FlowBlending: Stage-Aware Multi-Model Sampling for Fast and High-Fidelity Video Generation
Abstract: In this work, we show that the impact of model capacity varies across timesteps: it is crucial for the early and late stages but largely negligible during the intermediate stage. Accordingly, we propose FlowBlending, a stage-aware multi-model sampling strategy that employs a large model and a small model at capacity-sensitive stages and intermediate stages, respectively. We further introduce simple criteria to choose stage boundaries and provide a velocity-divergence analysis as an effective proxy for identifying capacity-sensitive regions. Across LTX-Video (2B/13B) and WAN 2.1 (1.3B/14B), FlowBlending achieves up to 1.65x faster inference with 57.35% fewer FLOPs, while maintaining the visual fidelity, temporal coherence, and semantic alignment of the large models. FlowBlending is also compatible with existing sampling-acceleration techniques, enabling up to 2x additional speedup. Project page is available at: https://jibin86.github.io/flowblending_project_page.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a simple way to make AI-generated videos faster to create without making them look worse. The idea is called FlowBlending. It uses a big, powerful model when it matters most and a smaller, faster model in the middle, so you get almost the same video quality as the big model but in much less time.
What questions are the researchers trying to answer?
- Do we really need a large (slow, powerful) model for every step of video generation?
- If not, when can we safely use a smaller (faster) model without hurting quality?
- Can switching smartly between a large and small model speed things up while keeping videos sharp, smooth, and on-topic with the prompt?
How did they do it? (Explained simply)
Think of AI video generation like cleaning a foggy window to reveal a picture:
- At the start, everything is noise. The early steps sketch the overall layout and motion—like outlining where people and objects should be.
- The middle steps fill things in more steadily—like coloring within the lines.
- The late steps sharpen details—like adding texture and fixing tiny flaws.
“Model capacity” is just how powerful a model is (big model = strong expert, small model = quick assistant). The team asked: when do we need the expert, and when can the assistant handle it?
Their FlowBlending schedule does this:
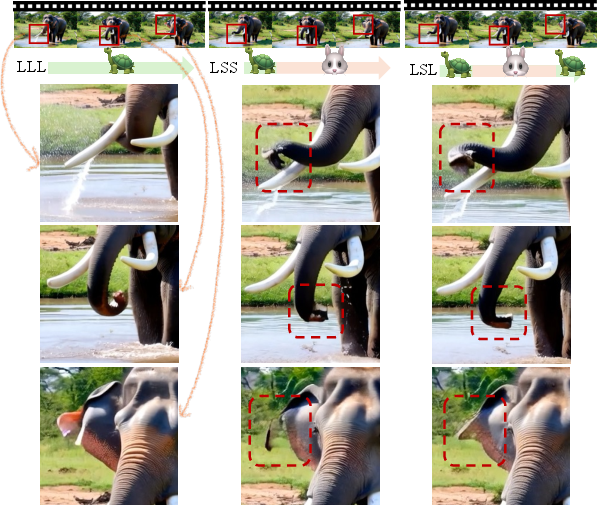
- Early steps: use the large model to set the global structure and motion (so the video matches the text prompt and makes sense).
- Middle steps: switch to the small model, because both models behave very similarly here.
- Late steps: switch back to the large model to refine details and remove flicker or artifacts.
How they picked the switch points:
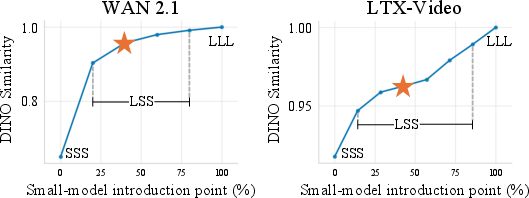
- Early boundary (when to switch from large to small): they compared how similar the results were to using the large model for everything. As long as similarity stayed high, they knew the structure was set, so it was safe to switch.
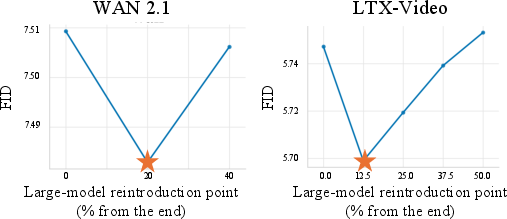
- Late boundary (when to switch back to large): they measured overall visual quality and looked for the sweet spot where details improved without adding artifacts.
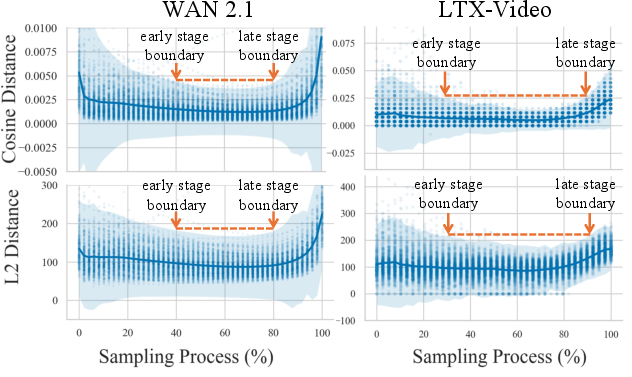
- They also checked how differently the two models “wanted to change” each step (they call this “velocity divergence”). That difference is high at the start and end (use large model) and low in the middle (use small model)—a helpful rule of thumb.
No extra training was needed. They just reused existing big and small versions of popular video models and changed which one ran at which stage.
What did they find, and why is it important?
- Early steps need the big model: It sets the scene and motion. If you start with the small model, it’s hard to fix mistakes later—even if you switch to the big model afterward.
- Middle steps can use the small model: Both models give almost the same updates here, so you save time without losing quality.
- Late steps benefit from the big model: It cleans up fine details and reduces flicker or weird artifacts.
- Speed-ups with quality kept: On two well-known video models (LTX-Video and WAN 2.1), FlowBlending made generation up to about 1.65× faster and cut the amount of computation by about 57%, while keeping the big model’s quality (sharpness, smooth motion, and matching the text prompt).
- Plays well with others: FlowBlending works on top of other speed-up tricks (like using fewer steps with better solvers or using distilled, faster models), giving even more acceleration.
Why this matters:
- Faster, cheaper video generation with big-model quality is useful for creative tools, rapid prototyping, and real-time applications.
- Lower compute means less energy used and lower costs.
What methods and terms mean (in everyday language)
- Diffusion/denoising steps: The model starts from random noise and gradually “cleans” it until a video appears, step by step.
- Model capacity: How big and powerful a model is. Bigger often means better but slower.
- FLOPs: A rough measure of how much math the computer has to do—the lower, the faster/cheaper.
- Velocity (here): The model’s “advice” for how to change the current frames at each step. If two models give similar advice in the middle steps, you can use the smaller one safely.
- Velocity divergence: How different the big model’s advice is from the small model’s. High difference = use big model; low difference = small model is fine.
What’s the bigger impact?
FlowBlending shows that:
- You don’t need maximum power at every moment—be smart about when to use it.
- Video generators can be made much faster without retraining or changing the models themselves.
- This stage-aware approach could guide future tools to be both efficient and high-quality.
A practical note: the best switch points can depend on the specific video model, so they may need to be recalculated when you change models. In the future, automatic detection of those boundaries could make this even easier to use.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of specific gaps and unresolved questions that could guide future research:
- Boundary selection without ground-truth references: The proposed early/late boundaries are chosen using DINO similarity to LLL and FID curves, both requiring reference generations from the large model and many samples. How can we devise an online, per-sample boundary detector that does not require LLL outputs or large-scale batch statistics?
- Per-sample/prompt-adaptive scheduling: Boundaries are fixed per model family; there is no mechanism to adapt early/late cut points to prompt complexity, motion type, scene dynamics, or guidance scale at inference time.
- Theoretical explanation of divergence U-shape: The paper observes a U-shaped velocity divergence across timesteps, but provides no theoretical account. What generative or optimization principles explain this curve, and when should we expect deviations?
- Runtime-feasible divergence proxies: Velocity divergence is computed by running both models in parallel; this is impractical at inference. Can we design cheap proxies (e.g., latent statistics, uncertainty, score norm, curvature) that correlate with divergence to trigger capacity switches?
- Generalization across model families and architectures: Results are shown for two families (LTX-Video and WAN 2.1). Does the stage sensitivity and U-shape persist for other backbones (e.g., U-Nets, Rectified Flows, SDE-based samplers), proprietary models, or non-transformer video models?
- More-than-two-model regimes: Only two capacities (small/large) are explored (with one distilled variant). What is the optimal allocation strategy for three or more capacity tiers (e.g., S–M–L), or for mixing quantized/pruned variants?
- Soft vs. hard switching: The method uses hard, stage-wise model assignment. Would soft blending (e.g., timestep-dependent convex combinations of velocities, adaptive gating per block, layer-wise mixtures) offer better quality/compute trade-offs?
- Within-step or layer-wise mixing: Only step-level switching is explored. Can intra-step or layer-level routing (e.g., routing specific layers/heads to large model at certain timesteps) reduce cost further while maintaining fidelity?
- Robustness to solver choice and NFE: Compatibility is shown with one solver (DPM++) and limited NFE settings. How do boundaries and performance change across a wider solver spectrum (Heun/Euler/EDM solvers), extreme NFE reductions, and adaptive-step ODE solvers?
- Length and resolution scaling: The evaluation does not systematically study long videos (e.g., 64–256+ frames) or high resolutions (e.g., ≥720p/1080p). Do early/late boundaries shift with longer temporal horizons or higher spatial resolutions?
- Domain and motion diversity: The benchmarks may not cover challenging regimes (fast/complex motion, heavy occlusion, multi-shot compositions, cinematic camera moves). Are there prompt or scene classes where the intermediate stage is capacity-sensitive?
- Conditional/video-editing settings: The method targets text-to-video. How do findings transfer to image-to-video, video-to-video, pose-/depth-/optical-flow-conditioned generation, audio-conditional generation, or editing tasks where source content constrains structure?
- Guidance and conditioning strength: The effects of classifier-free guidance scale, negative prompts, and multi-condition guidance on boundary selection and divergence patterns are not analyzed.
- Temporal coherence metrics: Temporal quality is primarily assessed via VBench “Motion Smoothness” and FVD. More targeted temporal metrics (e.g., warping error, temporal LPIPS/SSIM, optical-flow consistency, flicker detectors) could better quantify late-stage refinement benefits.
- Statistical rigor and variance: Sample sizes are modest (284–355) with limited reporting of confidence intervals and significance tests. How stable are improvements across seeds, datasets, and broader prompt distributions?
- End-to-end system costs: FLOPs are reported mostly for DiT blocks; end-to-end latency, memory bandwidth, model-loading overhead, kernel warm-up, and CPU/GPU transfer costs from model switching are not comprehensively analyzed.
- Memory footprint and deployment constraints: Running both small and large models requires substantial memory. What are practical strategies for swapping, offloading, or pipeline parallelism to make FlowBlending feasible on memory-constrained devices?
- Reproducibility under RNG control: Switching models mid-trajectory may alter stochasticity. How to ensure determinism/reproducibility across seeds and solvers when interleaving models?
- Stability under extreme compute constraints: For ultra-low NFE (e.g., 4–8 steps), does stage-aware switching still hold, and how should boundaries be adapted?
- Dataset dependence of boundary heuristics: Early boundary selection via DINO-drop and late boundary via FID V-shape may be dataset/prompt-set specific. Can we formalize boundary selection that generalizes across distributions without re-tuning?
- Safety and content moderation: The approach focuses on fidelity/efficiency; impacts on safety, bias, and undesired-content rates when mixing capacities are not assessed.
- Claims of “added realism” from small-model mid-stages: The observed “more realistic textures” are anecdotal. Can this be verified with human studies or calibrated realism metrics (e.g., perceptual studies, user preference tests)?
- Interaction with adapters and personalization: It is unknown whether boundaries remain valid when adding LoRA/ControlNets, personalization weights, or domain adapters that change capacity needs.
- Mixing across unrelated model families: Small and large models are from the same family. What happens if the small model is from a different architecture/training distribution, or if we mix open-source and proprietary models?
- Task-specific objective functions: Boundary selection optimizes FID/VBench. For downstream tasks (storyboarding, layout adherence, identity preservation), are different boundaries or soft blending strategies preferable?
- Automated, model-agnostic boundary discovery: The paper notes that boundaries need re-estimation per model. Can we develop model-agnostic, unsupervised criteria to discover stage boundaries once and transfer them across models and tasks?
Practical Applications
Immediate Applications
The following items can be deployed now by leveraging FlowBlending’s stage-aware multi-model sampling (LSL schedule), boundary selection heuristics (DINO similarity and FID trade-offs), and compatibility with existing accelerators (e.g., DPM++). Each item notes sector associations, potential tools/workflows, and key assumptions/dependencies.
- Generative video platforms (software/media)
- Use case: Reduce inference cost and latency while maintaining large-model quality for text-to-video services.
- Tools/workflows: “FlowBlending Sampler” plugin for Diffusers/CFM stacks; capacity scheduler that runs large model in early/late stages and small model in intermediate steps; opt-in DPM++ solver for additional 2× speedups.
- Assumptions/dependencies: Access to aligned small/large variants (e.g., LTX-Video 2B/13B, WAN 1.3B/14B), shared latent spaces and conditioning, boundary calibration via DINO similarity (>~96%) and FID curves, model licenses.
- Creative studios and VFX (media/entertainment)
- Use case: Faster previews and final renders with maintained temporal coherence and fine detail; higher iteration velocity for storyboarding and shot exploration.
- Tools/workflows: LSL schedule baked into studio render pipelines; “Quality guardrails” that reintroduce large model in late stage when LPIPS/PSNR drift or artifact detectors trigger.
- Assumptions/dependencies: GPU availability for large-model passes, prompt consistency, pipeline integration with asset/version control.
- Advertising and marketing (commerce)
- Use case: Scalable personalized video ads at lower compute cost while preserving semantics and brand compliance.
- Tools/workflows: Multi-tenant “Capacity-aware ad generator” with per-campaign LSL presets; automatic boundary tuning on representative prompts.
- Assumptions/dependencies: Content QA processes, prompt standardization, privacy policies for user data.
- Social and mobile apps (consumer/daily life)
- Use case: Faster and more battery-efficient on-device video generation; hybrid edge/cloud inference with small model locally and early/late passes in cloud.
- Tools/workflows: “Hybrid Cloud-Edge Orchestrator” that routes early/late steps to cloud GPUs and keeps intermediate steps on device NPUs.
- Assumptions/dependencies: Stable network connectivity, privacy controls for offloaded stages, consistent quantization across devices.
- Game studios (gaming)
- Use case: Rapid prototyping of animated assets and cutscenes with coherent motion and refined textures; more iterations per sprint.
- Tools/workflows: Unreal/Unity integrations of FlowBlending; batch generators with LSL presets for concept development.
- Assumptions/dependencies: Domain-specific prompt libraries, validation against engine constraints.
- Education and training (education)
- Use case: Efficient generation of explainer animations and course materials without sacrificing semantic alignment.
- Tools/workflows: “Classroom content generator” with LSL default; auto-boundary calibration on curriculum prompt sets.
- Assumptions/dependencies: Institutional approval, age-appropriate content safeguards.
- Robotics and simulation data generation (robotics)
- Use case: Faster synthesis of training videos that preserve motion coherence and object identity for perception model pretraining.
- Tools/workflows: “SimGen pipeline” that produces varied, temporally consistent clips via LSL sampling; integrated dataset curation.
- Assumptions/dependencies: Domain realism checks, task-specific evaluation (e.g., tracking, action recognition).
- Academic research (academia)
- Use case: Reduce experiment runtime and FLOPs for video generative model studies; apply velocity divergence as a proxy to choose stage boundaries.
- Tools/workflows: “Velocity Divergence Monitor” for U-shaped divergence tracking; “AutoBoundary Finder” that targets the similarity-drop point and late-stage FID minimum.
- Assumptions/dependencies: Availability of evaluation metrics (DINO/CLIP similarity, FID/FVD), reproducible sampling setups.
- Data center operations and sustainability (policy/operations)
- Use case: Lower GPU energy consumption and carbon footprint for video generation workloads.
- Tools/workflows: “GreenOps dashboard” reporting FLOPs savings and emissions reductions from LSL vs LLL; policy-compliant ops playbooks.
- Assumptions/dependencies: Emissions measurement or estimation, organizational buy-in for efficiency policies.
Long-Term Applications
These opportunities require additional research, scaling, or development—particularly automatic, model-agnostic boundary detection, broader modality generalization, and robust systems-level orchestration.
- Adaptive, per-prompt capacity control (software)
- Use case: Dynamic stage boundaries selected online via real-time velocity-divergence and artifact signals; content-aware scheduling for difficult prompts.
- Tools/workflows: “Adaptive Capacity Controller” microservice that tunes L/S allocation on the fly.
- Assumptions/dependencies: Reliable online divergence estimates, robust artifact detectors, low-overhead monitoring.
- Model-agnostic boundary discovery and auto-calibration (software/academia)
- Use case: Zero-shot FlowBlending across new or proprietary models without manual tuning.
- Tools/workflows: Boundary search using divergence, variance onset, and similarity thresholds; meta-learning of boundary policies.
- Assumptions/dependencies: Consistent access to velocity fields; generalizable heuristics across architectures and training regimes.
- Multi-model ensembles beyond capacity (media/creative tools)
- Use case: Stage-aware mixing with specialized models (e.g., stylization mid-trajectory, artifact-suppression late-stage, domain-specific small models).
- Tools/workflows: “StageMixer SDK” for modular per-stage backbones and style/adaptation passes.
- Assumptions/dependencies: Cross-model latent compatibility, harmonized conditioning interfaces, licensing.
- Cross-modality generalization (image, audio, 3D, simulation)
- Use case: Apply stage-aware mixing to other generative modalities (image diffusion, audio synthesis, 3D scene/video, physics-based simulation).
- Tools/workflows: Unified “Stage-aware Sampler” abstraction for diffusion/flow-matching across modalities.
- Assumptions/dependencies: Evidence of stage sensitivity in target modalities; suitable divergence proxies (e.g., score/velocity variants).
- Carbon-aware orchestration and scheduling (policy/infrastructure)
- Use case: Run large-capacity stages at low-carbon times or on greener regions; meet SLOs with cost/emissions constraints.
- Tools/workflows: “GreenGen Orchestrator” integrating carbon-intensity signals, workload SLOs, and capacity-aware sampling policies.
- Assumptions/dependencies: Accurate carbon telemetry, multi-region scheduling capabilities, organizational policy alignment.
- Full on-device generation via distillation and hardware co-design (mobile/edge)
- Use case: Remove cloud dependency by deploying distilled large-stage models on NPUs for early/late steps.
- Tools/workflows: Progressive distillation pipelines; hardware-aware quantization and memory optimization for large-stage passes.
- Assumptions/dependencies: Edge hardware capability, distillation quality parity, thermal/battery constraints.
- Safety, watermarking, and authenticity (policy/security)
- Use case: Ensure stage-aware sampling maintains watermark robustness and provenance; develop post-hoc authenticity passes.
- Tools/workflows: Watermark-preserving late-stage refinement; authenticity verification APIs.
- Assumptions/dependencies: Watermarking schemes resilient to mixed-capacity trajectories, regulatory acceptance.
- Healthcare and telemedicine content generation (healthcare)
- Use case: Synthetic training and patient education videos with strong semantic alignment and refined detail.
- Tools/workflows: Clinically validated LSL pipelines with domain-specific prompts and QA; privacy-first orchestration.
- Assumptions/dependencies: Clinical validation, regulatory compliance, bias/safety audits.
- Interactive education and co-creation (education)
- Use case: Real-time iterative video creation in classrooms; adaptive capacity control to keep latency low without losing clarity.
- Tools/workflows: Live authoring tools with stage-aware scheduling and immediate artifact clean-up passes.
- Assumptions/dependencies: UI/UX maturity, classroom device performance, content moderation.
- SaaS pricing and policy frameworks for efficiency (policy/finance)
- Use case: “Green tier” pricing and procurement guidelines that reward stage-aware sampling and report FLOPs/emissions.
- Tools/workflows: Efficiency reporting standards; contractual SLAs tying cost to measured savings.
- Assumptions/dependencies: Industry consensus on metrics, third-party verification, customer adoption.
In all cases, feasibility depends on having compatible large/small model variants, the ability to switch models mid-trajectory without breaking conditioning or latent alignment, and reliable boundary detection (via DINO/CLIP similarity, FID-based trade-offs, and velocity-divergence U-shape analysis). Integrations with sampling-step reduction (e.g., DPM++) and distilled backbones further amplify benefits but may require model-specific calibration and QA to preserve perceptual quality and semantics.
Glossary
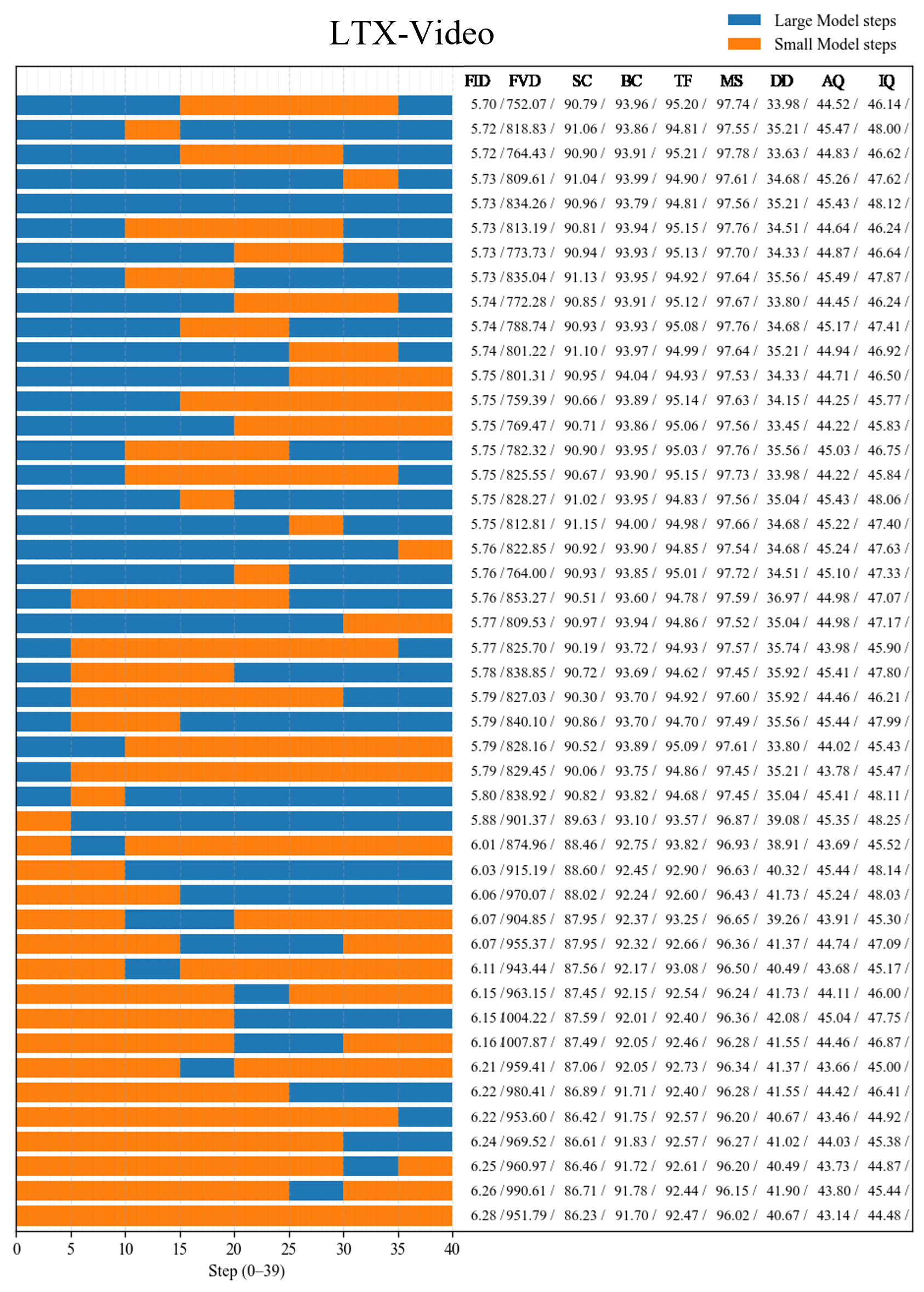
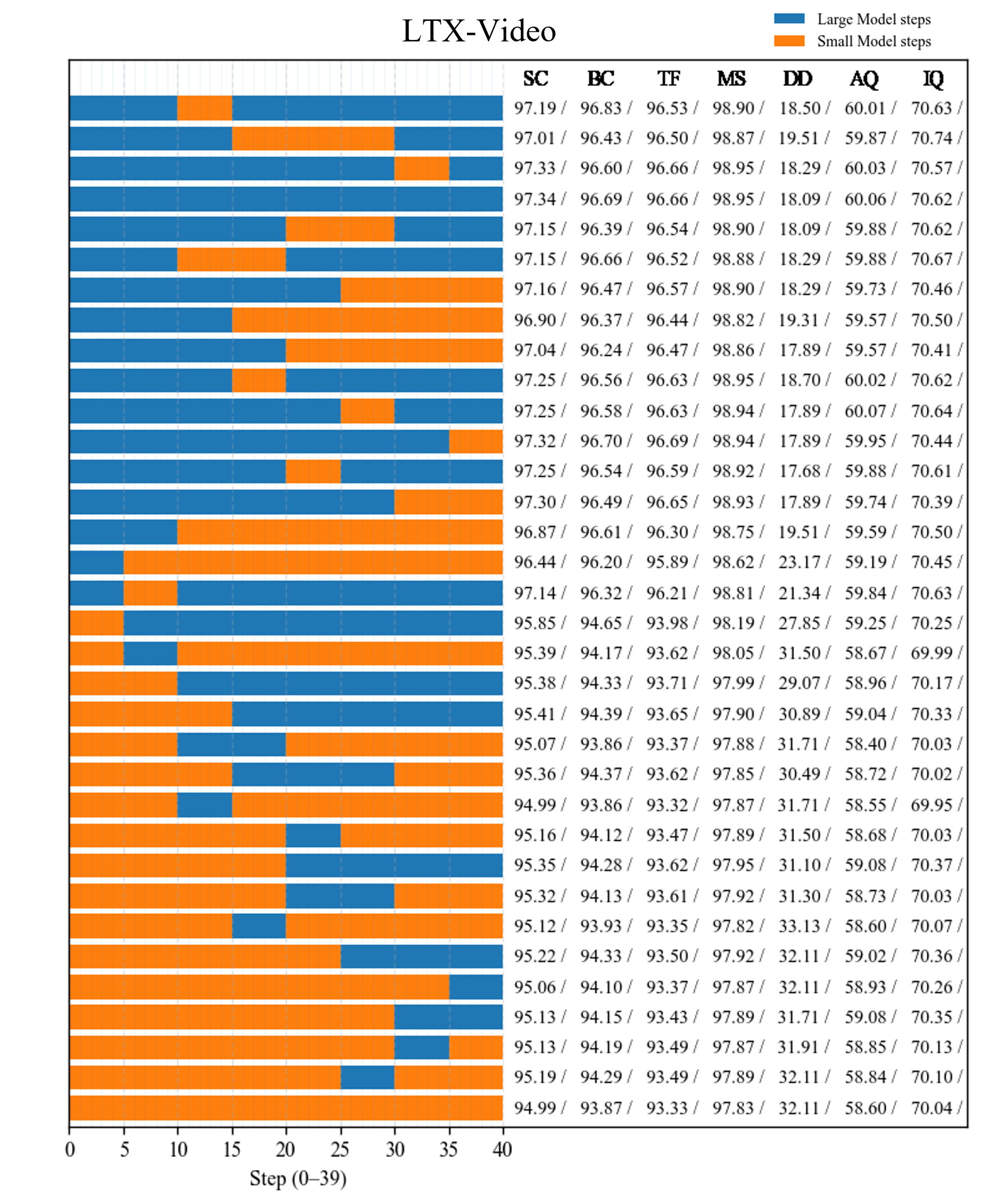
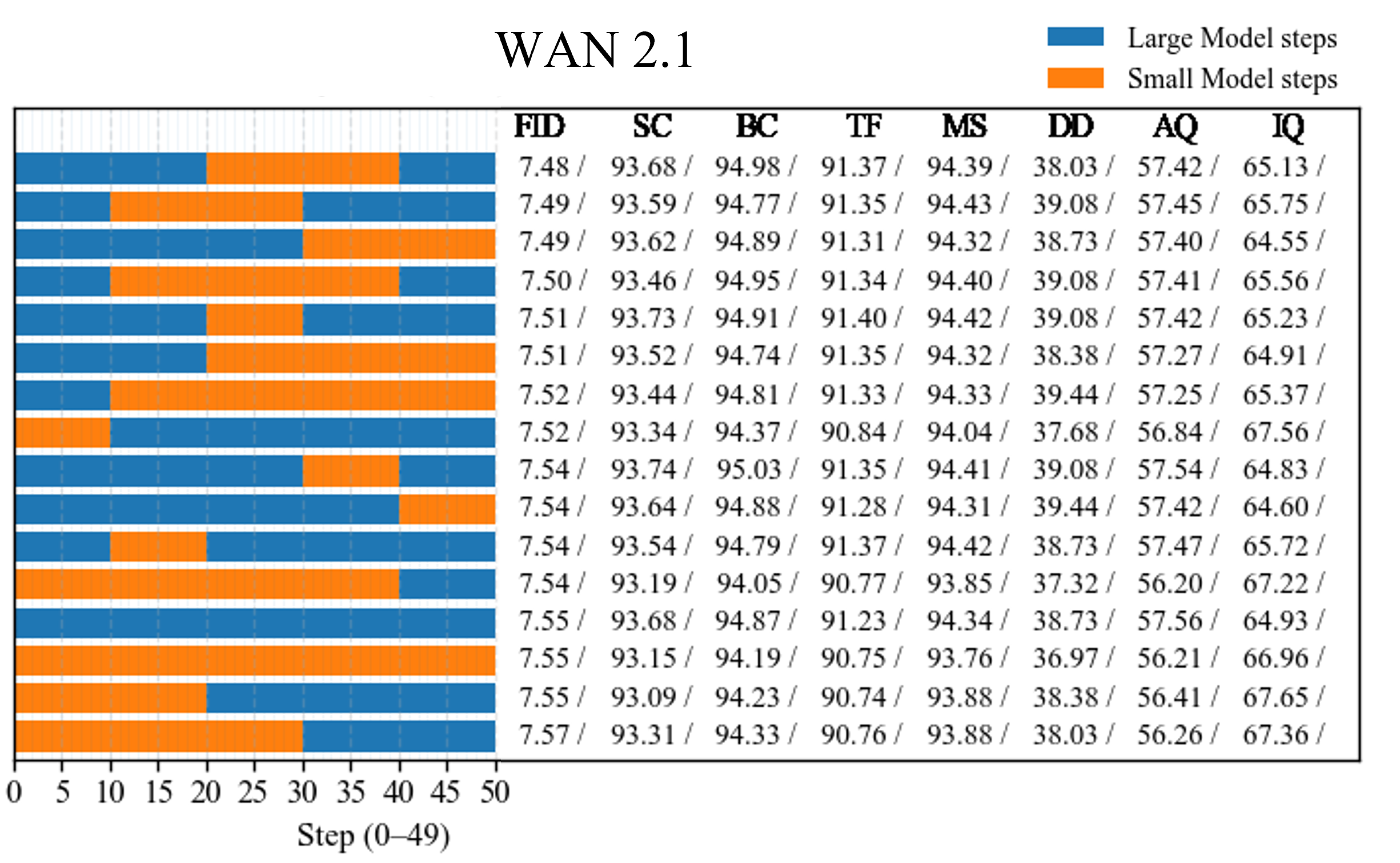
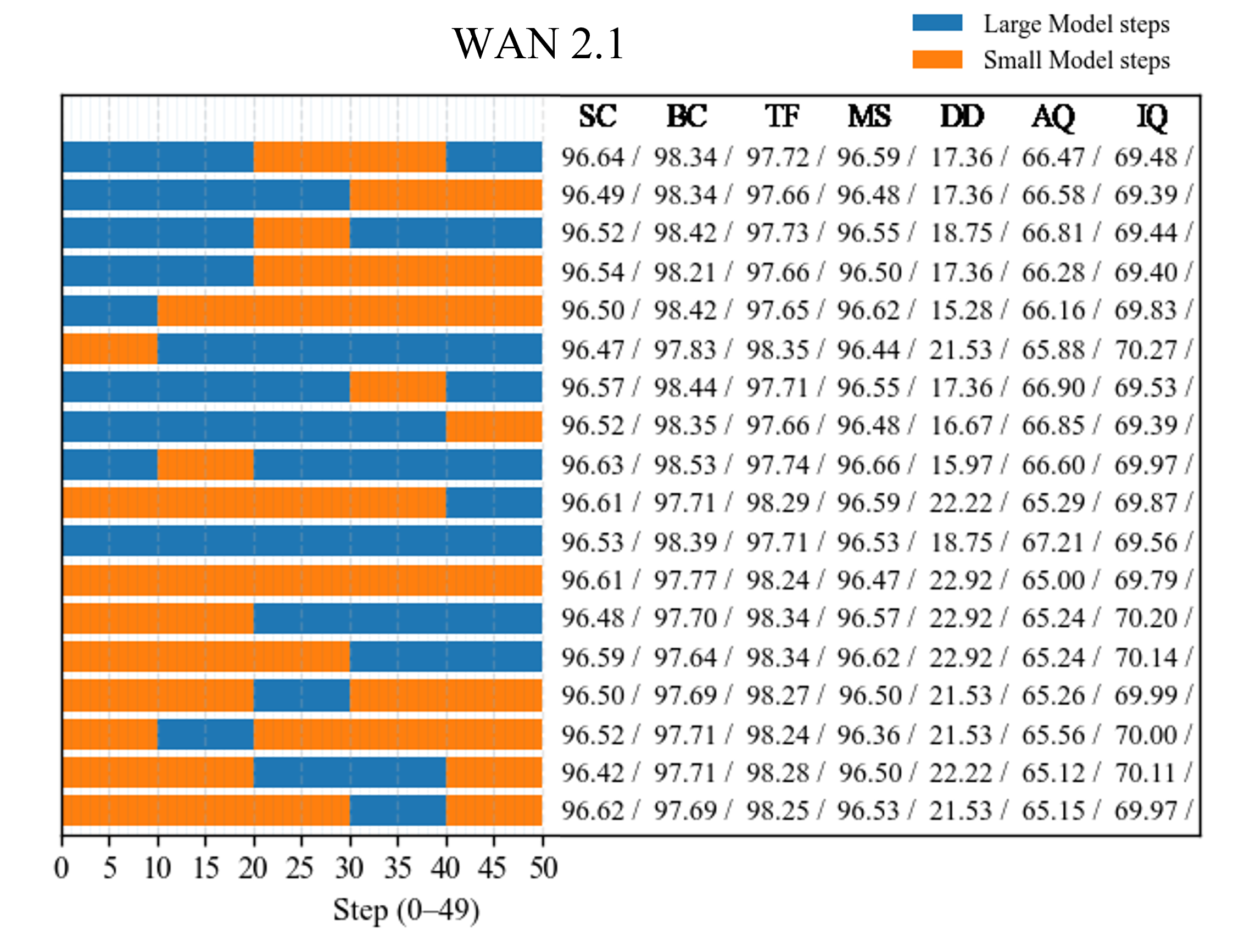
- Aesthetic Quality: A VBench metric assessing the visual appeal of generated videos. "We report FID and FVD using 284 generated samples, and four VBench metrics, Aesthetic Quality, Background Consistency, Subject Consistency, and Motion Smoothness, using 355 generated samples."
- Background Consistency: A VBench metric measuring consistency of backgrounds across video frames. "We report FID and FVD using 284 generated samples, and four VBench metrics, Aesthetic Quality, Background Consistency, Subject Consistency, and Motion Smoothness, using 355 generated samples."
- CLIP: A contrastive vision–LLM used to compute semantic similarity via embeddings. "we measure the similarity between each sampling schedule and the large-only baseline (LLL) using four metrics: (i) DINO and CLIP image-embedding similarity for semantic consistency, and (ii) LPIPS and PSNR for low-level similarity, averaged across all frames and 355 generated videos."
- Conditional flow matching (CFM): A training formulation for flow matching that conditions on endpoints to learn a velocity field. "According to conditional flow matching (CFM), an intermediate latent is formed at each timestep and the network is trained using the optimal transport CFM (OT-CFM) loss:"
- DINO: A self-supervised vision model whose embeddings are used to measure semantic similarity. "we measure the similarity between each sampling schedule and the large-only baseline (LLL) using four metrics: (i) DINO and CLIP image-embedding similarity for semantic consistency, and (ii) LPIPS and PSNR for low-level similarity, averaged across all frames and 355 generated videos."
- DiT blocks: Diffusion Transformer blocks; core compute units in transformer-based diffusion backbones. "To quantify computational efficiency, we report the runtime and FLOPs of DiT blocks per generated video."
- DPM++: A family of improved diffusion ODE solvers that reduce sampling steps without retraining. "DPM++ accelerates the denoising process by reducing the number of function evaluations (NFE)."
- FID: Fréchet Inception Distance; a distributional metric for generative quality. "We report FID and FVD using 284 generated samples, and four VBench metrics, Aesthetic Quality, Background Consistency, Subject Consistency, and Motion Smoothness, using 355 generated samples."
- FLOPs: Floating-point operations; a measure of computational cost. "allowing up to an additional 50\% FLOPs reduction"
- Flow matching: A generative modeling framework that learns a velocity field to transport a source distribution to a target distribution. "flow matching has emerged as a widely adopted framework for modern generative modeling"
- FlowBlending: The paper’s stage-aware multi-model sampling method that switches model capacity across denoising stages. "we propose FlowBlending, a stage-aware multi-model sampling strategy"
- FVD: Fréchet Video Distance; a distributional metric tailored to video quality. "We report FID and FVD using 284 generated samples, and four VBench metrics, Aesthetic Quality, Background Consistency, Subject Consistency, and Motion Smoothness, using 355 generated samples."
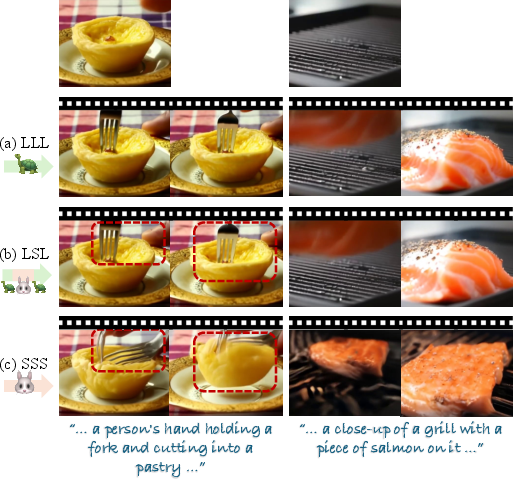
- High-frequency details: Fine textures and edges that are refined in the late denoising stage. "the late denoising stage refines high-frequency details and remove artifacts"
- LPIPS: Learned Perceptual Image Patch Similarity; a perceptual distance metric. "and (ii) LPIPS and PSNR for low-level similarity, averaged across all frames and 355 generated videos."
- LTX-Video: An open-source text-to-video diffusion model available in multiple parameter scales. "We evaluate the proposed sampling schedule on two representative open-source video diffusion models: LTX-Video (2B / 13B) and WAN 2.1 (1.3B / 14B)."
- Motion Smoothness: A VBench metric evaluating temporal smoothness of motion in generated videos. "We report FID and FVD using 284 generated samples, and four VBench metrics, Aesthetic Quality, Background Consistency, Subject Consistency, and Motion Smoothness, using 355 generated samples."
- Number of function evaluations (NFE): The number of solver steps (model evaluations) used during sampling. "by solving ordinary differential equation (ODE) with the number of function evaluations (NFE) where flow step ."
- Optimal transport CFM (OT-CFM): A CFM objective that uses an optimal transport coupling between endpoints. "the optimal transport CFM (OT-CFM) loss:"
- Ordinary differential equation (ODE): The deterministic dynamical system solved during flow-based sampling. "by solving ordinary differential equation (ODE) with the number of function evaluations (NFE) where flow step ."
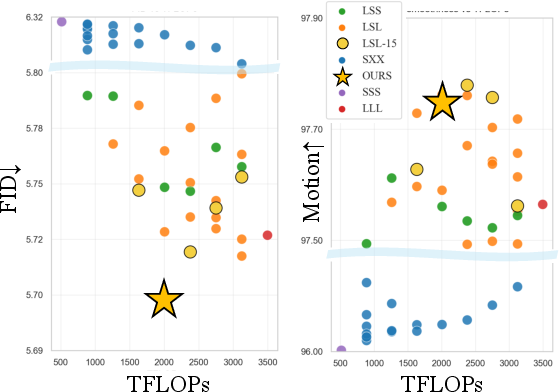
- Pareto frontier: The set of optimal trade-offs where improving one objective worsens another (e.g., quality vs. compute). "lie on the Pareto frontier, achieving LLL-level quality with lower FLOPs."
- PSNR: Peak Signal-to-Noise Ratio; a traditional signal fidelity metric. "and (ii) LPIPS and PSNR for low-level similarity, averaged across all frames and 355 generated videos."
- PVD: A video evaluation benchmark used for perceptual quality assessment. "Evaluations are conducted on the PVD and VBench."
- Semantic alignment: The degree to which generated content matches the input text prompt. "while maintaining the visual fidelity, temporal coherence, and semantic alignment of the large models."
- Stage-aware multi-model sampling: A strategy that allocates different model sizes to different denoising stages based on capacity sensitivity. "we propose FlowBlending, a stage-aware multi-model sampling strategy"
- Step distillation: A technique that compresses multi-step diffusion sampling into fewer steps via training. "Another major direction focuses on step distillation"
- Subject Consistency: A VBench metric measuring how consistently the main subject is preserved over time. "We report FID and FVD using 284 generated samples, and four VBench metrics, Aesthetic Quality, Background Consistency, Subject Consistency, and Motion Smoothness, using 355 generated samples."
- Temporal coherence: Temporal stability and consistency across video frames. "while maintaining the visual fidelity, temporal coherence, and semantic alignment of the large models."
- U-shaped pattern: A characteristic shape observed in divergence curves across timesteps. "the divergence curve consistently follows a U-shaped pattern across the sampling process."
- VBench: A benchmark suite for evaluating multiple quality aspects of generated videos. "Evaluations are conducted on the PVD and VBench."
- Velocity divergence: A measure of difference between velocity predictions of models (e.g., large vs. small). "we provide extensive experiments together with a velocity divergence analysis"
- Velocity field: The vector field that defines transport dynamics from noise to data in flow matching. "by learning a velocity field with a neural network ."
- WAN 2.1: A large-scale text-to-video diffusion model family with small and large variants. "We evaluate the proposed sampling schedule on two representative open-source video diffusion models: LTX-Video (2B / 13B) and WAN 2.1 (1.3B / 14B)."
Collections
Sign up for free to add this paper to one or more collections.