LLMCache: Layer-Wise Caching Strategies for Accelerated Reuse in Transformer Inference
Abstract: Transformer-based LLMs have achieved remarkable performance across a wide range of tasks, yet their high inference latency poses a significant challenge for real-timeand large-scale deployment. While existing caching mechanisms,such as token-level key-value caches, offer speedups in autore-gressive decoding, they are limited in scope and applicability. In this paper, we present LLMCache, a novel layer-wise caching framework that accelerates transformer inference by reusing intermediate activations based on semantic similarity of input sequences. Unlike prior work, LLMCache is model-agnostic,operates across both encoder and decoder architectures, and supports caching at arbitrary transformer layers. We introduce a lightweight fingerprinting mechanism for matching seman-tically similar inputs and propose adaptive eviction strategies to manage cache staleness. Experiments on BERT and GPT-2 across SQuAD, WikiText-103, and OpenBookQA show up to 3.1 X speedup in inference time with <0.5% accuracy degradation. Our results highlight LLMCache as a practical and general-purpose solution for optimizing transformer inference in real-world applications
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a way to make big LLMs (like BERT and GPT-2) respond faster without changing how they’re built or trained. The idea is called “LLMCache,” and it speeds up the model by reusing work it has already done when new inputs are similar to previous ones. It’s like not redoing the same math problem from scratch if you’ve already solved a very similar one before.
What questions did the researchers ask?
The paper focuses on three simple questions:
- Can we skip parts of a model’s work when new inputs are similar to past inputs?
- Can this work for different kinds of models (both those that read text and those that generate text)?
- Can we make things faster without hurting accuracy in a noticeable way?
How did they do it?
To understand the approach, it helps to know a bit about transformers and caching.
Transformers in simple terms
Think of a transformer model as an assembly line with multiple stations (called layers). Each station transforms the text into a more detailed understanding. Normally, every input goes through every station, even if it looks a lot like something the model just processed.
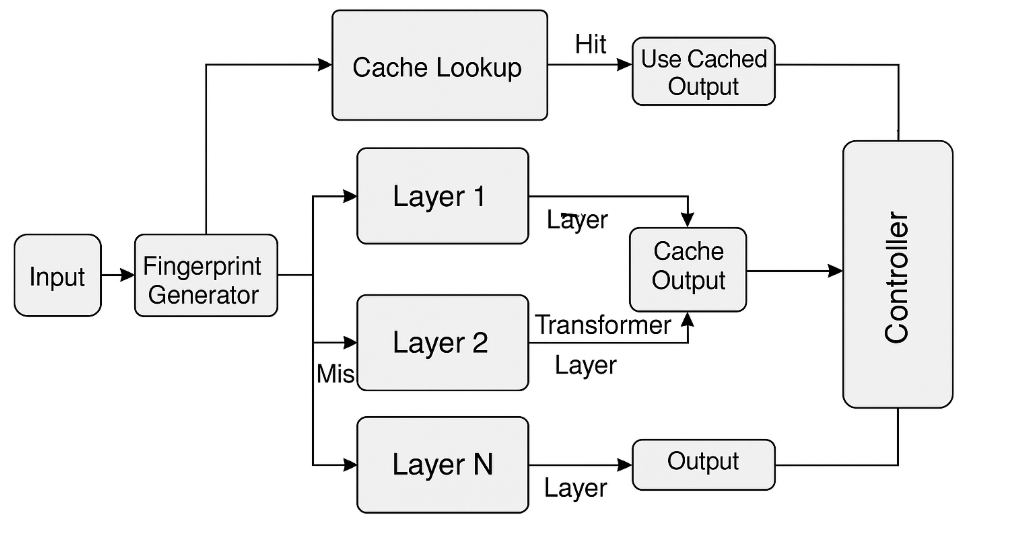
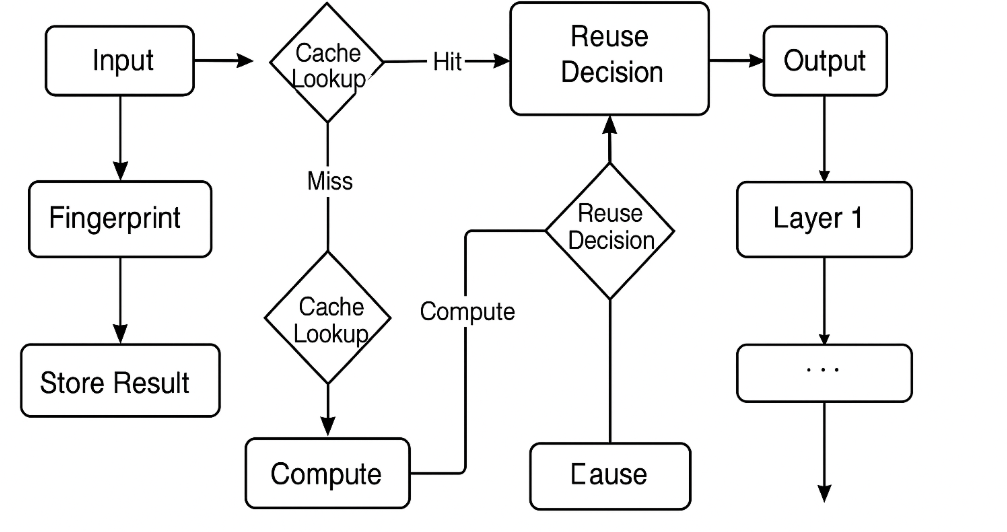
The main idea: layer-wise caching
LLMCache keeps a “notebook” of results from different stations (layers). If a new input is very similar to a past one, the model can reuse the saved result from that station instead of doing the work again. This is called “caching.”
- “Activations” are the station outputs (the model’s intermediate understanding at each layer).
- “Layer-wise” means caching happens at many different stations, not just at the attention step or for individual tokens.
Matching similar inputs with fingerprints
The system gives each input a short “fingerprint,” which is like a compact summary or ID card of what the input means. It uses simple, fast techniques (like SimHash or MinHash) so fingerprints can be compared quickly.
- If the new fingerprint is similar enough to one already in the notebook (above a set similarity threshold), LLMCache reuses the saved activation.
- If not, the model computes that layer’s result as usual and then saves it for future use.
Deciding when to use the cache
At each station (layer), LLMCache checks:
- “Do we have a similar fingerprint already?”
- Yes: reuse the saved activation (skip the computation).
- No: do the computation, then save the result.
This works for both:
- Encoders (models that read and understand text, like BERT)
- Decoders (models that write/generate text, like GPT-2)
Keeping the cache useful and tidy
Caches can get old or too big, so the system removes entries that aren’t helpful anymore. It uses common strategies:
- LRU (Least Recently Used): remove things you haven’t used in a while.
- Staleness/divergence checks: remove things that stop matching well over time.
- Size limits: balance memory use with speed gains.
What did they find?
The researchers tested LLMCache on:
- Models: BERT-base, DistilBERT, GPT-2 small
- Tasks: reading comprehension (SQuAD v2), language modeling (WikiText-103), and multiple-choice questions (OpenBookQA)
Key results:
- Speed: Up to 3.1× faster inference. For example, BERT-base saw about a 2.4× speedup, and GPT-2 got faster than standard token-level “KV caching.”
- Accuracy: Almost unchanged, typically less than 0.5% drop. In other words, the answers stayed basically the same.
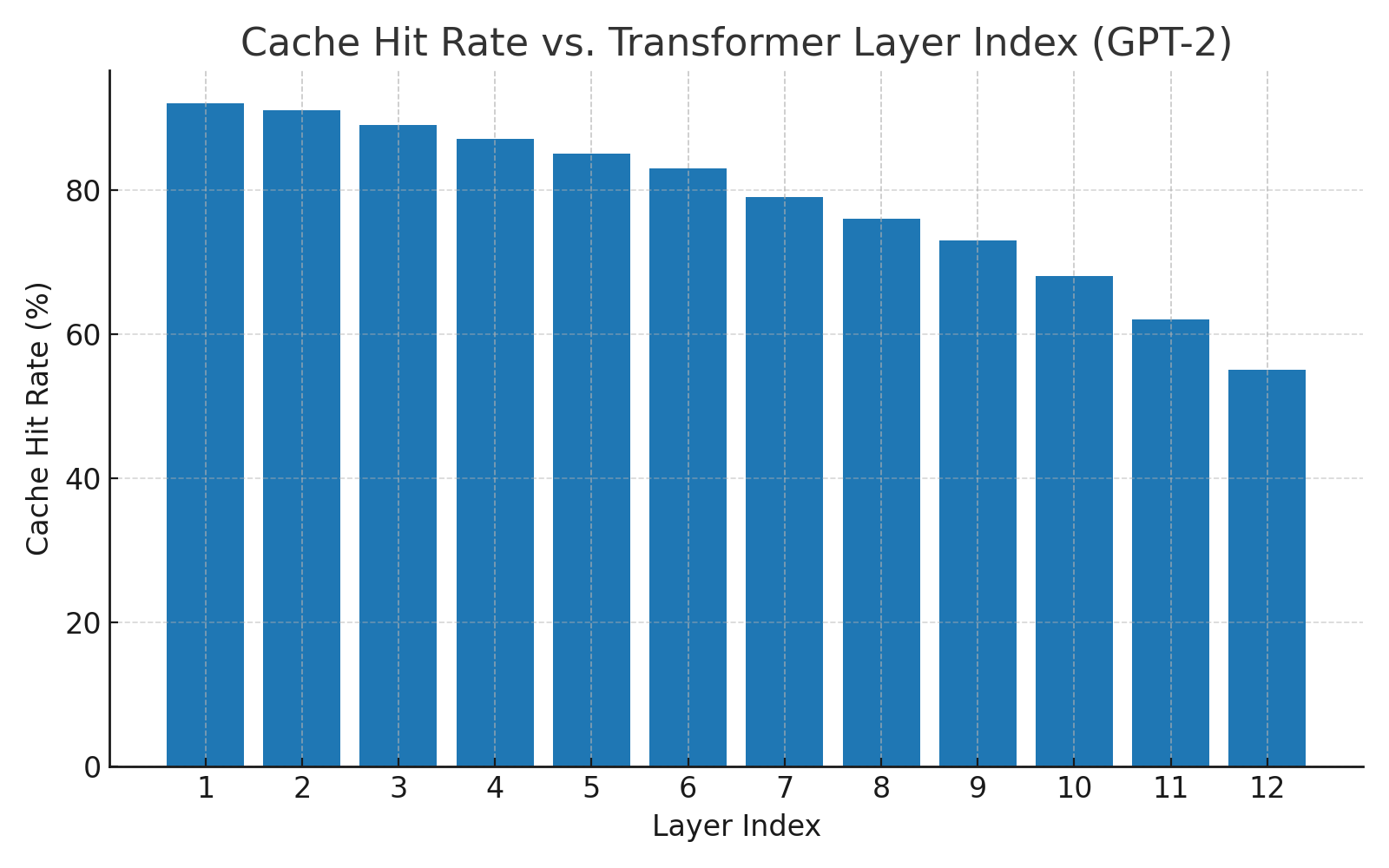
- Cache hit patterns: Lower and middle layers had the highest reuse (sometimes over 90%), because they capture general meaning that doesn’t change much with small input differences.
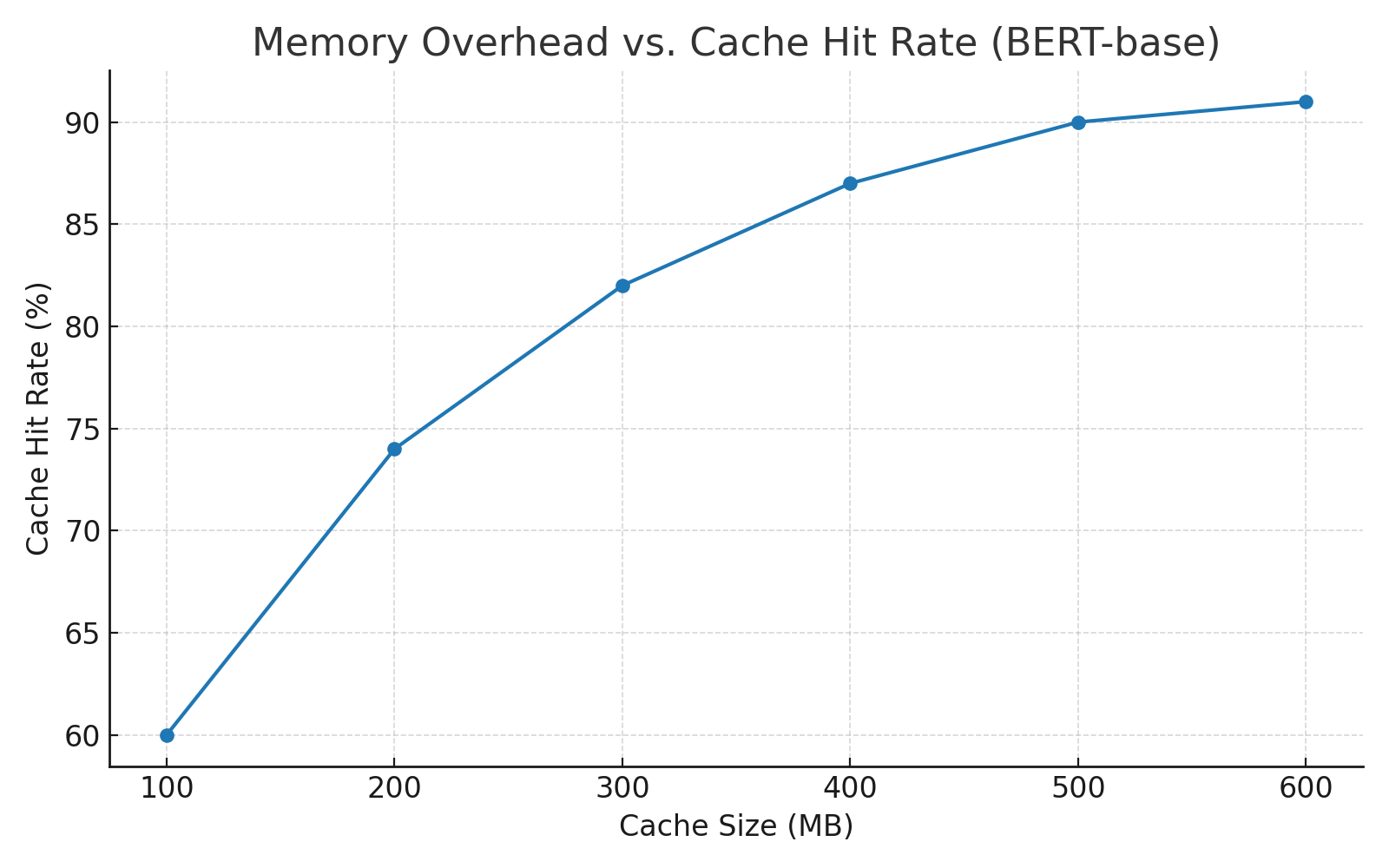
- Memory trade-offs: Bigger caches improve reuse but give diminishing returns; careful fingerprinting helps keep memory usage reasonable.
Why does it matter?
This approach is useful in real-world situations where many inputs are similar:
- Chatbots that handle repeated questions or templated prompts
- Document pipelines that process forms, reports, or pages with boilerplate
- Systems that use the same prefixes or context across many queries
By skipping repeated work inside the model, apps can respond faster and serve more users without needing new hardware or retraining smaller, less accurate models.
In short:
- It’s general-purpose: works for both reading and generating models.
- It’s practical: no changes to model architecture and no retraining needed.
- It’s efficient: faster responses with almost the same accuracy.
Looking ahead, this kind of “semantic reuse” could make LLMs more affordable and responsive at scale, especially in production systems that see lots of similar inputs.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a single, clear list of concrete gaps and open questions left unresolved by the paper, designed to guide future research.
- Applicability to large-scale LLMs remains untested: no evaluation on contemporary models (≥7B/13B parameters) or very long contexts (≥4k–32k tokens).
- Claims of encoder–decoder generality are not validated: no experiments on architectures like T5, UL2, or modern instruction-tuned models.
- Latency sources are not decomposed: missing breakdown of speedups attributable to cache hits versus overheads from fingerprinting, lookup, compression/decompression, and CPU–GPU transfers.
- Fingerprint collisions and false positives are unquantified: collision rates, mis-match probabilities, and their impact on accuracy are not measured.
- Fingerprint design choices lack detail: dimensionality, hashing parameters (e.g., SimHash/MinHash settings), and selection/tuning methodology are unspecified.
- No theoretical guarantees: conditions under which layer activations are “stable” enough for safe reuse are not formalized; bounds on reuse-induced error are absent.
- Robustness under distribution shift is untested: performance with adversarial paraphrases, subtle semantic changes, or domain drift (e.g., OOD inputs) is unknown.
- Layer selection policy is undeveloped: criteria for which layers to cache (versus compute) and the resulting speed–fidelity trade-offs are not explored.
- Eviction strategies are proposed but not compared: LRU, frequency-based, and divergence-aware policies lack empirical evaluation and guidance for workload-specific tuning.
- Divergence monitoring is underspecified: concrete metrics, thresholds, and triggers for revalidation (without labels) are not defined or tested.
- Memory scaling is under-characterized: per-layer, per-sequence cache footprint and planning guidelines for large models are missing.
- Compression effects are unmeasured: the accuracy/hit-rate impact of PCA/autoencoder compression and the parameters/codecs used are not reported.
- Cache placement trade-offs are unclear: latency penalties of storing caches on CPU vs GPU (PCIe/NVLink costs) are not quantified.
- Positional encoding sensitivity is unknown: reuse across inputs with different token positions or sequence lengths may be unsafe but is untested.
- Streaming and multi-turn contexts are not evaluated: behavior with growing chat histories, partial-context reuse (prefix vs suffix), and incremental updates remains open.
- Synergy with KV caching is unexplored: combining token-level KV caches with layer-wise activation reuse may yield different optimal designs.
- Generative metrics are missing: GPT-2 evaluations rely on “accuracy”; perplexity, ROUGE, BLEU, or human assessments of generative quality are absent.
- Cold-start behavior is not reported: cache warm-up time, initial miss rates, and break-even analysis for low-repetition workloads are missing.
- Concurrency and throughput are untested: performance with batch sizes >1, multi-request servers, and cache contention/locking overhead is unknown.
- Distributed caching remains conceptual: cross-node sharing, consistency, replication, and coherence protocols for multi-node serving are not designed or evaluated.
- Privacy and multi-tenant isolation are unaddressed: risks of hidden-state leakage across users, and policies for encryption/access control are not discussed.
- Security risks are unexplored: fingerprint collision attacks, cache poisoning, and adversarial matching vulnerabilities lack analysis.
- Interaction with other optimizations is unknown: compatibility or interference with quantization, pruning, distillation, FlashAttention, and sparsity methods is not studied.
- Generality across domains and tokenization is unvalidated: multilingual, code, and domain-specific inputs may break fingerprint robustness; no tests provided.
- Model update staleness is unquantified: strategies for invalidating caches across fine-tuning or version changes and their operational costs are missing.
- Energy/cost benefits are not measured: speedups are reported without power or cloud cost analyses; efficiency gains may not translate directly.
- Implementation portability is unclear: integration with vLLM, TensorRT-LLM, ONNX Runtime, JAX/XLA, or graph-level compilers is not demonstrated.
- Failure modes and safeguards are absent: no error analysis of harmful reuse cases or rollback/guardrail mechanisms (e.g., selective recompute on uncertainty).
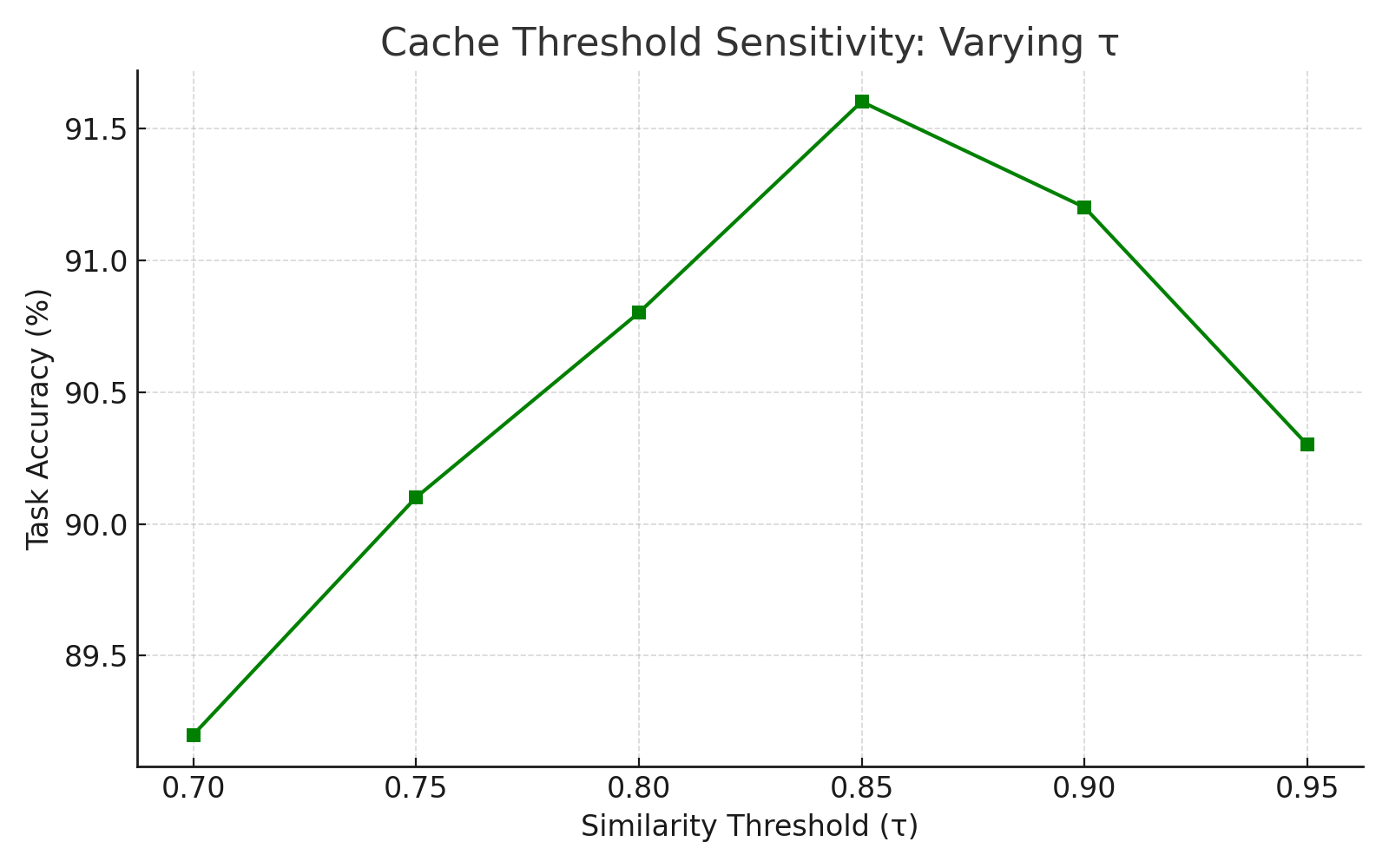
- Parameter tuning guidance is thin: only τ ranges are given; automatic or data-driven selection of τ, cache size, and compression parameters is not provided.
- Effects on attention distributions and calibration are unknown: whether reuse biases attention or affects uncertainty estimates is unmeasured.
- Benchmark coverage is limited: tasks emphasizing long contexts, RAG pipelines, and real-world traffic patterns are not included.
- Hardware generalization is untested: only A100 and batch size 1 are used; behavior on other GPUs, CPUs, and mixed-precision settings is unknown.
- Legal/compliance implications are not discussed: retention policies, data residency, and PII concerns when storing activations remain open.
- Reproducibility details are missing: code, configurations, fingerprinting implementation, cache parameters, and exact hyperparameters are not provided.
- Upper-layer sensitivity is noted but unresolved: strategies for partial reuse (e.g., subcomponents) or mitigation for unstable higher layers are not explored.
- Decoding strategy interactions are unclear: impacts on beam search, nucleus sampling, and token-by-token variability in autoregressive generation remain to be studied.
Practical Applications
Practical Applications of LLMCache
The paper presents LLMCache, a model-agnostic, layer-wise activation caching framework that reuses intermediate transformer representations for semantically similar inputs, yielding up to 3.1× speedups with <0.5% accuracy loss. Below are concrete, real-world applications across industry, academia, policy, and daily life, categorized by deployment readiness. Each item notes relevant sectors, potential tools/products/workflows, and feasibility assumptions or dependencies.
Immediate Applications
These use cases can be deployed now with careful engineering integration (e.g., PyTorch forward-pass hooks, cache banks per layer, similarity threshold tuning).
- Customer support and sales chatbots
- Sectors: Software, Customer Support, Retail, Telecom
- Tools/products/workflows: Integrate LLMCache into chatbot serving stacks (e.g., TorchServe, Triton Inference Server, FastAPI microservices) to cache common system prompts, templates, and repeated intents; combine with KV-cache for generation.
- Assumptions/dependencies: High overlap in prompts and boilerplate; memory budget for layer-wise activations; τ (similarity threshold) tuning to keep <0.5% quality loss; per-tenant cache isolation for privacy.
- Retrieval-augmented generation (RAG) with common prefixes
- Sectors: Search, Enterprise Knowledge Management, SaaS
- Tools/products/workflows: Cache early/mid-layer activations for fixed system prompts and frequently retrieved context chunks; integrate into LangChain/LlamaIndex pipelines; store cache on CPU RAM with optional PCA/SimHash compression.
- Assumptions/dependencies: Reused system prompts and recurring documents; effective fingerprinting (MinHash/SimHash) overhead is small relative to saved compute; cache eviction tuned to doc drift.
- Document processing pipelines with boilerplate
- Sectors: LegalTech, Insurance, Finance (KYC/AML), HR
- Tools/products/workflows: Apply to BERT/DistilBERT for classification, NER, and routing of forms/contracts with repeated sections; deploy in batch or streaming pipelines to improve throughput.
- Assumptions/dependencies: Stable templates and repeated sections across documents; cache storage sized to throughput; accuracy constraints acceptable given reported <0.5% drop.
- In-editor code assistants and CI bots
- Sectors: Software Development Tools
- Tools/products/workflows: Cache layer activations for recurrent code contexts (imports, headers, common function templates) in IDE servers or CI linting/analysis; integrate with LSP backends.
- Assumptions/dependencies: Repeated code scaffolding; quick fingerprinting of file/buffer segments; managing cache staleness during rapid edits.
- On-device/mobile NLP for smart replies and predictive text
- Sectors: Consumer Electronics, Mobile OS
- Tools/products/workflows: Use with DistilBERT/small GPT variants on-device to cache frequent phrase completions or intent templates; reduce CPU/GPU cycles and battery drain.
- Assumptions/dependencies: Memory constraints require compressed caches; strong privacy boundaries (no cross-user sharing); stable user input patterns.
- Moderation and safety filtering at scale
- Sectors: Social Media, Gaming, Messaging
- Tools/products/workflows: Cache early-layer activations for common toxicity/abuse patterns to accelerate classification; integrate with existing moderation APIs.
- Assumptions/dependencies: High redundancy in messages; careful τ settings to avoid false negatives; data isolation by jurisdiction/user group.
- Healthcare clinical note processing
- Sectors: Healthcare, Health IT
- Tools/products/workflows: Speed up ICD coding, template-based summarization, and triage classification where notes share structured templates; deploy behind HIPAA-compliant boundaries.
- Assumptions/dependencies: Strict accuracy and auditability; privacy-preserving cache management (no cross-patient sharing); validation to ensure negligible clinical impact.
- Contact center and public-sector digital services
- Sectors: Government, Public Services
- Tools/products/workflows: Cache activations for standard forms, FAQs, eligibility checks to reduce latency and cloud spend; report energy savings as part of Green IT metrics.
- Assumptions/dependencies: Repetitive workflows; clear operational controls on cache retention policies; potential requirement for deterministic behavior.
- E-commerce personalization and UGC analysis
- Sectors: E-commerce, Marketplaces
- Tools/products/workflows: Apply to review moderation, FAQ answering, and product attribute extraction where product descriptions are repeated.
- Assumptions/dependencies: High content redundancy; cache memory sized per category; threshold tuning to respect brand safety constraints.
- MLOps cost and throughput optimization
- Sectors: Platform Engineering, Cloud
- Tools/products/workflows: Ship LLMCache as a middleware plugin for TorchServe/Triton; add observability (cache hit rate per layer, latency histograms); combine with quantization/pruning.
- Assumptions/dependencies: Compatibility with fused kernels and inference graphs; safe fallbacks on cache miss; ops policies for cache warm-up and eviction (LRU, divergence-aware).
Long-Term Applications
These opportunities need further research, scaling, or ecosystem development (e.g., distributed cache sharing, learned fingerprints, privacy controls).
- Distributed, multi-node cache sharing (“activation CDN”)
- Sectors: Cloud, SaaS, Content Platforms
- Tools/products/workflows: Cross-pod/node sharing of fingerprints and compressed activations to maximize reuse in large clusters; cache registries with gRPC/RDMA; topology-aware placement.
- Assumptions/dependencies: Low-latency networking; privacy isolation, encryption, and tenant-aware partitioning; admission control to prevent cache poisoning; standards for activation serialization.
- Privacy-preserving federated caching on edge
- Sectors: Mobile, IoT, Automotive
- Tools/products/workflows: Federated aggregation of fingerprints (or secure sketches) across devices to benefit from shared patterns without exposing content; homomorphic hashing or secure enclaves.
- Assumptions/dependencies: Strong privacy guarantees; efficient compression; robust staleness/poisoning detection.
- Learned fingerprinting and adaptive τ per layer/input
- Sectors: All sectors using LLMs at scale
- Tools/products/workflows: Train lightweight encoders to predict cacheability and dynamic thresholds; uncertainty-aware reuse policies; automated per-layer cache selection.
- Assumptions/dependencies: Additional training data; interpretability and stability of learned fingerprints; guardrails to prevent quality regressions.
- Cross-model and cross-version cache portability
- Sectors: Platform Engineering, Model Hosting
- Tools/products/workflows: Map cached activations across fine-tuned variants or adapter-augmented models (e.g., LoRA); versioned caches with compatibility layers.
- Assumptions/dependencies: Representational alignment techniques; risk of distribution shifts; version-aware fallbacks.
- Integration with vector databases for RAG-aware caching
- Sectors: Search, Knowledge Management
- Tools/products/workflows: Store fingerprints alongside embeddings in vector DBs; cache activations per document chunk; co-schedule retrieval and cache hits in serving.
- Assumptions/dependencies: Joint indexing schemes; cache invalidation when content updates; consistency between retriever and generator models.
- Hardware–software co-design for activation caching
- Sectors: Semiconductors, Cloud Infrastructure
- Tools/products/workflows: GPU/TPU memory hierarchy support for activation caches (e.g., fast shared memory for early layers, NVLink-aware spillover); ISA primitives for cache lookup.
- Assumptions/dependencies: Vendor adoption; benchmarks demonstrating consistent wins; scheduling policies integrated with kernel fusion.
- Training-time acceleration via reuse (semi-static batches)
- Sectors: Research, Enterprise AI
- Tools/products/workflows: Explore caching forward activations during fine-tuning for repeated prompts or curriculum steps; reuse where gradient paths are not affected.
- Assumptions/dependencies: Non-trivial due to backprop requirements; correctness and stability guarantees needed; may be limited to certain curricula.
- Energy- and cost-aware policy frameworks
- Sectors: Policy, Sustainability
- Tools/products/workflows: Use LLMCache-based savings to support green-computing procurement guidelines, carbon reporting for AI services, and incentives for reuse-centric optimizations.
- Assumptions/dependencies: Standardized measurement (latency, energy per request); third-party audits; alignment with regulatory bodies.
- Safety-critical real-time systems (e.g., robotics, automotive)
- Sectors: Robotics, Automotive, Aerospace
- Tools/products/workflows: Apply to language or instruction-following modules with repeated command templates; deterministic cache policies with watchdogs for fallback computation.
- Assumptions/dependencies: Rigorous validation, worst-case latency bounds, and fail-safe fallbacks; certification pathways.
- Healthcare diagnostics and clinical decision support at scale
- Sectors: Healthcare
- Tools/products/workflows: Post-approval integration for high-volume but template-rich tasks (e.g., discharge summary generation) with clinically validated thresholds and monitoring.
- Assumptions/dependencies: Extensive clinical trials; bias and drift monitoring; regulatory approval and audit trails.
- Commercial “LLMCache-as-a-Service”
- Sectors: Cloud Providers, Model Marketplaces
- Tools/products/workflows: Managed caching layer for hosted LLMs (e.g., AWS/Azure/GCP), exposing APIs for cache policies, observability, and tenancy controls.
- Assumptions/dependencies: Provider integration; SLAs for latency/consistency; secure data handling and partitioning.
Notes on feasibility common to many applications:
- Workload affinity: Benefits are largest where inputs share templates, prefixes, or semantic cores; highly variable inputs reduce hit rates.
- Memory/latency trade-offs: Bigger caches raise hit rates but increase RAM/GPU pressure; compression (PCA/autoencoders) mitigates this at some fidelity cost.
- Quality controls: τ typically in 0.82–0.88 range per the paper; per-layer tuning and divergence-aware eviction reduce accuracy impact.
- Security and privacy: Prevent cross-tenant leakage; encrypt cache at rest/in transit; strict scoping and TTLs.
- Compatibility: Works with encoder and decoder models; can complement KV caching; may need care with fused kernels and quantized/pruned deployments.
Glossary
- Ablation studies: Controlled experiments that remove or vary components to understand their effect on performance. "Ablation Studies"
- Adaptive eviction strategies: Policies that dynamically decide which cache entries to remove based on usage and relevance. "and propose adaptive eviction strategies to manage cache staleness."
- Autoencoder projections: Compressed representations produced by autoencoders to reduce dimensionality of cached activations. "the system optionally compresses cached representations via PCA or autoencoder projections."
- Autoregressive decoding: Generation where each new token is produced conditioned on previously generated tokens. "token-level key-value caches, offer speedups in autoregressive decoding"
- Cache hit rate: The percentage of lookup attempts that successfully find a reusable cached entry. "Cache Hit Rate (\%)"
- Cache staleness: The degradation in cache relevance over time as inputs or model behavior drift. "and propose adaptive eviction strategies to manage cache staleness."
- Cosine similarity: A similarity measure between vectors based on the cosine of the angle between them. "Matching uses cosine similarity or Jaccard index depending on the fingerprinting scheme."
- Decoder-only settings: Model configurations containing only a decoder, typical in autoregressive transformers. "Key-value (KV) caching... is limited to decoder-only settings and primarily targets token-level reuse."
- Divergence-aware eviction: Cache removal policy that considers changes in outputs for similar fingerprints to prevent reuse drift. "Least-recently-used (LRU), frequency-based, and divergence-aware eviction policies are supported."
- Embedding aggregation: Combining token embeddings (e.g., averaging) to form a compact representation of input semantics. "Embedding Aggregation: captures the overall semantic content."
- Encoder-decoder architectures: Transformer setups with both an encoder and a decoder, common in sequence-to-sequence tasks. "supports encoder and encoder-decoder architectures."
- Fingerprinting mechanism: A lightweight method to generate compact identifiers for inputs to enable cache matching. "We introduce a lightweight fingerprinting mechanism for matching semantically similar inputs"
- Forward pass: The computation through all layers of a model to produce outputs from inputs. "standard inference pipelines perform full forward passes through all transformer layers."
- GPU shared memory: Fast, on-chip memory on GPUs that can be used to store frequently accessed data like cache entries. "Caches can be stored in CPU RAM or GPU shared memory depending on system constraints."
- Jaccard index: A set-based similarity metric measuring the overlap between two sets. "Matching uses cosine similarity or Jaccard index depending on the fingerprinting scheme."
- Key-value (KV) caching: Storing attention keys and values from prior steps to avoid recomputation in autoregressive models. "Key-value (KV) caching, used widely in autoregressive generation"
- KV-Cache: An implementation baseline that applies token-level key-value caching during decoding. "KV-Cache: Token-level key-value caching used in GPT-style decoding"
- Layer-wise Cache Banks: Per-layer storage structures holding fingerprints and corresponding hidden states for reuse. "Layer-wise Cache Banks"
- Layer-wise caching: Reusing intermediate activations at specific transformer layers based on input similarity. "a layer-wise caching framework"
- Least-recently-used (LRU): Eviction policy that removes the cache entry that has not been used for the longest time. "Least-recently-used (LRU), frequency-based, and divergence-aware eviction policies are supported."
- Locality-Sensitive Hashing (LSH): Hashing technique that preserves similarity, allowing efficient approximate nearest-neighbor search. "Fingerprints are compared via cosine similarity or LSH"
- MinHash: A hashing technique that approximates Jaccard similarity between sets for fast matching. "we use MinHash or SimHash-based techniques to ensure sub-linear comparison cost."
- Operator-level caching: Reusing outputs of lower-level operations (operators) to speed up inference. "DeepSpeed-Inference supports operator-level caching and pipelining."
- PCA: Principal Component Analysis, a dimensionality reduction technique to compress representations. "SimHash or PCA ensures compact and comparable vectors."
- Prefix attention stats: Summary statistics of early self-attention outputs used to stabilize fingerprints. "Prefix Attention Stats: Mean of initial self-attention outputs improves robustness to token shifts."
- Retrieval-augmented generation (RAG): Techniques that retrieve external information to condition generation. "retrieval-augmented generation"
- Semantic caching: Reuse based on semantic similarity rather than exact token matches. "Semantic caching is a nascent direction in NLP."
- Semantic fingerprint: A compact vector summarizing input semantics used as a cache key. "LLMCache first computes a semantic fingerprint ."
- SimHash: A hashing method that maps high-dimensional vectors to compact binary codes preserving similarity. "we use MinHash or SimHash-based techniques to ensure sub-linear comparison cost."
- Similarity threshold τ: The minimum similarity required between fingerprints to reuse cached activations. "The similarity threshold is tunable."
- Staleness-aware eviction: Removing cache entries whose match quality has decayed over time. "Staleness-aware Eviction: Removes entries with decayed match rates over time."
- Structured pruning: Systematically removing model components (e.g., heads or blocks) to reduce computation. "Structured pruning selectively removes blocks or heads in transformer layers."
- Temporal decay factors: Time-based weights used to diminish the influence of old fingerprints and evict them. "Additionally, temporal decay factors are used to flush outdated fingerprints over time."
- Vector reuse: Reusing previously computed vector representations to avoid recomputation. "leverage vector reuse but are confined to fixed-passage scenarios and do not support dynamic input reuse."
Collections
Sign up for free to add this paper to one or more collections.

