- The paper presents Uni-Hand, a framework that uses a dual-branch diffusion model to concurrently predict hand and head movements in egocentric views.
- It integrates multi-modal inputs, including vision, language, and 3D context, to accurately forecast detailed hand joint trajectories and interaction states.
- Experimental evaluations across diverse datasets demonstrate its state-of-the-art performance and real-world applicability in robotic manipulation and action recognition.
Uni-Hand: Universal Hand Motion Forecasting in Egocentric Views
Introduction
The paper "Uni-Hand: Universal Hand Motion Forecasting in Egocentric Views" (2511.12878) introduces a novel universal framework for hand motion forecasting, termed Uni-Hand. The motivation behind Uni-Hand arises from the necessity to accurately predict human hand movements in egocentric views to facilitate applications such as augmented reality, human-robot policy transfer, service, and assistive technologies. Current hand trajectory prediction methods have limitations including insufficient prediction targets, modality gaps between 2D inputs and 3D perceptions, and entangled hand-head motion patterns.
Uni-Hand addresses these challenges by incorporating multi-modal inputs (vision-language fusion, global context incorporation, and task-aware text embedding) to forecast hand trajectories in both 2D and 3D spaces. A dual-branch diffusion model is devised to concurrently predict human head and hand movements, capturing their synergy in egocentric vision. Further, Uni-Hand extends prediction targets beyond hand centers to specific joints and interaction states, facilitating downstream task applications.
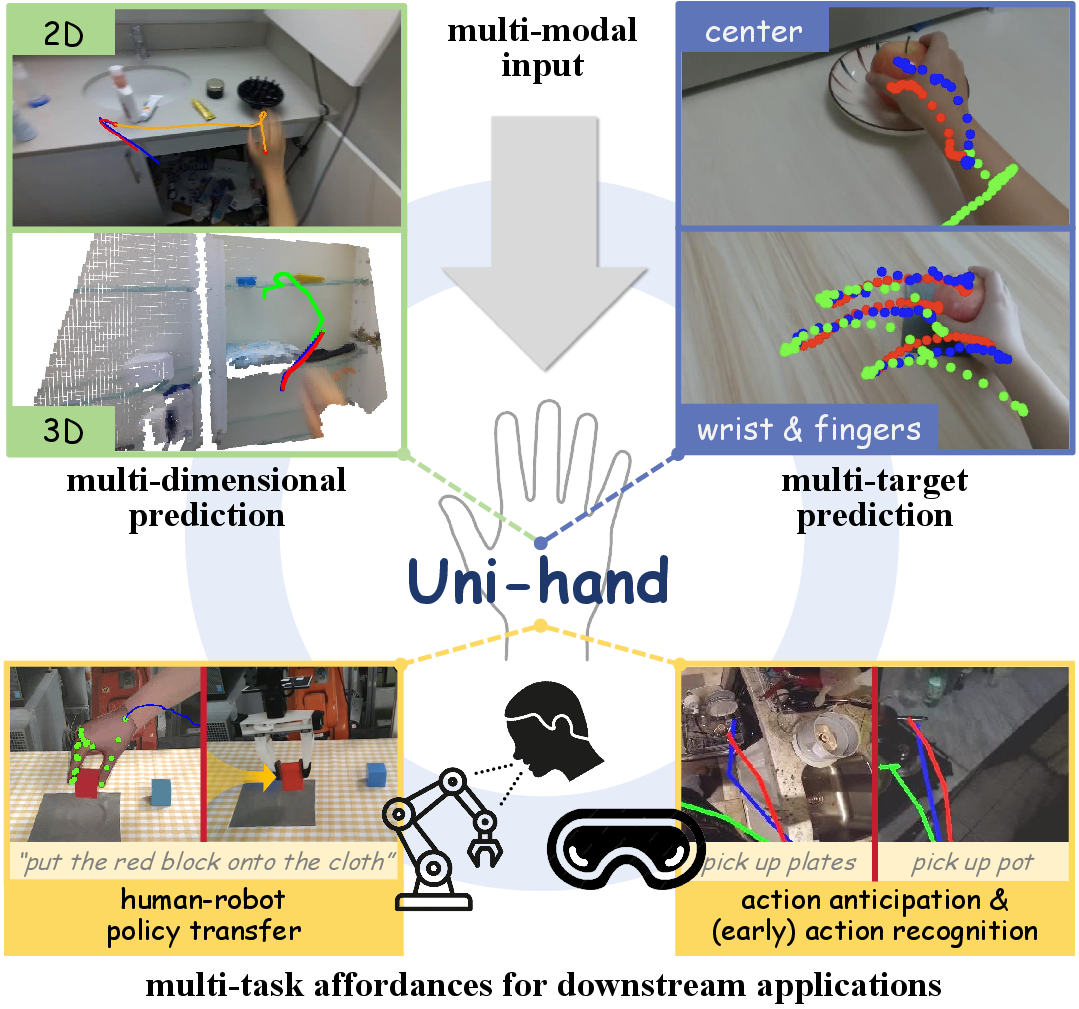
Figure 1: Uni-Hand is a universal hand motion forecasting framework which facilitates multi-dimensional and multi-target predictions with multi-modal input. It also enables multi-task affordances for downstream applications.
System Components
The system architecture of Uni-Hand consists of feature extraction modules, a dual-branch diffusion model, and specific decoders for trajectory and interaction state prediction.
Uni-Hand leverages multiple modalities for comprehensive input. VL-Fusion combines vision and language features, waypoint features, and task-aware embeddings to generate hand motion latents. Egomotion Encoder uses sequential homography matrices to track headset camera motion, while Voxel Encoder processes point clouds to create 3D global contexts.
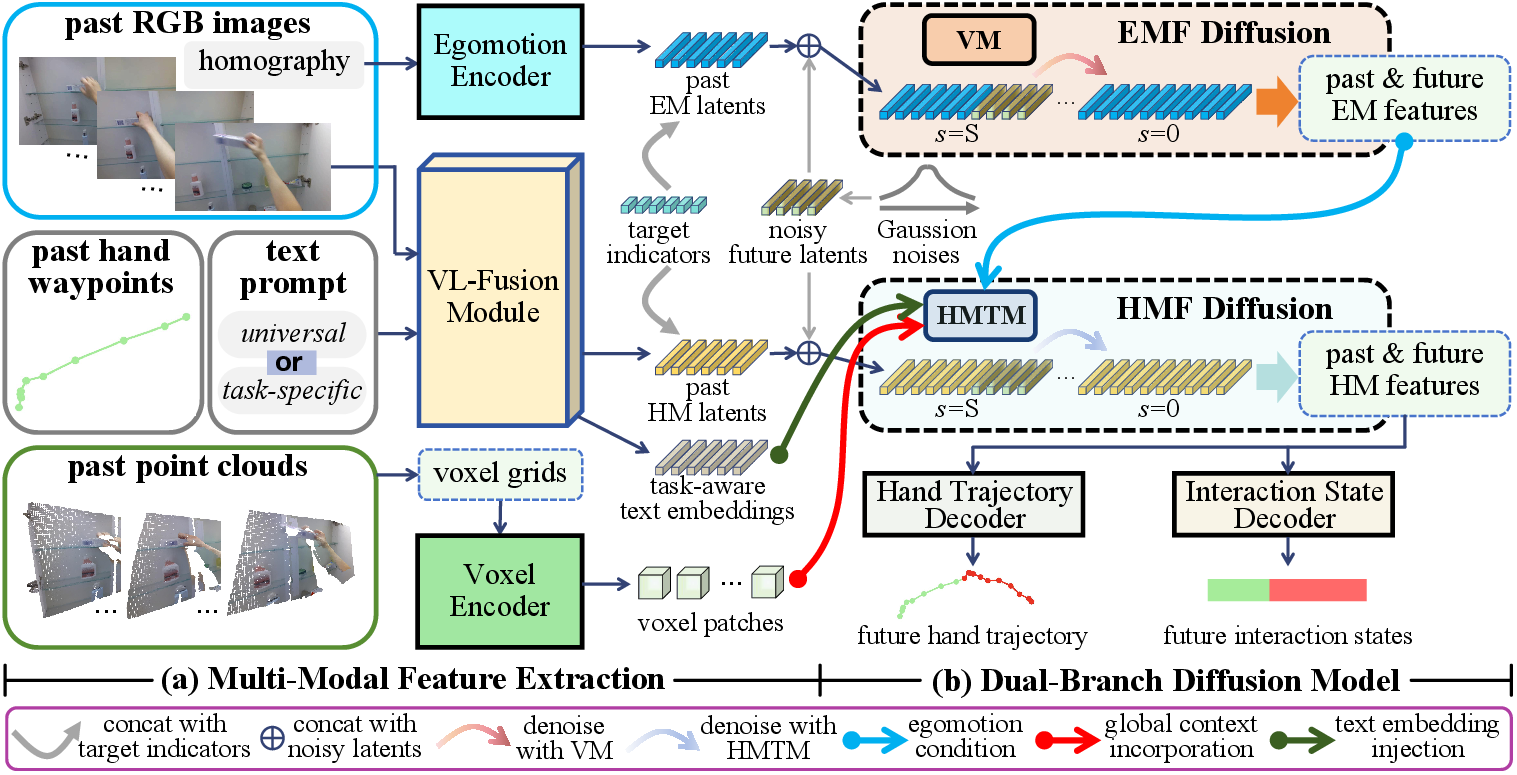
Figure 2: System overview of Uni-Hand. Uni-Hand (a) converts multi-modal input into latent feature spaces, and (b) decouples predictions of future egomotion latents (EM latents) and hand motion latents (HM latents) by a novel dual diffusion.
Dual-Branch Diffusion Model
The EMF diffusion, employing vanilla Mamba blocks, efficiently denoises future egomotion latents. In contrast, the HMF diffusion utilizes a hybrid Mamba-Transformer module to accommodate egomotion-aware and structure/task-aware modeling. This ensures balanced integration of temporal motion patterns with global 3D context and specific task orientations.
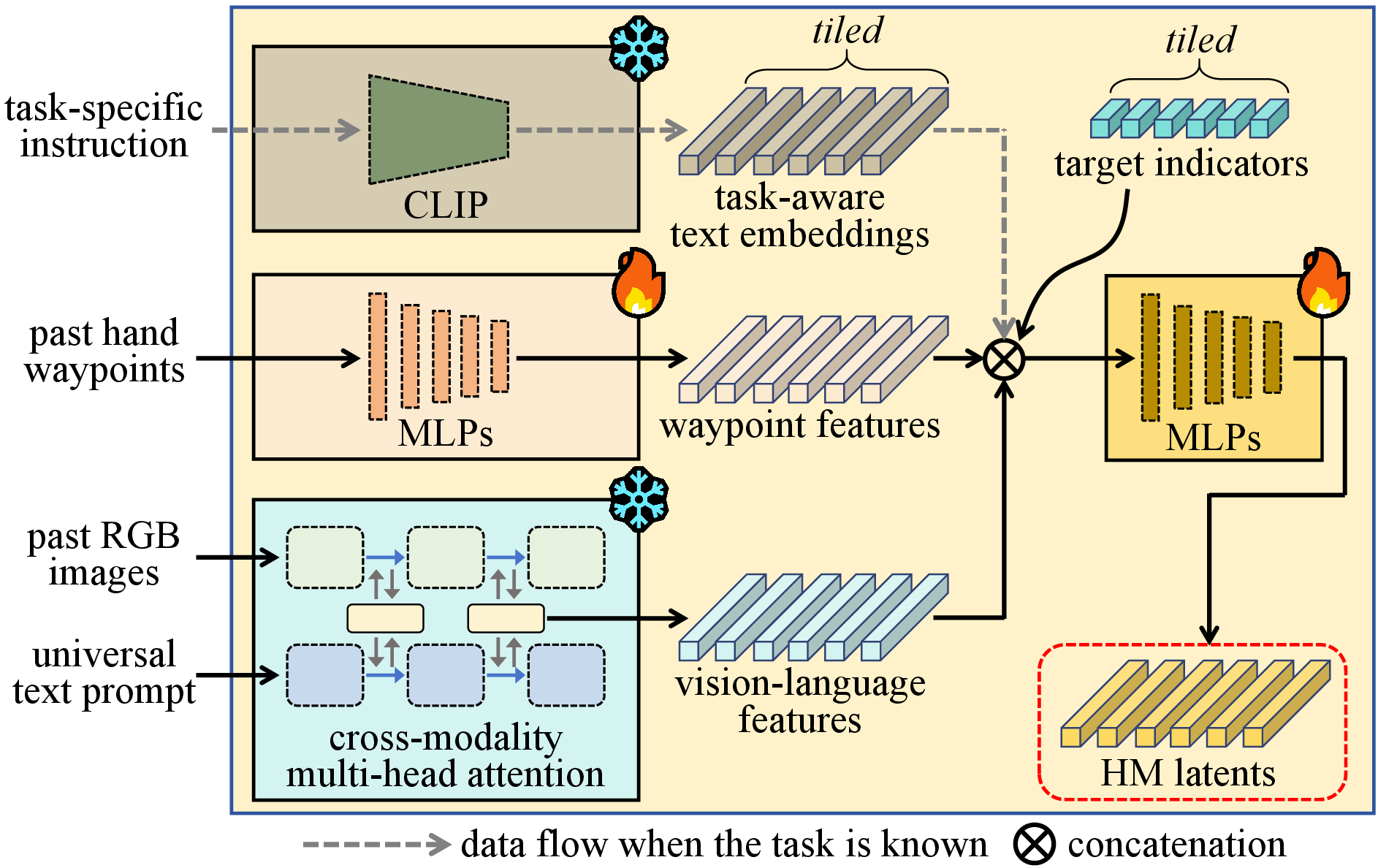
Figure 3: Architecture of the VL-fusion module. It generates HM latents for the following HMF diffusion by fusing vision-language features, waypoint features, and task-aware text embeddings.
Experimental Evaluation
Uni-Hand demonstrates state-of-the-art (SOTA) performance in hand trajectory prediction across several datasets, including EgoPAT3D-DT, H2O-PT, HOT3D-Clips, and a newly proposed collection benchmark, CABH. Extensive validation showcases its capability in multi-target hand forecasting and robust integration in downstream tasks such as robotic manipulation and action recognition.
Multi-Target Prediction
Uni-Hand's ability to forecast specific joints extends conventional target prediction, revealing its adaptability to different hand models like MANO and UmeTrack. This multi-target capability is especially beneficial for detailed interactive sessions where precise joint movement prediction is crucial.
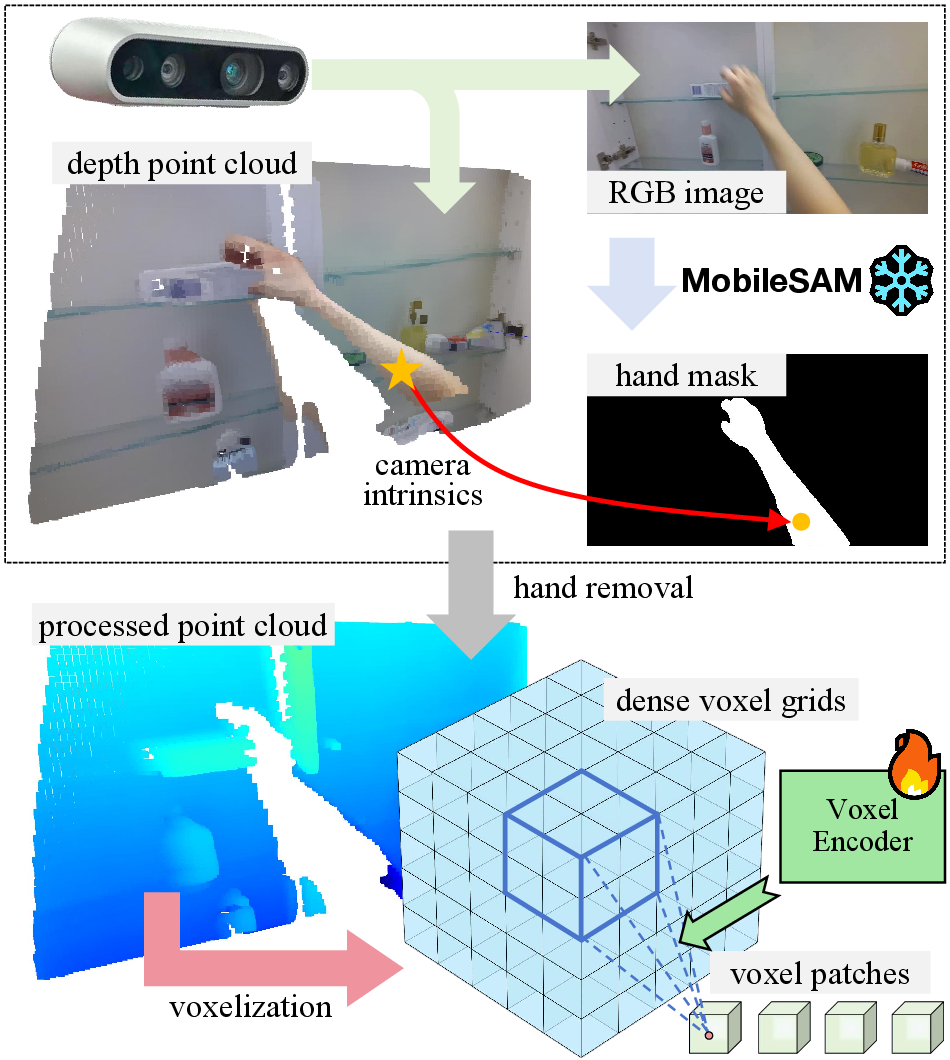
Figure 4: Hand removal for purified point clouds. We regard the voxel patches encoded by the voxel encoder as 3D global context for the denoising process in the HMF diffusion.
Downstream Applications
Through practical deployments on robotic platforms like ALOHA, Uni-Hand proves its applicability in real-world settings. Its hand motion predictions guide autonomous manipulation tasks efficiently, handling challenges such as language conditioning and long-horizon planning.
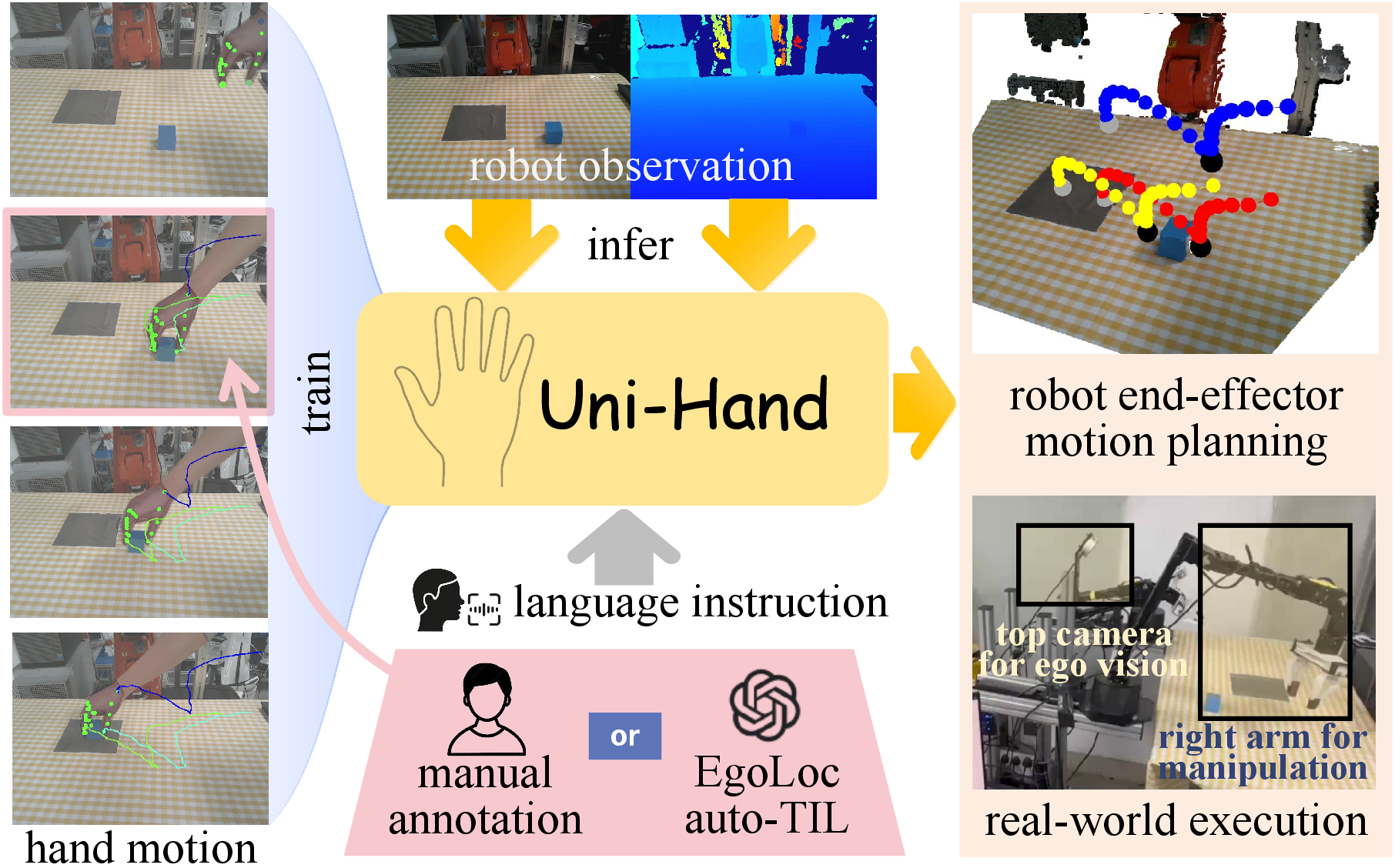
Figure 5: Our scheme to deploy Uni-Hand to real-world robotic manipulation tasks.
Conclusion
Uni-Hand stands as a versatile framework poised to enhance human-machine interaction by accurately forecasting hand dynamics in diverse settings. Its holistic approach in multi-dimensional, multi-target prediction alongside multi-modal fusion marks significant progress over existing paradigms. With future expansion towards 3D HOI analysis and scalable robotics integration, Uni-Hand holds promise for advancing both foundational research and practical deployments in embodied intelligence.