Flowing from Reasoning to Motion: Learning 3D Hand Trajectory Prediction from Egocentric Human Interaction Videos
Abstract: Prior works on 3D hand trajectory prediction are constrained by datasets that decouple motion from semantic supervision and by models that weakly link reasoning and action. To address these, we first present the EgoMAN dataset, a large-scale egocentric dataset for interaction stage-aware 3D hand trajectory prediction with 219K 6DoF trajectories and 3M structured QA pairs for semantic, spatial, and motion reasoning. We then introduce the EgoMAN model, a reasoning-to-motion framework that links vision-language reasoning and motion generation via a trajectory-token interface. Trained progressively to align reasoning with motion dynamics, our approach yields accurate and stage-aware trajectories with generalization across real-world scenes.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching computers to guess how a person’s hands will move next in 3D, based on what the person sees, what their hands have just done, and what the person plans to do. The team built two things:
- EgoMAN dataset: a large collection of first-person (“egocentric”) videos with detailed hand movement data and question–answer pairs.
- EgoMAN model: an AI system that “reasons” about the scene and your intent (like “grab the cup”), then turns that reasoning into smooth 3D hand movements.
What is the paper trying to do?
The paper has three simple goals:
- Create a better dataset that shows not just motion, but also the purpose behind it and the stages of an interaction (like moving toward an object, then using it).
- Build a model that can understand a scene, read a short intent sentence, and predict long, accurate 3D hand paths.
- Connect high-level reasoning (what and why) to low-level motion (how the hand actually moves) using simple, clear “checkpoint” tokens.
How did they do it?
The EgoMAN dataset
Think of this as a huge, organized library of “what hands do” from a first-person camera view.
- Scale: 300+ hours, 1,500+ different scenes, 219,000+ 3D wrist trajectories.
- Stage labels: Each hand interaction is split into stages:
- Approach: moving the hand toward the target.
- Manipulation: doing the action (like turning a knob or picking up a cup).
- Wrist data: For both hands, the dataset stores:
- Position in 3D space (where the wrist is).
- Orientation (which way the wrist is rotated).
- Together, these are “6 DoF” (six degrees of freedom): 3 for position (x, y, z) and 3 for rotation (pitch, yaw, roll).
- Q&A pairs: 3 million questions about:
- Semantic (intent): What action is next? Why?
- Spatial (where/when): Where will the hand be at contact? When does manipulation end?
- Motion (how): How does past movement hint at the next steps?
They collected data from real-world glasses (Project Aria) and other devices, then used a LLM to help label stages and create questions.
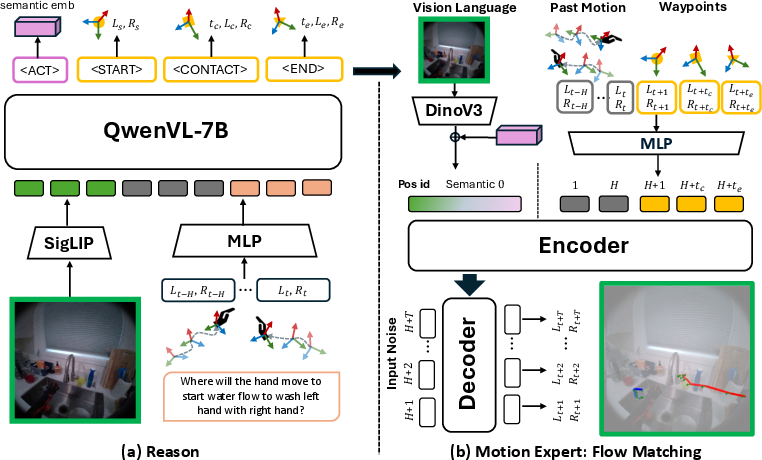
The EgoMAN model
The model has two main parts that work together like a coach and a choreographer:
- Reasoning Module (the coach): Looks at a single image, reads your intent (like “open the oven”), and considers recent hand motion. It outputs:
- One semantic token:
<ACT>(summarizes the action). - Three waypoint tokens:
<START>,<CONTACT>,<END>(checkpoints in time and space). <START>: when approaching begins.<CONTACT>: when the hand reaches the target.<END>: when the manipulation finishes.
- One semantic token:
Waypoints are like GPS checkpoints for the hand: each comes with a time, a 3D position, and a rotation.
- Motion Expert (the choreographer): Uses a technique called “Flow Matching” to turn those tokens plus the image and past motion into smooth, detailed 3D hand paths over time.
- Flow Matching, in simple terms, starts from a rough path and gently “flows” it into the right trajectory, ensuring the movement is smooth, realistic, and consistent with the checkpoints.
Training approach (how they taught it)
They trained the two parts in stages to keep learning stable and accurate:
- Train the Reasoning Module on the Q&A pairs so it learns intent and waypoints.
- Train the Motion Expert on real trajectories using true waypoints and action phrases.
- Jointly train both so the Motion Expert learns to trust the Reasoning Module’s predicted tokens (which can be a little noisy, like real life).
This “token interface” is like passing a short, structured checklist from the reasoning side to the motion side. It’s simple, fast, and easy to interpret.
What did they find?
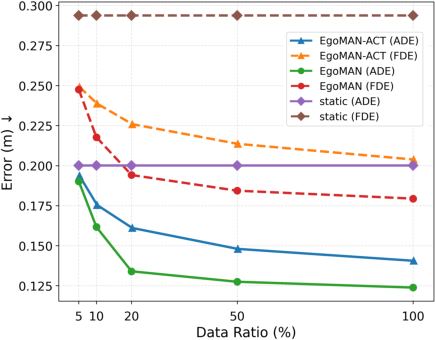
- More accurate trajectories: EgoMAN beat leading methods on all major motion metrics (distance and rotation errors), including when tested on new scenes and even different datasets. On a key metric (ADE), it reduced error by about 27% compared to a strong baseline.
- Better waypoints: It predicted contact and end positions much closer to the ground truth than “affordance” methods (which guess usable spots on objects), and did it much faster (around 3.45 frames per second versus under 0.05 for some rivals).
- Generalization: It worked well in unseen locations and with new objects, thanks to stage-aware reasoning and intent grounding.
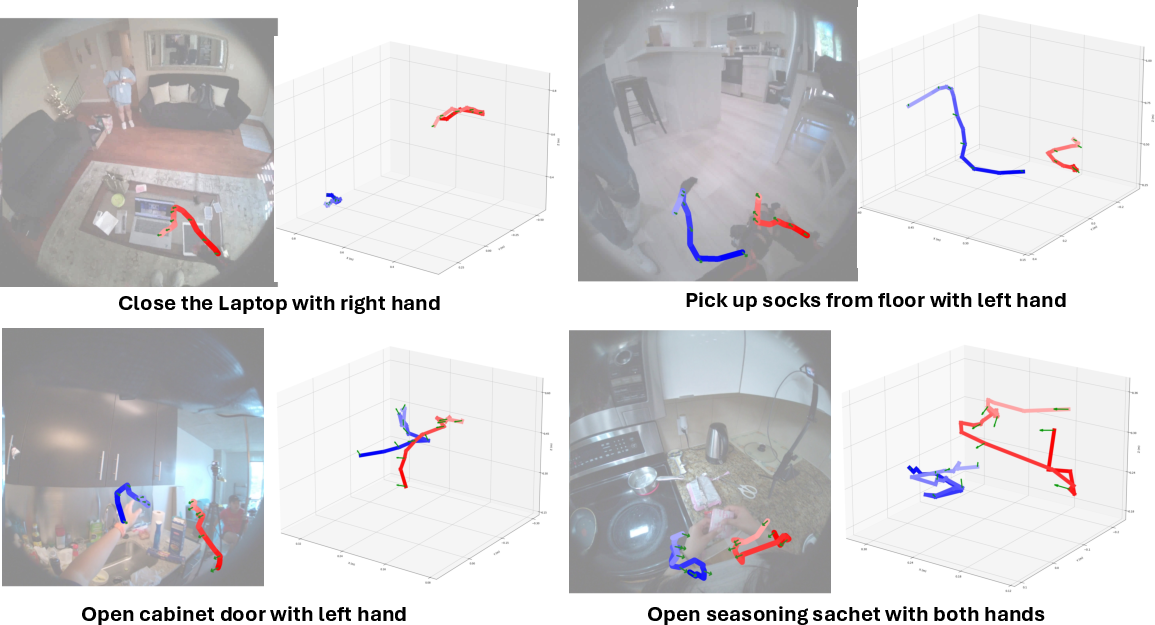
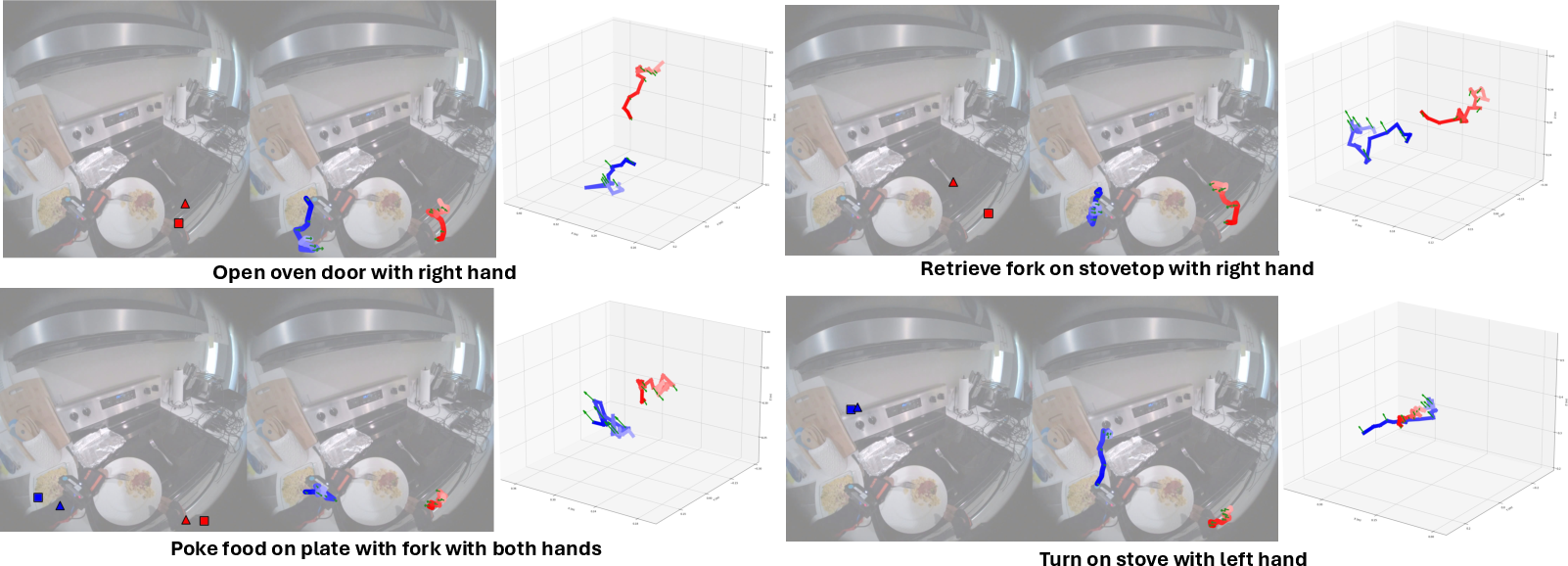
- Smoother, intent-matched motion: Given the same image and past motion, changing the intent text (“open the oven” vs “pick up fork”) produced different, correct trajectories.
Why this matters: The model doesn’t just push points around—it understands “what” the person is trying to do and “how” to do it in that scene, then moves hands accordingly.
Why is this important?
This research can impact several areas:
- Robot help and manipulation: Robots can learn from human videos to anticipate actions and assist, like handing tools or opening doors at the right time.
- Assistive technology: Systems could predict what a user is trying to do and help proactively (e.g., guiding motions, warning of mistakes).
- AR/VR and animation: More natural, intent-driven hand motion for avatars and games, making interactions feel real.
- Safer, smarter interfaces: Understanding intent and stages reduces errors and makes assistance more timely and reliable.
In short, EgoMAN shows how to connect “thinking” (reasoning about intent) to “doing” (accurate, smooth hand motion) using a clean, simple set of tokens and a strong motion engine. It’s a step toward computers that can watch, understand, and help in everyday hand–object tasks.
Knowledge Gaps
Below is a single, focused list of the paper’s unresolved knowledge gaps, limitations, and open questions that future work could concretely address:
- Annotation reliability and bias: GPT-4.1-generated stage labels and 3M QA pairs lack reported human validation rates or error analysis; HOT3D stage boundaries are inferred via heuristics (0.5–2.0 s prior to object motion). How accurate and consistent are these annotations across domains and edge cases?
- Intent query dependence: The model requires an explicit intent text at inference. Can it infer intent autonomously from visual/motion context, recover under ambiguous/missing intent, or interactively refine inferred intents?
- Single-frame visual input: Reasoning uses one RGB frame rather than a short video clip. What is the impact on moving targets, occlusions, scene changes, and egomotion, and does adding temporal vision features improve robustness?
- Lack of depth/geometry: The model conditions on DINOv3 features without explicit depth, point clouds, or scene reconstructions. How would incorporating metric depth (e.g., Metric3D) or 3D maps affect metric accuracy and OOD generalization?
- Ego-motion handling: Trajectories are transformed to the final camera frame before interaction; explicit head/camera egomotion is not modeled. How does strong wearer motion affect predictions, and can egomotion conditioning improve stability?
- Temporal resolution: Trajectories are sampled at 10 FPS up to 5 s. Is this granularity sufficient for fast manipulations, and how does performance scale at 30–60+ FPS and longer horizons?
- Stage taxonomy coverage: Dataset and tokens target approach and manipulation; release/retreat, search, pre-grasp, hand-off, and recovery stages are omitted. What stage set and tokenization best capture diverse interaction workflows?
- Waypoint timing accuracy: The model predicts waypoint timestamps but evaluation reports only spatial errors. How accurate are the timing predictions, and what metrics capture temporal alignment and latency?
- Finger articulation and contact physics: Predictions are wrist-only 6DoF; finger poses, contact points, forces, and object state changes are not modeled. How to incorporate hand articulation and contact dynamics while maintaining efficiency?
- Object-centric affordances: The interface is wrist-centric; object affordances and constraints are not explicitly enforced. Would integrating object-conditioned contact normals/surfaces improve success on precision tasks?
- Uncertainty calibration: Flow Matching is probabilistic, but evaluation uses best-of-K errors without likelihood/coverage metrics. Are predicted distributions calibrated, and do they capture multi-modal futures?
- Robustness to token errors: Joint training addresses distribution mismatch but does not analyze failure modes when <ACT>/<START>/<CONTACT>/<END> are inaccurate. Can self-correction loops, iterative refinement, or confidence gating reduce cascading errors?
- Generalization breadth: OOD evaluation is limited to HOT3D-Aria. How does performance transfer to different sensors (smartphones, GoPros), third-person views, outdoor scenes, varied lighting, and broader demographics?
- Dependency on past 6DoF wrist history: Inference assumes accurate past wrist trajectories. How does performance degrade with noisy/missing motion histories, and can the system operate from video-only inputs?
- Quantitative intent alignment: There is no metric verifying that predicted trajectories satisfy the verb phrase or task semantics. How to measure semantic-motion consistency (e.g., action success rates or language-to-motion accuracy)?
- Multi-step tasks and hierarchy: Tokens model a single atomic interaction. How to chain variable-length token sequences for multi-step plans, branches, loops, and long-horizon tasks?
- Bimanual coordination analysis: Although bi-hand 6DoF is predicted, the paper does not analyze inter-hand role allocation, synchronization, or failure modes in complex bimanual manipulations.
- Occlusion robustness: Only visible waypoints are supervised; strategies for long occlusions and out-of-view targets are unspecified. How can the model predict through occlusions and recover when hands reappear?
- Physical feasibility in clutter: Losses optimize displacement/rotation errors without collision checks, kinematic limits, or reachability constraints. How physically realizable are trajectories in cluttered scenes?
- Efficiency and deployability: Waypoint FPS is reported, but end-to-end trajectory generation latency and memory on realistic edge hardware (AR glasses, mobile GPUs) are missing. Can the system meet real-time constraints with smaller models?
- Data quality and bias: The pretrain split includes low-quality, ambiguous interactions; there is no systematic study of label noise effects, scene biases, or demographic coverage. What data curation or robust training strategies mitigate these?
- Token interface scalability: The four-token design may be insufficient for complex actions. How to extend to variable-length, action-specific token sets and maintain interpretability/efficiency?
- Training stability diagnostics: Progressive training is motivated qualitatively; quantitative diagnostics and failure analyses of instability sources (e.g., gradient conflicts, objective mismatch) are absent.
- Evaluation metrics scope: ADE/FDE/DTW/Rot capture geometry but not task outcomes. There is no measurement of contact success, manipulation completion rates, or human perceptual judgments of trajectory plausibility.
Glossary
- 6D rotation parameterization: A continuous representation of 3D orientation using six parameters to avoid singularities in rotation learning. "We use the continuous 6D rotation parameterization~\cite{zhou2019continuity} with a geodesic rotation loss ($\mathcal{L}{\text{geo}$)"
- 6DoF: Six degrees of freedom describing a rigid body's 3D position and orientation (translation and rotation). "The EgoMAN dataset provides 6DoF wrist trajectories for both hand wrists (3D position + 6D rotation~\cite{zhou2019continuity}), sampled at 10 frames per second (FPS)."
- ADE (Average Displacement Error): The average Euclidean distance between predicted and ground-truth trajectory points. "including Average Displacement Error (ADE), Final Displacement Error (FDE), and Dynamic Time Warping (DTW), all reported in meters"
- Action semantic token (<ACT>): A specialized token that encodes the intended action’s semantic embedding used to condition motion generation. "The action semantic token<ACT> decodes an action semantic embedding corresponding to the interaction phrase (e.g., ``left hand grabs the green cup'')."
- Affordance: Properties of objects that suggest possible actions; in modeling, predicted points or regions indicating where interactions can occur. "Affordance-based methods~\cite{vrb, chen2025vidbot} rely on object detectors and affordance estimators, which propagate upstream detection errors and introduce additional computational overhead."
- Angular Rotation Error (Rot): The angular difference (in degrees) between predicted and ground-truth wrist orientations. "as well as Angular Rotation Error (Rot) in degrees."
- Best-of-K: Evaluation that reports the best (lowest error) among K sampled trajectories for stochastic predictors. "Unless otherwise specified, all results are reported as best-of-, which selects the trajectory with minimum error to the ground truth."
- CLIP: A vision–LLM that encodes images and text into a joint embedding space via contrastive learning. "contrast against a CLIP-encoded~\cite{radford2021learning} GT embedding."
- Conditional Variational Autoencoder (CVAE): A generative model that learns conditional latent variables for structured outputs (e.g., trajectories) given inputs like tokens or images. "using a Conditional Variational Autoencoder (CVAE)~\cite{cvae} head from 50 predicted special hand tokens;"
- DINOv3: A self-supervised vision backbone that produces robust visual features used as context for motion prediction. "intent semantics and DINOv3~\cite{simeoni2025dinov3} visual features are added as non-temporal context tokens."
- DTW (Dynamic Time Warping): A sequence alignment metric that measures similarity between temporal sequences with possible time shifts. "including Average Displacement Error (ADE), Final Displacement Error (FDE), and Dynamic Time Warping (DTW), all reported in meters"
- Egocentric: First-person perspective data captured from the wearer’s viewpoint (e.g., head-mounted camera). "Egocentric hand forecasting aims to infer future hand motion from past observations under ego-motion and depth ambiguity."
- Egomotion (ego-motion): The motion of the camera wearer that affects perceived hand/object dynamics in egocentric videos. "Egocentric hand forecasting aims to infer future hand motion from past observations under ego-motion and depth ambiguity."
- FDE (Final Displacement Error): Euclidean distance between predicted and ground-truth positions at the trajectory’s final time step. "including Average Displacement Error (ADE), Final Displacement Error (FDE), and Dynamic Time Warping (DTW), all reported in meters"
- Flow Matching (FM): A generative modeling technique that learns a velocity field to transform noise into data samples, producing smooth probabilistic trajectories. "The Motion Expert is an encoder–decoder transformer using Flow Matching (FM)~\cite{lipman2023flow} conditioned on past wrist motion, intent semantics, low-level visual features, and stage-aware waypoints."
- Gaussian time windows: Weighted time intervals (Gaussian-shaped) used to emphasize supervision near specific timestamps. "each waypoint token is supervised with Huber losses weighted by Gaussian time windows:"
- Geodesic rotation loss: A loss measuring the shortest rotational distance on the rotation manifold between predicted and ground-truth orientations. "with a geodesic rotation loss ($\mathcal{L}{\text{geo}$)"
- Huber loss: A robust regression loss that is less sensitive to outliers than squared error. "each waypoint token is supervised with Huber losses weighted by Gaussian time windows:"
- InfoNCE: A contrastive learning objective that separates positive pairs from negatives using a temperature-scaled softmax. "otherwise, we use an InfoNCE-style contrastive loss."
- Machine Perception Services (MPS): A production system that provides hand tracking and perception outputs from the Aria platform. "For EgoExo4D, we use hand tracking data produced by Aria’s Machine Perception Services (MPS)~\cite{mps}."
- Out-of-distribution (OOD): Data that differ significantly from training distributions, used to assess generalization. "HOT3D-OOD includes 990 trajectory samples from HOT3D (dataset only used in testing), designed to evaluate out-of-distribution (OOD) performance on novel subjects, objects, and environments."
- Pinhole camera model (pinhole views): An idealized camera projection model that maps 3D points to 2D via a single viewpoint. "Aria fisheye images are rectified to pinhole views using device calibration."
- Positional IDs: Index-based positional encodings assigned to tokens to reflect their timestamps in the input sequence. "These temporal tokens receive positional IDs based on their timestamps."
- Qwen2.5-VL: A multimodal vision–LLM backbone used for reasoning with images, text, and motion. "Built on Qwen2.5-VL~\cite{qwen2025qwen25technicalreport}, it takes as input an egocentric frame"
- Rectification: The process of correcting lens distortions (e.g., fisheye) to standard projection models. "Aria fisheye images are rectified to pinhole views using device calibration."
- State-space models: Sequence models that represent dynamics via latent states and transitions; used for trajectory forecasting. "state-space models~\cite{BaoUSST_ICCV23}, diffusion~\cite{diffip2d, Hatano2025EgoH4}, and hybrid variants~\cite{ma2024madiff, ma2025mmtwin}."
- Trajectory-Token Interface: A structured bridge of semantic and waypoint tokens that connects reasoning outputs to the motion generator. "The trajectory tokens of (a) form the Trajectory-Token Interface which replaces semantic and waypoint condition inputs of (b) to bridge from Reasoning to Motion Expert."
- Trajectory-Warp Distance (Traj): A waypoint error metric measuring average distance to the nearest ground-truth trajectory point. "Trajectory-Warp Distance (Traj): The average Euclidean distance from each predicted waypoint to its nearest point on the GT trajectory."
- Unprojection: Converting 2D image points (with depth) back into 3D coordinates. "VRB* and HAMSTER* produce 2D affordance points that we unproject to 3D"
- Vision-Language-Action (VLA): Systems that extend VLMs with action generation for embodied tasks like manipulation or navigation. "Vision-Language-Action (VLA) systems~\cite{kim24openvla, zitkovich2023rt, luo2025being} support manipulation and navigation via robot datasets"
- Vision-LLM (VLM): Models that jointly process and reason over visual and textual inputs. "Modern VLMs unify perception and language~\cite{liu2023visualinstructiontuningllava, maaz2023videochatgpt, hanoona2023GLaMM, lai2024lisareasoningsegmentationlarge, palm-e, qwen2025qwen25technicalreport, gemmateam2025gemma3technicalreport}"
- Waypoint tokens: Structured tokens (<START>, <CONTACT>, <END>) predicting stage timestamps, positions, and rotations for interaction. "The three waypoint tokens: <START>, <CONTACT>, and <END> denote the approach onset, manipulation onset (i.e, approach completion), and maunipulation completion stages respectively."
- Wrist-centric: Focusing on the wrist’s position/orientation rather than object-centric coordinates for motion annotation and prediction. "we crop a 5\,s clip and annotate two wrist-centric interaction stages:"
Practical Applications
Immediate Applications
Below is a concise set of deployable use cases that leverage the paper’s dataset (EgoMAN) and model (reasoning-to-motion with trajectory-token interface), including sector links, potential tools/products/workflows, and feasibility notes.
- Industry — AR/VR intent-aware overlays for hands
- Use case: Predict a user’s approach, contact, and end waypoints to visualize “ghost paths,” highlight targets, and prefetch UI elements in headsets or smartglasses.
- Potential tools/products/workflows:
- “Waypoint Overlay Engine” that renders <START>/<CONTACT>/<END> paths in Unity/Unreal.
- Intent-conditioned AR assistants for assembly, cooking, maintenance.
- Assumptions/dependencies:
- Egocentric camera and on-device or nearby compute; reliable hand tracking for past motion; camera calibration; text intent via prompt or inferred from context.
- Industry — Collaborative robot safety and scheduling
- Use case: Use predicted human wrist trajectories to dynamically expand safety zones and modulate robot speed; schedule co-manipulation to avoid hand–robot conflict near <CONTACT>/<END>.
- Potential tools/products/workflows:
- “Safety Envelope Extender” plug-in for cobot controllers.
- Stage-aware task scheduler that pauses robot motion at predicted human contact.
- Assumptions/dependencies:
- Shared coordinate frame between human and robot; sub-100 ms latency for tight safety margins; industrial safety validation.
- Robotics — Teleoperation latency compensation
- Use case: Predict operator hand waypoints to pre-shape and pre-position robot end-effectors, offsetting network latency.
- Potential tools/products/workflows:
- “Waypoint Lookahead” module integrated into teleop stacks.
- Assumptions/dependencies:
- Robust retargeting from human wrist frames to robot end-effector frames; operator consent for prediction; fail-safe fallbacks.
- Software/Media/Academia — Automatic stage-aware video annotation
- Use case: Batch-process egocentric corpora to label approach/manipulation segments and 6-DoF wrist keypoints to cut annotation costs.
- Potential tools/products/workflows:
- “EgoMAN Annotator” for research labs and media indexing.
- Assumptions/dependencies:
- Domain match to EgoMAN’s scenes; acceptable accuracy for semi-automatic pipelines; privacy-compliant handling of egocentric video.
- Education/Training — Skill coaching with trajectory feedback
- Use case: Provide trainees with stage-timed feedback (e.g., “reach too high,” “late contact,” “over-rotation”) for tasks like cooking, lab work, or assembly.
- Potential tools/products/workflows:
- AR “Ghost Reach” guidance; instructor dashboards showing ADE/FDE over sessions.
- Assumptions/dependencies:
- Appropriate sensors in training environments; tolerance for moderate error; task-specific calibration.
- Animation/Gaming — Text-conditioned hand motion synthesis
- Use case: Generate long-horizon hand motions from a still frame + text (e.g., “pick up the green cup”) to accelerate mocap-free prototyping.
- Potential tools/products/workflows:
- Engine plugins mapping trajectory tokens to skeleton controllers; procedural “reach–grasp–release” templates.
- Assumptions/dependencies:
- Wrist-level motion suffices for many assets; finger articulation may require separate models.
- Warehousing/Logistics — Pick-by-vision guidance
- Use case: Show predicted reach targets and end orientations for pick faces, speeding up pick-and-place operations.
- Potential tools/products/workflows:
- AR workflows that render predicted contact points and expected orientation for box handles.
- Assumptions/dependencies:
- Stable egocentric capture (headsets); integration with inventory locations; worker acceptance.
- Healthcare — Rehabilitation monitoring and home exercises
- Use case: Quantify adherence to reach–manipulate–release patterns and progression in range of motion and smoothness.
- Potential tools/products/workflows:
- “Stage-Timing Scorecard” with ADE/DTW-based progress metrics for therapists/patients.
- Assumptions/dependencies:
- Clinical validation; secure data storage; calibration to patient anthropometry.
- Daily Life — Contextual safety prompts in smart kitchens/shops
- Use case: Warn users when reaching toward hot surfaces or sharp tools; time-to-contact estimation for proactive alerts.
- Potential tools/products/workflows:
- Edge-based alert system using predicted <CONTACT> timing and location.
- Assumptions/dependencies:
- Reliable object recognition or rules for hazard zones; low false-alarm tolerance.
- Academia — Benchmarking and method development
- Use case: Use EgoMAN dataset and trajectory-token interface to test reasoning-to-motion models; evaluate stage-aware generalization and sample efficiency.
- Potential tools/products/workflows:
- Baseline kits; token-interface APIs for new VLM–motion couplings.
- Assumptions/dependencies:
- Access to dataset licenses; compute for training; reproducible splits.
- Robotics/ML — Data augmentation for imitation learning
- Use case: Generate intent-consistent waypoint-conditioned trajectories from human videos to augment robot learning datasets.
- Potential tools/products/workflows:
- “Intent-to-Waypoint Synthesizer” feeding robot policy training with diversified reaches.
- Assumptions/dependencies:
- Retargeting pipeline; alignment between human and robot kinematics.
- HCI — Anticipatory gesture UIs
- Use case: Predict imminent hand actions (e.g., button press, slider grasp) to pre-enlarge UI targets or reduce acquisition time.
- Potential tools/products/workflows:
- UI toolkits that adapt layouts based on predicted <CONTACT> points.
- Assumptions/dependencies:
- Acceptable prediction error margins; careful UX to avoid intrusive adaptation.
Long-Term Applications
These opportunities require further research, scaling, integration, or certification before broad deployment.
- Robotics — Dexterous manipulation from human videos (VLA control)
- Use case: Map intent and wrist waypoints to full robot hand control (including finger contacts) for general-purpose manipulation.
- Potential tools/products/workflows:
- “Trajectory-Token → End-Effector Planner” coupled with grasp planners and tactile feedback.
- Assumptions/dependencies:
- Reliable retargeting; high-frequency control; grasp synthesis and contact modeling; safety certification.
- Assistive prosthetics and exoskeletons with intent priors
- Use case: Use predicted waypoints as priors fused with EMG/IMU to stabilize and anticipate user movements in upper-limb prostheses/exos.
- Potential tools/products/workflows:
- Intent-fusion controllers combining EgoMAN tokens with biosignals.
- Assumptions/dependencies:
- On-device, low-latency inference; clinical trials; personalized calibration.
- On-device real-time assistants on AR glasses
- Use case: Fully local, privacy-preserving intent-aware guidance at >10–30 FPS with minimal heat and power.
- Potential tools/products/workflows:
- Distilled/quantized EgoMAN variants; hardware accelerators for flow matching.
- Assumptions/dependencies:
- Model compression; energy-efficient vision-language stacks; vendor SDK support.
- Home-service cobots that anticipate human intent
- Use case: Household robots coordinate with humans by predicting hand intent (e.g., opening a drawer) and preparing tools/positions.
- Potential tools/products/workflows:
- Multi-agent planners using human waypoints as constraints for robot trajectories.
- Assumptions/dependencies:
- Robust perception in clutter; long-horizon scheduling; trust and safety frameworks.
- Multi-agent and social interaction prediction
- Use case: Extend stage-aware prediction to multiple people and bi-manual coordination; improve safety and collaboration in teams.
- Potential tools/products/workflows:
- “Group Trajectory Tokenizer” for shared workspaces; social-compliance policies.
- Assumptions/dependencies:
- New datasets covering multi-person egocentric scenes; identity tracking; conflict resolution.
- Clinical assessment of motor disorders
- Use case: Derive biomarkers from stage timing, smoothness (DTW), and rotational errors for conditions like Parkinson’s or post-stroke recovery.
- Potential tools/products/workflows:
- Analytics suites for clinicians with longitudinal tracking and norms.
- Assumptions/dependencies:
- Regulatory approval; longitudinal datasets; clinical validation against gold standards.
- Policy and standards — Safety benchmarks for predictive HRI
- Use case: Define standardized, stage-aware metrics (e.g., ADE/FDE thresholds near <CONTACT>) for certifying predictive assistance in cobots and AR.
- Potential tools/products/workflows:
- Public test suites built on EgoMAN-Bench for conformity testing.
- Assumptions/dependencies:
- Multi-stakeholder consensus; liability and risk frameworks; versioned datasets.
- Privacy-preserving egocentric data frameworks
- Use case: Create protocols for collecting/processing egocentric video with strict consent, on-device redaction, and minimization, enabling research/industry use.
- Potential tools/products/workflows:
- Federated training pipelines; secure enclaves for model updates.
- Assumptions/dependencies:
- Regulatory alignment (e.g., GDPR/CCPA); vetted redaction tech; user trust.
- Generalizable intent-to-motion simulators for robot training
- Use case: Simulate diverse human intentions and stage-aware hand paths to pretrain robots in photorealistic digital twins.
- Potential tools/products/workflows:
- “EgoSim” modules that inject waypoint-conditioned human agents into Isaac/Unity simulators.
- Assumptions/dependencies:
- Bridging sim-to-real; coverage of diverse tasks; physics-grounded hand–object interaction models.
- Fine-grained content creation tools with finger-level synthesis
- Use case: Extend wrist trajectory predictions to full hand pose and contact dynamics for film/VFX and high-fidelity training media.
- Potential tools/products/workflows:
- Coupled token interfaces for wrist + finger waypoints; differentiable contact solvers.
- Assumptions/dependencies:
- New datasets with finger articulation and contact labels; advanced motion models.
Cross-cutting assumptions and dependencies
- Sensing and calibration: Egocentric cameras or equivalent sensors, reliable past hand tracking, and camera/scene calibration are typically required.
- Domain shift: Performance may degrade in tasks, objects, or environments far from training data; adaptation or finetuning may be needed.
- Safety and ethics: Predictive systems must be fail-safe, provide uncertainty estimates, and respect privacy/consent in egocentric data collection.
- Compute and latency: Reported waypoint rates (~3.45 FPS on datacenter GPUs) imply additional engineering for real-time, on-device operation.
- Scope of motion: Current predictions are wrist-centric 6-DoF at 10 FPS; fine finger articulation and contact physics require additional models or sensors.
Collections
Sign up for free to add this paper to one or more collections.

