- The paper introduces a minimalistic single-stage RL training strategy with fixed hyperparameters that achieves state-of-the-art reasoning performance on 1.5B LLMs.
- The paper demonstrates that this approach yields significant gains, achieving up to a 70+% score on benchmarks while using half the computational resources compared to complex methods.
- The paper advocates a paradigm shift by favoring robust, simple baselines over intricate multi-stage pipelines, ensuring stable training and efficient scaling.
JustRL: Scaling a 1.5B LLM with a Simple RL Recipe
Introduction
The paper "JustRL: Scaling a 1.5B LLM with a Simple RL Recipe" presents an approach that challenges the prevailing complexity in training LLMs using reinforcement learning (RL). Recent advancements in this domain typically involve intricate multi-stage pipelines, dynamic hyperparameter scheduling, and curriculum strategies. This paper proposes a minimalistic, single-stage training strategy with fixed hyperparameters, which generates state-of-the-art results for 1.5B parameter reasoning models while using half the computational resources compared to more sophisticated methods.
Methodology
Training Setup
The approach leverages a default implementation of GRPO in veRL, maintaining fundamental simplicity through single-stage training and fixed hyperparameters, avoiding the complexities of multi-stage training, dynamic adjustments, and data curation strategies:
- Single-stage training: Continuous training without progressive context adjustments or curriculum transitions.
- Fixed hyperparameters: Consistent settings throughout the training process without adaptive modifications.
- Core Algorithm: Utilizing lightweight rule-based verifiers and avoiding external symbolic libraries.
Table 1 provides a summary of the fixed hyperparameters utilized for training.
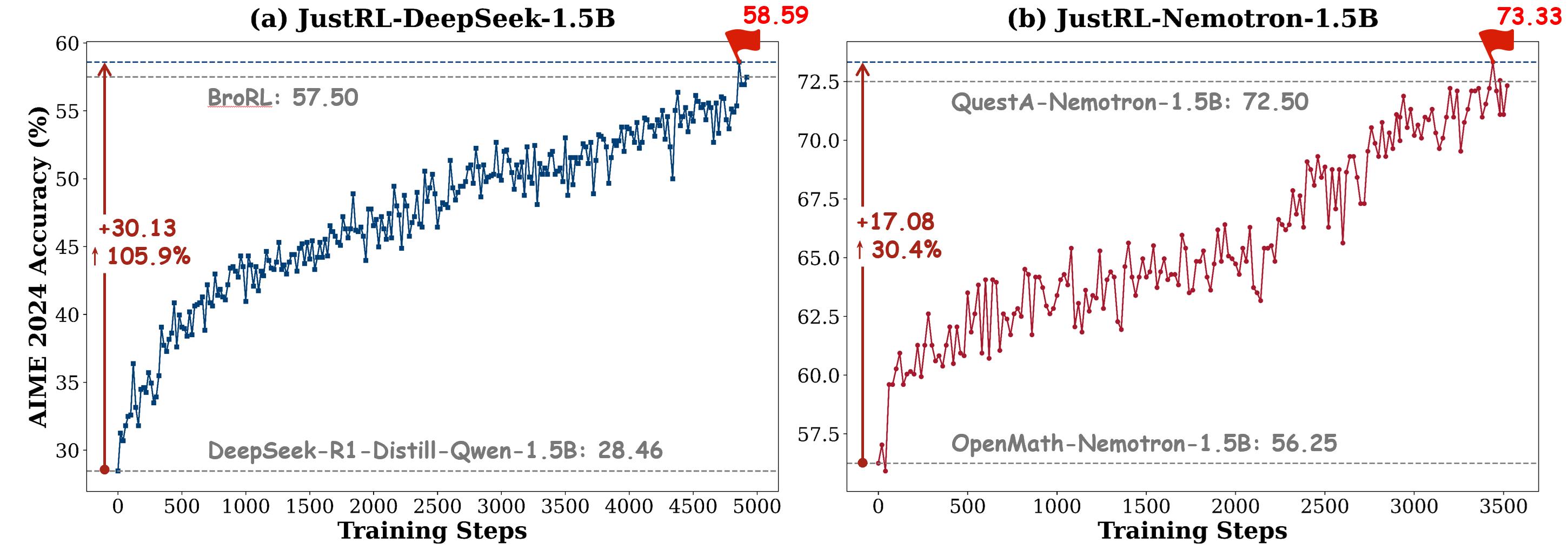
Figure 1: JustRL achieves substantial performance gains through simple, single-stage training. (a) The AIME24 (avg@32) performance curve for scaling from DeepSeek-R1-Distill-Qwen-1.5B into JustRL-DeepSeek-1.5B, from 28\% to 58\% over 4,000 steps; (b) from OpenMath-Nemotron-1.5B into our 1.5B reasoning SOTA model JustRL-Nemotron-1.5B, showing its training journey to the final 70+\% score over 3,000 steps.
Evaluation Protocol
Evaluation was conducted across nine challenging mathematical reasoning benchmarks, using both conventional tasks as well as rigorous evaluation protocols. Notably, the evaluations were reinforced with the CompassVerifier-3B to mitigate false negatives, bolstering the reliability of the results.
Experimental Results
The experimental results demonstrate the efficacy of JustRL in achieving substantial gains on two prominent 1.5B reasoning models, JustRL-DeepSeek-1.5B and JustRL-Nemotron-1.5B.
JustRL-DeepSeek-1.5B
The model exceeded expectations by achieving an average performance of 54.87% across nine benchmarks, leading in six of them (Table 2). The computational efficiency of this approach is noteworthy, as it employs half the computational resources of comparable methods (Table 3).
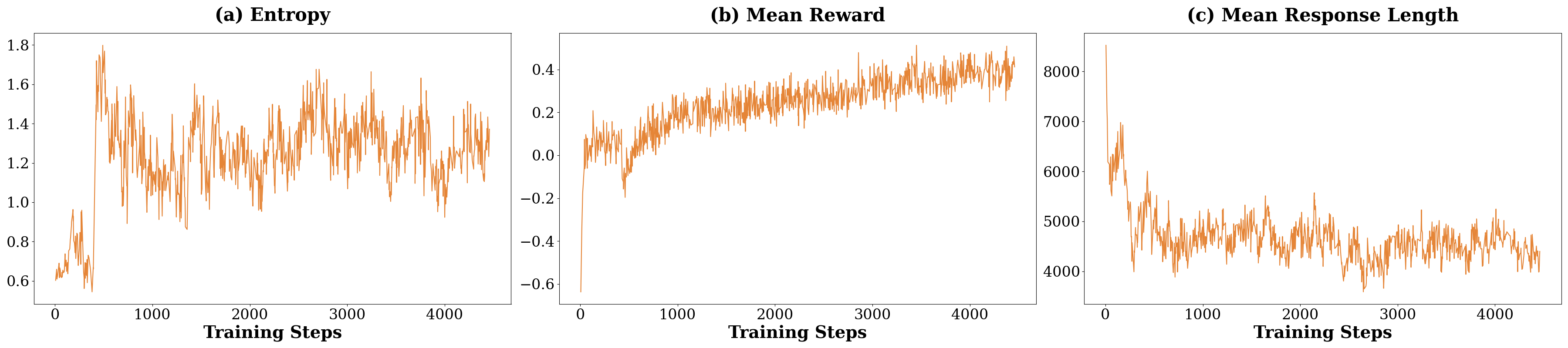
Figure 2: Training Dynamics of JustRL-DeepSeek-1.5B. (a) Policy entropy remains stable throughout training, oscillating naturally around 1.2-1.4 without drift or collapse. (b) Mean reward shows smooth, monotonic improvement from negative to ∼0.4, indicating consistent learning without plateau-breaking interventions. (c) Response length naturally converges from initial verbosity (∼7,000 tokens) to a stable range (4,000-5,000 tokens) with 16k max context length, without explicit length penalties.
JustRL-Nemotron-1.5B
Without hyperparameter tuning, JustRL-Nemotron-1.5B matches and even slightly outperforms state-of-the-art results using curriculum learning, achieving an overall average of 64.32% across benchmarks (Table 4).
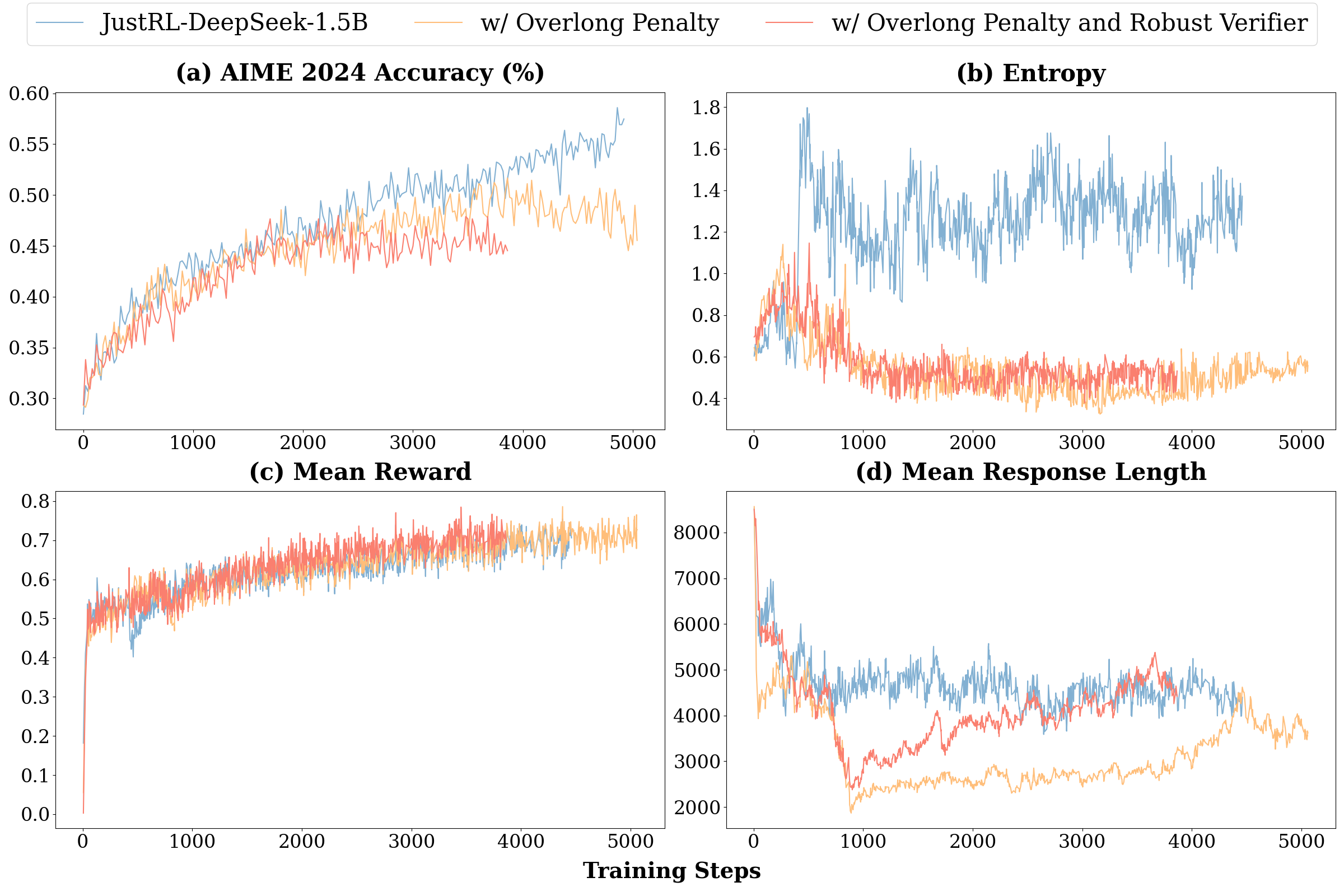
Figure 3: Ablation Study Results. (a) AIME 2024 performance diverges after ∼2,000 steps. Our base recipe reaches 55\%, while adding overlong penalty plateaus at 50\%, and adding both modifications plateaus at 45\%. (b) Entropy: Both modifications show collapsed exploration (entropy ∼0.5-0.6) compared to healthy oscillation in the base recipe (∼1.2-1.4).
Discussion
The simplicity of JustRL elucidates its robustness and high performance. Deliberately eschewing complex techniques highlights the unnecessary complexity introduced by current practices. The study showcases smooth training without typical instabilities, suggesting that complexity might address artifacts introduced by multifaceted pipelines rather than fundamental RL challenges.
Ablation studies further emphasize that additional modifications can degrade performance, suggesting an existing fine balance with minimal setups. The results propose a recalibration in methodology: establishing simple, robust baselines before integrating complexity.
Conclusion
This study boldly navigates the convoluted landscape of RL for LLMs, proposing a simple yet effective methodology that achieves competitive or superior performance with less compute resource investment. It advocates a paradigm shift towards starting with fundamental simplicity and scaling up, endorsing complexity only when essential. Future work should consider exploring similar strategies across different domains and model scales, using this approach as an empirical baseline.

