- The paper introduces a PDE framework for deep Transformers, unifying various self-attention mechanisms through a Vlasov equation model.
- It establishes global well-posedness using fixed-point arguments and derives ODEs that explain Gaussian data evolution and token clustering.
- Numerical experiments validate the approach, highlighting differences between attention types and low-rank covariance behavior in high dimensions.
Introduction
The study of Transformer architectures is pivotal in understanding their capacity to process data efficiently across various tasks in machine learning. The paper explores the intricate dynamics of tokens as they propagate through Transformer layers by framing this process in terms of a partial differential equation (PDE), remarkably a Vlasov equation. This approach not only extends existing analyses but also unifies multiple self-attention variants under a single theoretical framework.
Well-Posedness for Compactly Supported Initial Data
The analysis establishes the well-posedness of the Transformer PDE for a variety of self-attention mechanisms when initiated with compactly supported data. These include Softmax, L2, Sinkhorn, Sigmoid, and multi-head attentions. The stability estimates were derived, showcasing the dependence on initial conditions, and reflect the likelihood of measuring convergence in practice. Key to this theory is the use of a fixed-point argument to establish the global existence and uniqueness of solutions to the PDE, ensuring that well-posed dynamics correspond to stable evolutions of token representations.
Dynamics for Gaussian Initial Data
For Gaussian initial data, which retains its Gaussian nature under this PDE dynamics, explicit ordinary differential equations (ODEs) for expectation and covariance matrices are deduced. This provides insight into the evolving anisotropy of data as it traverses Transformer layers. The Gaussian case enables reduced complexity and elucidation of clustering phenomena akin to discrete token interactions observed empirically.
- A prominent finding under certain matrix assumptions is that limiting covariance matrices of these Gaussian states tend towards low rank, effectively capturing cluster formation typical in Transformer outputs.
Gradient Flow Structures
The paper investigates equipping the Transformer PDEs with a gradient flow structure under new metrics, differing from traditional Wasserstein distances. Specifically, the Sinkhorn self-attention aligns with entropic regularization frameworks, connecting to Bures-Wasserstein gradient flows in quantum information geometry. On the other hand, a novel twisted Wasserstein distance has been proposed for Softmax attention, though the associated energy functional lacks global geodesic convexity.
Numerical Experiments
The computational evidence underpins the theoretical findings, particularly the rank-deficiency of limiting covariances in higher dimensions. These results parallel discrete token clustering and emphasize differences in behavior, particularly between L2 attention (which is more numerically stable) and Softmax attention, highlighting trajectories of divergence and convergence across the solution space.
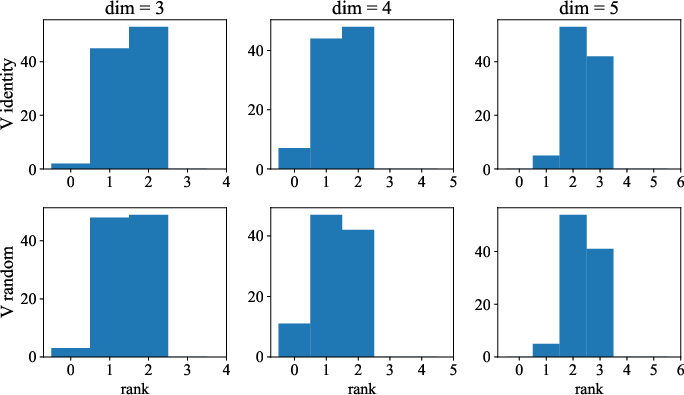
Figure 1: Histogram of the rank of limiting points of the covariance equation for Softmax self-attention in dimensions 3, 4, and 5. The clustering phenomenon is consistent with empirical token behaviors.
Conclusion
This paper contributes significantly by framing the dynamics of deep Transformer models in familiar mathematical terms, allowing for comprehensive analysis through PDEs and their interpretations as mean-field limits. The theoretical and empirical results provide a cohesive understanding of how different attention mechanisms influence the emergent properties of these models, offering a pathway to optimizing Transformer architectures for diverse applications. Future research could focus on extending the applicability of these models to non-compact data and exploring the limitations of current gradient flow characterizations in capturing the nuanced behaviors of Transformer dynamics.