- The paper introduces ResFiT, a residual RL method that fine-tunes immutable behavior cloning policies for enhanced robotic visuomotor control.
- It combines behavior cloning with action chunking and off-policy RL to achieve superior sample efficiency and near-perfect success rates across tasks.
- Experiments in simulation and real-world settings demonstrate significant performance gains in complex manipulation tasks, paving the way for autonomous robotic control.
Residual Off-Policy RL for Finetuning Behavior Cloning Policies
Introduction
This paper addresses the challenges faced by behavior cloning (BC) and reinforcement learning (RL) in training visuomotor control policies for robots. While BC requires extensive manual data collection and suffers from performance saturation, RL struggles with sample inefficiency and safety in real-world scenarios, particularly in systems with high degrees of freedom (DoF). The authors propose a novel approach that synergistically leverages BC and RL through a residual learning framework, introducing the off-policy residual fine-tuning (\textit{ResFiT}) method. This approach uses BC policies as immutable foundations and applies lightweight, sample-efficient off-policy RL to learn corrections, enabling robotics applications in both simulation and reality, demonstrated by training on a humanoid robot.
Methodology
The method presented (\textit{ResFiT}) employs a two-phase process: an initial BC phase followed by off-policy RL-based fine-tuning. This approach involves:
- Behavior Cloning (BC) with Action Chunking: BC policies are trained on demonstration data, predicting sequences of actions to mitigate compounding errors. Action chunking reduces task horizons and improves imitation learning.
- Off-Policy Residual Reinforcement Learning (RL): The core novelty lies in training a residual policy to refine base actions from BC policies rather than learning from scratch. This is facilitated by enhanced sample efficiency achievable by reparameterizing conventional Q-learning techniques for residual settings.
The paper includes a comprehensive algorithm for \textit{ResFiT}, detailing the interplay of BC and RL techniques to achieve optimal fine-tuning performance.

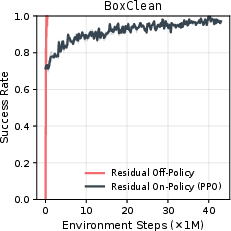
Figure 1: Our simulation tasks from Robomimic and DexMimicGen, spanning single-arm manipulation as well as bimanual coordination tasks.
Experimental Evaluation
Simulation Results
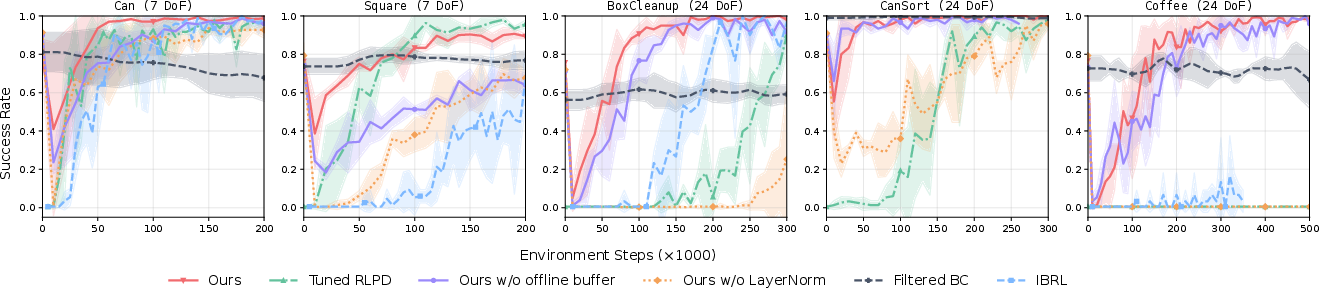
The authors conducted extensive experiments across tasks of varying complexity, from single-arm to bimanual manipulation, validating the efficacy of \textit{ResFiT}. In these evaluations, \textit{ResFiT} significantly outperformed existing methods by achieving near-perfect success rates across several sophisticated tasks. Key findings include:
Real-World Results
In real-world testing on bimanual dexterous manipulation tasks with complex humanoids, \textit{ResFiT} increased task success rates substantially. Specific tasks, such as picking and handing over objects with human-like dexterity, showcased the method's potential for practical deployment.

Figure 3: Real-world results of applying \textit{ResFiT}, where our residual RL approach shows a significant boost in performance over the base model.
Discussion and Future Work
The approach demonstrates a practical pathway to integrating the strengths of BC and RL, facilitating deployment of RL in environments with sparse rewards and high DoFs. Critiques include the potential for strategy limitations due to static base policies, and the paper proposes future research on adaptive base policies and distillation of improvements into foundational policies. Autonomous real-world learning, independent of human oversight, remains an open challenge.
Conclusion
The paper advances the field of robotics by presenting a scalable method to enhance base BC policies using residual RL in off-policy settings. The proposed \textit{ResFiT} method achieves state-of-the-art results in both simulation and real-world tasks, paving the way for more autonomous, real-world capable RL applications in robotics.