Lie to Me: Knowledge Graphs for Robust Hallucination Self-Detection in LLMs
Abstract: Hallucinations, the generation of apparently convincing yet false statements, remain a major barrier to the safe deployment of LLMs. Building on the strong performance of self-detection methods, we examine the use of structured knowledge representations, namely knowledge graphs, to improve hallucination self-detection. Specifically, we propose a simple yet powerful approach that enriches hallucination self-detection by (i) converting LLM responses into knowledge graphs of entities and relations, and (ii) using these graphs to estimate the likelihood that a response contains hallucinations. We evaluate the proposed approach using two widely used LLMs, GPT-4o and Gemini-2.5-Flash, across two hallucination detection datasets. To support more reliable future benchmarking, one of these datasets has been manually curated and enhanced and is released as a secondary outcome of this work. Compared to standard self-detection methods and SelfCheckGPT, a state-of-the-art approach, our method achieves up to 16% relative improvement in accuracy and 20% in F1-score. Our results show that LLMs can better analyse atomic facts when they are structured as knowledge graphs, even when initial outputs contain inaccuracies. This low-cost, model-agnostic approach paves the way toward safer and more trustworthy LLMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Lie to Me: Knowledge Graphs for Robust Hallucination Self-Detection in LLMs — Explained Simply
1) What is this paper about?
This paper is about making AI chatbots (like the ones that answer your questions) better at noticing when they accidentally “make things up.” That problem is called hallucination: the AI says something that sounds believable but isn’t true. The authors show a simple trick to help AIs check their own answers more carefully by turning those answers into small, connected “fact maps” called knowledge graphs. Using these fact maps helps the AI catch mistakes more reliably.
2) What questions did the researchers ask?
- Can adding a “fact map” (a knowledge graph) help an AI detect when it’s hallucinating?
- Does this work both when the AI checks itself once (single-sample) and when it compares multiple versions of its answer (multi-sample)?
- Which self-checking method works best with this “fact map” idea?
- Is this approach cheap, simple, and usable with different AIs?
3) How did they do it?
Think of an AI’s answer like a paragraph that may include several small facts. Instead of judging the entire paragraph at once, the researchers break it into tiny, simple fact pieces and check each one. Here’s the idea:
- What’s a knowledge graph?
- Imagine a mind map made of small facts. Each fact is a triple: subject–relation–object. For example: “Saturn – has – rings.” Each subject or object is a dot (an “entity”), and each relation is a line linking them. This turns a long answer into a set of clear, checkable facts.
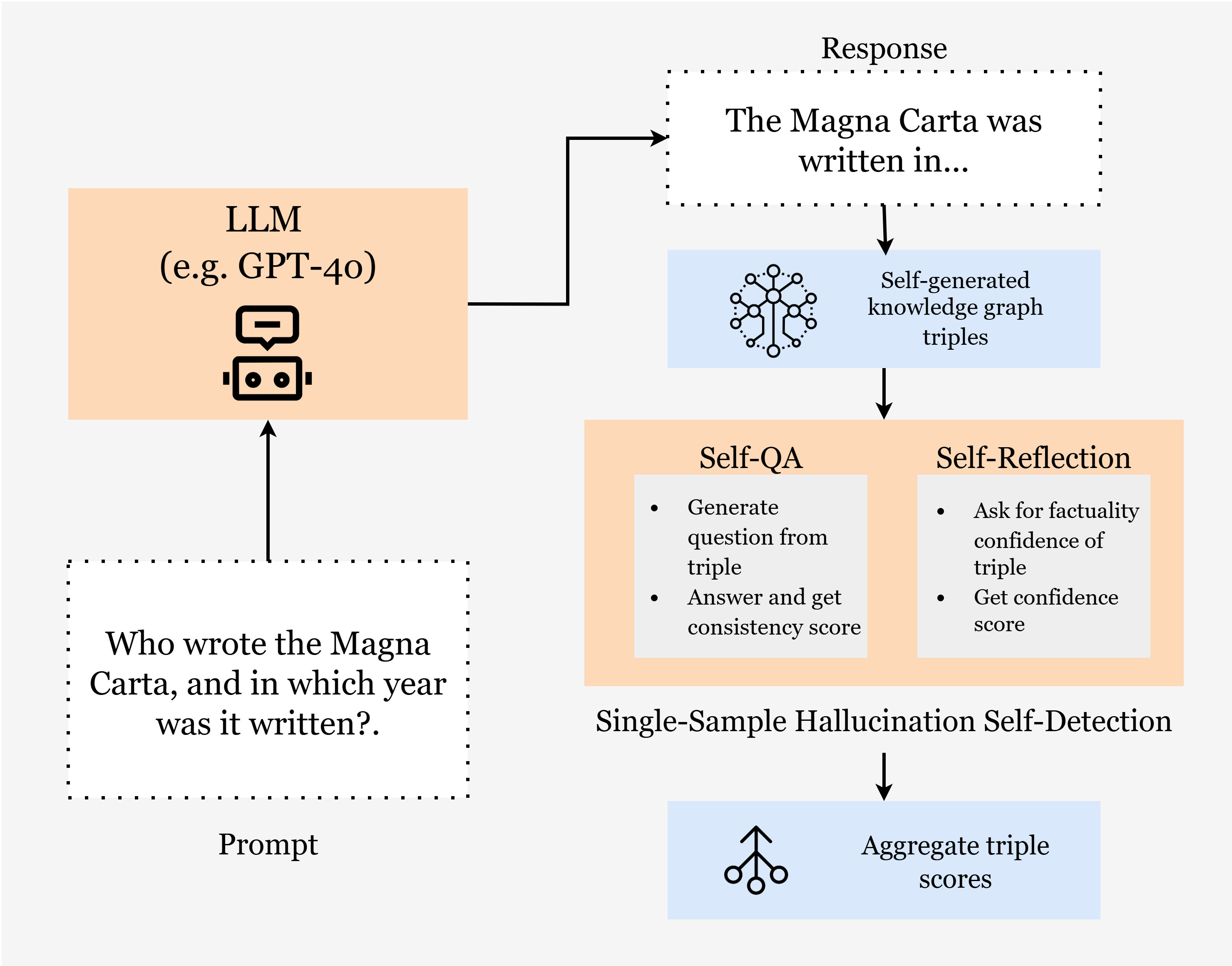
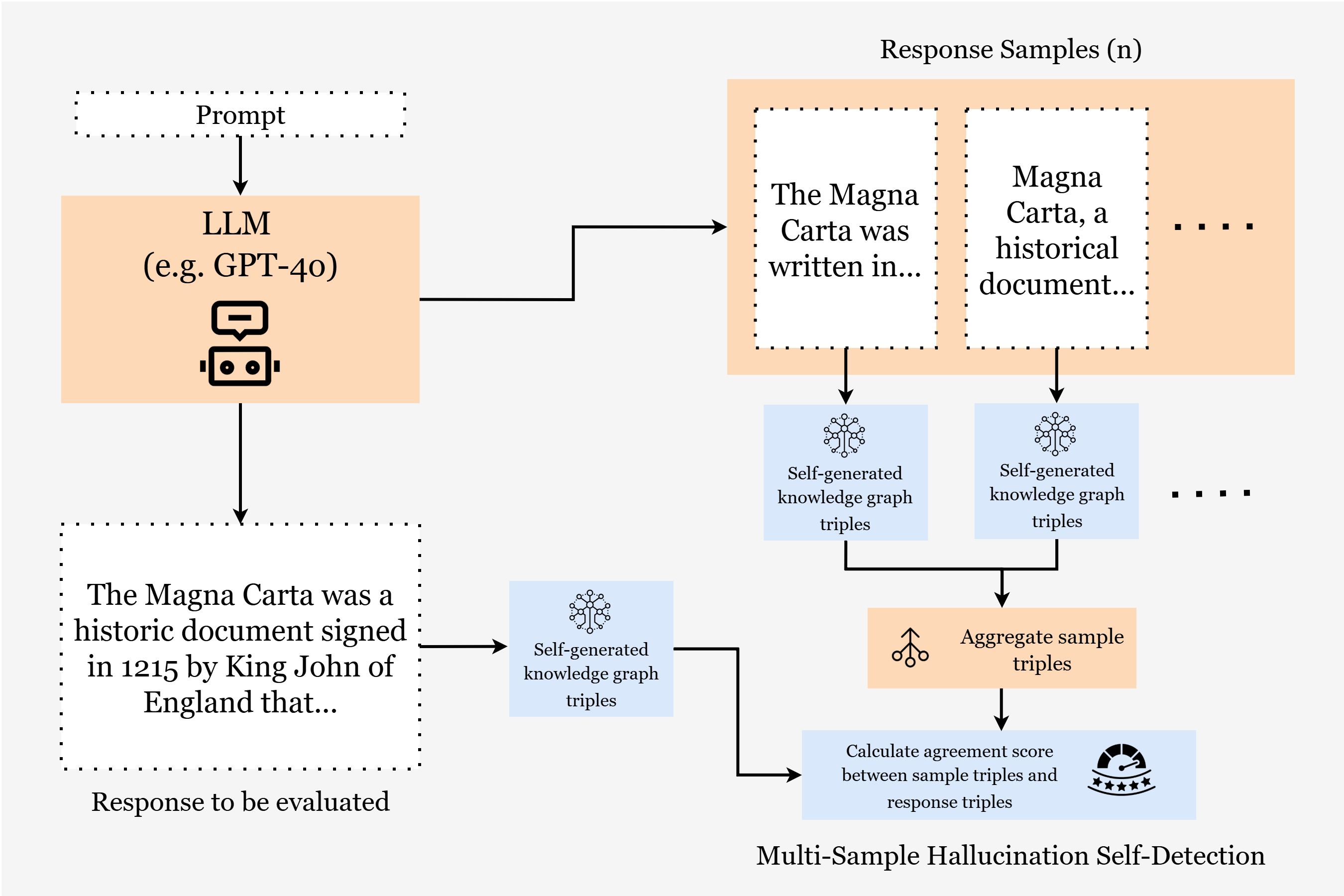
- Step 1: Turn the AI’s answer into a knowledge graph.
- The AI extracts triples like (subject, relation, object) from its own answer. This creates a neat list of facts.
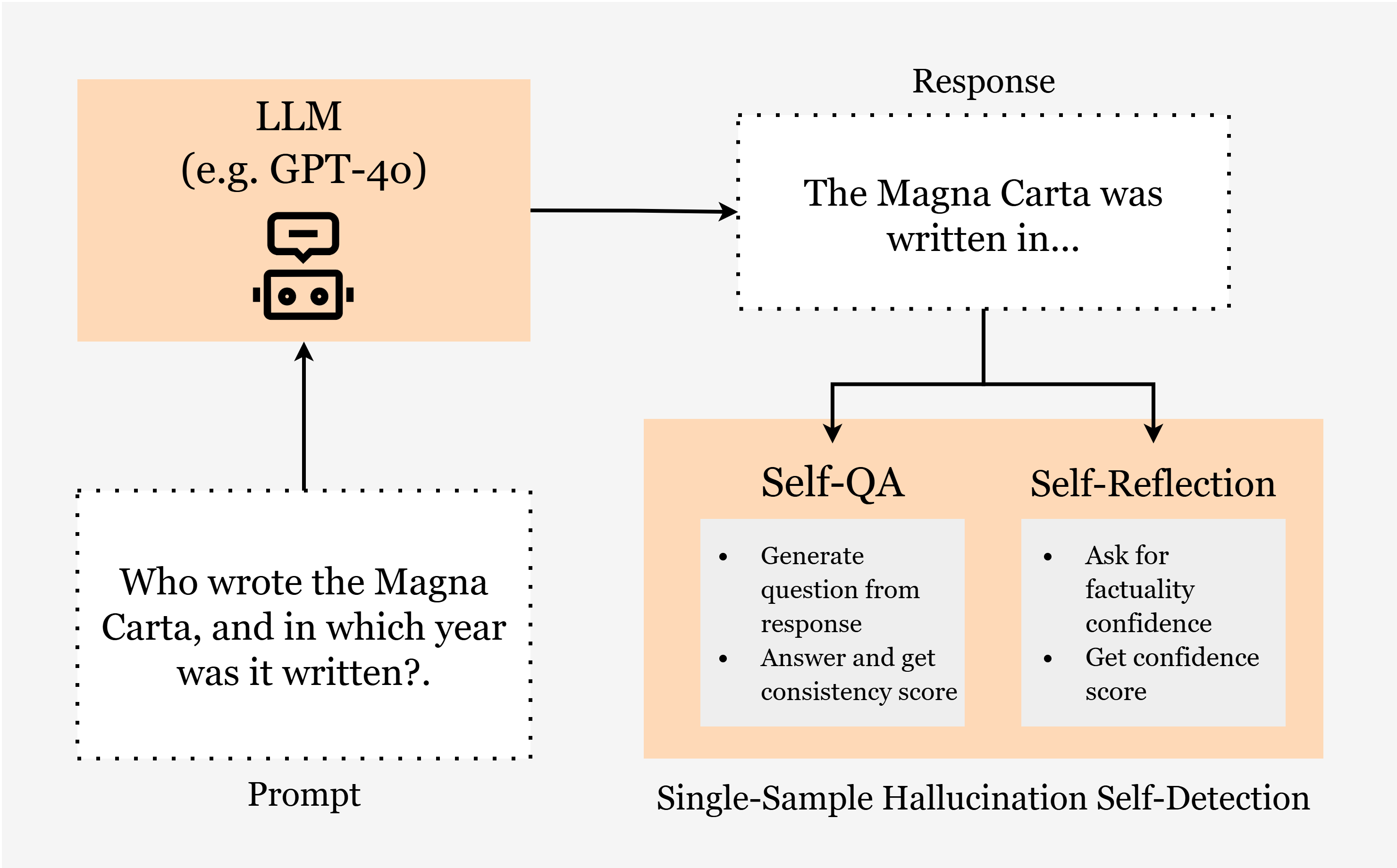
- Step 2: Check facts instead of the whole sentence.
- Single-sample methods (one self-check pass):
- Self-Questioning: The AI writes a question about each fact (“Does Saturn have rings?”), answers it, then gives a score for how consistent the answer is with the original claim. Lower score = more likely a hallucination.
- Self-Confidence: The AI simply rates how confident it is in each fact (from 0 to 1). Lower confidence = more likely a hallucination.
- For both, the final score for the whole answer is the average of all fact scores.
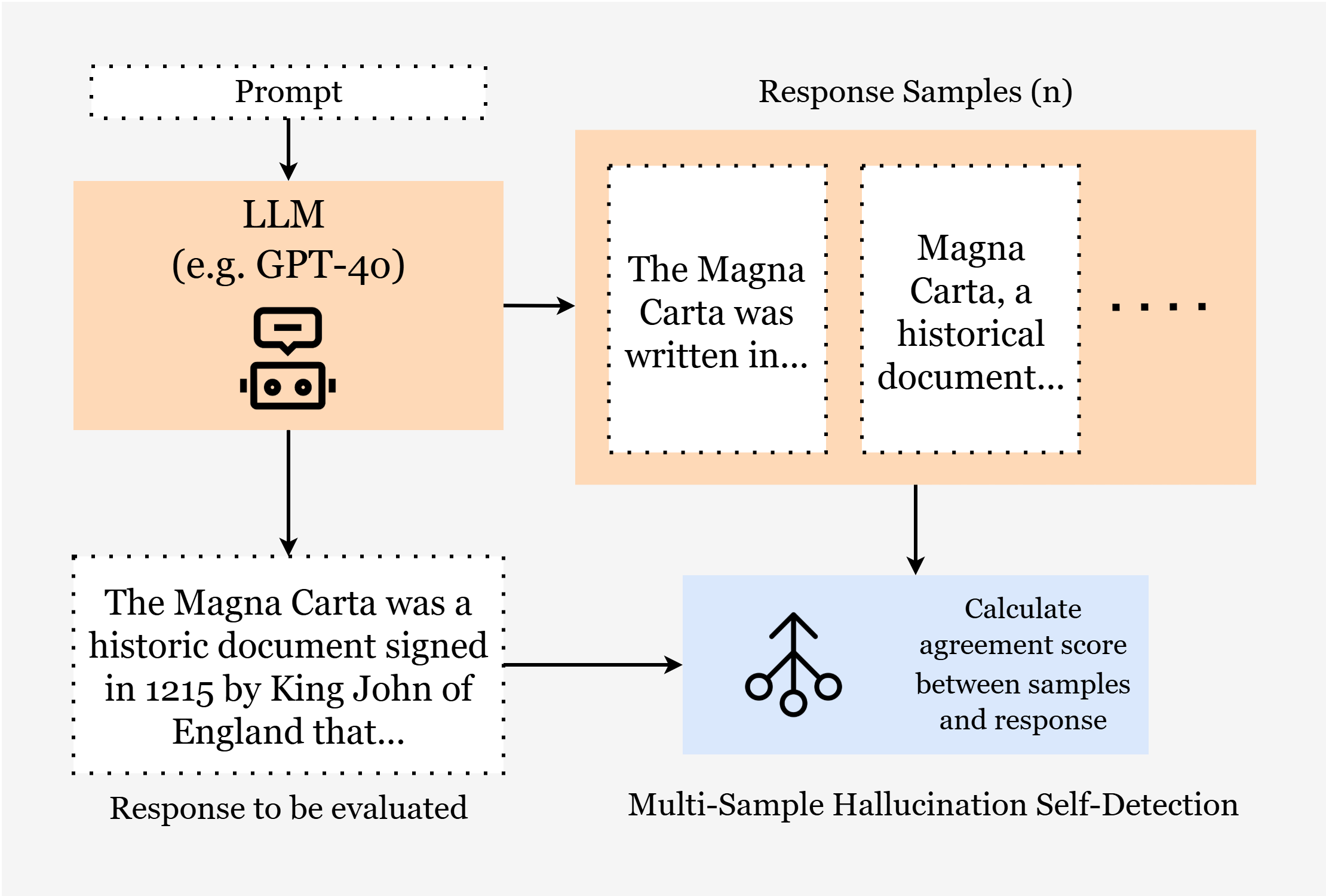
- Multi-sample method (compare many versions):
- SelfCheckGPT: The AI generates the same answer multiple times in different ways, then compares them. If the versions agree on the facts, that’s a good sign. With knowledge graphs, the AI compares fact-to-fact instead of paragraph-to-paragraph, which is clearer and fairer.
- What did they test on?
- Two strong AI models: GPT-4o and Gemini 2.5 Flash.
- Two datasets:
- SimpleQA: short factual questions.
- WikiBio GPT-4o: a new, carefully built set of 501 sentences with a balanced mix of true and false statements, made from real GPT-4o outputs. They release this dataset to help others test methods more fairly.
4) What did they find, and why does it matter?
Key takeaways:
- Knowledge graphs help a lot. Adding the “fact map” boosted results across the board. The method improved accuracy by up to about 16% and F1-score by up to about 20% compared to strong baselines (including SelfCheckGPT). In simple terms: the AI got much better at spotting when it was wrong.
- Fact-level checking beats whole-paragraph guessing. Breaking answers into small facts makes it easier to spot exactly where things go wrong.
- Self-Confidence worked best overall. Asking the AI to rate how sure it is—fact by fact—gave the strongest results. Self-Questioning also improved the most when knowledge graphs were added.
- Multi-sample wasn’t always worth the extra cost. Generating many versions of an answer and comparing them didn’t beat the best single-check methods when the AI was already pretty stable. Using knowledge graphs made multi-sample better, but single-sample with fact maps was often strong enough.
- It’s simple and cheap. No retraining or special tools are needed. You just add one extra step: turn the answer into a set of small facts and score them.
Why it matters:
- More trustworthy AI: If AIs can better detect their own mistakes, they can warn users, ask for more info, or try again—reducing misinformation.
- Clearer reasoning: Fact maps show exactly which claim is shaky, helping people and systems fix errors faster.
5) What’s the bigger impact?
This study shows a practical path to safer, more reliable AI:
- It’s model-agnostic: Works with different AIs, even closed ones like GPT and Gemini.
- It’s low-cost and easy to add: No training needed—just prompt the AI to turn its answer into a fact map and score each fact.
- It encourages better habits: Instead of treating an answer as one big blob, we should break it into facts and check each one.
Limitations and next steps:
- Tests used English datasets; future work should try other languages and topics.
- The authors tuned decision cutoffs to get the best results; future work could improve scoring so cutoffs are more consistent.
- They also plan to explore more cases where the AI must compare many samples.
In short: Turning AI answers into simple, connected facts—then checking those facts—helps AIs catch their own mistakes more reliably. This could make AI tools safer and easier to trust in schoolwork, research, and real-world decisions.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, formulated to guide future research.
- Applicability to long-form and multi-sentence outputs: the method assumes single-sentence responses; how to build and score KGs over multi-paragraph outputs with coreference, discourse links, and cross-sentence dependencies is not addressed.
- KG construction fidelity: no quantitative evaluation of triple extraction accuracy (entity detection, relation labeling, coreference resolution, entity disambiguation), nor error analysis of KG quality.
- Robustness to KG errors: the impact of noisy or incorrect triples on self-detection scores is unmeasured; sensitivity analyses or error propagation studies are absent.
- Aggregation strategy: averaging per-triple scores assumes independence and equal importance; weighting, graph-level reasoning, or handling interdependent triples is unexplored.
- Normalization by graph size: how detection performance scales with the number of extracted triples per output (e.g., very short vs very long answers) and whether normalization biases decisions is unclear.
- Calibration and threshold generalization: thresholds are tuned per method and dataset for best-case accuracy/F1; out-of-the-box calibration, cross-dataset generalization, and robust threshold selection are not evaluated.
- Computational cost and latency: the added overhead of per-triple prompting (questioning or confidence) is not quantified; scalability to long outputs and production settings is not assessed.
- Multi-sample parameterization: the effect of the number of samples (n=20 fixed), temperature/top-p choices, and alternative sampling strategies on performance and cost is not studied.
- Similarity function choices (KG-SelfCheckGPT): reliance on SBERT embeddings is unexamined; ablations with other encoders, triple representations, or relation-aware similarity are missing.
- Baseline coverage: comparisons are limited to SelfCheckGPT and two single-sample methods; stronger zero-resource detectors (e.g., InterrogateLLM, MetaQA, beam-search variants) are not benchmarked.
- Model diversity: evaluation uses two closed-source LLMs; applicability to open-source models, smaller models, or domain-specific LLMs is untested.
- Cross-lingual generalization: experiments are limited to English; performance on morphologically rich, low-resource, or non-Latin-script languages remains unknown.
- Domain transfer: effectiveness on specialized domains (medical, legal, code, scientific claims) and tasks (summarization, reasoning-heavy QA, math) is not evaluated.
- Non-factual hallucinations: detection beyond atomic factual claims (e.g., logical fallacies, reasoning errors, contradictions, pragmatic misstatements) is not addressed.
- Mechanistic explanation: why KG structuring “activates” latent reasoning is hypothesized but not empirically probed (e.g., layer-level or representation-level analyses).
- Annotation reliability (WikiBio GPT-4o): the dataset is curated by a single expert; inter-annotator agreement, guidelines, and bias assessments are missing.
- Dataset balance effects: SimpleQA balancing and curated sample selection may introduce distribution shifts; the impact on reported gains is not analyzed.
- Adversarial robustness: performance under adversarial or misleading prompts, hedging language, and safety-critical scenarios is unknown.
- Numerical/temporal claims: handling of numbers, dates, units, and temporal relations in triples, and dedicated verification strategies for quantitative facts, is not explored.
- External KG integration: combining self-generated KGs with external sources (while maintaining black-box constraints) for verification and improved detection remains open.
- Entity linking: lack of canonical entity IDs or alias resolution may degrade triple alignment and similarity; the benefits of integrating EL/NER/linking are untested.
- Confidence elicitation reliability: self-reported confidence may be miscalibrated; post-hoc calibration, mapping functions, or learning-based calibration are not investigated.
- Prompt sensitivity: reproducibility across prompt templates and the sensitivity of KG extraction and scoring prompts to wording is not reported.
- Statistical methodology: details on how 95% CIs were computed, multiple-comparisons control, and power analyses are missing; significance across subgroups is not examined.
- Error taxonomy: which hallucination types are most/least detected with KG augmentation is not analyzed; fine-grained failure cases and qualitative error studies are absent.
Practical Applications
Immediate Applications
The following applications can be deployed with current tooling and workflows, leveraging the paper’s model-agnostic, low-cost KG-augmented self-detection methods (Self-Confidence and Self-Questioning) and the released dataset/code.
- Software/AI Tooling — KG-guardrail middleware for LLM apps
- Use case: Wrap any LLM generation with a KG-augmented self-detection step that scores atomic claims (triples) and gates responses (e.g., block, revise, or route to retrieval when confidence is low).
- Sector: Software, enterprise AI platforms
- Tools/workflows: LangChain/LlamaIndex plugin “KG-Guard”; “AtomicFactScore API” that returns per-triple confidence and an overall score; fallback policy orchestration (e.g., call RAG, ask clarifying questions).
- Assumptions/dependencies: Reliable triple extraction; threshold calibration per model/domain; English-first; minimal latency budget for the extra prompt(s).
- Customer Support & CRM — Safer chatbots with fact-level gating
- Use case: For support bots, highlight or redact low-confidence claims; auto-escalate to human when per-triple scores fall below a threshold; add dynamic disclaimers.
- Sector: Customer experience, retail, telecom
- Tools/workflows: “Hallucination Heatmap” UI to mark questionable statements; agent routing policies; compliance logging of flagged claims.
- Assumptions/dependencies: Domain prompts tuned for entity/relation extraction; access to logs for audit; acceptable UX impact of disclaimers.
- Enterprise Knowledge Bases & RAG — Pre-answer self-detection
- Use case: Before returning an answer, run KG-based self-confidence; if low, trigger retrieval or reformulation; reduce false confident answers in internal Q&A tools.
- Sector: Enterprise IT, documentation portals
- Tools/workflows: RAG pipeline policy node: detect → retrieve → re-answer; per-triple gating to drive targeted retrieval on specific entities.
- Assumptions/dependencies: Integration with retrieval stack; content coverage in KB; prompt alignment across domains.
- Editorial/Summarization Workflows — Fact-level annotation for reviewers
- Use case: In newsrooms or marketing, show per-claim confidence to editors; require human confirmation for low-confidence claims before publication.
- Sector: Media, marketing, legal content ops
- Tools/workflows: “Claim Cards” embedded in CMS; batch scoring for generated summaries; export flagged claims to fact-check queues.
- Assumptions/dependencies: Adequate precision of triples in long-form outputs; editor acceptance; latency acceptable in production pipelines.
- Healthcare Triage Assistants — Non-diagnostic safety checks
- Use case: For patient-facing triage chat, flag any medical claim with low confidence; force citations or direct users to trusted resources.
- Sector: Healthcare (patient education, triage)
- Tools/workflows: Per-claim gating + citation prompts; escalation to clinician review; audit trails for safety teams.
- Assumptions/dependencies: Strict non-diagnostic use; domain-adapted prompts; regulatory review; robust disclaimers; not a substitute for clinical verification.
- Financial Drafting & Reporting — Compliance-aware gating
- Use case: For investment notes or internal memos, block or annotate low-confidence claims before circulation; log flagged statements for compliance reviews.
- Sector: Finance, compliance
- Tools/workflows: “Factuality Gate” in document drafting tools; per-claim audit exports; integration with model risk management dashboards.
- Assumptions/dependencies: Domain prompts for financial entities; policy-defined thresholds; human-in-the-loop acceptance.
- Education & Learning — Critical reading and writing assistants
- Use case: Student writing coach that highlights questionable claims and recommends sources or revision; educator tools for grading LLM-generated content.
- Sector: Education, EdTech
- Tools/workflows: Classroom add-ons showcasing per-claim confidence; guided revision flow; assignment-level dashboards of flagged content.
- Assumptions/dependencies: Alignment to curricula; privacy considerations for student data; domain coverage beyond general knowledge.
- AI Governance & Audit — Factuality risk metrics in production
- Use case: Integrate AUC-PR/F1 and per-claim risk scores into AI risk monitoring; alert when hallucination rates rise; support model governance reports.
- Sector: Enterprise governance, compliance, risk
- Tools/workflows: Observability dashboards; weekly risk reports; policy triggers tied to confidence thresholds.
- Assumptions/dependencies: Stable scoring prompts; per-model threshold tuning; storage for telemetry.
- Content Moderation & Misinformation Triage
- Use case: Flag questionable factual claims in user-generated content assisted by LLMs; prioritize items for human moderation.
- Sector: Social platforms, marketplaces
- Tools/workflows: Batch KG-extraction + scoring; moderation queues sorted by per-claim risk.
- Assumptions/dependencies: False positive tolerance; domain adaptation to trending topics; scalability of batch processing.
- Daily Life — Personal drafting assistants with “truth annotations”
- Use case: Browser or email add-in that annotates generated text with confidence per claim; prompts users to verify low-confidence assertions.
- Sector: Consumer productivity
- Tools/workflows: Lightweight extension calling KG scoring API; toggle to reveal hidden claims or request sources.
- Assumptions/dependencies: API availability; acceptable latency; user willingness to engage with annotations.
- MLOps — Test harnesses and continuous evaluation
- Use case: Add KG-based self-detection to model regression tests; track improvements after fine-tuning or prompt changes.
- Sector: Machine learning engineering
- Tools/workflows: CI pipelines with per-claim scoring; canary tests on new prompts; trend analysis of hallucination metrics.
- Assumptions/dependencies: Stable benchmarks; the paper’s WikiBio GPT-4o dataset for quick checks; team capacity to maintain thresholds.
- Academia — Benchmarking with released dataset/code
- Use case: Use the curated WikiBio GPT-4o dataset and open-source implementation to evaluate new self-detection variants or domains.
- Sector: Academic research
- Tools/workflows: Reproduce ablations; extend to multilingual datasets; compare single vs. multi-sample strategies.
- Assumptions/dependencies: English bias in current resources; access to closed-model APIs or strong open models.
Long-Term Applications
These applications require further research, scaling, domain adaptation, or regulatory alignment before broad deployment.
- Clinical Decision Support with Verified KGs
- Use case: Combine KG self-detection with domain medical knowledge bases to produce clinical-grade, per-claim attestations in provider tools.
- Sector: Healthcare
- Tools/workflows: KG fusion with trusted ontologies (e.g., SNOMED, UMLS), external verification steps, formal safety cases.
- Assumptions/dependencies: Regulatory approval; rigorous validation; multilingual/medical terminology coverage; liability frameworks.
- Legal Drafting & E-Discovery — Claims-level attestations
- Use case: Claims-level confidence and provenance trails for legal summaries; automated alerts on risky assertions; structured audit of changes.
- Sector: Legal tech
- Tools/workflows: “Factuality Passport” per document; integration with e-discovery platforms; provenance-aware KG graph stores.
- Assumptions/dependencies: High-precision entity linking in legal domains; admissibility standards; careful human review.
- Financial Advisory & Trading — High-stakes gating
- Use case: KG-based self-detection as pre-trade or pre-publication gate; enforce confidence thresholds and source validation.
- Sector: Finance
- Tools/workflows: Risk engines that combine per-claim scores with external data feeds; quantitative thresholds tied to governance policies.
- Assumptions/dependencies: Tight latency constraints; explainability requirements; integration with market data; regulatory compliance.
- Multilingual and Domain-General Expansion
- Use case: Extend KG extraction and scoring to multiple languages, specialized fields (biotech, law, engineering), and noisy inputs.
- Sector: Global enterprises, public services
- Tools/workflows: Language-specific prompts; domain ontologies; cross-lingual entity linking; multilingual embeddings for comparisons.
- Assumptions/dependencies: Robust cross-lingual triple extraction; local regulations; model performance parity across languages.
- Model Training Objectives — KG-aware learning
- Use case: Train or fine-tune models with objectives that reward accurate fact decomposition and penalize inconsistent triples.
- Sector: AI research, foundation model development
- Tools/workflows: Synthetic KG supervision; RLHF with fact-level rewards; curriculum learning around atomic facts.
- Assumptions/dependencies: Access to model weights; high-quality labeled KGs; stability of training; potential trade-offs with fluency.
- Standardization & Certification — Claims-level factuality standards
- Use case: Regulatory or industry standards that require per-claim confidence logging and self-detection for high-risk LLM applications.
- Sector: Policy, standards bodies (NIST, ISO, EU AI Act)
- Tools/workflows: Conformance test suites; minimum AUC-PR/F1 thresholds; audit-ready telemetry schemas.
- Assumptions/dependencies: Consensus definitions of “hallucination”; sector-specific thresholds; certified evaluation tooling.
- Provenance-Rich LLM UIs — “Fact Cards” in consumer products
- Use case: Mainstream chat interfaces that expose claims, confidence, and sources, enabling users to drill into individual assertions.
- Sector: Consumer software
- Tools/workflows: UI patterns for per-claim expanders; privacy-preserving provenance storage; accessibility accommodations.
- Assumptions/dependencies: Usability validation; user trust; product differentiation and adoption.
- Multi-Agent Factuality Pipelines
- Use case: Orchestrate agents where one extracts KGs, one self-scores, and another validates key claims via external tools (search, calculators, databases).
- Sector: Software automation, research assistants
- Tools/workflows: Agent frameworks; tool-use policies; selective external verification triggered by low per-claim confidence.
- Assumptions/dependencies: Tool reliability; cost/latency budgets; error compounding across agents; robust failure handling.
- Privacy-Preserving On-Device Self-Detection
- Use case: Run KG extraction and atomic scoring locally without sending sensitive content to cloud APIs.
- Sector: Edge/enterprise privacy
- Tools/workflows: On-device small models for triple extraction; local embeddings; limited-context optimization.
- Assumptions/dependencies: Capable local models; hardware acceleration; careful compression and distillation.
- Benchmark Ecosystem Growth
- Use case: Expanded, multilingual, domain-specific datasets and shared baselines for KG-based self-detection, with standardized metrics.
- Sector: Academia, standards, open-source
- Tools/workflows: Community-led dataset curation; leaderboards; inter-model comparability studies.
- Assumptions/dependencies: Sustainable funding and governance; diverse annotator pools; clear licensing.
Cross-cutting assumptions and dependencies
- Triple extraction quality: The approach assumes LLMs can reliably extract (subject, relation, object) triples; performance varies by domain and language.
- Threshold calibration: Optimal thresholds differ across models, tasks, and sectors; ongoing tuning is needed.
- Language and context scope: Current experiments are English and single-sentence oriented; longer contexts and multilingual settings require further validation.
- Cost/latency trade-offs: Each extra prompt or embedding comparison adds overhead; production deployments must budget for this.
- Model heterogeneity: Closed vs. open models may respond differently to scoring prompts; prompt robustness is critical.
- Human-in-the-loop: High-stakes sectors (healthcare, finance, law) require human review and formal governance regardless of improved self-detection metrics.
Glossary
- AUC-PR: Area Under the Precision–Recall Curve; a threshold-independent metric for evaluating binary classifiers, especially under class imbalance. "boosting F1 scores by up to 20.4\% and AUC-PR by up to 21.0\% relative improvement for popular models like GPT-4o and Gemini 2.5 Flash."
- BERTScore: A semantic similarity metric that compares texts using contextual embeddings from BERT to assess agreement. "The BERTScore (named from the original reference \cite{manakul-etal-2023-selfcheckgpt}) for the output is computed as the average semantic similarity between and the samples, where a higher score indicates greater agreement and hence higher confidence in factuality:"
- Chain-of-Thought verification: A prompting strategy that has models reason step-by-step to verify their outputs. "We emulate the Chain-of-Thought verification and slightly modify it for the hallucination self-detection objective."
- Chain-of-Verification (CoVe): A procedure where the model generates verification questions about its own answers and then answers them to reduce hallucinations. "CoVe (Chain-of-Verification) \cite{dhuliawala-etal-2024-chain} shows that having a model draft questions about its own answer and then answer them reduces hallucinations."
- Confidence elicitation: Prompting a model to report its own confidence score in the factual accuracy of its output. "Confidence elicitation provides a direct, interpretable signal of the modelâs belief in its own outputs, without requiring intermediate questionâanswer steps."
- Cosine distance: A vector-space measure of dissimilarity based on the cosine of the angle between two embedding vectors. "The similarity is computed computed using the cosine distance between the embeddings obtained by processing the triplets with SBERT \cite{all-MiniLM-L6-v2}."
- Entity and relation extraction: The NLP task of identifying entities and the labeled relations between them from text. "complex multi-step pipelines previously used for entity and relation extraction \cite{zhang-soh-2024-edc} are no longer necessary."
- Factuality detection: Methods that identify objective inaccuracies in model outputs using external knowledge sources. "By objective, methods target either factuality detection \cite{wang-etal-2024-factuality}, which identifies objective inaccuracies using external knowledge, or faithfulness detection, which evaluates alignment with the given context and the modelâs internal knowledge, often through confidence-based analysis \cite{sahoo-etal-2024-comprehensive}."
- Faithfulness detection: Techniques that assess whether a model’s output aligns with the given context and its internal knowledge. "By objective, methods target either factuality detection \cite{wang-etal-2024-factuality}, which identifies objective inaccuracies using external knowledge, or faithfulness detection, which evaluates alignment with the given context and the modelâs internal knowledge, often through confidence-based analysis \cite{sahoo-etal-2024-comprehensive}."
- Hallucination self-detection: Detecting hallucinations using the same model that generated the content, without external resources. "we examine the use of structured knowledge representations, namely knowledge graphs, to improve hallucination self-detection."
- Knowledge graph: A structured representation where entities are nodes and relations are labeled edges, enabling reasoning over facts. "Knowledge graphs (KGs) provide structured representations in which entities are nodes and relations are labelled edges."
- Multi-sample methods: Approaches that generate multiple outputs for the same prompt and compare them for consistency to detect hallucinations. "Multi-sample methods detect hallucination by generating multiple responses from the same LLM given an identical input, and comparing consistency with the response under evaluation."
- NeMO Guardrails: A guardrails framework for LLMs whose multi-sample input concatenation can exceed context limits. "Other multi-sample methods, like NeMO Guardrails \cite{dong2024buildingguardrailslargelanguage}, are incompatible with our approach because they require concatenating multiple samples into a single input, exceeding the LLMâs context length."
- SBERT embeddings: Sentence-BERT embeddings used to compute semantic similarity between texts or triples. "In our case, we use the SBERT embeddings \cite{all-MiniLM-L6-v2} to compute similarity."
- SelfCheckGPT: A black-box, zero-resource method that detects hallucinations by comparing an output against multiple stochastic samples. "SelfCheckGPT is a black-box, zero-resource hallucination detection method that measures the consistency of an LLMâs output by comparing it against multiple stochastic samples generated for the same prompt."
- Self-Confidence: A single-sample method that directly elicits the model’s own confidence score for its output’s factual accuracy. "Self-Confidence: Another single-sample approach for hallucination self-detection is to directly elicit confidence scores from the model itself, inspired by recent research \cite{lin2022teachingmodelsexpressuncertainty}."
- Self-Contradictory Reasoning: A single-sample technique that checks for contradictions within the model’s own reasoning to flag hallucinations. "as exemplified by Self-Contradictory Reasoning \cite{liu-etal-2024-self-contradictory} and verbalised confidence analysis \cite{kale-vrn-2025-line}."
- Self-Questioning: A single-sample method where the model generates a verification question about its own output, answers it, and scores consistency. "Self-Questioning: We emulate the Chain-of-Thought verification and slightly modify it for the hallucination self-detection objective."
- Semantic similarity: A measure of meaning-level closeness between two texts, often computed via embeddings. "where denotes any semantic similarity function."
- Triple (subject, relation, object): A fact representation in knowledge graphs specifying a relation between two entities. "extract a structured set of factual triples in the form of (subject, relation, object) from each output."
- Zero-resource: Methods that require no external knowledge bases, annotations, or tools beyond the model itself. "SelfCheckGPT is a black-box, zero-resource hallucination detection method that measures the consistency of an LLMâs output by comparing it against multiple stochastic samples generated for the same prompt."
Collections
Sign up for free to add this paper to one or more collections.

