Mechanism-Based Intelligence (MBI): Differentiable Incentives for Rational Coordination and Guaranteed Alignment in Multi-Agent Systems
Abstract: Autonomous multi-agent systems are fundamentally fragile: they struggle to solve the Hayekian Information problem (eliciting dispersed private knowledge) and the Hurwiczian Incentive problem (aligning local actions with global objectives), making coordination computationally intractable. I introduce Mechanism-Based Intelligence (MBI), a paradigm that reconceptualizes intelligence as emergent from the coordination of multiple "brains", rather than a single one. At its core, the Differentiable Price Mechanism (DPM) computes the exact loss gradient $$ \mathbf{G}_i = - \frac{\partial \mathcal{L}}{\partial \mathbf{x}_i} $$ as a dynamic, VCG-equivalent incentive signal, guaranteeing Dominant Strategy Incentive Compatibility (DSIC) and convergence to the global optimum. A Bayesian extension ensures incentive compatibility under asymmetric information (BIC). The framework scales linearly ($\mathcal{O}(N)$) with the number of agents, bypassing the combinatorial complexity of Dec-POMDPs and is empirically 50x faster than Model-Free Reinforcement Learning. By structurally aligning agent self-interest with collective objectives, it provides a provably efficient, auditable and generalizable approach to coordinated, trustworthy and scalable multi-agent intelligence grounded in economic principles.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
1. Brief overview
This paper introduces a new way to build smart multi-agent systems called Mechanism-Based Intelligence (MBI). Instead of trying to make one giant “brain” that knows and plans everything, MBI treats intelligence as good teamwork among many smaller agents. The key tool is a Differentiable Price Mechanism (DPM) that tells each agent exactly how to change its action to help the whole team reach the goal. The authors argue this makes agents both coordinated and aligned with the overall objective, with mathematical guarantees.
2. Key objectives and questions
The paper aims to answer, in simple terms:
- How can many independent agents, each with their own limited knowledge, work together so their actions help the shared goal?
- How can we ensure each agent’s self-interest doesn’t harm the team (alignment)?
- Can we do this efficiently, without the heavy, slow planning that traditional methods need?
3. Methods and approach (explained simply)
The authors borrow ideas from economics and calculus to design a “rulebook” that makes coordination natural.
The problem they’re solving
- Hayekian Information Problem: Useful knowledge is spread out. Each agent sees different things (like sensors in different places, people with local expertise). A single central brain can’t gather all this perfectly.
- Hurwiczian Incentive Problem: Even if agents know what to do locally, they might choose actions that help themselves but hurt the group unless the rules reward the right behavior.
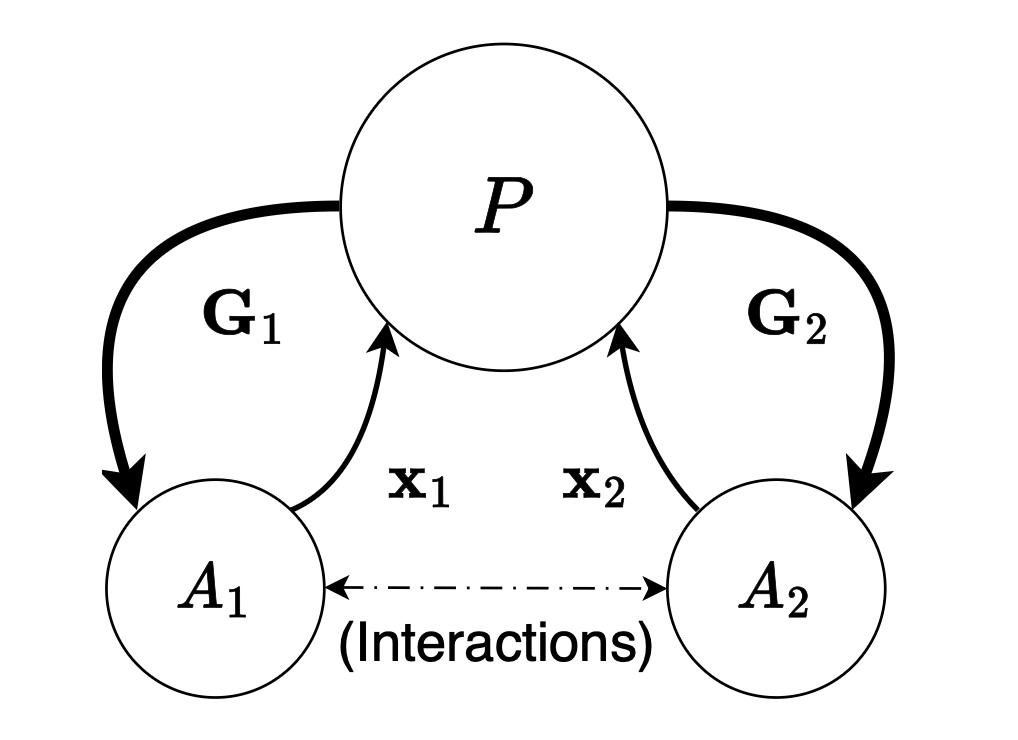
The planner, the graph, and the goal
- Planner: Think of a fair referee who sets the team’s overall goal (like “minimize total time” or “hit target output”) and defines how agents connect. This Planner does not micromanage; it just sets the rules and the objective.
- D-DAG (Differentiable Directed Acyclic Graph): This is a clean flowchart of who sends information to whom. It’s “differentiable,” meaning we can calculate how small changes in one agent’s action affect the final result.
- Global loss: A single score that tells how well the whole system is doing. Lower is better (like fewer errors or lower cost).
The Differentiable Price Mechanism (DPM)
- Core idea: After agents act, the system computes a precise signal for each agent that says, “If you nudge your action this way, you’ll help the team this much.”
- In math, this signal is the negative gradient: . You can read it as: “How much would the team’s score improve if agent i tweaked its action a tiny bit?” Negative means it reduces the loss, which is good.
- Why this matters: It turns the team’s big, complicated goal into a clear, local instruction for each agent.
How the cycle works (like a game loop)
- Forward pass: Agents choose actions using their local info.
- Compute team score: The system measures how good the joint result is.
- Backward pass (the “price” signal): The system calculates for each agent—the personalized guidance for the next step.
- Update: Agents use next time to do better.
Incentives and rational behavior
- Each agent tries to maximize its own “utility” (how much it benefits), which the mechanism ties directly to . That means when they help themselves, they also help the team.
- Bounded rationality (Simon's idea): Agents don’t plan forever. They stop when the extra thinking isn’t worth the cost. The paper includes a “thinking cost” so agents use just enough effort, not too much.
Why this is like a fair market
- The DPM works like a dynamic price: it charges or rewards agents in proportion to the impact of their actions on the team. This is similar to famous mechanisms in economics (like Vickrey-Clarke-Groves) that make telling the truth your best strategy.
- With a Bayesian version, it also works when the system doesn’t know each agent’s exact costs, only a probability range.
4. Main findings and why they matter
Here’s what the authors claim their method achieves:
- Guaranteed alignment: Because comes from the team’s goal, maximizing personal utility aligns with improving the shared outcome. In economics terms, this is incentive compatibility (agents have no reason to “game” the system).
- Strong coordination signal: is a rich, directional signal (like a compass showing where and how far to move), not a vague score. That makes learning and coordination faster and clearer than typical reinforcement learning rewards.
- Efficiency and scale: Computing all scales linearly with the number of agents (proportional to N), instead of exploding combinatorially like many multi-agent planning methods. The authors report it’s about 50× faster than a common model-free RL baseline in their tests.
- Handles private, local knowledge: Because agents act on their own information and the mechanism only needs gradients, the system can use scattered, hard-to-centralize knowledge effectively.
- Theoretical grounding: The method connects to well-known economic mechanisms that are proven to align self-interest with group goals, and it provides a clear, auditable reason for each agent’s action.
Why this matters: If true in practice, it could make multi-agent AI much more reliable, controllable, and scalable for real-world tasks like logistics, energy grids, or finance—areas where many independent parts must coordinate safely.
5. Implications and potential impact
If adopted, MBI could shift how we build advanced AI:
- From one big thinker to many coordinated doers: Rather than building bigger black-box models, we design better rules and signals so agents coordinate rationally.
- Trust and transparency: Because the incentive signal is directly tied to the team’s goal and is mathematically traceable, it can help explain why each agent did what it did.
- Practical uses: The approach could help in supply chains, automated markets, robot teams, or climate-related coordination, where good local decisions must add up to a good global outcome.
- Future challenges: It works best when the system’s goal and agent costs are differentiable and reasonably well-behaved. The authors note harder cases (like non-convex problems or very uncertain costs) need more research, and they propose Bayesian extensions and advanced optimization tricks.
A simple example to make it concrete
Imagine two workers making a product:
- Worker 1 chooses a base size .
- Worker 2 makes a final adjustment to hit a target .
- The team’s score (loss) is worse if the final size misses , and it also gets worse if Worker 1 uses a very large base (because that’s costly).
MBI computes for each worker a signal that says, “If you increase or decrease your choice a little, here’s how much the team score will improve.” Each worker then adjusts in the direction that helps the team most. The math shows the best solution is to let the cheaper worker (Worker 2) do the adjusting, while Worker 1 keeps the base small. No central boss tells them precisely what to do; the mechanism’s signals lead them there naturally.
Bottom line
This paper argues that the smartest way to get many agents to act well together is not to think harder in one place, but to design better incentives everywhere. By turning the team’s goal into clear, personalized guidance for each agent—and making that guidance their best self-interested move—MBI promises fast, reliable, and transparent coordination at scale.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of unresolved issues and concrete research directions that the paper leaves open.
- Formal convergence guarantees: Specify and prove the exact conditions (e.g., convexity/strong convexity, Lipschitz continuity, step-size rules, synchronous vs. asynchronous updates) under which the DPM-driven agent updates provably converge to the global optimum, and characterize failure modes when assumptions are violated.
- VCG-equivalence rigor: Provide a formal theorem with necessary and sufficient conditions showing when a gradient-based “price” signal is truly VCG-equivalent, including assumptions on quasilinear utilities, transfer implementation, and the mapping from gradients to monetary payments or utility adjustments.
- Payment and budget-balance implementation: Clarify how incentives are operationalized as actual transfers (not just information signals), address individual rationality and budget balance (a known limitation of VCG), and analyze the planner’s budget requirements and potential deficits/surpluses at scale.
- DSIC/BIC with incomplete information: Develop a rigorous mechanism design treatment for asymmetric information beyond using expected costs E[λi], including (i) priors, belief updates, and posterior inference, (ii) dynamic type changes, (iii) robustness to mis-specified priors, and (iv) conditions for DSIC/BIC under learning or uncertainty about agent types.
- Collusion and manipulation: Analyze susceptibility to collusion, gradient gaming, or strategic manipulation of inputs/outputs that affect the backpropagated incentive signal; propose anti-collusion constraints or audit protocols that preserve IC under coalition formation.
- Non-convex and discrete action spaces: Extend the framework to non-convex objectives and discrete/combinatorial choices (common in planning, scheduling, and markets), and determine when relaxations, subgradients, or surrogate losses preserve IC and convergence.
- Cycles and dynamic feedback: The D-DAG assumption excludes feedback loops prevalent in real systems. Develop methods for cyclic or dynamic environments (e.g., unrolling, fixed-point computation, equilibrium messages) and study stability under delayed or recurrent interactions.
- Partial observability and unknown dynamics: Explain how gradients are obtained when the mapping from actions to global loss is unknown, partially observed, or stochastic; quantify sample complexity, variance, and bias of gradient estimators, and analyze how estimation error affects IC and convergence.
- Stochastic environments and noise: Provide bounds on performance and incentive compatibility under noisy gradient signals, measurement error, delayed incentives, and nonstationary environments; include robustness analyses and variance reduction techniques.
- Update rules and step-size selection: Specify the agent-side optimization procedure (e.g., gradient ascent, line search, trust region), learning rates, and stopping criteria for the satisficing condition; analyze stability under simultaneous versus sequential updates and stale gradients.
- Coupling constraints and KKT structure: Incorporate shared constraints (e.g., budgets, capacities, resource limits) and explicitly tie the DPM to Lagrange multipliers/KKT conditions to ensure feasibility and correct internalization of constraint-induced externalities.
- Utility realism and heterogeneity: The utility UAi = Gi − C(Effort) abstracts away heterogeneous objectives and non-quasilinear preferences. Investigate how heterogeneous, multi-attribute, or non-additive utilities impact IC and whether the gradient signal remains sufficient to align self-interest.
- Effort cost modeling and calibration: Provide practical models and empirical calibration methods for C(Effort) across diverse computational agents (LLMs, solvers, simulators), and study sensitivity of outcomes to misspecification of effort costs.
- Communication, latency, and scalability in practice: Quantify communication overheads, incentive delivery latency, and failure modes in distributed settings; verify whether O(N) scaling holds when action dimensions, bandwidth constraints, and synchronization costs are included.
- Security and integrity of incentive signals: Develop cryptographic or verifiable computation schemes to guarantee that agents can trust the correctness of the gradients they receive, and design tamper-resistance against adversarial attacks on the mechanism.
- Privacy and information leakage: Assess whether high-information gradient signals leak private state or type information; propose privacy-preserving mechanism variants (e.g., differential privacy, secure aggregation) and analyze the trade-off with IC and accuracy.
- Fairness and multi-objective trade-offs: Examine how the choice of global loss encodes normative trade-offs (e.g., fairness, risk, safety) and whether DPM-based alignment can incorporate constraints beyond efficiency; develop methods for multi-objective or lexicographic goals without breaking IC.
- Benchmarking and empirical validation: Provide standardized, reproducible benchmarks (beyond the toy example and Appendix claims) comparing MBI against state-of-the-art cooperative RL, differentiable games, and mechanism-learning baselines across stochastic, partially observable, and non-convex tasks.
- Human-in-the-loop integration: Specify how the mechanism interfaces with human agents (bounded rationality, biases, compliance), and design socio-technical protocols (UX for incentives, conflict resolution, accountability) that preserve IC and practical usability.
- Relation to potential games and differentiable games: Situate MBI within the theory of potential games and differentiable game dynamics; identify conditions under which the global loss functions as a potential and how this affects equilibrium existence, uniqueness, and learning dynamics.
- Budgeted/planner-side optimization: Analyze planner-side computational and institutional costs (mechanism design, D-DAG maintenance, belief updates), and propose scalable algorithms for planner optimization under resource constraints.
- Robustness to model misspecification: Quantify sensitivity to errors in the global loss specification and D-DAG structure; develop mechanisms for online correction, safe defaults, and guarantees under bounded misspecification.
- Legal/regulatory and XAI specifics: Translate claims of auditability and explainability into concrete governance artifacts (logs, proofs, compliance checks), and evaluate regulatory alignment (e.g., with AI Act requirements) for real deployments.
- Generalization beyond differentiability: Explore extensions to non-differentiable processes (code execution, symbolic reasoning, discrete simulators) via smoothing, surrogate modeling, or subgradient methods while maintaining IC guarantees.
- Asynchronous and event-driven systems: Characterize performance and guarantees when agents act on different clocks, events, or triggers, and study convergence in the presence of network jitter, partial updates, and dynamic participation.
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed now or with modest engineering effort, leveraging the paper’s Differentiable Price Mechanism (DPM), Differentiable Directed Acyclic Graph (D-DAG), and bounded-rational agent utility.
- Enterprise multi-agent LLM orchestration for complex workflows
- Sector: software; enterprise IT; productivity
- What: Replace ad hoc “agentic” pipelines with an MBI orchestrator that defines a global loss over business KPIs (quality, latency, cost, compliance) and routes high-information incentive signals
G_i = -∂L/∂x_ito LLM tools (retrievers, planners, coders, testers). - Tools/Products/Workflows: “MBI Orchestrator SDK” for LangChain/LlamaIndex; a D-DAG compiler; “Incentive Router” middleware that backpropagates incentives; telemetry-to-loss aggregator that computes audit-ready explanations.
- Assumptions/Dependencies: Differentiable global objective; actionable telemetry; D-DAG decomposition of the pipeline; convex local action spaces improve guarantees; organizational willingness to treat agents as utility-maximizers with cost-of-compute.
- Manufacturing line balancing and sequential task coordination
- Sector: robotics; industrial automation; MES/ERP
- What: Use MBI to align upstream and downstream station decisions (e.g., sizing, timing, rework rates) with a plant-wide loss (throughput, scrap, energy, SLA penalties), sending gradient incentives to local controllers or decision support UIs.
- Tools/Products/Workflows: “MBI for MES” plugin; OPC-UA adapters; incentive-aware station controllers; dashboards showing externality-internalization at each node.
- Assumptions/Dependencies: Instrumentation to calculate losses and gradients; differentiable surrogate models for station dynamics; initial convex approximations; human-in-the-loop validation for safety.
- Cloud microservice SLO governance (cost, latency, error budget)
- Sector: software; DevOps; SRE
- What: Model service mesh as a D-DAG; define global loss over SLOs and cloud spend; compute
G_ito steer autoscaling, caching, queue priorities, and rollout gates. - Tools/Products/Workflows: “MBI SRE Controller” integrated with Kubernetes/HPA; Prometheus/Grafana loss builder; incentive-aware canary gating in CI/CD.
- Assumptions/Dependencies: Reliable metrics and differentiable SLO loss; guardrails for non-convex behaviors (e.g., tail latency); policy acceptance of incentive-driven autoscaling.
- Supply chain local decision alignment (inventory, routing, procurement)
- Sector: logistics; retail; manufacturing
- What: D-DAG across suppliers, DCs, and retailers; global loss over stockouts, working capital, transport emissions; gradient incentives to set reorder points, carrier choices, and lead-time buffers.
- Tools/Products/Workflows: “MBI Supply Chain Studio”; ERP/APS connectors; incentive dashboards explaining marginal externalities per node.
- Assumptions/Dependencies: Differentiable surrogate models of demand and lead times; BIC extension if costs are privately known; data-sharing agreements.
- Smart home/device orchestration for comfort-energy trade-offs
- Sector: consumer IoT; energy
- What: Define a household loss (comfort deviation, energy price, carbon intensity) and send
G_ito HVAC, EV charging, lighting, and appliances to align actions. - Tools/Products/Workflows: Home Assistant “MBI Coordinator”; utility price/carbon APIs; user preference calibration UI.
- Assumptions/Dependencies: Access to device controls; simple convex cost models; consent and privacy by design.
- SOC triage and cyber incident response coordination
- Sector: cybersecurity
- What: Use MBI to coordinate detectors, triage agents, and responders with a global loss over risk, response time, and false positives; incentives guide prioritization and evidence gathering.
- Tools/Products/Workflows: “MBI SOC Brain” integrated with SIEM/SOAR; incentive-aware playbooks; XAI audit trails showing gradient rationales.
- Assumptions/Dependencies: Differentiable risk scoring; high-quality labeling/feedback; safe human override.
- DAO governance and bounty allocation with auditability
- Sector: web3; digital organizations
- What: Replace static reward rules with DPM-based incentives tied to a transparent global loss (roadmap progress, QA quality, treasury risk); agents internalize externalities (e.g., QA delays impact release).
- Tools/Products/Workflows: “MBI Governance Module” for DAO frameworks; verifiable on-chain logs of
G_isignals; bounty router based on planner-defined loss. - Assumptions/Dependencies: On-chain/off-chain bridging; BIC for asymmetric costs; community acceptance of mechanism-driven payouts.
- XAI/Compliance overlays for multi-agent systems
- Sector: regulated industries (finance, healthcare, public sector)
- What: Use gradient incentives and D-DAG traces as auditable explanations of why agents acted; show marginal externality internalization in reports.
- Tools/Products/Workflows: “MBI Explainability Layer”; compliance dashboards; exportable mechanism proofs of DSIC-equivalence.
- Assumptions/Dependencies: Stable mechanism definitions; regulator acceptance of mechanism-based explanations; consistent logging.
- Academic benchmarking in multi-agent coordination
- Sector: academia; AI/economics
- What: Establish benchmarks comparing MBI vs RL (PPO) on Dec-POMDP-like tasks; use linear scaling O(N) and 50× speed claims to study sample efficiency and alignment.
- Tools/Products/Workflows: Open-source “MBI Gym”; canonical D-DAG tasks; reproducible DSIC/BIC demonstrations.
- Assumptions/Dependencies: Shared task suites; careful treatment of convexity and differentiability; transparent code.
- Hospital-level scheduling and bed/OR allocation pilots
- Sector: healthcare operations
- What: D-DAG over wards, ORs, and staff; global loss (wait times, overtime, cancellations); gradient incentives to guide schedule adjustments and resource sharing.
- Tools/Products/Workflows: “MBI Ops Coordinator” integrated with EHR/OR systems; incentive-aware rosters.
- Assumptions/Dependencies: Operations data; privacy and HIPAA compliance; human override; surrogate models for patient flow.
Long-Term Applications
These use cases require further research, scale-out, non-convex control techniques, or policy integration (as noted in the paper’s future work and Bayesian extension).
- National-scale grid coordination and demand response
- Sector: energy
- What: Use DPM as a continuous “price-like” incentive to align DERs, storage, and loads with system-wide losses (reliability, emissions, cost), enabling DSIC/BIC-style coordination.
- Tools/Products/Workflows: “MBI Grid Coordinator”; microgrid pilots; ISO/RTO integration for dynamic mechanism pricing; DER incentive APIs.
- Assumptions/Dependencies: Non-convex dynamics and stability guarantees; regulator buy-in; robust telemetry; BIC for private costs; safety certification.
- Fleet-level autonomous driving and traffic flow alignment
- Sector: mobility; robotics
- What: Coordinate AV route choice, lane changes, and charging with a global loss (safety risk, congestion, energy), sending
G_ito local planners. - Tools/Products/Workflows: “MBI Fleet Brain”; V2X incentive protocols; city-level planners defining loss functions.
- Assumptions/Dependencies: Non-convex control; real-time guarantees; liability and standards; city data-sharing; robust simulations.
- Swarm robotics and warehouse autonomy
- Sector: robotics; logistics
- What: Incentive-driven coordination of many robots for picking, packing, and routing to minimize time and collisions; gradients guide motion plans and task assignment.
- Tools/Products/Workflows: “MBI Swarm Controller”; ROS integrations; incentive-aware task allocators.
- Assumptions/Dependencies: Handling non-convex kinematics/obstacles; safe fallback policies; certified performance.
- Market infrastructure and automated auctions with differentiable economics
- Sector: finance; marketplaces
- What: Implement VCG-equivalent, incentive-compatible mechanisms for ad auctions, cloud spot markets, or freight exchanges using differentiable losses.
- Tools/Products/Workflows: “MBI Auction Engine”; DE (Differentiable Economics) integration; simulators for welfare/outcome audits.
- Assumptions/Dependencies: Regulatory approval; game-theoretic stress testing; adversarial robustness; BIC for private types.
- Climate policy implementation across regions (carbon budgets, resilience)
- Sector: policy; sustainability
- What: Planner-defined losses (emissions, adaptation costs, equity) driving incentive signals to municipalities and firms; mechanism ensures externalities are internalized.
- Tools/Products/Workflows: “MBI Climate Planner”; policy dashboards; incentive APIs tied to tax/subsidy instruments.
- Assumptions/Dependencies: Political feasibility; data quality; multi-level governance; societal acceptance of mechanism-driven coordination.
- Healthcare care-pathway optimization at network scale
- Sector: healthcare
- What: Align distributed care teams, diagnostics, and scheduling with outcome-based losses (readmission, time-to-treatment, cost), incentivizing actions across hospitals.
- Tools/Products/Workflows: “MBI Care Network”; payer-provider mechanism contracts; incentive-aware care coordination tools.
- Assumptions/Dependencies: Patient privacy; causal validity of surrogate losses; non-convexity and fairness constraints; reimbursement integration.
- Education resource allocation and multi-agent tutoring ecosystems
- Sector: education
- What: Coordinate teacher time, AI tutors, and content sequencing with a global loss (learning outcomes, equity, cost), sending
G_iincentives to adapt schedules and interventions. - Tools/Products/Workflows: “MBI Learning Planner”; LMS integrations; incentive-aware tutoring orchestration.
- Assumptions/Dependencies: Measurement robustness; fairness; privacy; human governance; socio-technical acceptance.
- Globally scalable decentralized AI economy (agents as firms)
- Sector: cross-sector; socio-technical systems
- What: Mechanism-designed marketplaces where computational agents trade services/resources under DPM incentives to satisfy global objectives (efficiency, safety).
- Tools/Products/Workflows: “MBI Economic OS”; standards for incentive signals; audit registries of externalities.
- Assumptions/Dependencies: Interoperability standards; safe DSIC in heterogeneous environments; resilience to manipulation; non-convex mechanism research.
- Research extensions: non-convex guarantees, trust-region/stochastic methods, dynamic beliefs
- Sector: academia; foundational AI/economics
- What: Develop methods that preserve IC under non-convex costs, dynamic planner beliefs (Bayesian MBI), and hybrid human-computer coordination.
- Tools/Products/Workflows: Open research benchmarks; formal verification toolchains; hybrid lab studies.
- Assumptions/Dependencies: New theory/algorithms; empirical validation at scale; cross-disciplinary teams.
Cross-cutting assumptions and dependencies affecting feasibility
- Differentiability and convexity: DSIC/VCG-equivalent guarantees are strongest under differentiable, convex action spaces and losses; non-convex environments need trust-region/stochastic extensions.
- Accurate global loss modeling: Planners must define meaningful, measurable objectives; poor surrogates can misalign incentives.
- Bayesian extension for private information: When agent costs are unknown, the BIC variant relies on calibrated beliefs
E[λ_i]; miscalibration can increase global loss. - Telemetry and D-DAG decomposition: Instrumentation to compute gradients and an acyclic process graph are required; cyclic dependencies need careful restructuring.
- Bounded rationality modeling: Agent utilities should incorporate computational cost; tuning
C(Effort)affects efficiency and responsiveness. - Governance and auditability: Adoption depends on transparent logging of
G_i, explainability, and regulator acceptance; mechanism misuse must be prevented. - Safety and human oversight: High-stakes domains need guardrails, escalation paths, and verified fallbacks; human-in-the-loop remains necessary.
Glossary
- Automated Mechanism Design (AMD): The use of algorithmic and computational methods to design game-theoretic mechanisms that achieve desired objectives with strategic agents. "Automated Mechanism Design (AMD)"
- Bayesian Incentive Compatibility (BIC): A property of mechanisms where truthful behavior maximizes expected utility given beliefs about others’ private information. "A Bayesian extension ensures incentive compatibility under asymmetric information (BIC)."
- Bayesian MBI (BMBI): A Bayesian extension of the MBI framework that sets incentives based on the planner’s belief over agent types to handle asymmetric information. "The Bayesian MBI (BMBI) extension mitigates this issue by setting incentives based on the Planner's belief ()."
- Bounded Rationality (BR): The notion that agents have limited computational resources and cannot compute globally optimal solutions, settling for satisfactory ones. "Planning Constraints and Bounded Rationality (BR):"
- Contract Net Protocol: A decentralized task allocation protocol in multi-agent systems where agents bid for tasks based on capabilities. "Contract Net Protocol"
- Decentralized autonomous organizations (DAOs): Organizations governed by smart contracts and distributed decision-making rather than centralized authorities. "decentralized autonomous organizations (DAOs)"
- Decentralized Partially Observable Markov Decision Process (Dec-POMDP): A formal model for cooperative decision-making by multiple agents with partial observations and decentralized control. "Decentralized Partially Observable Markov Decision Process (Dec-POMDP) framework"
- Differentiable Directed Acyclic Graph (D-DAG): A computational graph with directed, acyclic structure where operations are differentiable, enabling gradient-based incentive computation. "Differentiable Directed Acyclic Graph (D-DAG)"
- Differentiable Economics (DE): The application of differentiable optimization and machine learning to solve economic mechanism design problems. "Differentiable Economics (DE)"
- Differentiable Price Mechanism (DPM): A mechanism that computes incentives as negative gradients of the global loss, aligning local actions with global objectives. "the Differentiable Price Mechanism (DPM) computes the exact loss gradient"
- Distributed Planner Mechanism (DPM): An analytically derived mechanism (named in the paper) to achieve VCG-equivalence under Hurwiczian constraints. "Distributed Planner Mechanism (DPM) to achieve VCG-Equivalence"
- Dominant Strategy Incentive Compatibility (DSIC): A mechanism property where truth-telling or target action is optimal for each agent regardless of others’ strategies. "guaranteeing Dominant Strategy Incentive Compatibility (DSIC)"
- Evidence Lower Bound (ELBO): A variational inference objective that lower-bounds the log-likelihood, often used to guide approximate probabilistic modeling. "analogous to the Evidence Lower Bound (ELBO) in variational inference."
- Explainable AI (XAI): Methods and practices that make AI system decisions understandable to humans. "Explainable AI (XAI)"
- Externality: The marginal cost or benefit imposed on the global objective by an individual agent’s action, not accounted for in the agent’s private decision. "internalize all externalities its action creates."
- First-Order Condition (FOC): The necessary condition for optimality in continuous optimization where the derivative of the objective with respect to the decision variable equals zero. "necessary first-order condition (FOC)"
- General Problem Solver (GPS): An early AI system aimed at general-purpose problem solving, illustrating the limits of centralized cognitive planning. "the General Problem Solver (GPS)"
- Hierarchical Joint Embedding Predictive Architecture (H-JEPA): A centralized predictive architecture that learns hierarchical representations for world modeling. "Hierarchical Joint Embedding Predictive Architecture (H-JEPA)"
- Hurwiczian Incentive Problem: The challenge of ensuring that self-interested, locally optimizing agents remain aligned with global objectives. "The Hurwiczian Incentive Problem"
- Hurwiczian Mechanism Design: Mechanism design principles (following Hurwicz) used to align local incentives with global goals through explicit rules and pricing. "Hurwiczian Mechanism Design"
- Incentive Compatibility (IC): The property that mechanisms elicit truthful reporting or aligned actions from agents as their utility-maximizing behavior. "they lack formal guarantees of Incentive Compatibility (IC)"
- Kalman filter: An optimal estimator for linear dynamical systems with Gaussian noise, used for state correction and prediction. "Unlike a Kalman filter, which corrects its state optimally"
- Large Reasoning Models (LRMs): Models designed for compositional and stepwise reasoning tasks beyond standard language modeling. "Large Reasoning Models (LRMs)"
- Mechanism-Based Intelligence (MBI): A paradigm viewing intelligence as emergent from rational coordination via mechanisms and incentives in multi-agent systems. "Mechanism-Based Intelligence (MBI), a paradigm"
- Model-Free Reinforcement Learning (Model-Free RL): RL approaches that learn policies or value functions without explicit environment models. "Model-Free Reinforcement Learning"
- Monte-Carlo Tree Search (MCTS): A heuristic search algorithm that uses Monte Carlo simulations to explore action spaces in planning problems. "Monte-Carlo Tree Search (MCTS)"
- Planner Axiom: The assertion that any stable system requires at least one planner to structure rules, allocate actions/resources, and provide feedback for equilibrium. "Planner Axiom: Every stable system—biological, social or computational—requires at least one Planner"
- Proximal Policy Optimization (PPO): A policy gradient RL algorithm that stabilizes training via clipped objectives and trust constraints. "Model-Free RL (PPO)"
- Satisficing: A decision strategy where agents stop searching once an action meets a sufficiency criterion rather than seeking a global optimum. "Simon's satisficing"
- Trust-region optimization: Optimization methods that restrict steps to a region where local models are reliable, aiding convergence in nonconvex settings. "trust-region optimization"
- Trustworthy AI: AI systems that are reliable, ethical, safe, and compliant with regulations. "Trustworthy AI"
- Von Neumann–Morgenstern (VNM) Expected Utility Theory: A formal framework for rational decision-making under uncertainty based on expected utility maximization. "VNM Expected Utility Theory"
- Vickrey–Clarke–Groves (VCG): A class of mechanisms that achieve efficiency and truthful behavior via payments aligned with marginal externalities. "VCG-equivalent incentive signal"
- World Models: Internal predictive representations that simulate environment dynamics for planning and reasoning. "predictive ``World Models''"
Collections
Sign up for free to add this paper to one or more collections.

