- The paper introduces a latent variable EM framework modeling rationale generation as a bridge between questions and answers.
- It develops a filtered gradient-based EM algorithm with various rationale sampling schemes, notably demonstrating the superiority of prompt posterior sampling (PPS).
- Empirical tests on ARC, MMLU, and OpenBookQA show that PPS improves accuracy, efficiency, and output conciseness.
Recent advances in LLMs have highlighted the utility of explicit rationale generation (chain-of-thought, CoT) for enhancing LLM reasoning performance. This work recasts reasoning within a formal latent variable model (LVM) framework, assigning the rationale z as the latent variable connecting question x to answer y⋆, resulting in the Markov structure x→z→y⋆. This brings the modeling of reasoning closer to probabilistic graphical models. The principal benefit is that, by modeling the rationale as a latent variable, the learning dynamics favor improvements in generalization and reasoning capacity, compared to directly mapping x to y⋆.
Expectation-Maximization Algorithm for LLMs
Building on the LVM, the paper derives an EM-style training objective for learning to reason. Classical EM alternates between an E-step (estimating the posterior over latent variables) and an M-step (maximizing expected complete-data likelihood). For LLMs, however, neither step can be performed analytically; posteriors are intractable and expectations must be approximated via sampling. The authors propose a filtered gradient-based variant, where rationale-answer pairs are sampled and only correct-answer pairs are used for parameter updates—mapping exactly onto reward-weighted fine-tuning with a binary reward.
Mathematically, the update becomes:
θ(k)←θ(k−1)+η(k)i=1∑Nr(y^i,yi⋆)∇θlogπ(z^i,y^i∣xi;θ)
where r(y^i,yi⋆) is an indicator of answer correctness. The expectation over rationale generation is approximated by a single Monte Carlo sample per datapoint, and the underlying "proposal" distribution q(⋅∣x,y⋆;θ)—i.e., how rationales are sampled—is shown to be a key determinant of the quality of learning.
Comparative Study of Rationale Sampling Schemes
The paper rigorously compares several rationale sampling schemes within its EM framework:
- Rejection Sampling (Budget M): Samples rationale-answer pairs using the base model, accepts only if the answer is correct, up to M attempts.
- Self-Taught Reasoning (STaR): Combines a single rejection sample with a fallback "rationalization" prompt that directly exposes the true answer, supporting rationale generation conditioned on ground-truth.
- Prompt Posterior Sampling (PPS): Generates rationales with an explicit hint of the correct answer in the prompt, then filters for answer correctness. PPS corresponds to the rationalization stage of STaR, but is used exclusively and rigorously analyzed in this work for the first time.
Experiments are deployed on ARC, MMLU, and OpenBookQA using Llama3.2-3B-Instruct and Qwen2.5-3B-Instruct, over 2000 questions per benchmark. Four sampling variants are compared: rejection sampling (M=1), rejection sampling (M=5), STaR, and PPS.
Empirical Results and Quantitative Analysis
PPS is empirically shown to yield higher test accuracy than all alternatives across models and datasets. Notably, PPS succeeds without increasing data usage, suggesting improvements are due to higher-quality rationales rather than mere quantity. Rationales generated via PPS are shorter, more concise, and more informative, as indicated by character-based analysis and qualitative examples.
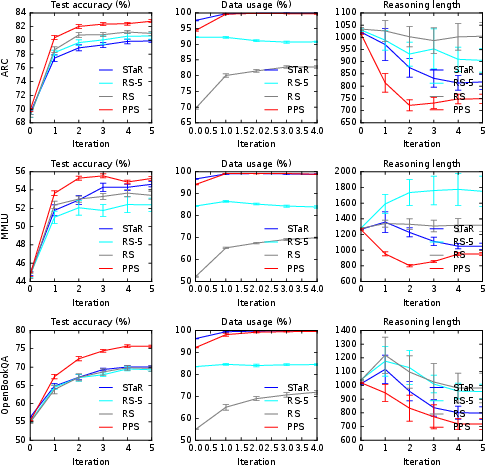
Figure 1: Test accuracy, data usage, and reasoning length for four sampling schemes on Llama3.2-3B-Instruct.
The accuracy of all schemes increases with iterations before plateauing, showing effective iterative self-improvement. Data usage (percentage of accepted rationale-answer pairs) is not necessarily higher for PPS, pointing to its efficiency in reasoning. The PPS rationales demonstrate superior conciseness and comprehensiveness, unlike longer and more verbose outputs in other methods.
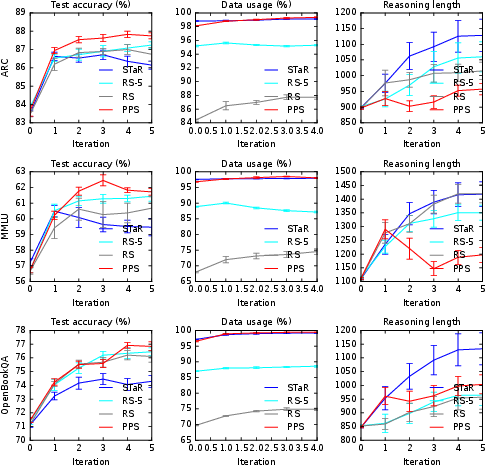
Figure 2: Test accuracy, data usage, and reasoning length for four sampling schemes on Qwen2.5-3B-Instruct.
Similar trends hold for Qwen2.5-3B-Instruct, but with higher achieved accuracy overall, consistent with the model's baseline performance. PPS again outperforms other schemes across all metrics.
This formalization bridges policy-gradient RL and statistical EM. The paper establishes new bounds connecting reward-maximization with filtered EM, showing the update tightness when the proposal matches the base policy. The analysis also connects to recent research on data filtering, reward shaping via top-K rationale selection, and MCMC samplers targeting sharpened distributions, but formally grounds these sampling/filtering methods using latent variable EM.
From a theoretical standpoint, the work develops a general recipe for filtered self-improvement algorithms in LLM reasoning—rather than seeking increasingly complex policy-gradient variants, careful design of the rationalization proposal is critical. The EM lens clarifies the interplay between rationale generation, answer correctness, and sample efficiency.
Practical Implications and Future Directions
Practically, the findings indicate that prompt-level interventions—especially conditioning rationale sampling on ground-truth answers—substantially improve reasoning in LLMs. This has direct implications for curriculum design, feedback-in-the-loop learning, and dataset augmentation practices in LLM training. PPS-style rationale conditioning proves highly effective and should be considered as a routine step for multi-step reasoning tasks during supervised fine-tuning.
Future developments may address several open problems:
- Sampling mismatches between train-time (with ground-truth-conditioned rationales) and test-time (question-only conditioning) distributions.
- Extending the filtered EM and PPS frameworks to broader reasoning tasks beyond multi-choice QA, such as program synthesis, open-domain deduction, and causal inference.
- Quantifying rationale diversity and its relationship to generalization, using richer statistical latent variable models.
- Investigating the convergence properties and sample complexity of filtered EM in overparameterized LLM settings.
Conclusion
This paper provides a highly formal latent variable perspective on learning to reason in LLMs, concretizing the connection between EM and reward-weighted fine-tuning. The rationale sampling scheme emerges as a major factor in performance, and prompt posterior sampling—conditioning rationale generation on ground-truth answers in the prompt—demonstrates clear empirical superiority. The results have practical significance for designing data collection and training protocols for LLM reasoning. The paper’s formalization further opens new avenues for EM-based and self-improving learning algorithms in large-scale LLMs.

