Can LLMs Predict Their Own Failures? Self-Awareness via Internal Circuits
Abstract: LLMs generate fluent and complex outputs but often fail to recognize their own mistakes and hallucinations. Existing approaches typically rely on external judges, multi-sample consistency, or text-based self-critique, which incur additional compute or correlate weakly with true correctness. We ask: can LLMs predict their own failures by inspecting internal states during inference? We introduce Gnosis, a lightweight self-awareness mechanism that enables frozen LLMs to perform intrinsic self-verification by decoding signals from hidden states and attention patterns. Gnosis passively observes internal traces, compresses them into fixed-budget descriptors, and predicts correctness with negligible inference cost, adding only ~5M parameters and operating independently of sequence length. Across math reasoning, open-domain question answering, and academic knowledge benchmarks, and over frozen backbones ranging from 1.7B to 20B parameters, Gnosis consistently outperforms strong internal baselines and large external judges in both accuracy and calibration. Moreover, it generalizes zero-shot to partial generations, enabling early detection of failing trajectories and compute-aware control. These results show that reliable correctness cues are intrinsic to generation process and can be extracted efficiently without external supervision.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Can LLMs Predict Their Own Mistakes? A Simple Guide to “Gnosis”
What is this paper about?
This paper looks at a big problem with AI LLMs: they can sound very confident even when they’re wrong. Instead of asking a separate, bigger model to check their work, the authors ask a new question: can a model look at its own “thought process” while it’s answering and tell if it’s likely to be right or wrong?
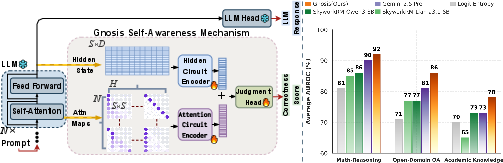
They introduce Gnosis, a tiny add-on (about 5 million parameters) that plugs into an existing LLM and predicts whether the model’s answer is correct—by reading the model’s internal signals—without changing the LLM or slowing it down much.
What questions did the authors ask?
The paper focuses on three simple questions:
- Can an LLM predict when it is making a mistake just by watching its own inner activity as it generates an answer?
- Can this be done with almost no extra cost or delay?
- Will this work across different kinds of tasks (like math, trivia, and school subjects), and even when we only see part of the answer?
How does Gnosis work? (Everyday explanation)
Think of the LLM like a student solving a problem:
- The student’s “hidden states” are like their brain activity at each step.
- The “attention maps” are like where the student focuses their eyes—what part of the text they pay attention to while thinking.
Gnosis is like a tiny coach sitting quietly beside the student, not changing the student’s work, just watching these signals and deciding, “Does this look like a correct line of thinking, or is something off?”
Here’s the approach, in simple steps:
- Read the model’s internal signals:
- Hidden states: snapshots of what the model is thinking at each step.
- Attention maps: a map of where the model is focusing its attention.
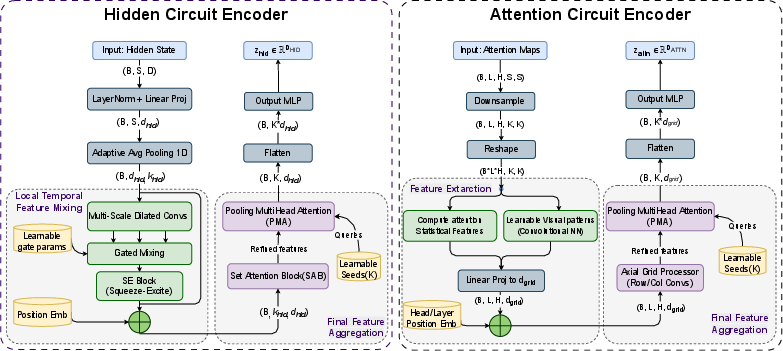
- Summarize them to a fixed size:
- Answers can be short or very long. Gnosis compresses the signals to a small, fixed-size “summary,” so its speed doesn’t depend on how long the answer is. (Imagine turning a whole movie into a short trailer that still captures the key moments.)
- Two “streams” of understanding:
- A hidden-state stream that looks for patterns over time (like noticing smooth, steady reasoning vs. jumpy, messy thinking).
- An attention stream that reads the focus patterns (like noticing whether attention is stable, local, or scattered).
- Fuse both views:
- A small final layer combines both summaries and outputs one number: the probability that the answer is correct (between 0 and 1).
- Training (no human grading needed):
- The model generates answers on training questions.
- The authors check if the final answers match the correct ones (automatic checking).
- Gnosis learns to predict “right” vs. “wrong” from the internal signals alone.
- The original LLM stays frozen; only the tiny Gnosis add-on is trained.
What did they find, and why does it matter?
Here are the key results and why they’re important:
- Stronger than big external judges:
- Gnosis, with ~5M parameters, often beats reward models that are about 1000× larger and even a very large “judge” model on math, trivia, and academic tests.
- Why it matters: You can get better reliability without paying for huge extra models or extra runs.
- Fast and cheap:
- Gnosis adds roughly constant delay (about 25 ms in their tests), even for very long answers (e.g., 12k–24k tokens).
- Compared to large judges, it can be 37× to 99× faster on long answers.
- Why it matters: It’s practical for real-time systems.
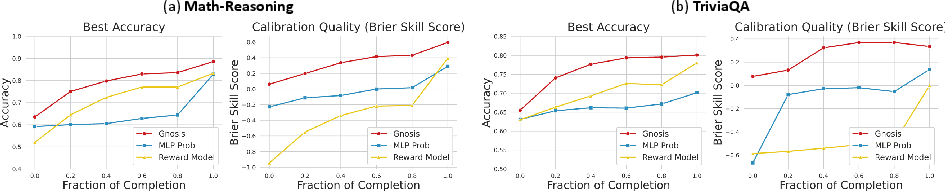
- Works early, not just at the end:
- Gnosis can judge correctness halfway through an answer and still be very accurate.
- Why it matters: If the model is going off track, you can stop early to save time and compute, or escalate the question to a stronger model.
- Transfers across model sizes:
- A Gnosis head trained on a small model (like 1.7B) can judge bigger models in the same family (like 4B or 8B) without retraining.
- Why it matters: One small checker can help many models—cheap and flexible.
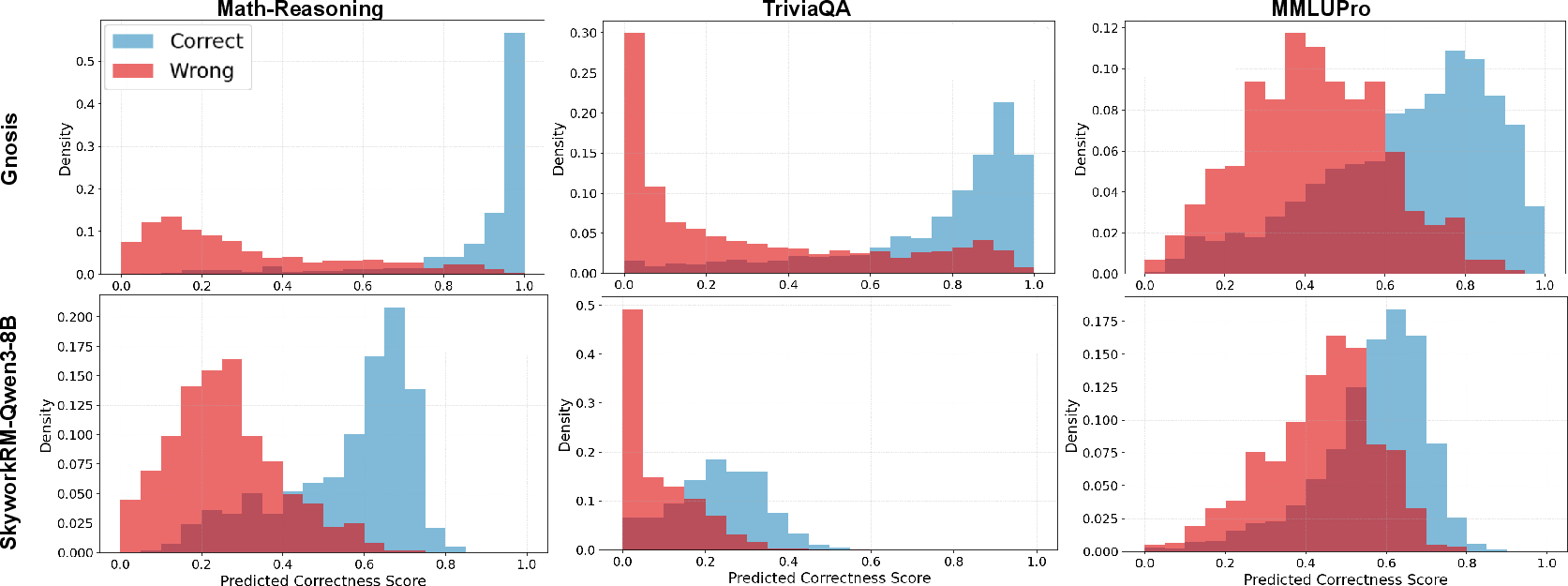
- Better calibration:
- When Gnosis says it’s 90% confident, it tends to be right about 90% of the time. Many other methods sound confident but are poorly aligned with the truth.
- Why it matters: Trustworthy confidence makes AI safer and easier to use.
What could this change in the real world?
- Safer AI assistants:
- Models can flag their own risky answers, helping avoid confident-sounding mistakes.
- Smarter use of compute:
- If the internal “alarm” goes off early, stop the answer or ask a stronger model—saving time and money.
- Easy to deploy:
- It’s tiny, fast, and doesn’t need extra prompts or multiple attempts.
- Helpful in long reasoning:
- Especially powerful in math and multi-step thinking, where “how you think” matters as much as “what you say.”
Any limitations?
- Best within a “family” of models:
- It transfers well between related models (similar style and architecture), but it’s not a universal judge for all models everywhere.
- It doesn’t add new knowledge:
- Gnosis doesn’t fact-check by itself. It reads the model’s internal signals to judge reliability; it doesn’t go look things up.
The simple takeaway
Gnosis shows that LLMs carry clues about whether they’re right or wrong inside their own thinking process. By reading those clues directly—quickly and cheaply—we can make AI that knows when to trust itself, when to slow down, and when to ask for help.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following points unresolved and open for future research:
- Applicability beyond evaluated domains: Assess Gnosis on code generation (e.g., HumanEval, MBPP), long-form summarization, multi-turn dialogue safety, tool-use/agents, and multi-modal tasks to verify whether internal signals still predict correctness reliably.
- Black-box constraints: Determine how to deploy Gnosis when full hidden states and attention maps are inaccessible (typical for closed APIs); explore reduced-telemetry variants (e.g., logits-only, selective layer hooks, synthetic “introspection tokens”) and quantify trade-offs.
- Cross-family/architecture transfer: Test zero-shot transfer across unrelated model families (e.g., Llama/Mistral/Gemma, dense vs MoE) and architectures with different depths, head counts, rotary embeddings, and positional schemes; identify the minimal alignment conditions needed for transfer to work.
- Sensitivity to generation style and decoding: Systematically evaluate robustness across prompting paradigms (CoT vs direct answers), formatting idiosyncrasies, temperature/top‑p/beam changes, and structured outputs; quantify degradation and propose normalization or conditioning strategies.
- Extremely long-context scaling: Measure memory and latency overhead of capturing and downsampling attention maps for contexts beyond 24k (e.g., 128k–1M tokens), including streaming scenarios; characterize bottlenecks and propose incremental/online compression.
- Hidden-state layer selection: Investigate whether incorporating multi-layer hidden states (not only final-layer) improves performance; provide per-layer contribution analyses and principled selection or learned weighting across layers.
- Mechanistic interpretability of learned features: Identify which heads/layers and which hidden-state trajectories drive predictions; link features to known circuits (e.g., fact recall vs reasoning) and provide causal tests (interventions/patching) rather than correlations.
- Adversarial robustness: Evaluate susceptibility to prompt-based attacks that manipulate attention routing or hidden-state trajectories to evade detection or induce false alarms; develop defenses and certify robustness bounds.
- Labeling biases and noise: Analyze effects of discarding generations without “valid final answers” on training distribution, and quantify sensitivity to label noise and imperfect answer extraction; propose noise-robust training or weak-supervision alternatives.
- Outcome vs process scoring: Extend Gnosis from final-outcome correctness to step-wise/process error detection (e.g., ProcessBench), including token-level or rationale-chunk scoring; compare against PRMs and test hybrid outcome/process fusion.
- Early detection policies: Formalize decision rules for prefix-based judgments (thresholds, patience, confidence intervals) and quantify compute–accuracy trade-offs (tokens saved, false aborts/escalations) in end-to-end systems.
- Use as a training signal: Study co-training or RL with Gnosis as a reward and the potential for “gaming” the verifier; examine stability, distribution shifts, and whether backbone models learn to steer internal traces without truly improving correctness.
- Ensemble strategies: Explore combining Gnosis with external judges or self-consistency signals to improve accuracy/calibration; analyze complementarities and cost-effective fusion schemes.
- Calibration under distribution shift: Provide reliability diagrams and calibration analyses across strong domain shifts (new subjects, formats, languages); test recalibration methods (temperature scaling, isotonic) specific to internal descriptors.
- Hyperparameter sensitivity: Quantify the impact of descriptor budgets (, ), pooling/downsampling choices, and attention feature extractor variants (CNN vs stats) on performance and latency; provide guidelines for resource-constrained deployments.
- Applicability to instruction-following vs “thinking” variants: Systematically characterize when transfer fails between Thinking and Instruct models and propose conditioning or domain-adaptive heads to bridge formatting/style gaps.
- Coverage of attention types: Clarify whether only self-attention is used; evaluate inclusion of cross-attention (e.g., tool outputs, retrieval contexts) and its effect on reliability prediction.
- Data efficiency: Determine minimal training data requirements, scaling laws for head size vs dataset size, and whether task-specific fine-tuning is necessary for new domains.
- Privacy and security considerations: Assess whether exposing internal traces poses privacy risks or increases attack surface in shared-serving contexts; propose secure telemetry abstractions.
- Practical serving integration: Provide detailed engineering measurements for hooking internal states in production (GPU memory pressure, KV-cache interaction, batching effects), and quantify end-to-end throughput impact beyond verifier forward time.
Glossary
- Adaptive pooling: A technique to reduce variable-sized tensors to fixed-size by aggregating over dimensions. "downsampled via adaptive pooling to a fixed grid size "
- Attention eigenvalue score: A heuristic metric based on eigenvalues of attention matrices to gauge reliability. "Attn Eigenvalue Score"
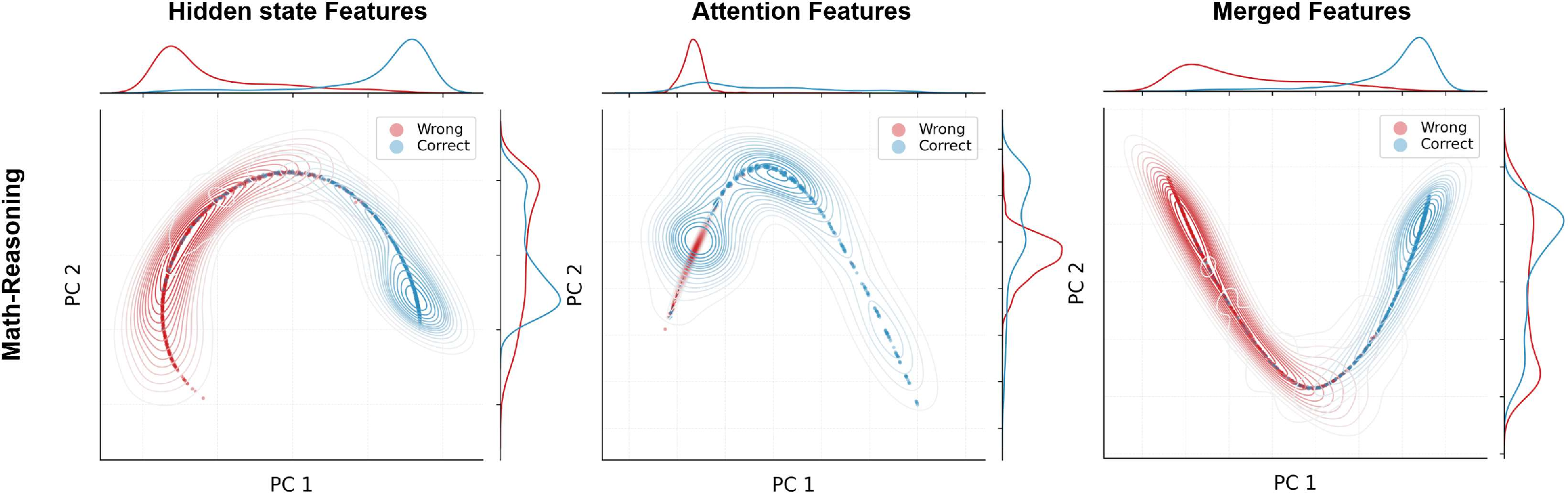
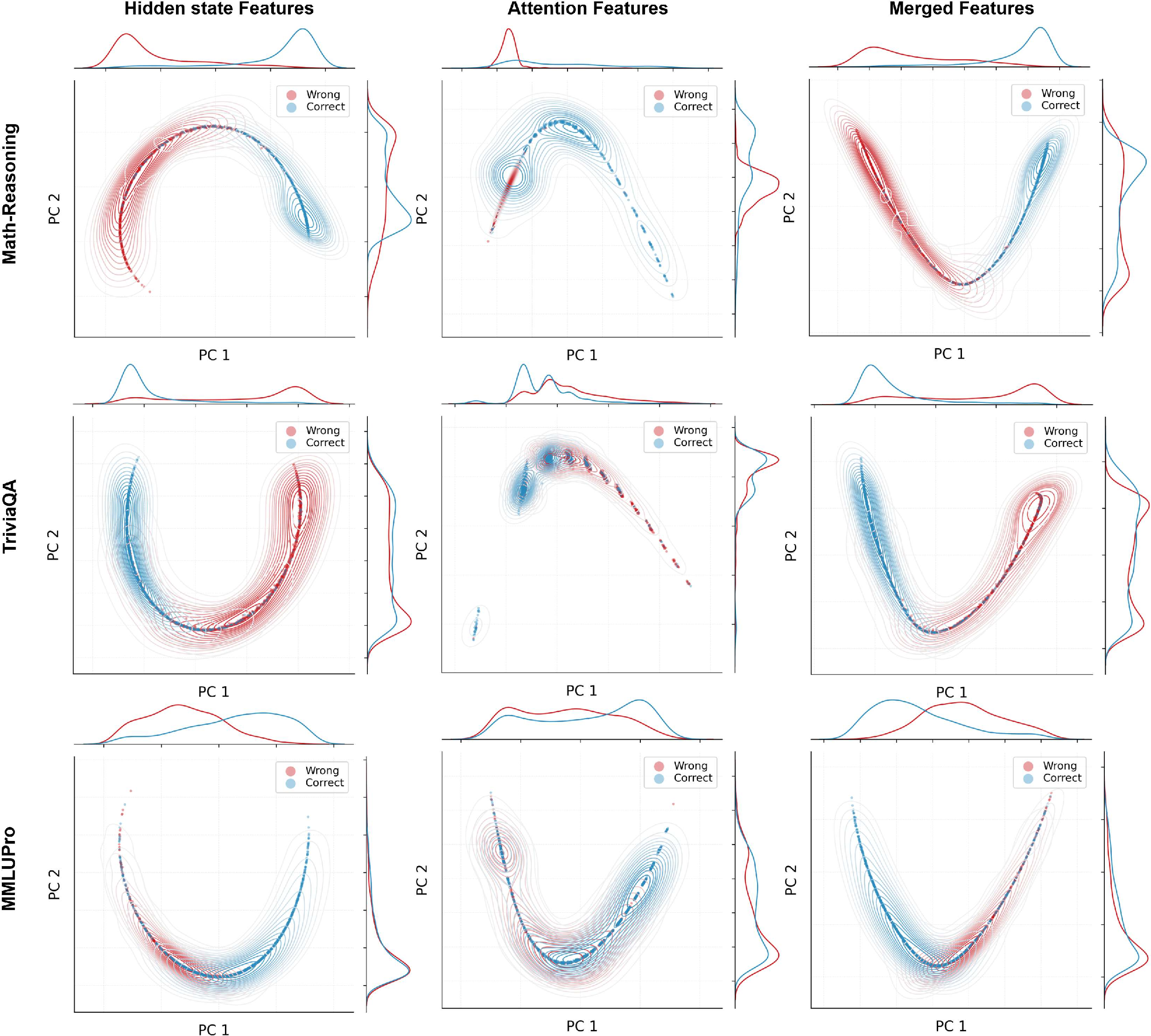
- Attention maps: Matrices of attention weights showing how tokens attend to each other. "and the attention maps "
- Attention routing: Patterns of how attention heads direct focus across tokens and layers. "attention-routing patterns through a compact, fixed-budget architecture"
- AUROC: Area under the ROC curve; measures ranking performance in binary classification. "in AUROC on math reasoning, open-domain QA, and academic knowledge"
- AUPR-c: Area under precision-recall treating correct as the positive class. "AUPR-c: correct as positive"
- AUPR-e: Area under precision-recall treating incorrect/error as the positive class. "AUPR-e: incorrect as positive"
- Axial convolutional layers: Convolutions applied along specific axes to mix information efficiently. "using a few axial convolutional layers."
- Binary cross-entropy: A loss function for binary classification comparing predicted probabilities to labels. "Gnosis is trained to minimize binary cross-entropy:"
- Brier Skill Score (BSS): A calibration metric comparing probabilistic predictions to actual outcomes. "Brier Skill Score (BSS) and Expected Calibration Error (ECE)."
- Chain-of-Embedding: A trajectory/spectral analysis of representation changes across layers. "Chain-of-Embedding"
- Compute-aware control: Adapting computation at inference time based on confidence or early signals. "compute-aware control."
- Depthwise convolution: A lightweight convolution that processes each channel independently. "multi-scale 1D depthwise convolution"
- Expected Calibration Error (ECE): Metric quantifying mismatch between predicted probabilities and empirical accuracy. "Expected Calibration Error (ECE)"
- Final-layer hidden states: The last-layer activations of the transformer used as internal signals. "we read only the final-layer hidden states"
- Fixed-Budget Compression: Strategy to project variable-length traces to fixed-size descriptors, decoupling cost from sequence length. "Fixed-Budget Compression."
- Gated MLP: An MLP with gating mechanisms to modulate feature contributions. "is a lightweight gated MLP"
- Glass-box signals: Internal model signals (logits, hidden states, attention) accessible for analysis. "Glass-box signals exploit logits, hidden states, and attention routing."
- Hallucination: Confident but incorrect outputs produced by a LLM. "mistakes and hallucinations."
- Information density: Quantitative measure of information content in representations across tokens. "Token-wise hidden-state entropy and information density can outperform perplexity-based failure prediction"
- Kernel Density Estimation (KDE): Nonparametric density estimation used for visualizing distributions. "with KDE contours and marginal densities"
- Latent representations: Internal vector representations learned by the model. "final-layer latent representations."
- Likert ratings: Ordinal human ratings on a fixed scale used for preference datasets. "Likert ratings, pairwise preferences, and extrapolation"
- Logit Entropy: Entropy computed from logits/probabilities as an uncertainty proxy. "Logit Entropy"
- Logits: Pre-softmax scores for tokens used to derive probabilities. "token probabilities (logits)"
- Mean Token Prob: Average token probability used as a confidence indicator. "Mean Token Prob"
- Mixture-of-Experts (MoE): Architecture that routes inputs to multiple expert sub-networks. "gpt-oss-20B MoE"
- Multi-sample self-consistency: Confidence estimation via agreement across multiple generations. "Multi-sample self-consistency infers confidence from agreement across sampled rationales"
- Outcome Reward Models (ORM): Models scoring final outcomes/responses for quality or correctness. "Outcome and Process Reward Models (ORM/PRM) are widely used"
- Perplexity: A language-model uncertainty measure based on token likelihoods. "perplexity-based failure prediction"
- Pooling-by-Multihead-Attention (PMA): Attention-based pooling module to aggregate sets into summaries. "Pooling-by-Multihead-Attention (PMA) block"
- Process Reward Models (PRM): Models scoring intermediate reasoning steps/processes. "Outcome and Process Reward Models (ORM/PRM) are widely used"
- Projection operator: A mapping that reduces variable-length inputs to fixed-size tensors. "we use a projection operator "
- Reward model: Auxiliary model that evaluates or ranks generated responses. "External reward models and judge LLMs"
- Set Attention Blocks (SAB): Set-Transformer components enabling attention over set elements. "Set Attention Blocks (SAB) followed by a Pooling-by-Multihead-Attention (PMA) block."
- Set Transformer: Architecture for processing sets with permutation-invariant attention. "Set Transformer–style encoder"
- Sibling Modeling: Training a verifier on one model and deploying it to judge related sibling models. "We introduce “Sibling Modeling”"
- Sigmoid: Logistic function mapping real-valued inputs to probabilities in [0,1]. " is the sigmoid."
- Trajectory/spectral internal indicators: Heuristics summarizing how representations evolve across layers. "Trajectory/spectral internal indicators summarize cross-layer hidden-state dynamics"
- Zero-shot: Generalization to a task or setting without task-specific fine-tuning. "generalizes zero-shot to partial generations"
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging Gnosis’s lightweight, sequence-length–independent introspection on hidden states and attention maps to predict correctness with negligible overhead.
- Stronger output gating and escalation in production LLMs
- Sector: software, enterprise AI, consumer assistants
- What: Use Gnosis’s correctness score to gate responses, trigger abstention, add disclaimers, or escalate to a stronger model or human-in-the-loop when confidence is low.
- Tools/products/workflows: “CorrectnessScore API” integrated into LLM serving; confidence thresholds per task; escalation ladders across 1.7B/4B/8B/20B backbones; UI badge “likely incorrect—verifying.”
- Assumptions/dependencies: Access to internal hidden states and attention maps; thresholds tuned per domain; distribution alignment between training data and deployed tasks.
- Compute-aware control and early termination of failing chains-of-thought
- Sector: cloud AI platforms, MLOps, energy/cost management
- What: Stop long reasoning trajectories early when Gnosis indicates low correctness, or auto-route to stronger models before wasting tokens.
- Tools/products/workflows: “EarlyStopper for CoT”; token-budget policies driven by score; “AutoEscalate Ladder” that switches models at 40% completion if risk is high.
- Assumptions/dependencies: Hooking into generation loop; policy design to avoid premature stops; monitoring false negatives/positives.
- Lightweight reward-model replacement in ranking and evaluation
- Sector: model development, RLHF/RLAIF, inference-time selection
- What: Replace heavy 8B+ reward models with ~5M-param Gnosis for scoring candidate completions (math, QA, knowledge tasks).
- Tools/products/workflows: “Gnosis-RM” for single-pass scoring; re-rank multiple samples; integrate with self-consistency only when needed (confidence-weighted sampling).
- Assumptions/dependencies: Internal signal access; quality comparable to target reward models on chosen domains; automated ground-truth labeling for training.
- Sibling-model orchestration across a model family
- Sector: model routing, service reliability
- What: Train Gnosis on a small backbone (e.g., 1.7B) and deploy the same head (zero-shot) to judge larger siblings (4B, 8B) for routing and quality control.
- Tools/products/workflows: “RouteByGnosis” to score outputs from multiple family members; family-aware routers that consider model style (Thinking vs Instruct).
- Assumptions/dependencies: Shared architecture and generation style; degraded transfer when styles diverge.
- Reliability-aware Retrieval-Augmented Generation (RAG)
- Sector: enterprise knowledge management, customer support
- What: If Gnosis indicates low correctness, increase retrieval depth, re-query, or ask clarifying questions before responding.
- Tools/products/workflows: “RetrieveDepth Controller” adjusting top-k/top-p retrieval; query reformulation triggered by low score; fallback to human agent.
- Assumptions/dependencies: RAG pipeline integration; domain calibration; ground-truth availability for initial Gnosis training.
- Calibration dashboards and automated QA for LLM deployments
- Sector: MLOps, compliance
- What: Track AUROC, Brier Skill Score, ECE in production using Gnosis’s probabilities; auto-flag drifts or domains with poor calibration.
- Tools/products/workflows: “Calibration Monitor” in observability stack; per-skill calibration audits; alarms for distribution shift.
- Assumptions/dependencies: Logging of predicted scores; occasional labeled checks; privacy-preserving storage of traces.
- Academic data curation and benchmark generation
- Sector: academia, LLM evaluation
- What: Auto-label correctness on generated answers to build clean datasets, filter noisy rationales, and bootstrap new benchmarks without human annotation.
- Tools/products/workflows: “AutoLabeler” to accept/reject synthetic answers; “Noise Filter” for process datasets (math steps, QA rationales).
- Assumptions/dependencies: Reliable ground-truth answer keys; awareness of domain shift; not a substitute for human review in nuanced tasks.
- Education: tutors that “know when they’re unsure”
- Sector: education technology
- What: Math/QA tutors that flag low-confidence steps, propose checking work, or escalate to a detailed explanation or a stronger model.
- Tools/products/workflows: Step-level uncertainty highlights; adaptive hinting when score drops; session-level escalation policies.
- Assumptions/dependencies: Task-specific thresholds; careful UX to avoid over-refusal; guardrails for student-facing content.
- Software engineering assistants with risk-aware workflows
- Sector: software development
- What: Gate risky code suggestions; when Gnosis scores low, auto-run unit tests, ask for specification, or route to a more capable model.
- Tools/products/workflows: CI triggers conditioned on correctness score; “Confidence→Test Budget” mapping; code review auto-escalation.
- Assumptions/dependencies: Integration with developer tools; non-trivial mapping between general correctness and code validity; domain-specific tuning.
- Finance and healthcare decision-support disclaimers and triage
- Sector: finance, healthcare
- What: Use Gnosis to pre-screen LLM outputs, adding disclaimers or routing to human experts when correctness risk is high.
- Tools/products/workflows: Risk-flagged summaries; human triage workflows; audit logs of correctness scores.
- Assumptions/dependencies: Strict regulatory constraints; domain validation required; Gnosis should not be the sole authority for safety-critical decisions.
Long-Term Applications
These applications require further research, validation across domains, broader vendor support for internal signals, or integration into training and governance pipelines.
- Universal cross-architecture introspection heads
- Sector: model platforms, open/closed model ecosystems
- What: Develop Gnosis variants that generalize across unrelated architectures and styles (beyond sibling families).
- Tools/products/workflows: “Universal Gnosis Head” shipped with model SDKs; standardized internal-signal APIs.
- Assumptions/dependencies: Vendor cooperation to expose hidden states/attention; robust domain-transfer techniques.
- Integrated training with introspection as an auxiliary objective
- Sector: model training, calibration research
- What: Co-train LLMs to produce more separable internal correctness cues, improving calibration and early detection natively.
- Tools/products/workflows: Auxiliary losses optimizing ECE/BSS; curriculum emphasizing process reliability; regularization for interpretable internal circuits.
- Assumptions/dependencies: Training access to core models; large-scale experimentation; avoiding overfitting to training domains.
- Fine-grained step-level process reward modeling
- Sector: reasoning models, RLHF/RLAIF
- What: Use internal signals to score intermediate reasoning steps, guiding search and reinforcement learning more efficiently than external PRMs.
- Tools/products/workflows: “StepScore Head” supervising chain-of-thought; compute-aware branching; early pruning of failing steps.
- Assumptions/dependencies: Reliable step extraction; robust mapping between internal cues and step correctness; careful alignment with task objectives.
- Energy-aware datacenter scheduling and carbon reduction
- Sector: cloud infrastructure, sustainability
- What: Use early failure detection to reduce wasted tokens and route only promising queries to expensive models, lowering energy use.
- Tools/products/workflows: “Confidence-aware Scheduler”; per-region carbon-aware routing; SLOs tied to correctness thresholds.
- Assumptions/dependencies: Fleet-wide orchestration; accurate score-to-quality mapping; telemetry and governance.
- Safety-critical deployments with certified introspective gating
- Sector: regulated industries (healthcare, legal, public policy)
- What: Develop standards where introspective correctness scores inform automated refusal, human review requirements, and audit compliance.
- Tools/products/workflows: Policy templates; certification frameworks; audit trails of internal scores and decisions.
- Assumptions/dependencies: Regulatory buy-in; extensive domain validation and post-market surveillance; robust fail-safes.
- Multi-agent LLM orchestration with self-awareness
- Sector: autonomous agents, enterprise automation
- What: Agents coordinate based on introspective confidence, delegating tasks to peers or tools when they predict failure.
- Tools/products/workflows: Confidence-mediated task graphs; agent swarms with “refuse-escalate-collaborate” behaviors.
- Assumptions/dependencies: Stable agent interfaces; avoidance of feedback loops; strong evaluation across complex workflows.
- Auditable AI with introspection logs for governance
- Sector: compliance, AI assurance
- What: Persist internal correctness signals for forensic analysis (why a model replied, when it escalated/abstained).
- Tools/products/workflows: “Introspection Ledger”; dashboards linking scores to actions; policy verification tools.
- Assumptions/dependencies: Privacy-preserving trace capture; storage policies; standard formats.
- Domain-specialized heads (medical, legal, scientific)
- Sector: healthcare, law, research
- What: Train Gnosis heads on domain-specific traces to improve reliability cues tailored to specialized reasoning and terminology.
- Tools/products/workflows: “MedGnosis,” “LegalGnosis” modules; controlled deployment with human oversight.
- Assumptions/dependencies: High-quality labeled domain datasets; rigorous validation; cross-institutional collaboration.
- Data curation at scale for synthetic training corpora
- Sector: model building, data engineering
- What: Filter synthetic data by introspective correctness to reduce noise in supervised fine-tuning or distillation pipelines.
- Tools/products/workflows: “Confidence Filter” in data pipelines; active learning loops selecting uncertain examples for human review.
- Assumptions/dependencies: Alignment between score and data utility; avoidance of bias reinforcement; monitoring diversity.
- Self-healing reasoning loops
- Sector: advanced reasoning systems
- What: Use internal cues to adapt decoding (e.g., adjust attention locality, prompt scaffolding, or tool calling) to rescue failing trajectories mid-generation.
- Tools/products/workflows: Dynamic prompt rewriting; on-the-fly retrieval/tool invocation based on score dips; adaptive decoding parameters.
- Assumptions/dependencies: Robust causal links between internal signals and recoverable errors; careful control to avoid oscillations.
Global assumptions and dependencies across applications
- Internal access: Many closed models do not expose hidden states or attention maps; adoption in proprietary settings requires vendor APIs or on-prem models.
- Domain calibration: Scores trained on math/QA may need re-training or calibration for specialized domains (healthcare, legal, code).
- Style alignment: Transfer is strongest within families and similar generation styles (Thinking→Thinking); style mismatch reduces accuracy.
- Policy tuning: Thresholds and escalation logic must be tuned to balance false positives/negatives and user experience.
- Safety boundaries: Gnosis should not be the sole arbiter for safety-critical decisions; use as a triage signal within human-in-the-loop workflows.
- Privacy and logging: Storing internal traces requires privacy-aware design and potentially significant observability engineering.
Collections
Sign up for free to add this paper to one or more collections.

