- The paper introduces a retrieval-augmented approach that decouples knowledge acquisition from rote memorization in PFMs.
- It employs a dynamic knowledge-store with dense retrieval, kNN-guided training, and output interpolation to improve zero-shot and few-shot performance.
- Empirical evaluations on NLP and vision benchmarks reveal enhanced robustness, reduced performance variance, and improved handling of long-tail data.
Retrieval-Augmented Prompt Learning for Pre-trained Foundation Models
Motivation and Context
Pre-trained foundation models (PFMs) are central to multimodal learning, supporting diverse domains including NLP and computer vision. The prompt learning paradigm enables effective task adaptation, particularly in data-scarce settings. However, conventional prompt learning is fundamentally parametric, which can result in compromised stability in generalization and an over-reliance on rote memorization, especially when handling atypical or rare examples and shallow data distributions.
To address these limitations, this paper presents a retrieval-augmented framework designed to decouple true knowledge acquisition from mere memorization. The method introduces a knowledge-store—an indexed key-value database constructed from training data embeddings—that is accessible across input, training, and inference. By enabling active retrieval of semantically similar instances, the system achieves a harmonized balance between memorization and generalization.
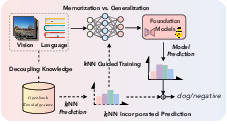
Figure 1: The framework decouples knowledge from memorization by constructing a retrievable knowledge-store, enabling dynamic reference during training and inference.
Methodological Framework
The core architecture consists of three components: a dense retriever for semantic indexing, kNN-guided training, and kNN-output interpolation for inference. The knowledge-store utilizes contextually encoded key-value tuples, where keys are prompt-based embeddings from the PFM encoder (updated dynamically as model parameters change) and values are associated label words.
For efficient lookup, the method leverages scalable inner product search via FAISS, ensuring real-time neighbor retrieval. The training pipeline incorporates kNN-derived difficulty signals by weighting the cross-entropy loss with focal-style adjustments based on instance classification correctness and neighbor distribution softmax probabilities. During inference, predictions are interpolated between the parametric model output and the non-parametric nearest-neighbor distribution, with a scaling factor controlling the degree of retrieval reliance.
For NLP, neural demonstrations—aggregated weighted neighbor embeddings—are concatenated at the embedding layer to boost class analogical learning. In computer vision, CLIP-based prompt learning is further augmented with retrieval from few-shot supervisions, restricting model training to prompt optimization rather than full encoder retraining.
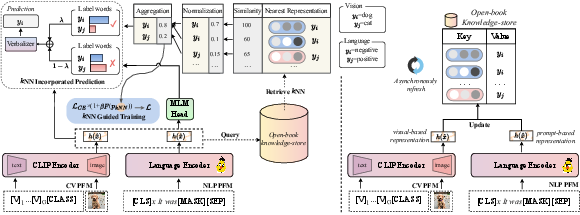
Figure 2: Schematic illustration of the retrieval-augmented prompting mechanism and flow through dense retriever, kNN training guidance, and kNN output interpolation.
Empirical Evaluation and Results
Extensive experiments demonstrate the efficacy of the proposed approach in both zero-shot and few-shot contexts over a suite of NLP and CV benchmarks:
- Few-shot Language Understanding: On tasks ranging from single-sentence classification (SST-2, MR, CR) to multi-class information extraction (FewNERD, SemEval, TACRED), retrieval-augmented prompt learning consistently surpasses state-of-the-art baseline prompt tuning (KnowPrompt, LM-BFF, KPT). Notably, the method exhibits reduced performance variance, improved generalization, and enhanced handling of long-tail distribution samples.
- Few-shot Visual Understanding: On nine public image classification datasets, the approach outperforms both CoOp and zero-shot CLIP, demonstrating clear advantages in scenarios with extremely limited training data. For example, the method achieves +10.48% over CoOp on FGVCAircraft and +2.67% on Food101 with only two training shots.
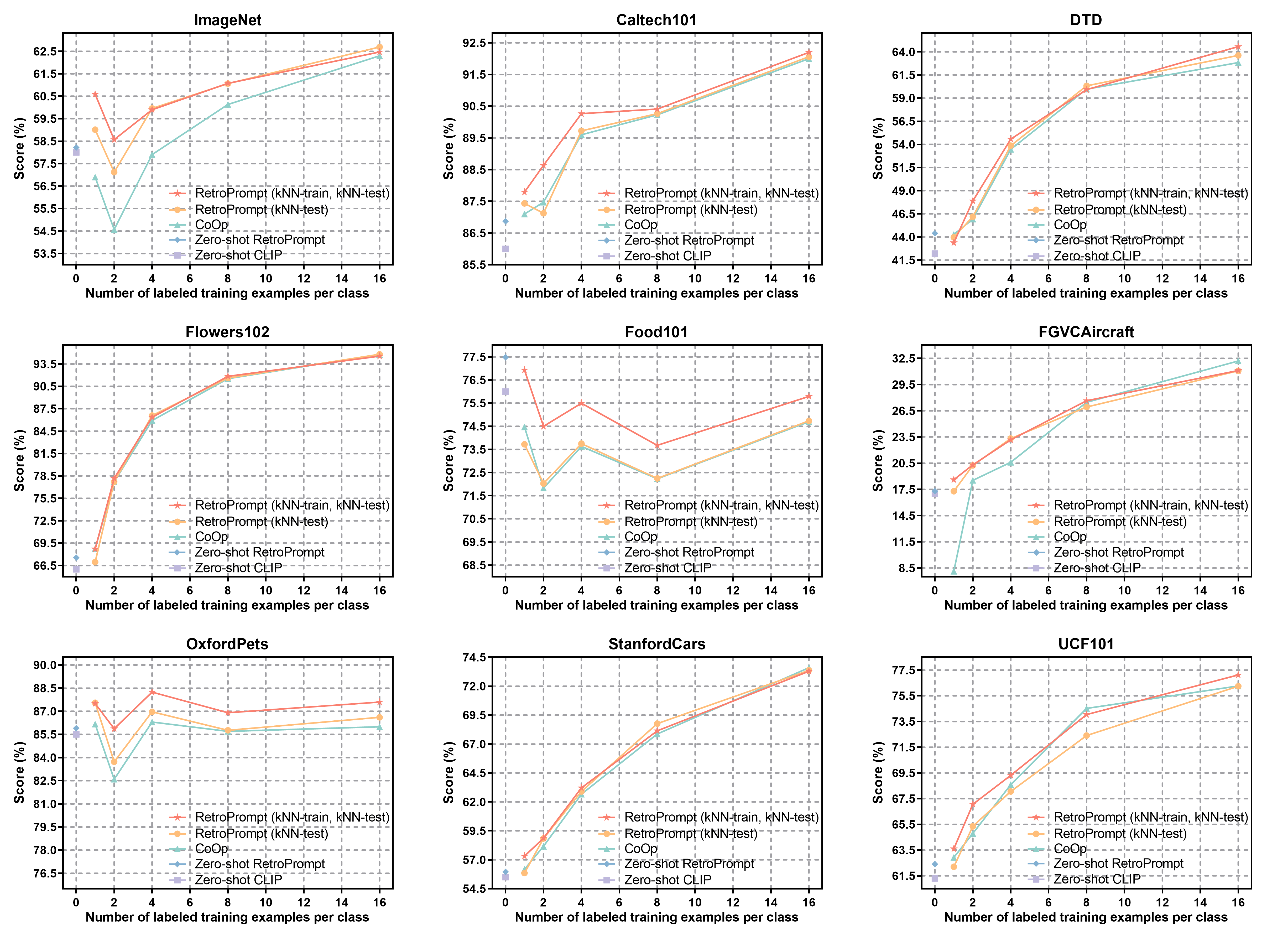
Figure 3: Comparative results on nine image classification datasets for zero-shot and few-shot settings, demonstrating gains from kNN-guided training and inference.
- Zero-shot Performance: The system exhibits robust zero-shot transfer using unlabeled training data and pseudo-labeling for datastore construction, outperforming dedicated self-training approaches (LOTClass) and knowledge-augmented methods (KPT).
- Fully-supervised Regimes: Retrieval-augmented prompting maintains competitive accuracy even in fully-supervised settings with pronounced long-tail distributions, validating its generalization by reducing overfitting to atypical instances.
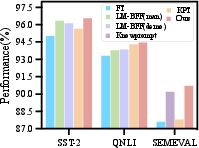
Figure 4: Performance comparison across fully-supervised paradigms, highlighting improved instance assimilation in long-tailed datasets.
Analysis of Memorization and Generalization
To probe deeper into the memorization mechanisms of PFMs, the paper incorporates influence function-based measures to quantify the memorization score for training samples. Results indicate a disproportionately higher memorization score for atypical examples, suggesting that conventional prompting and fine-tuning strategies favor recall over associative generalization. The retrieval-augmented method, by contrast, yields substantially lower memorization scores, indicating successful decoupling and superior generalization behavior.
Further, case analyses on the ImageNet dataset visualize retrieval impacts, confirming that kNN consistently augments both prediction correctness and grounding for hard instances. Instances where kNN predictions fail exert minimal adverse impact due to high underlying ground-truth probabilities in neighbor distributions.

Figure 5: Visualization of top-5 retrieved neighbors and prediction probability shifts on ImageNet samples.
Ablation and Component Analysis
Component ablations demonstrate that each retrieval mechanism—kNN in training, kNN in inference, neural demonstrations, and dynamic knowledge-store refresh—contributes additively to overall model performance. The prompt-based key features and inner-product similarity for kNN retrieval yield optimal results compared to CLS token or BM25-based alternatives.
Implications and Outlook
This retrieval-augmented prompting strategy establishes a compelling direction for model generalization, particularly under resource-constrained or distribution-shifting conditions. It affirms that explicit caching and retrievable contextualization of training signals empower PFMs to transcend the limitations of rote memorization, enhancing adaptability in both language and vision domains.
Practically, the method invites straightforward integration with existing prompt-tuning pipelines, offers low-bar adaptation for multimodal architectures, and is especially advantageous for settings where updating or extending knowledge is frequent. The retrieval overhead, however, introduces computational complexity and potential scalability issues for extreme-scale PFMs, necessitating further systems-level optimizations.
Theoretically, the decoupling of knowledge and memorization via non-parametric retrieval mechanisms suggests new research in hybrid learning architectures and the development of robust analogical reasoning modules across modalities.
Conclusion
Retrieval-augmented prompt learning provides a principled solution for decoupling knowledge from memorization in PFMs. By integrating dynamic retrieval during input, training, and inference, this framework consistently enhances generalization across NLP and CV tasks in zero-shot, few-shot, and fully-supervised regimes. Future studies may extend the approach to generative modeling, investigate scalability for ultra-large foundation models, and evaluate cross-lingual and multi-modal generalization.
(2512.20145)