- The paper presents a unified framework combining causal inference with reinforcement learning to overcome limitations in robustness, generalization, and explainability.
- It introduces eleven benchmark environments and four CRL algorithms that improve policy evaluation and enable counterfactual reasoning under confounding conditions.
- The survey offers a taxonomy of CRL methods, providing comprehensive evaluations across diverse applications in healthcare, robotics, and finance.
Unifying Causal Reinforcement Learning: Survey, Taxonomy, Algorithms, and Applications
The integration of causal inference (CI) with reinforcement learning (RL) has created a compelling paradigm to overcome some of the core limitations that afflict conventional RL approaches, including issues of explainability, robustness, and generalization. While RL traditionally relies on correlations for making decisions, these methods often falter when confronted with distribution shifts, unrecognized confounders, and fluctuating environments. Causal reinforcement learning (CRL) capitalizes on the fundamental principles of causal inference by explicitly modeling cause-and-effect relationships, therefore promising solutions to these RL challenges.
Introduction
Reinforcement learning (RL) methodologies are revolutionizing multiple domains, including healthcare, robotics, and finance. Despite their potential, RL application in practice is frequently restricted due to concerns over robustness, interpretability, and reliable generalization. This paper serves the community by unifying and analyzing the growing intersection between causal inference and RL, showcasing how causal reasoning can mitigate the intrinsic challenges faced by classical RL. The authors provide a foundational resource intended for researchers and practitioners focused on constructing AI systems that are more robust, interpretable, and trustworthy.
Furthermore, the paper develops substantial practical tools to accelerate CRL research. The authors introduce eleven benchmark environments specifically devised to evaluate causal challenges such as confounded observations, spurious correlations, distribution shifts, and hidden common causes. Additionally, four causal reinforcement learning algorithms, equipped with comprehensive code implementations, are presented to facilitate further method development within the domain. Comprehensive evaluation protocols that measure task performance, causal robustness, transfer capability, and explanation quality further lower entry barriers for researchers new to this field.
Background and Contributions
Causal reasoning is inherently a core component of both human and artificial intelligence, enabling agents to move beyond associative patterns to interpret, predict, and intervene within the world. For humans, understanding cause-and-effect relationships forms early in life and guides decision-making under uncertainty. In artificial intelligence, causality has emerged as pivotal to advancing adaptability, robustness, and clarity in decision-making. It allows agents not only to anticipate future outcomes but also to engage in counterfactual reasoning—speculating on what might have happened under different conditions. This ability to conceptualize alternative possibilities represents substantial progress from mere statistical pattern recognition to more profound understanding and reasoning.
Limitations of Conventional Reinforcement Learning: Conventional RL algorithms demand immense volumes of interaction data and typically fail to generalize beyond the training environment. This reliance on associational patterns learned through experience, without accounting for causal structures, hampers generalization capabilities, particularly in applications involving high stakes and dynamic environments. In these instances, data-intensive and brittle learning paradigms are impractical or unsafe.
Causality's Impact on Reinforcement Learning: Integrating causal inference with RL empowers agents to model cause-and-effect structures precisely, allowing them to identify variables truly influencing outcomes, whereas RL agents would treat all observed correlations as equally informative. This nuanced understanding permits interventions that refine exploration strategies by targeting informative opportunities, thus, enhancing sample efficiency.
Survey Goals and Scope: The survey systematically synthesizes recent advancements by: clarifying conceptual connections between CI and RL constructs, categorizing existing methodologies, identifying key challenges, reviewing empirical evidence and applications, and suggesting future research directions, emphasizing the potential of CRL.
Foundations
Reinforcement Learning Fundamentals
Reinforcement learning fundamentally addresses sequential decision-making challenges within Markov Decision Process (MDP) frameworks represented by state and action spaces, state transition probabilities, reward functions, and discount factors. RL's objective is to identify optimal policies that maximize expected cumulative rewards through techniques that balance exploration and exploitation.
However, these associative-driven policy decisions often fail due to spurious correlations, leading to biased policy evaluations, especially when hidden confounders influence both actions and rewards. This reveals the necessity of causal frameworks for reliable estimation and generalization.
Fundamentals of Causal Inference
Causal inference uses Structural Causal Models (SCMs) to identify and quantify causal relationships rather than correlations. By distinguishing between observational data and interventional reasoning using Pearl's do-calculus, it addresses confounding biases through identification criteria like back-door and front-door adjustments, enabling interventions that enhance policy evaluation and credit assignment.
Causal Reinforcement Learning
Transforming MDPs into causal MDPs extends RL frameworks by representing hidden confounders and causal dynamics explicitly, allowing better differentiation between observational and interventional data. This distinction facilitates interventions to discern true causal effects. Causal MDPs align with Pearl's do-calculus to achieve unbiased policy evaluations and facilitate counterfactual policy estimations under interventions.
Moreover, the integration of causality promotes robust generalization by enforcing causal invariances, demonstrating significant improvements over traditional RL approaches that might exploit superficial correlations.
Bridging Causal Inference and Reinforcement Learning: An Integrated Approach
This section delineates where causal inference complements the RL pipeline, incorporating interventional dynamics for policy evaluation and improvement, while categorizing CRL approaches into distinct thematic methodologies. The causal Bellman operator provides a computation backbone, creating interventional policy evaluation pathways that address confounding biases, distribution shifts, and enhance data efficiency.
The survey presents a modular algorithmic template for CRL, enabling plug-and-play integration with various identification strategies such as back-door, front-door, proxies, and SCM-based counterfactual simulation through causal worldview.
Survey of Methods
The paper categorizes CRL contributions into five families, demonstrating their potential across representation learning, counterfactual policy learning, offline causal RL, transfer learning, and explainability. Each approach infuses causality to address RL limitations while achieving notable successes that provide pathways for high-performance RL designs.
Applications and Empirical Studies
The authors evaluate CRL across a spectrum of applications, effectively showcasing how causal paradigms address inherent RL challenges, yielding improvements in robustness, generalization, efficiency, and interpretability.
Study A: Causal Feature Selection for Robust Generalization
The experiment systematically demonstrates the efficiency of causal architectures that ignore spurious features, thereby achieving seamless generalization across varied environments.
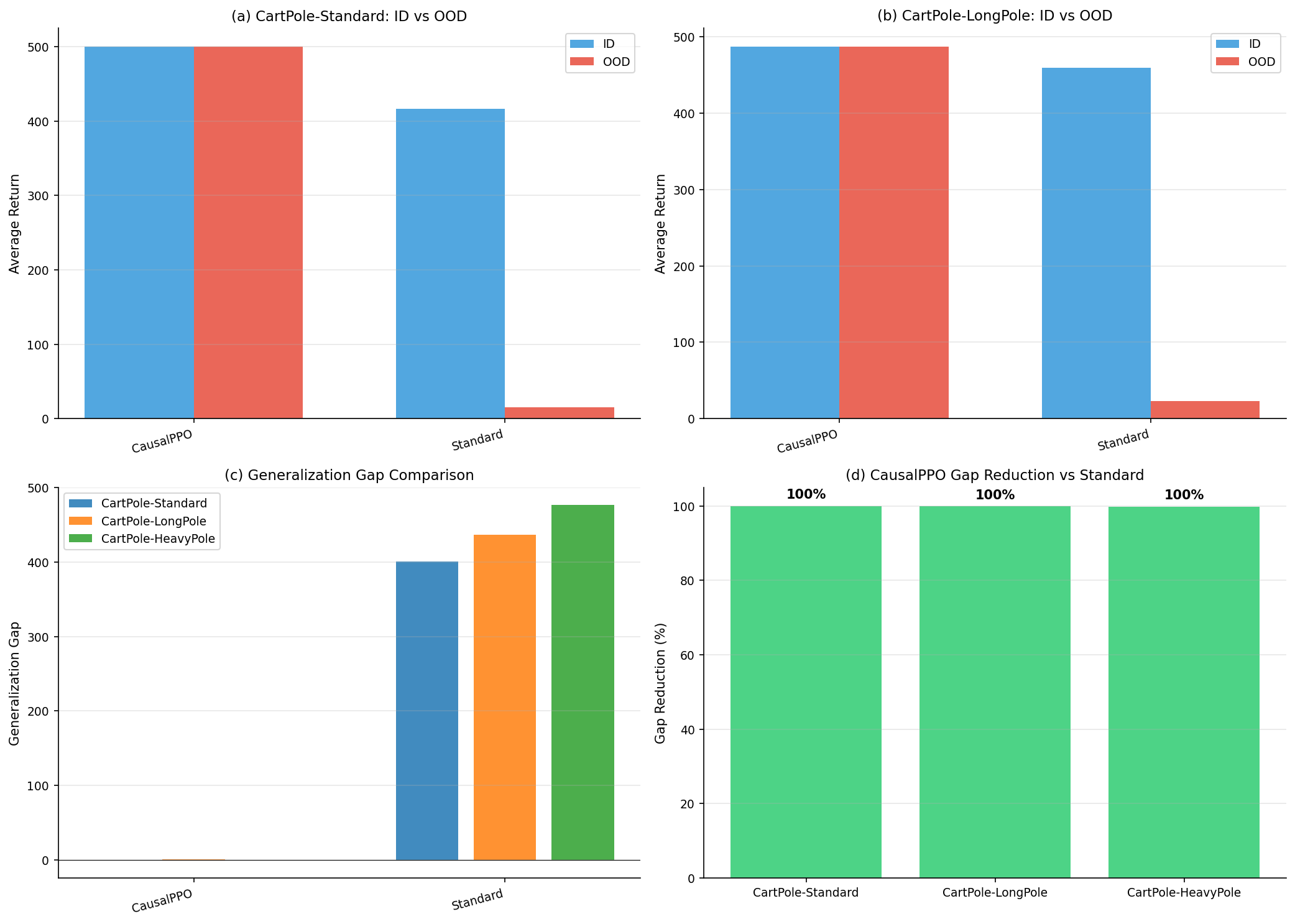
Figure 1: Study A results demonstrate robust generalization using CausalPPO over StandardPPO across distribution shifts in physics variants.
Study B: Counterfactual Advantage Estimation for Credit Assignment
The experiment explores trajectory-based inference to effectively resolve credit assignment problems brought about by hidden confounders.
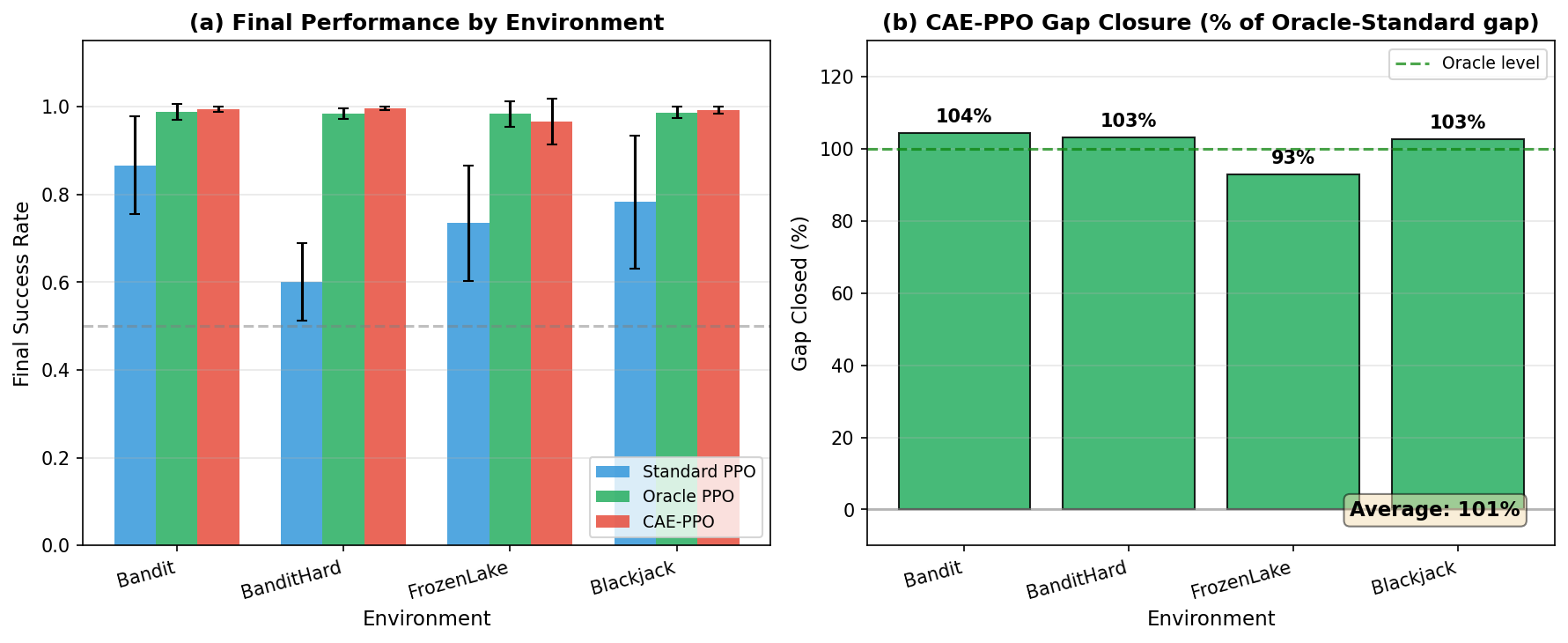
Figure 2: Reflecting CAE-PPO's unmatched ability to close the performance gap against Oracle methods.
Study C: Offline Causal RL Under Confounding
By incorporating proxy conditioning into the offline RL framework, significant improvement in policy performance and OPE accuracy is achieved.
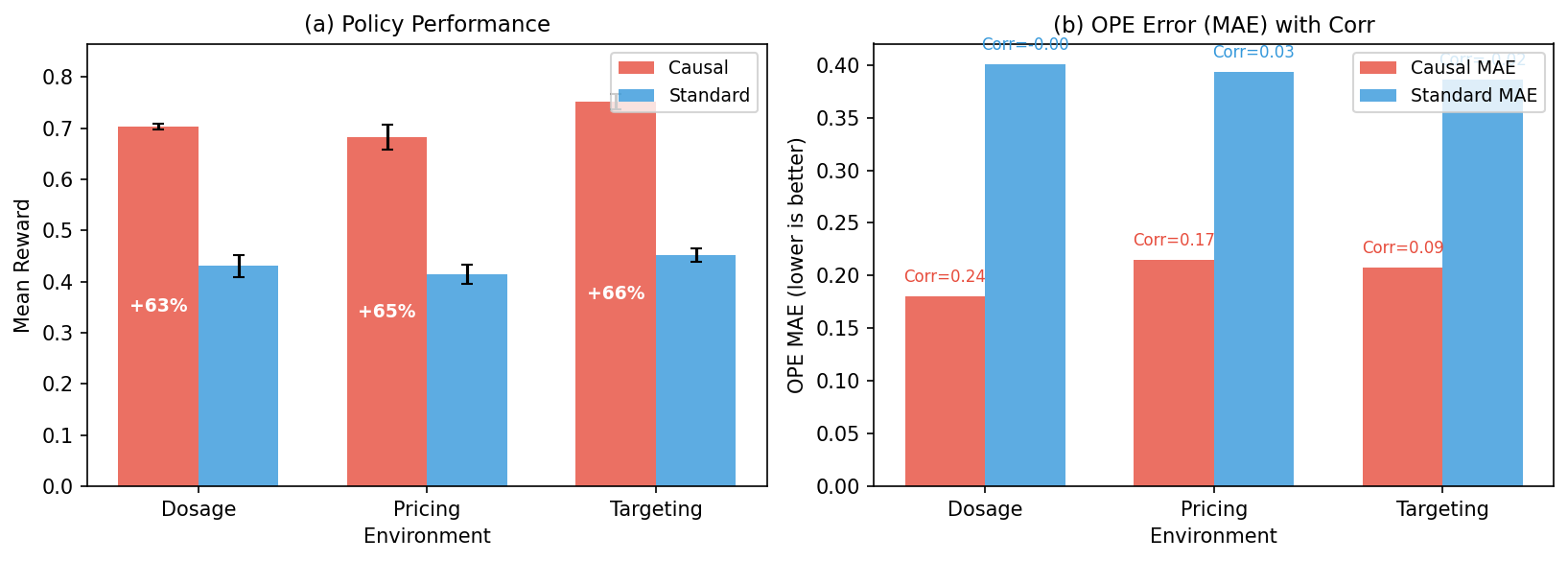
Figure 3: Study C results showcase the positive correlation improvements using causal methods over standard approaches.
Study D: Causal Transfer Learning Across Visual Domains
Efficient transfer across visual domains is achieved through causal content-style separation. The method provides substantial performance gains when adapting from clean to distracted environments.
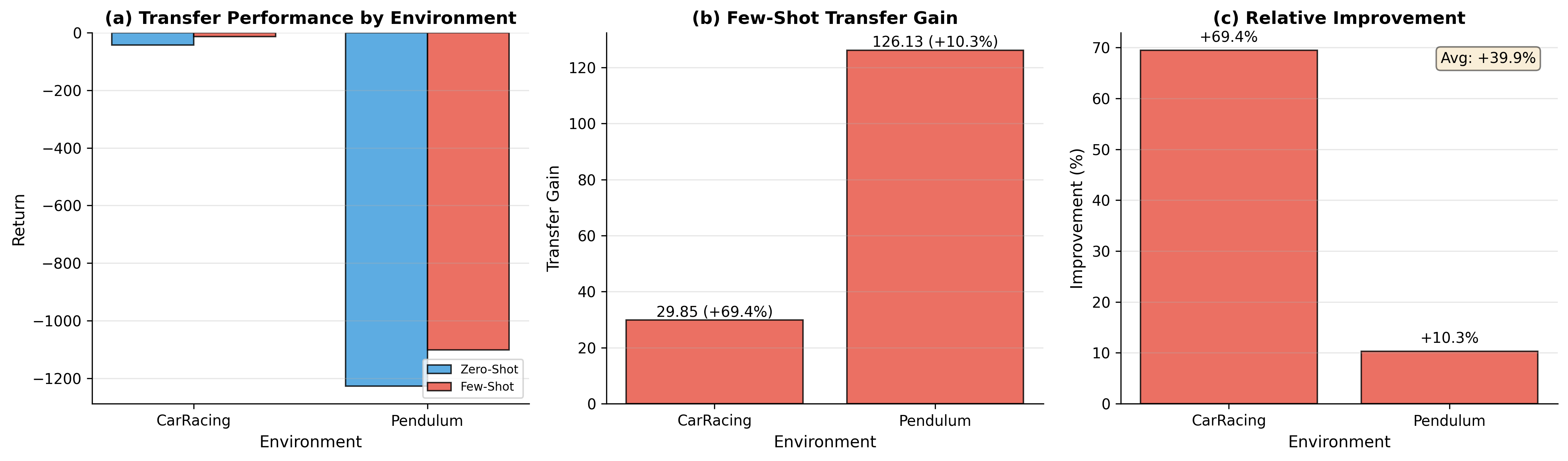
Figure 4: Results indicate successful adaptation across visual environments using causal transfer learning frameworks.
Study E: Causal Explainability via Structural Causal Models
The framework provides soaring improvements in interpretability by correctly identifying domain-relevant features, achieving near-perfect dynamics predictions for counterfactual reasoning.
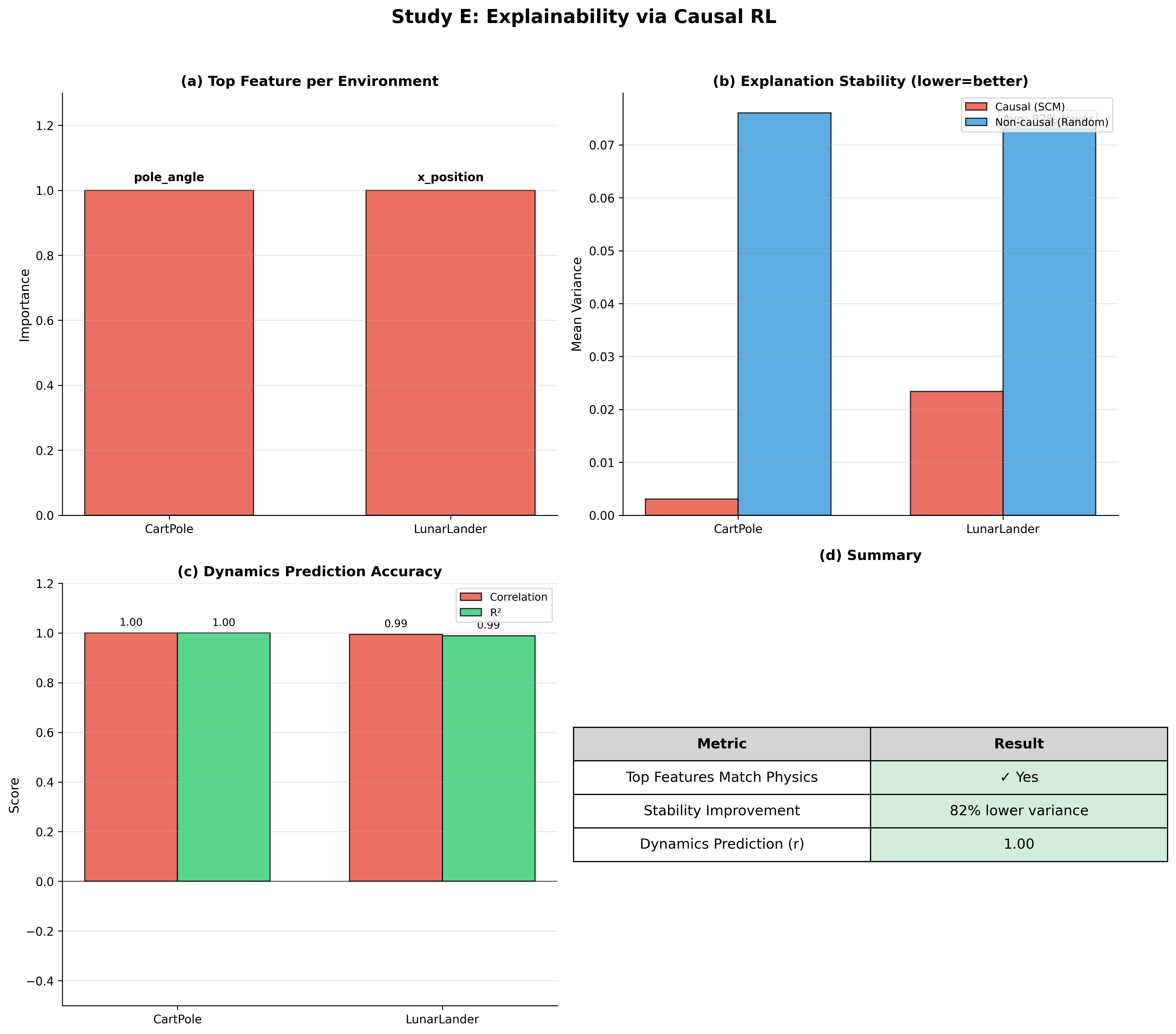
Figure 5: Highlighting SCM-based causal explanations characterized by a reduced variance and enhanced dynamics prediction.
Recommendations
Causal RL is especially beneficial when addressing distribution shifts, confounding in offline settings, and when sample efficiency or interpretability is paramount. However, its complexity may not be justified in stable environments without distributional variance or in domains where causal structures cannot be reliably identified. Researchers should blend CRL selectively with standard RL, ensuring rigorous validation of causal assumptions and reporting uncertainties transparently.
Open Problems and Future Research Directions
Methodological challenges, such as causal discovery in sequential settings and confounding in decision-making, remain ripe for exploration. The implementation hurdles regarding scalability, assumption verification, and adaptation to evolving environments present continual avenues for crafting robust CRL paradigms. Practical gaps like benchmarks, theoretical foundations, and real-world deployments necessitate further investigation. Embracing emerging opportunities in neuroscience-inspired algorithms, scientific discovery, and federated CRL stand poised to redefine the causal-RL integration landscape.
Conclusion
Unifying causal inference with reinforcement learning provides principled avenues to address the fundamental limitations faced by RL—offering enhanced robustness, interpretability, sample efficiency, and generalization. As this field advances, causal RL will inevitably play a pivotal role in shaping trustworthy AI systems capable of reliable deployment in high-stakes domains.

