- The paper introduces a novel, fully autonomous AI workflow that translates legacy Fortran kernels into portable Kokkos C++ code with minimal human intervention.
- It utilizes a multi-agent system where each agent handles translation, validation, optimization, and error correction while leveraging hardware profiler feedback.
- Performance evaluation on NAS benchmarks shows that optimized Kokkos code achieves near-equivalent or superior performance to Fortran baselines across diverse HPC architectures.
Autonomous Agentic AI Workflow for Fortran-to-Kokkos Modernization
Introduction
The paper presents a fully autonomous agentic AI workflow for translating legacy Fortran kernels into performance-portable Kokkos C++ programs. The motivation stems from the persistent reliance on Fortran in scientific computing and the lack of native Fortran bindings for modern GPU-accelerated architectures. Manual porting to frameworks like Kokkos is labor-intensive and requires deep expertise in both C++ and parallel programming. The proposed workflow leverages specialized LLM agents to automate translation, validation, compilation, execution, functionality testing, and iterative optimization, targeting high-performance and portability across heterogeneous hardware.
Agentic AI Workflow Architecture
The workflow is structured as a multi-agent system, where each agent is responsible for a specific stage in the modernization pipeline. The agents operate sequentially, passing intermediate outputs and diagnostic feedback to subsequent agents. The orchestration logic enforces configurable thresholds for agent invocations at each stage, ensuring robustness and bounded iteration.
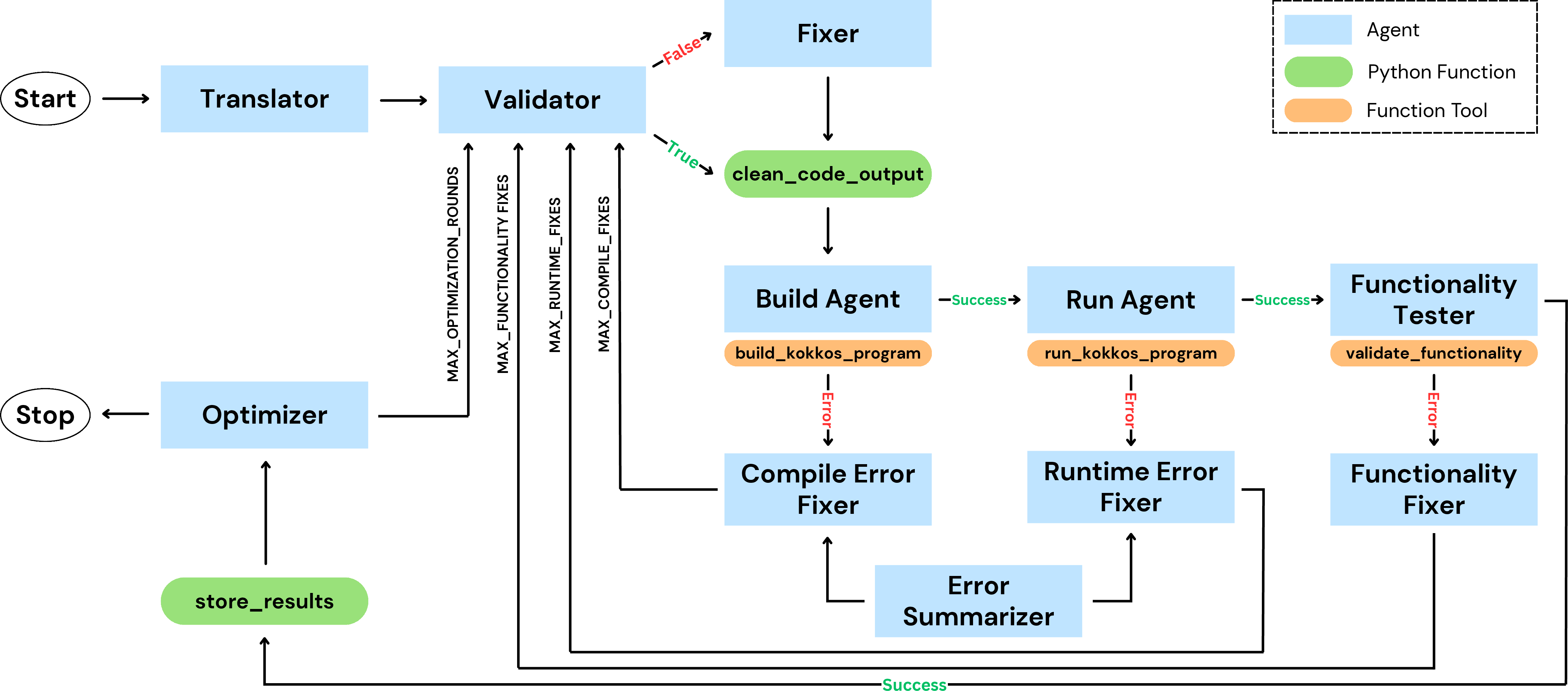
Figure 1: Agentic AI workflow for autonomous Fortran-to-Kokkos translation, validation, compilation, runtime execution, functionality testing, and performance optimization.
Agent Roles and Interactions
- Translator Agent: Converts Fortran kernels to Kokkos C++ code, preserving computational semantics and ensuring backend portability.
- Validator Agent: Ensures syntactic correctness and removes non-code artifacts.
- Fixer Agents: Triggered on error events (compilation, runtime, or functionality failures), applying targeted corrections based on diagnostic summaries.
- Build and Run Agents: Manage compilation and execution via SLURM, leveraging Spack for environment consistency.
- Functionality Tester: Injects kernel-specific testing code, compares outputs against Fortran baselines, and validates correctness.
- Optimizer Agent: Incorporates hardware profiler feedback (e.g., NVIDIA Nsight Compute, AMD ROCProfiler) to guide structural code optimizations.
All artifacts, metrics, and agent interaction metadata are versioned and stored per run, enabling reproducibility and post-analysis.
Benchmark Kernels and Evaluation
The workflow was evaluated on modularized Fortran kernels from the NAS Parallel Benchmarks (CG, EP, MG, FT) and OpenBLAS (DGEMM). Each kernel was selected for its parallel complexity and representative computational patterns (memory-bound, compute-bound, hierarchical, and global communication). The translation and optimization pipeline was tested across multiple hardware partitions (AMD MI250, NVIDIA A100, NVIDIA GH200) and LLMs (OpenAI GPT-5, o4-mini-high, Meta Llama4-Maverick).
Experimental Setup
- Hardware: GPU-accelerated HPC nodes with diverse architectures.
- Software: Spack-managed environments, SLURM for job scheduling, OpenAI Agents SDK for agent orchestration.
- LLM Inference: Proprietary models accessed via OpenAI API; open-source models served locally via Ollama and LiteLLM.
- Runtime Configuration: Input sizes and kernel repetitions scaled to normalize job runtimes; optimization rounds capped at five per kernel.
Results
Pipeline Reliability and Cost
Proprietary LLMs (GPT-5, o4-mini-high) consistently executed the full pipeline across all kernels and hardware partitions, producing functionally correct and performance-portable Kokkos codes. Open-source Llama4-Maverick frequently failed to complete the workflow, often exceeding maximum fix thresholds.
- Agent Invocations: GPT-5 and o4-mini-high required variable numbers of build, run, and functionality tester invocations, reflecting non-deterministic optimization strategies.
- Token Costs: Full translation and optimization of benchmark kernels incurred only a few U.S. dollars in API costs, demonstrating economic feasibility.
- Optimization Trajectories: Successive optimization rounds yielded measurable improvements in GFLOPS for compute-bound kernels. However, the best-performing version was not always the final one, highlighting the stochastic nature of LLM-guided optimization.
- Runtime Comparison: Kokkos translations outperformed Fortran baselines on both CPU and GPU backends. The most optimized versions generated by GPT-5 and o4-mini-high achieved near-equivalent performance, while Llama4-Maverick lagged significantly.
- Roofline Analysis: Compute-bound kernels (EP, DGEMM) achieved up to 52% of peak hardware performance on NVIDIA A100, while memory-bound kernels remained below 10%. This gap underscores the challenge of automating memory hierarchy optimizations.
Implementation Considerations
- Agentic Orchestration: Modular, asynchronous execution with version tracking and bounded fix attempts ensures robustness and reproducibility.
- Profiler Integration: Hardware profiler feedback is parsed and summarized for the Optimizer Agent, enabling targeted code restructuring (memory layout, loop ordering, execution policies).
- Functionality Testing: Kernel-specific output comparison is automated, but generalization to larger applications requires dynamic test generation.
- LLM Selection: Proprietary models currently outperform open-source alternatives in reliability and optimization efficacy. Model size and training data diversity are likely contributing factors.
Implications and Future Directions
The demonstrated workflow establishes agentic AI as a viable paradigm for autonomous code modernization in HPC. The ability to translate and optimize legacy Fortran kernels into portable Kokkos C++ programs with minimal human intervention has significant implications:
- Practical Impact: Reduces expertise, time, and cost barriers for scientific code modernization, accelerating adaptation to evolving supercomputing architectures.
- Theoretical Advancement: Validates the efficacy of structured, multi-agent LLM workflows for domain-specific reasoning and tool-driven automation.
- Open Challenges: Generalizing functionality testing, enhancing memory-bound kernel optimization, and exploring heterogeneous agent assignments (specialized LLMs per agent role) are promising avenues for future research.
Conclusion
The agentic AI workflow presented in this paper autonomously modernizes legacy Fortran kernels into high-performance, portable Kokkos C++ programs. Proprietary LLMs reliably execute the full pipeline, achieving substantial fractions of peak hardware performance for compute-bound kernels and outperforming Fortran baselines. The approach is both computationally and economically practical, requiring only a few hours and minimal cost per kernel. Open-source LLMs remain less capable, indicating a need for further development. Future work should focus on generalizing functionality testing, refining optimization strategies, and leveraging heterogeneous LLMs to further enhance workflow effectiveness and scalability.

