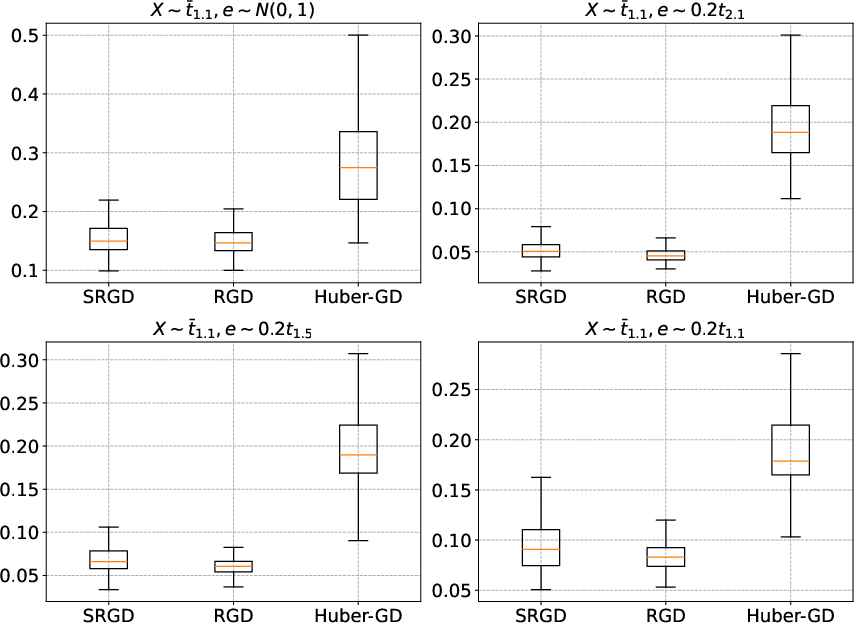Scale-Invariant Robust Estimation of High-Dimensional Kronecker-Structured Matrices
Published 22 Dec 2025 in stat.ME | (2512.19273v1)
Abstract: High-dimensional Kronecker-structured estimation faces a conflict between non-convex scaling ambiguities and statistical robustness. The arbitrary factor scaling distorts gradient magnitudes, rendering standard fixed-threshold robust methods ineffective. We resolve this via Scaled Robust Gradient Descent (SRGD), which stabilizes optimization by de-scaling gradients before truncation. To further enforce interpretability, we introduce Scaled Hard Thresholding (SHT) for invariant variable selection. A two-step estimation procedure, built upon robust initialization and SRGD--SHT iterative updates, is proposed for canonical matrix problems, such as trace regression, matrix GLMs, and bilinear models. The convergence rates are established for heavy-tailed predictors and noise, identifying a phase transition where optimal convergence rates recover under finite noise variance and degrade optimally for heavier tails. Experiments on simulated data and two real-world applications confirm superior robustness and efficiency of the proposed procedure.
The paper introduces a novel scale-invariant robust estimation procedure that decouples gradient scaling and truncation, ensuring consistent recovery in high dimensions.
The method employs Scaled Robust Gradient Descent (SRGD) and Scaled Hard Thresholding (SHT) to achieve statistically optimal convergence rates and accurate support recovery under heavy-tailed noise.
Empirical results on EEG classification and macroeconomic forecasting validate the framework’s superior robustness and efficiency compared to traditional non-robust methods.
Scale-Invariant Robust Estimation of High-Dimensional Kronecker-Structured Matrices
Overview and Motivation
This work proposes a robust, statistically optimal, and computationally scalable framework for estimation of high-dimensional matrices with Kronecker product structure under heavy-tailed distributions. The central technical challenge addressed is the confluence of three properties: the scaling ambiguity inherent in Kronecker factorizations, heavy-tailed predictors and noise, and the imposition of structured sparsity for interpretability in high dimensions.
Kronecker-structured models are widely used in multi-modal and matrix-variate data, where parsimony is induced by representing the coefficient as the sum of Kronecker products of smaller factors. However, such factorizations are non-identifiable up to scale, so classical robustification procedures—based on fixed thresholds for truncated gradients or loss modification—fail, as the magnitude of the gradients is arbitrarily distorted by parametrization choice. This leads to substantial statistical inefficiency and potential breakdown: either valid signal directions are truncated, or outliers are passed through, depending on the choice of scaling.
Furthermore, variable selection in the Kronecker regime requires support recovery invariant to rescalings, which is nontrivial, because naive hard thresholding (row-wise, as in standard IHT) can be arbitrarily manipulated by unidentifiable basis changes.
Scaled Robust Gradient Descent (SRGD) and Scaled Hard Thresholding (SHT)
The authors resolve the robustness-scaling conflict by introducing a three-step update rule: de-scaling, truncation, and re-scaling. At each SRGD iteration, gradients with respect to each factor are first de-scaled (by the inverse square root Gram matrix of the other factor), mapped to a scale-invariant space. Truncation is then performed with a fixed threshold in this normalized domain to remove heavy-tailed noise or extreme leverage points, before mapping the robustified update vector back to the original parameter space.
This operation achieves strict invariance to the Kronecker ambiguity, so the robustification threshold acts only on the statistical outliers, not on rescaling-induced artifacts. The approach is formalized for generic empirical loss minimization over rank-K Kronecker sums and is agnostic to the underlying distributional form (beyond moment requirements).
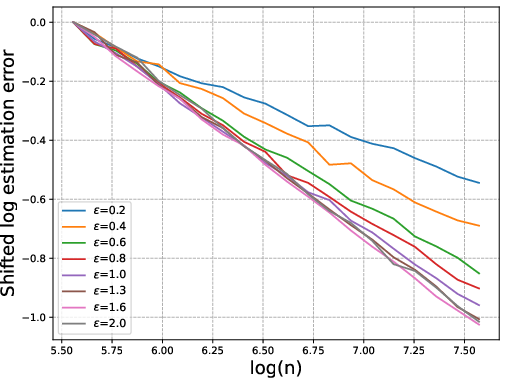
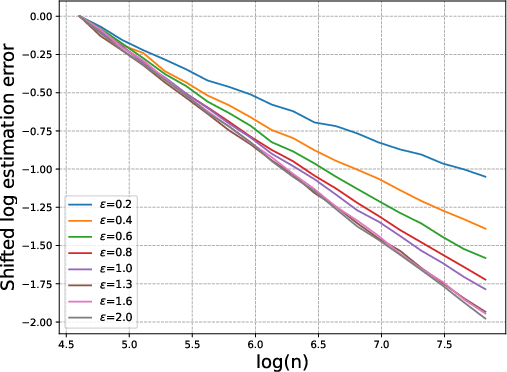
Figure 1: Log of the relative estimation error versus log(n) for varying tail indices ϵ. Steeper slopes confirm faster and theoretically predicted convergence, with match to O(n−ϵ/(1+ϵ)).
Enforcement of sparsity is handled by SHT, a hard thresholding operator applied after rescaling the factor matrices to norm-invariant versions, ensuring consistent support recovery of the underlying Kronecker factors regardless of choice of basis or parametrization.
Theoretical Analysis: Convergence and Minimax-Optimal Rates
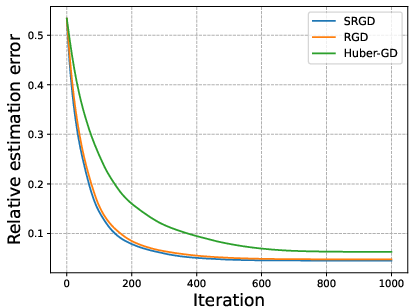
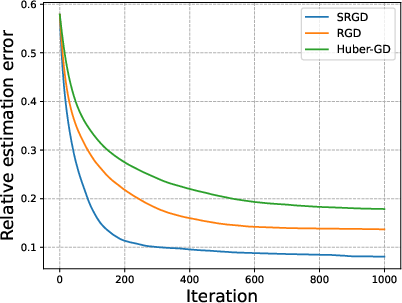
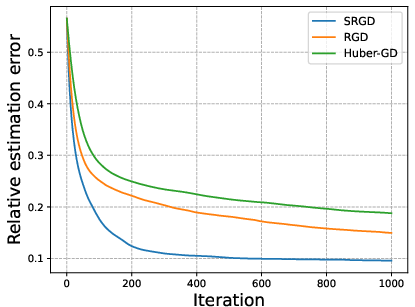
The analysis rigorously establishes that the SRGD–SHT framework achieves local linear convergence up to a statistical error floor, quantified by tail properties of the predictors and the noise. The factorization condition number has no effect on the convergence or stability, in contrast to conventional methods whose error deteriorates with ill-conditioning—confirmed both in theory and via ablation on the condition number κ.
Two fundamental phase transitions are precisely characterized:
For noise with finite variance (ϵ=1), the procedure achieves optimal parametric rate O(s/n) (where s is sparse support).
For heavier-tailed noise (ϵ<1), the error rate transitions to O(s1/2n−ϵ/(1+ϵ)), which matches the information-theoretic lower bounds for robust estimation under these conditions.
Figure 2: Relative estimation error versus iterations for increasing condition numbers κ. SRGD is strictly invariant to ill-conditioning, unlike alternatives.
The sample complexity is driven by the heavier tail between noise and predictors, confirming that robustification cannot overcome fundamentally insufficient data regularity, but does so optimally otherwise.
Empirical Evaluation: Simulated and Real Data Evidence
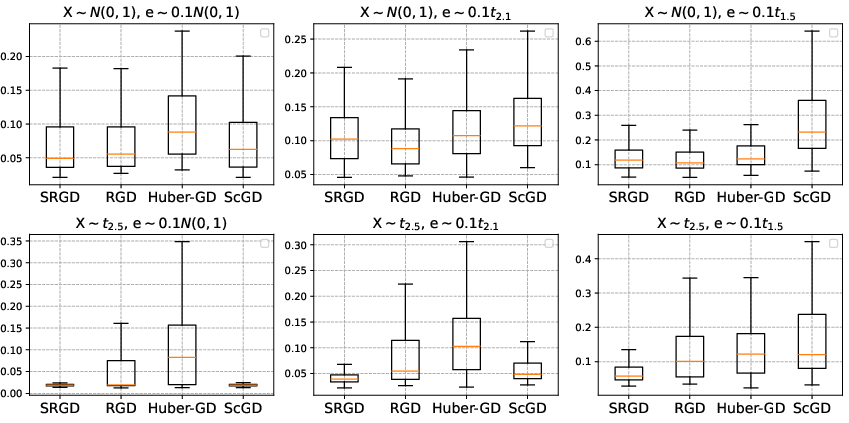
Comprehensive simulations validate all theoretical predictions. Estimation error in the SRGD procedure closely follows the predicted n−ϵ/(1+ϵ) rate, and independence from scaling is qualitatively confirmed: changing factor condition numbers leaves both convergence speed and statistical error unaffected for SRGD, in contrast to naive robustification or classical robust M-estimation.
Figure 3: Distribution of relative estimation errors under various regimes (Gaussian/heavy-tailed predictors and noise), verifying statistical efficiency and breakdown of non-robust approaches.
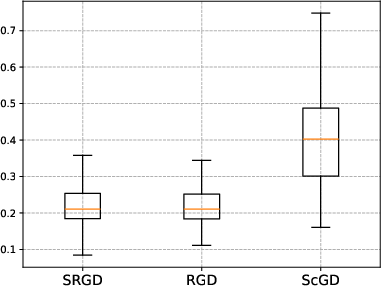
On matrix logistic regression and bilinear models, gradient truncation achieves robust and efficient learning, while Huber-based or non-truncated methods experience significant error inflation in the presence of heavy-tailed, high-leverage covariates.
Figure 4: Boxplots of estimation error on matrix logistic regression, highlighting truncation’s superiority, especially with heavy-tailed predictors.
Figure 5: Boxplots of estimation error for bilinear regression, emphasizing SRGD’s adaptivity to heavy-tailed noise and predictors over alternatives.
Applications: High-Dimensional Neuroimaging and Macroeconomic Forecasting
Beyond simulations, the effectiveness of this framework is demonstrated on high-noise, high-leverage real-world datasets.
For EEG-based alcoholism classification, matrix logistic models learned with SRGD–SHT achieve substantial improvements over vectorized or unstructured low-rank models, realizing AUCs of $0.923$ and $0.915$—a marked improvement over all ablations, especially when explicit gradient truncation is used to combat heavy-tailed artifacts in the data streams.
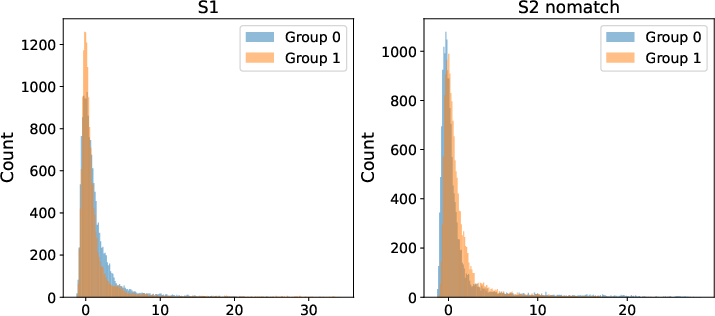
Figure 6: Visualization of excess kurtosis in real EEG predictors, underscoring violation of Gaussian assumptions and necessity of explicit robustification.
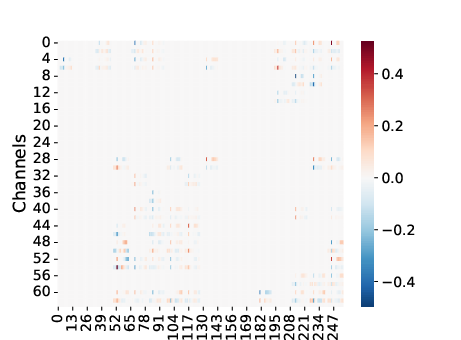
Figure 7: Heatmap of difference between robust and non-robust coefficient estimates, showing localized correction in critical regions.
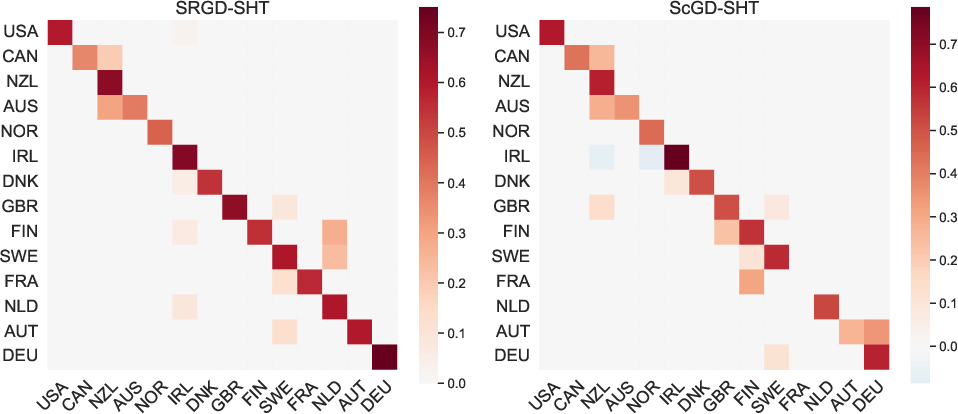
On multi-country macroeconomic time series, modeled with sparse bilinear autoregression, the SRGD estimator yields both the lowest mean out-of-sample forecast errors and recovers interpretable system structure (e.g., diagonal dominance of the transition matrix, as expected in sovereign forecasting tasks), in contrast to non-robust alternatives that are confounded by outliers in the time series.
Figure 8: Estimated country transition matrices; robust approach recovers plausible dynamics missed by non-robust estimation.
Implications, Limitations, and Future Directions
The study establishes that, for non-convex matrix and tensor decompositions with intrinsic scale ambiguity, robustification should operate strictly after normalization. Any fixed-threshold robust M-estimator applied to magnitude-distorted gradients is suboptimal and potentially inconsistent; SRGD’s scale-then-truncate principle is thus of general applicability.
The methods and insights carry potential ramifications for robust deep learning, where scale ambiguity in network weights abounds, and for higher-order tensors (e.g., models for imaging genomics or complex dynamical systems). The extension to online or streaming scenarios is immediate, given the SGD-like structure.
A current limitation is the local (rather than global) convergence; guarantees presuppose an initial estimator sufficiently close to the ground truth, but the required rate for initialization is standard and achieved by robust Dantzig or LASSO methods under mild assumptions.
Conclusion
The paper develops a statistically optimal, computationally scalable, and interpretable framework for robust high-dimensional estimation under non-convex Kronecker structure. By separating gradient robustification from scaling ambiguity, the method achieves scale invariance, optimal rates, and strong empirical performance, and offers a principled approach for robust learning in high-dimensional and heavy-tailed environments. These results are especially relevant as high-dimensional and multi-modal data (and their intrinsic heavy tails) become ubiquitous in contemporary applications.
Reference: "Scale-Invariant Robust Estimation of High-Dimensional Kronecker-Structured Matrices" (2512.19273)