for free to add this paper to one or more collections.

