- The paper reveals that frozen attention components can model sequences competitively by forming induction heads in tasks like language modeling.
- It introduces transformer variants such as Frozen-QK, Frozen-MLP, and MixiT to isolate the roles of trainable parameters in performance.
- Experimental results demonstrate that even randomized attention supports complex tasks, challenging the need for adaptive attention weights.
The paper investigates the necessity of trainable components within the transformer architecture, particularly focusing on the self-attention mechanism. It explores alternate configurations by freezing portions of the architecture and assesses their performance across various tasks. Key findings demonstrate that frozen attention components can still effectively model sequences, challenging the established view that trainable attention weights are crucial for transformers’ success.
The study introduces several variants of the Llama Transformer model—Frozen-QK, Frozen-MLP, and MixiT—each altering different aspects of the trainable components to isolate their contributions to sequence modeling tasks.
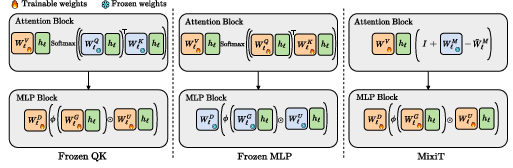
Figure 1: Variants of the Llama Transformer model that we study.
Frozen-QK Model
This variant retains the typical transformer structure but with fixed query and key weights. Despite the fixed attention components, Frozen-QK forms induction heads and achieves competitive performance on tasks that require contextual reasoning, such as language modeling.
Frozen-MLP and MixiT Models
Frozen-MLP freezes the weights of the MLP layers within the transformer, and MixiT employs random static attention scores that are input-independent post-initialization. MixiT reveals that even completely randomized attention can support a wide range of tasks by leveraging the learned token embeddings and MLP blocks.
Analytical Results and Theoretical Insights
Expressivity and Capability
Despite the static nature of its attention weights, Frozen-QK can approximate a wide variety of sequence-level functions, suggesting the robustness of transformers in forming specialized computational circuits without adaptive attention patterns.
Covariance and Stability
The paper provides an analysis of covariance in hidden representations, indicating the stability of signal propagation in MixiT despite its random attention configuration due to its variance-preserving normalization.
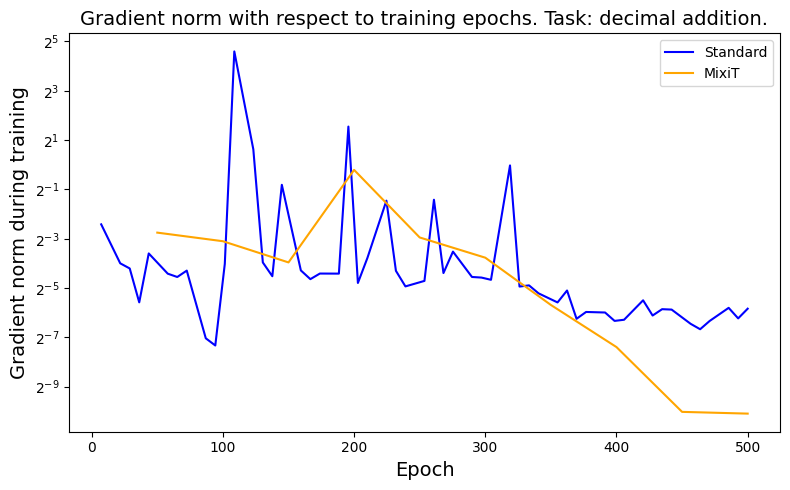
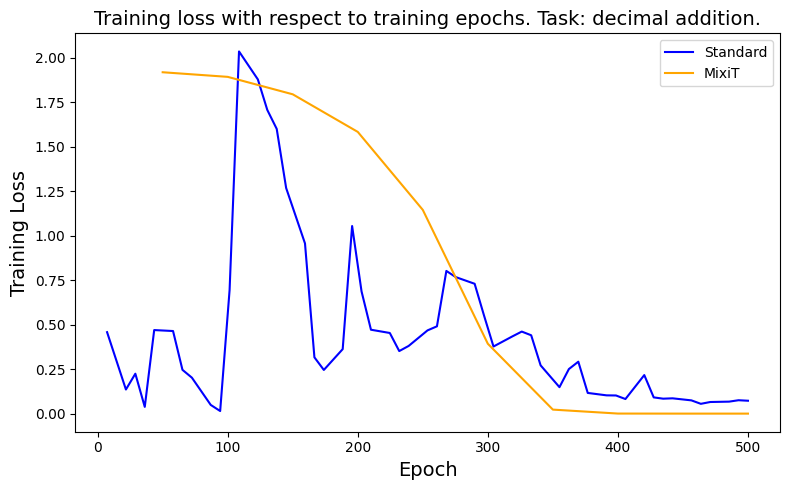
Figure 2: Grad norm.
Experimental Findings
Surprisingly, Frozen-QK closely matches the standard transformer in language modeling tasks, as measured by log perplexity scores. Despite randomized attention weights, it effectively forms induction heads, fundamental for context-dependent reasoning in LLMs.
Algorithmic Task Competence
MixiT demonstrates high proficiency in algorithmic tasks such as modular addition and parentheses balancing, suggesting that learned attention scores are not imperative for basic computation and memorization tasks.
Memorization and Collaboration of Components
Attention and MLPs contribute together to memorization capabilities. Frozen-MLP underperforms compared to other configurations, highlighting the collaborative role of trainable attention in enhancing memorization beyond mere parameter count increases.
Model Training Considerations
The paper outlines optimized hyperparameter configurations for each model variant across different tasks, revealing critical differences in training dynamics and throughput improvements, particularly when training time is a constraint.
Discussion on Implications
The research underscores the potential of non-trainable components in transformer architectures, pointing towards efficient architectural designs with reduced computational overhead. These findings advocate for reconsidering the necessity of adaptive attention in transformers for specific tasks.
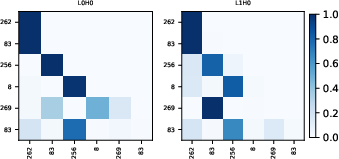
Figure 3: The Frozen-QK model can solve the retrieval task by forming an induction head. In the first head, each token attends to the previous one; in particular, the query token 83 is attended by 256. In the head of the second layer, the correct token 256 is retrieved.
Conclusion
This investigation demonstrates the surprising capability of random and frozen components in transformer models to perform sequence modeling tasks, questioning traditional beliefs about the indispensability of trainable attention mechanisms. Future work could explore the extension of these findings to more complex reasoning tasks and the implications for designing efficient transformer architectures.
These insights could drive innovative directions in transformer research, focusing on simplifying components while maintaining robust performance in sequence modeling applications.

