- The paper introduces diffusion models, Dream-VL and Dream-VLA, that overcome limitations of autoregressive approaches in complex visual planning and robotic control.
- The paper demonstrates that Dream-VL achieves state-of-the-art results on benchmarks like LIBERO and ViPlan through iterative refinement and bidirectional feature integration.
- The paper shows that Dream-VLA attains superior convergence and robust action generation by leveraging continuous pre-training on large-scale robotic datasets.
Dream-VL & Dream-VLA: Open Vision-Language and Vision-Language-Action Models with Diffusion LLM Backbone
Introduction
The paper "Dream-VL & Dream-VLA: Open Vision-Language and Vision-Language-Action Models with Diffusion LLM Backbone" (2512.22615) introduces a novel approach to vision-language modeling using diffusion-based architectures. Traditionally, autoregressive Large Vision-LLMs (VLMs) have dominated the field, achieving significant success across various benchmarks. However, these models often encounter limitations when applied to tasks involving complex visual planning and dynamic robotic control due to their sequential generation process. To address this, the authors propose Dream-VL, a diffusion-based VLM designed to overcome the inherent constraints of autoregressive models, and Dream-VLA, an advanced Vision-Language-Action (VLA) model developed through continuous pre-training on large-scale robotic datasets.
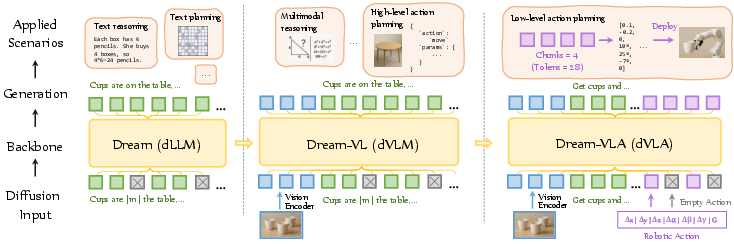
Figure 1: Overview of the Dream family, illustrating the diffusion LLM Dream-7B and the derived state-of-the-art diffusion VLM and VLA models.
Diffusion-Based Approach
Diffusion LLMs (dLLMs) approach generation differently compared to autoregressive models, utilizing iterative refinement of noisy sequences to produce coherent outputs. This method naturally supports global coherence and is particularly beneficial for tasks requiring long-range planning and goal-oriented reasoning. Additionally, diffusion models inherently enable parallel decoding, which can accelerate inference processes.
Building on these principles, Dream-VL achieves competitive performance with top autoregressive VLMs, demonstrating enhanced capabilities in visual planning tasks. The bidirectional nature of diffusion models facilitates richer multimodal feature integration, aiding not only in traditional visual understanding but also in tasks demanding complex planning. This advantage is evidenced in Dream-VL's application across diverse benchmarks.

Figure 2: The schematics of high-level and low-level planning processes required for effective long-horizon robotics tasks.
Vision-Language-Action Model Development
The development of Dream-VLA, built upon Dream-VL, transitions into the field of VLA modeling, extending diffusion models to include action generation capabilities. This shift is supported by a comprehensive pre-training regime using open robotic datasets, leveraging the bidirectional nature of diffusion models for efficient action chunking and parallel generation. Dream-VLA attains superior convergence rates during downstream fine-tuning, showcasing significant improvements in various robotic manipulation tasks.
Dream-VLA demonstrates robust performance across established benchmarks such as LIBERO and SimplerEnv, surpassing existing models like GR00T-N1 and OpenVLA-OFT. The advantages offered by the diffusion backbone are further illustrated by the model's exceptional average success rates across different tasks, emphasizing the potential of diffusion-based models for action-centric applications.
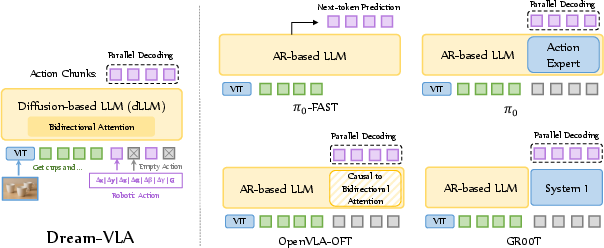
Figure 3: The architecture comparison, highlighting structural differences across various VLA models.
Experimental Results
Comprehensive evaluations reveal that Dream-VL and Dream-VLA achieve state-of-the-art results among diffusion-based models. Dream-VL's advantages are particularly pronounced in visual planning benchmarks such as LIBERO and ViPlan, where it consistently outperforms autoregressive models in scenarios demanding intricate planning. Additionally, Dream-VLA's robust action prediction capabilities are showcased through its efficient handling of long-horizon tasks, maintaining accuracy and speed even with increased action chunk sizes.
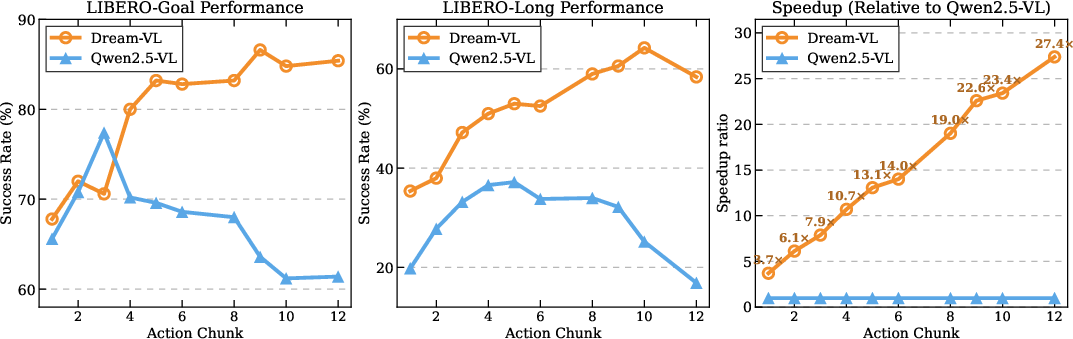
Figure 4: Examination of performance metrics and computational efficacy with varying action chunk sizes.
Implications and Future Directions
The introduction of Dream-VL and Dream-VLA marks a significant stride in advancing the capabilities of diffusion-based vision-LLMs. By addressing the limitations of autoregressive architectures, diffusion models offer promising avenues for enhancing both theoretical and practical applications within AI, particularly in autonomous systems and robotic manipulation.
Future research could explore optimizing training datasets and strategies, exploring joint improvements for high-level planning and precise low-level control, and expanding real-world evaluations to further validate scalability and application flexibility. Additionally, investigating continuous action space modeling over diffusion VLM backbones could refine the discrete-to-continuous action transition, enhancing the comprehensive model adaptability across diverse robotic domains.
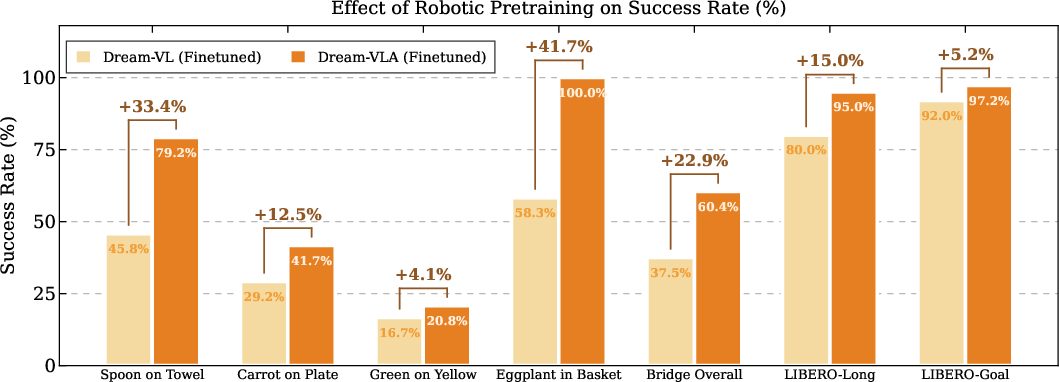
Figure 5: Visualizing the impact of robotic pretraining on task performance across varied domains.
Conclusion
The research presented in "Dream-VL & Dream-VLA: Open Vision-Language and Vision-Language-Action Models with Diffusion LLM Backbone" paves the way for innovative explorations in diffusion-based AI models. Through rigorous evaluation, the paper establishes clear performance enhancements over conventional models, setting a new benchmark in vision-language-action modeling, particularly for complex planning tasks. As the field progresses, diffusion models could further redefine the landscape of AI-driven solutions in robotics and beyond.