Published 26 Sep 2025 in cs.CL, cs.AI, and cs.LG | (2509.22637v1)
Abstract: We introduce a variational reasoning framework for LLMs that treats thinking traces as latent variables and optimizes them through variational inference. Starting from the evidence lower bound (ELBO), we extend it to a multi-trace objective for tighter bounds and propose a forward-KL formulation that stabilizes the training of the variational posterior. We further show that rejection sampling finetuning and binary-reward RL, including GRPO, can be interpreted as local forward-KL objectives, where an implicit weighting by model accuracy naturally arises from the derivation and reveals a previously unnoticed bias toward easier questions. We empirically validate our method on the Qwen 2.5 and Qwen 3 model families across a wide range of reasoning tasks. Overall, our work provides a principled probabilistic perspective that unifies variational inference with RL-style methods and yields stable objectives for improving the reasoning ability of LLMs. Our code is available at https://github.com/sail-sg/variational-reasoning.
The paper introduces a unified probabilistic framework that models reasoning as latent 'thinking traces' to improve final answer accuracy.
It leverages an IWAE-style multi-trace objective and forward KL training to stabilize and debias reasoning optimization.
Empirical results show improved performance and stability across diverse benchmarks, outperforming existing methods by up to 160% on complex tasks.
Variational Reasoning for LLMs: A Probabilistic Framework for Reasoning Optimization
Introduction
This paper presents a unified probabilistic framework for training LLMs to perform complex reasoning, leveraging variational inference to treat "thinking traces" as latent variables. The approach formalizes reasoning as a joint generative process over both the intermediate thinking steps and the final answer, and introduces a variational posterior to efficiently sample high-quality reasoning paths. The framework generalizes and connects existing supervised finetuning (SFT), rejection sampling finetuning (RFT), and reinforcement learning (RL) methods, revealing implicit biases and providing tighter, more stable training objectives.
Probabilistic Formulation and Variational Inference
The reasoning process is decomposed into a thinking trace z and an answer y, with the model πθ(z,y∣x) generating both given a question x. The marginal probability of producing a correct answer is Pθ(Y∣x)=z∑πθ(Y∣z,x)πθ(z∣x), where Y is the set of correct answers. Direct maximization of logPθ(Y∣x) is intractable due to the sum over all possible traces.
To address this, the paper derives an evidence lower bound (ELBO) using a variational posterior qϕ(z∣x,y′) conditioned on the question and an answer hint y′. The ELBO is:
Gradients are computed using normalized importance weights ρk, with practical estimators for πθ(Y∣zk,x) based on either accuracy or geometric mean of token likelihoods to mitigate length bias and variance.
Forward KL Training for Variational Posterior
Empirical observations show that reverse KL optimization of qϕ can lead to collapse or shortcut reasoning. The paper proposes optimizing qϕ via forward KL divergence:
DKL(Pθ(z∣Y,x)∥qϕ(z∣x,y′))
This is implemented as weighted SFT, sampling traces from πθ and weighting by answer accuracy, which stabilizes training and prevents collapse.
Connections to SFT, RFT, and RL
The framework reveals that RFT and binary-reward RL objectives are equivalent to forward KL optimization weighted by model accuracy, which biases training toward easier questions. In contrast, the variational reasoning objective treats all questions more evenly, reducing this bias. The analysis extends to GRPO and general RL reward shaping, showing that reward normalization further amplifies the bias toward high-accuracy (easy) questions.
Implementation Details
Model Architecture: The framework is implemented on Qwen2.5 and Qwen3 model families, with separate models for the reasoning policy πθ and the variational posterior qϕ.
Training Pipeline: Initial models are trained via SFT, followed by variational posterior training with forward KL, and final reasoning model training using the IWAE-style objective and weighted SFT.
Sampling and Weighting: For each question, multiple traces are sampled from qϕ, and importance weights are computed using accuracy-based or geometric mean estimators.
Prompt Engineering: Robustness to prompt templates is demonstrated, with both "Solution/Explanation" and "Solution/Thought" formats yielding similar results.
Computational Considerations: Scaling the number of traces K improves performance but increases computational cost, requiring trade-offs in practice.
Empirical Results
Performance: The variational reasoning framework consistently outperforms strong baselines (Bespoke-Stratos, General-Reasoner, RLT) across math, code, and general reasoning benchmarks, with up to 160% improvement over base models and 8.5% over the best baseline on average accuracy.
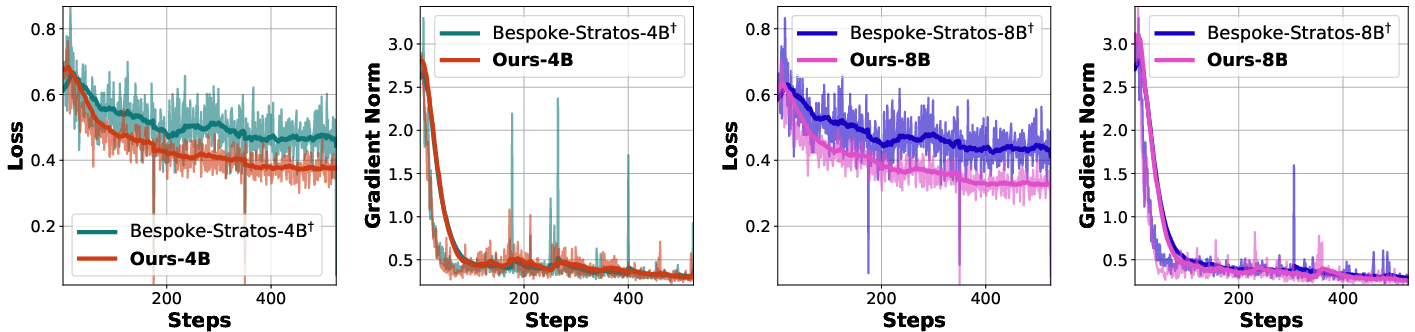
Stability: Training loss and gradient norms are more stable compared to baselines, attributed to adaptive importance weighting.
Figure 1: Training loss and gradient norm of different methods during Qwen3-Base model training, showing improved stability for variational reasoning.
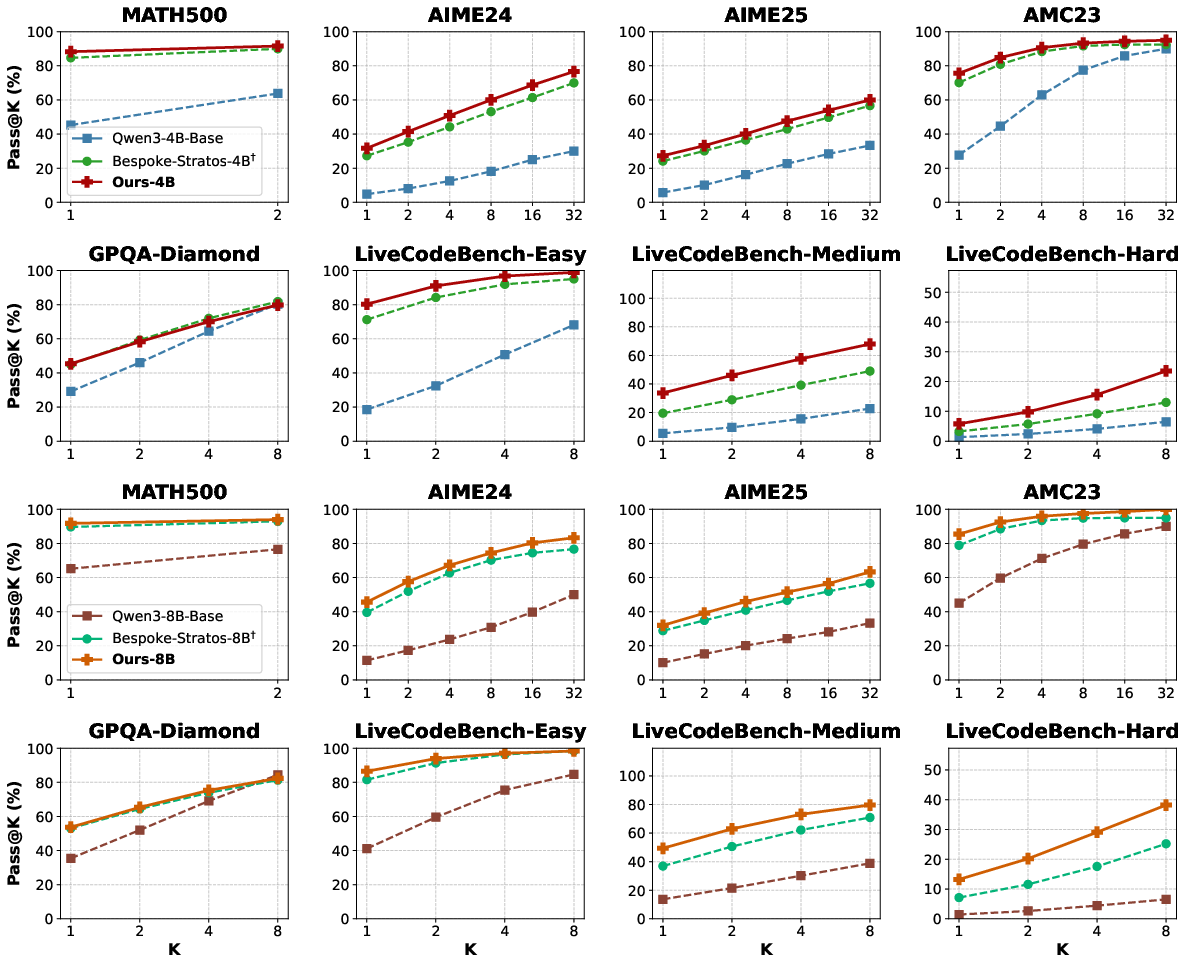
Pass@K Analysis: The advantage of variational reasoning increases with larger K on complex tasks, while diminishing on simpler or multiple-choice tasks.
Figure 2: Pass@K comparison of baselines versus variational reasoning, highlighting superior performance on complex benchmarks.
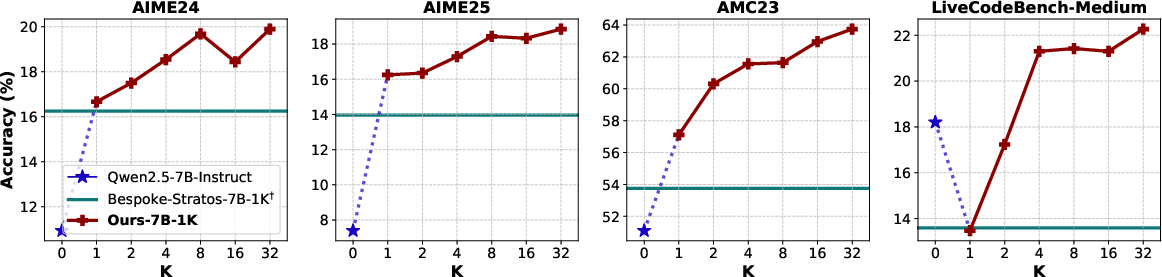
Scaling Effects: Increasing the number of sampled traces K yields further accuracy improvements, with diminishing returns at high K.
Figure 3: Effects of scaling up the number of thinking traces (K) on final model performance.
Estimator Ablations: Accuracy-based and geometric mean estimators outperform naive likelihood, validating theoretical analysis.
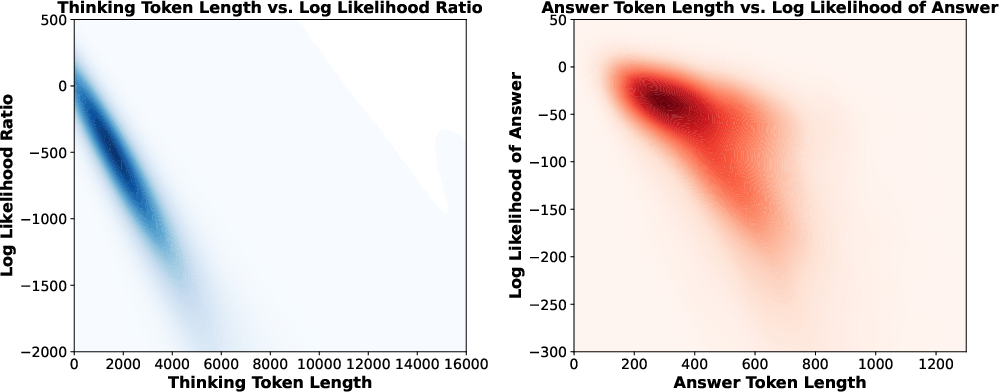
Length Bias: Density maps reveal strong correlation between trace length and likelihood ratios, justifying estimator choices.
Figure 4: Density maps of thinking token length versus log-likelihood ratio, and answer token length versus log-likelihood, illustrating length bias.
Theoretical and Practical Implications
The framework provides a principled probabilistic perspective that unifies variational inference and RL-style methods for reasoning. It clarifies the implicit biases in existing approaches and offers stable, scalable objectives for improving reasoning ability. The analysis of estimator variance and bias informs practical implementation choices, and the connection to reward shaping in RL suggests avenues for debiasing and more equitable training.
Future Directions
Potential extensions include multi-round training (beyond T=1), richer posterior designs for answer hints, and application to broader domains. The framework's generality suggests applicability to agentic reasoning, program synthesis, and scientific discovery tasks.
Conclusion
The variational reasoning framework advances the training of reasoning LLMs by formalizing thinking traces as latent variables and optimizing via variational inference. It achieves strong empirical gains, improved stability, and theoretical clarity, while subsuming and debiasing existing SFT, RFT, and RL methods. This work lays the foundation for principled, scalable reasoning optimization in LLMs.