Prompt Repetition Improves Non-Reasoning LLMs
Abstract: When not using reasoning, repeating the input prompt improves performance for popular models (Gemini, GPT, Claude, and Deepseek) without increasing the number of generated tokens or latency.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows a surprisingly simple trick to make AI chatbots (like Gemini, GPT, Claude, and DeepSeek) answer questions better when you don’t ask them to “show their work.” The trick: repeat the user’s prompt once before the model answers. So instead of sending just your question, you send your question twice in a row. The authors find this often makes answers more accurate without making responses longer or slower.
What questions were the researchers asking?
The researchers wanted to know:
- Does repeating the prompt help LLMs give better answers when we don’t ask them to think step-by-step?
- Does this work across different AI models and different kinds of tests (like multiple choice and math)?
- Does it make replies slower or longer?
- Is the benefit really from repetition, or just from making the input longer?
How did they test their idea?
Think of an LLM like a student who reads from left to right. If you put answer choices before the question, the student sees the choices first and might get confused. If you repeat the whole thing, then on the “second read-through” the student has already seen everything once, so they can connect all the parts better.
What they did:
- They picked 7 popular models from different companies.
- They tried 7 test sets, including:
- Standard benchmarks (like science and general knowledge multiple-choice, plus math).
- Two simple list puzzles they made:
- NameIndex (find the 25th name in a list of 50).
- MiddleMatch (find which item sits directly between two others in a list with repeats).
- For each question, they compared:
- Baseline: ask the question once.
- Prompt repetition: paste the exact same question twice in a row.
- They measured:
- Accuracy (how often the model was right).
- Speed (how long it took to respond).
- Length of the model’s answer (number of output tokens).
- They also tried variations like repeating three times and adding filler dots (padding) to see if “just being longer” helps.
Helpful translations:
- “Reasoning on/off”: With reasoning on, you ask the model to “think step by step.” With it off, you ask for a short, direct answer.
- “Causal LLM”: The model reads from left to right and can only use what it has already seen. That means the order of your prompt matters.
- “Prefill stage”: The quick, parallel “reading” stage where the model takes in your prompt before it starts “writing” the answer.
What did they find, and why does it matter?
Key results:
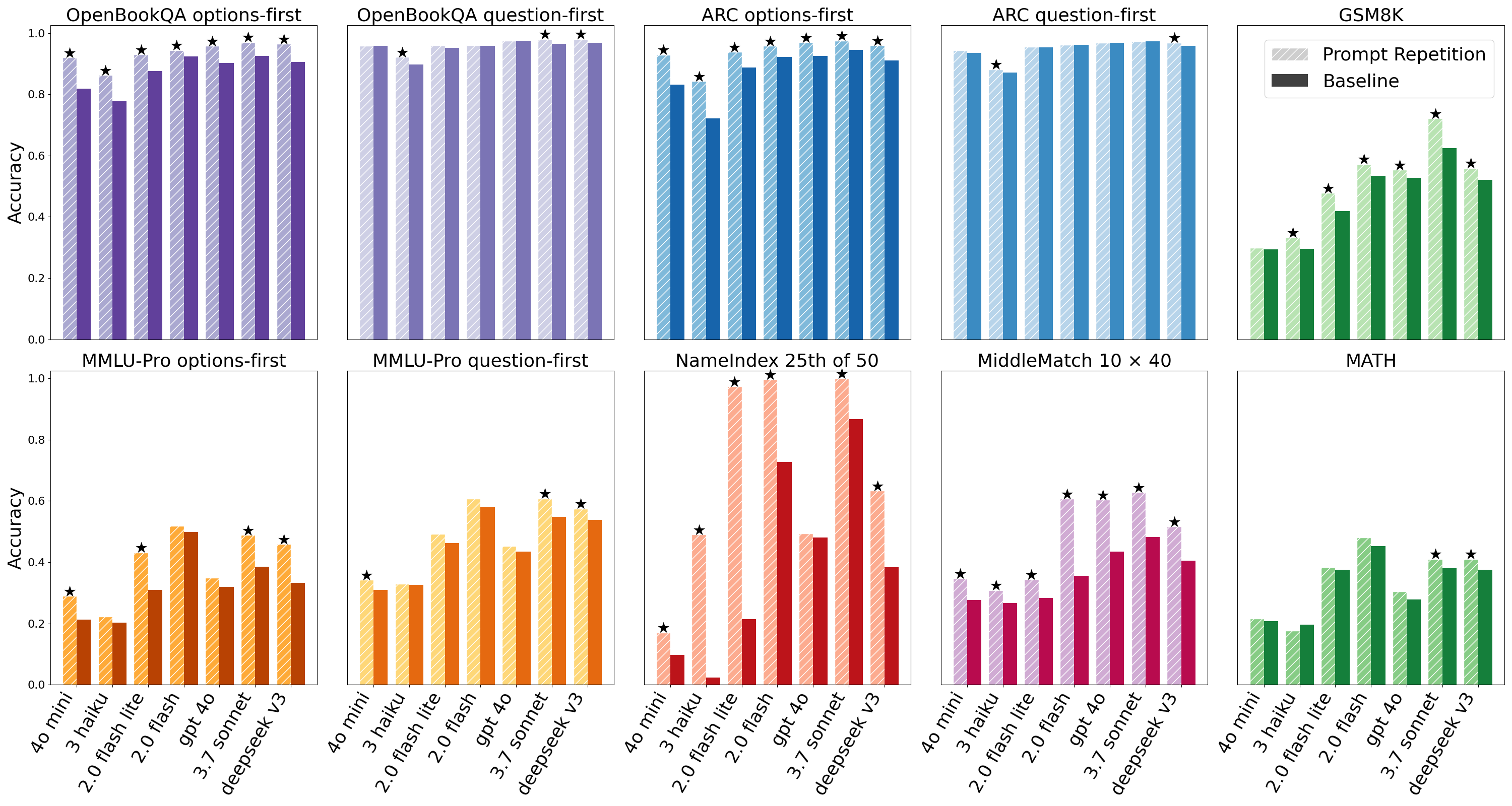
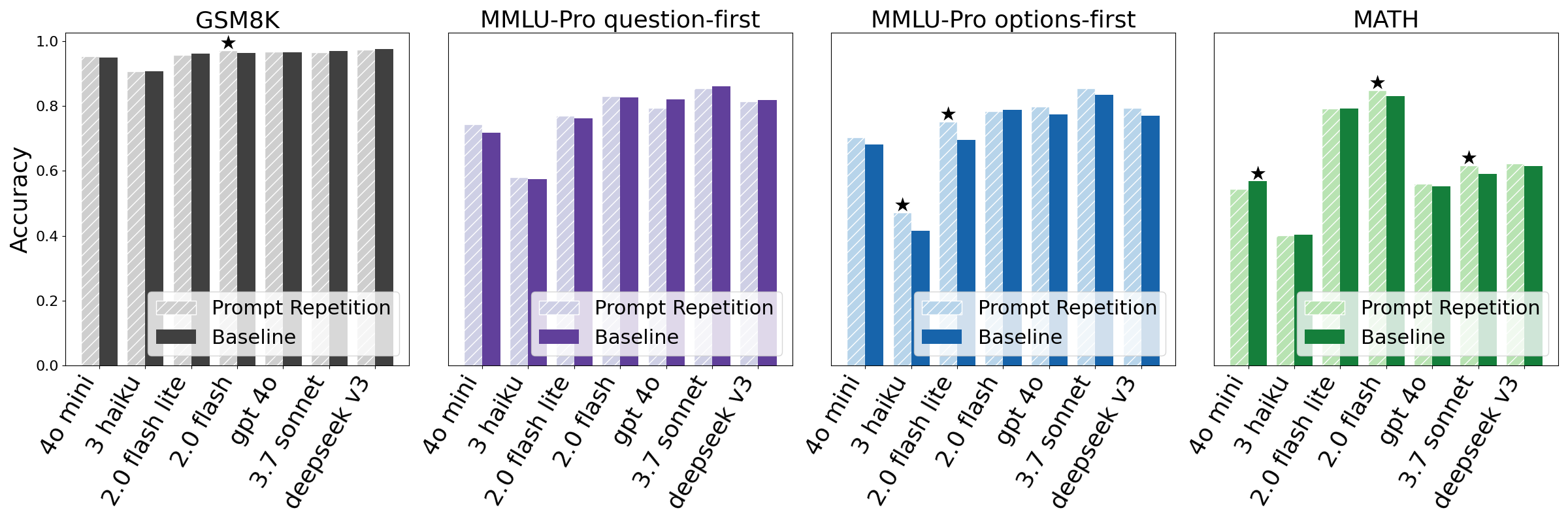
- Repeating the prompt improved accuracy a lot when “reasoning” was off. Across 70 model-and-dataset tests, the repeated prompt did better in 47 and worse in 0 (the rest were ties). They also used a simple statistical check to make sure these wins weren’t just luck.
- The biggest gains were on multiple-choice questions where the answer options came before the question (a tricky setup). Repetition helps the model connect the options with the question on the second pass.
- The two list puzzles saw especially strong improvements. For example, on NameIndex, one model jumped from about 21% right to about 97% right with repetition.
- When “reasoning” was on (asking the model to think step by step), repeating the prompt was neutral to slightly positive—often no big change. That makes sense because the model already tends to restate parts of the question during its step-by-step thinking.
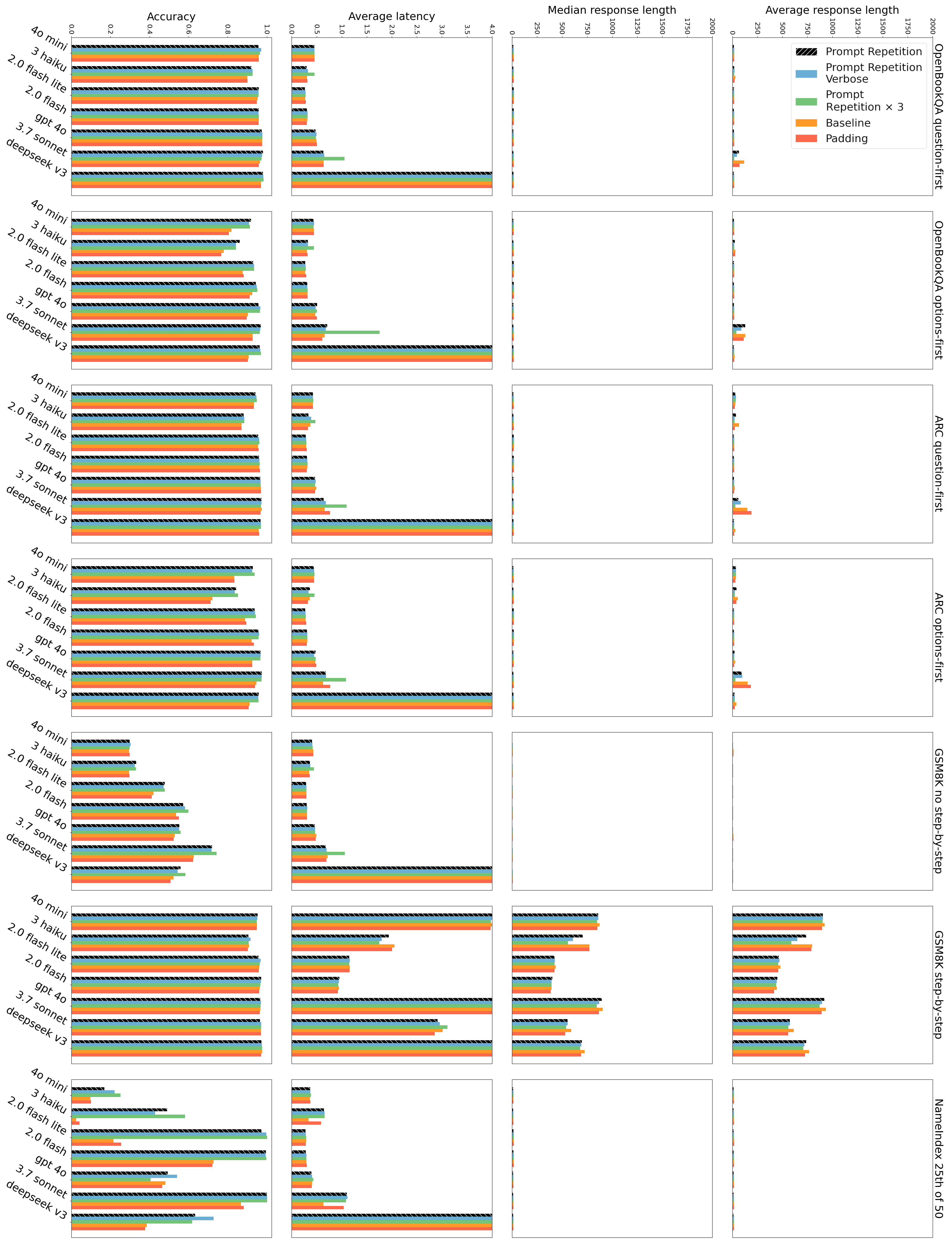
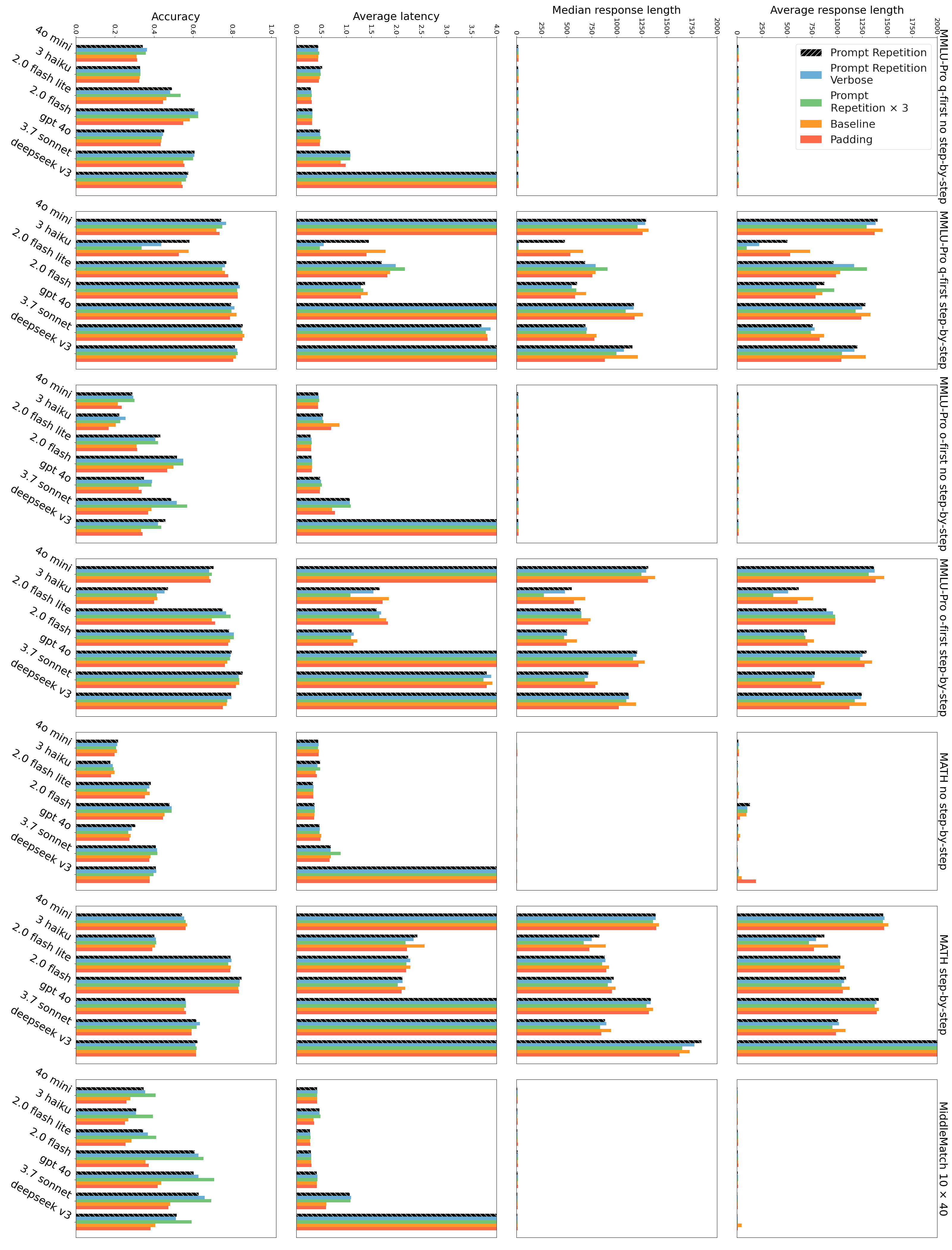
- Speed and answer length stayed about the same. In most cases, repeating the prompt did not make the model’s reply longer or slower. There were a few slowdowns for very long prompts on some models, because reading the longer input takes a bit more time.
- Repeating three times sometimes helped even more (especially on the list puzzles).
- Padding with dots (to make the input longer without repeating the content) did not help. So it’s the repetition of meaning, not just length, that matters.
Why this matters:
- It’s a simple, drop-in change. You don’t need to fine-tune models or change how answers are formatted.
- You get better accuracy with almost no downside when not using step-by-step reasoning.
Why does repeating help?
Because LLMs read from left to right, the position of information in your prompt matters. When you send “QUESTION + OPTIONS,” the model connects them easily. But if you send “OPTIONS + QUESTION,” it can’t “look ahead” to the question while reading the options.
Repeating the whole prompt fixes this: on the second copy, every part can “see” the first copy. It’s like rereading the problem—on the second read, the model can connect all the pieces no matter their order.
What’s the impact of this research?
- For everyday use: If you’re asking a model for a direct answer (no step-by-step), repeating your prompt is a quick way to get more accurate responses, especially for tricky multiple-choice formats and list-based tasks.
- For developers: This is an easy, low-cost improvement you can add to existing systems without changing outputs or making them longer. It tends to keep speed the same.
- For future work: The authors suggest exploring training with repeated prompts, repeating only parts of long prompts, using more than two repetitions when helpful, applying the idea to multi-turn chats or images, and analyzing how attention patterns change when you repeat.
In short, a simple “read it twice” trick helps many AI models answer better, especially when you want short, direct answers.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and concrete research directions that the paper leaves open.
- Mechanistic explanation: The claim that prompt repetition “enables each prompt token to attend to every other prompt token” under causal masking is not formally established. Provide a precise theoretical analysis (e.g., attention mask math for absolute/relative/rotary positional embeddings) and empirical attention-map studies showing which tokens attend to which repetition and why performance increases.
- Decoding settings ambiguity: The paper does not specify temperatures, top-p/top-k, or other decoding parameters. Quantify how repetition effects vary across deterministic vs. sampled decoding and under different parameter regimes.
- Multiple comparisons and statistical rigor: Using McNemar with p<0.1 across 70 tests without correction may inflate false positives. Report effect sizes, confidence intervals, and apply FDR/Bonferroni corrections; conduct power analyses.
- Replicability across time and versions: Evaluations rely on proprietary APIs (Feb–Mar 2025) without pinning model versions or releases. Establish a reproducible benchmark harness, versioned prompts, and seeds; replicate on open-source models (e.g., Llama, Mixtral) to assess generality.
- Cost and token economics: While output length and latency are unchanged, input tokens double (or triple). Quantify monetary cost, throughput impact, and provider rate-limit implications; compare cost-normalized accuracy (accuracy per input-token dollar).
- Context window constraints: Repetition consumes context budget and may be infeasible for long prompts. Systematically characterize failure regimes near window limits and propose truncation/partial-repetition strategies that retain gains.
- Prefill-stage compute and memory: The claim of “performance-neutral generation” overlooks increased prefill compute and KV-cache size. Measure GPU/TPU memory, throughput, and energy impact in local inference (not just cloud API latency).
- Safety and alignment impacts: Evaluate whether repetition affects refusal/guardrail behavior, jailbreak susceptibility, or amplification of harmful content; run red-teaming and safety benchmarks with/without repetition.
- Instruction-following and format fidelity: The paper asserts format interchangeability but does not quantify instruction adherence or response formatting error rates. Measure format compliance and constraint satisfaction across tasks.
- Negative cases and failure modes: Identify tasks where repetition harms performance (e.g., key-information extraction, structured JSON outputs, tool-use/function-calling). Provide a taxonomy of when repetition helps vs. hurts.
- Domain and task coverage: Benchmarks skew toward QA/math/list tasks. Test generative tasks (summarization, translation, code generation, long-form reasoning, RAG), and evaluate impact on coherence, factuality, and hallucination rates.
- Language and modality generalization: All tests appear in English; assess repetition in multilingual settings and in other modalities (images, audio), as suggested but not explored.
- Multi-turn and conversational contexts: Repetition’s effect in dialogues (history + system + user messages) is unknown. Evaluate multi-turn interactions, role conditioning (system vs. user), and cumulative repetition strategies.
- Interaction with structured inputs: Explore repetition with schemas (JSON/XML), programmatic prompts, and tool call specifications to ensure it doesn’t disrupt parsing or function invocation.
- Order effects disentanglement: Improvements in options-first may conflate repetition with reordering benefits. Compare repetition to learned or heuristic reordering strategies to isolate mechanisms.
- Position-embedding dependence: Test whether gains depend on RoPE/ALiBi vs. learned absolute position embeddings; run controlled experiments on models with different positional schemes.
- Variant efficacy boundaries: The paper shows gains for ×3 in custom tasks but does not explore saturation or diminishing returns beyond 3. Map the accuracy–cost frontier across 2–N repetitions and adaptive repetition policies.
- Partial repetition strategies: Systematically evaluate repeating subsets (e.g., only question, only constraints, only options) and content-aware repetition (repeat salient spans) vs. naive duplication.
- KV-cache optimization: The idea to keep only the second repetition in the KV-cache is proposed but not tested. Implement and benchmark cache-pruning strategies to confirm generation-stage neutrality.
- Attention pattern diagnostics: Beyond anecdotal motivation, provide quantitative analyses (e.g., layer-wise attention entropy, probe-based attribution, representational similarity) to understand how token representations change across repetitions.
- Robustness to noise and adversarial inputs: Test repetition under misspellings, distractors, and adversarial perturbations; assess whether repetition amplifies or mitigates sensitivity to spurious cues.
- Calibration and confidence: Measure changes in calibration (ECE/Brier scores) and self-consistency under repetition; does repetition increase overconfidence or improve confidence alignment?
- Data contamination and leakage risks: Repeated prompts may inadvertently surface memorized content differently. Evaluate repetition against contamination-aware test sets and memorization probes.
- Interaction with CoT and reasoning traces: Results are “neutral to slightly positive” under “think step by step” but limited. Test with diverse reasoning prompts (CoT, PoT, self-verification) and tool-augmented reasoning to quantify synergies or conflicts.
- RAG and retrieval pipelines: Analyze repetition in retrieval-augmented generation where long contexts are common; determine whether repetition interacts with retriever ranking and chunk salience.
- Provider-specific behavior: Anthropic models showed latency increases for long inputs; systematically characterize provider/model differences (architecture, batching, caching policies) that modulate repetition benefits.
- Generalization to non-proprietary settings: Validate on local inference stacks (vLLM, TGI, llama.cpp) to ensure the observed effects are not artifacts of provider infrastructure.
- Benchmark construction details: Custom tasks (NameIndex, MiddleMatch) strongly benefit from repetition but are synthetic. Release datasets, generators, and rationale; test on real-world list- and index-heavy tasks to avoid overfitting to contrived patterns.
- Ethical and UX considerations: Duplicating user content may be confusing in logs or UI. Study user experience, privacy implications (e.g., repeating sensitive text), and transparency requirements in deployed systems.
Practical Applications
Immediate Applications
Below are concrete, deployable uses that leverage prompt repetition (i.e., sending <QUERY><QUERY>) for non-reasoning LLM calls, along with sectors, likely tools/workflows, and key assumptions or dependencies.
Industry
- Production “repeat-2” prompt middleware to uplift accuracy without output-format changes
- Sectors: software/SaaS, enterprise IT, e-commerce, customer support, legal ops, finance ops
- Tools/workflows: SDK/plugin for LangChain, LlamaIndex, Semantic Kernel, or API gateways that auto-duplicate prompts for non-CoT calls (classification, extraction, short-form QA, policy/terms adherence checks); toggle via a feature flag
- Assumptions/dependencies: Works best when no chain-of-thought/reasoning is used; doubles input tokens (higher input-token cost and context usage) while keeping generation length and latency roughly unchanged; possible latency increase for very long prompts and specific providers (e.g., Claude variants as observed); must fit within model context limits; observe provider rate limits
- RAG answer selection and snippet re-ranking with repetition
- Sectors: enterprise search/knowledge management, customer support, legal and compliance search
- Tools/workflows: Apply repetition to final “answer selection” prompt or reranking prompts over retrieved passages; keep outputs schema-identical for downstream parsers
- Assumptions/dependencies: End-to-end latency dominated by retrieval/generation remains stable; context windows must handle doubled prompt; gains are task- and model-dependent—A/B test per deployment
- More robust function calling and tool routing
- Sectors: automation/platform engineering, agent frameworks, IT operations
- Tools/workflows: Repeat the tool schema + user request in tool-router prompts to reduce misroutes while keeping function-call JSON formats unchanged
- Assumptions/dependencies: Non-reasoning routing prompts; strict output formatting preserved; input-token cost increase; verify that duplicated specs don’t exceed tool description limits
- Content moderation, risk triage, and policy classification
- Sectors: trust & safety, ad tech, social media, marketplace ops
- Tools/workflows: Repeat user content + policy rubric for labelers (toxicity, hate speech, PII tags) to lift accuracy without adding latency to high-throughput pipelines
- Assumptions/dependencies: Legal/privacy review required because repeating inputs duplicates sensitive content in logs; consider redaction before repetition; cost and throughput budgets must tolerate higher input tokens
- Data labeling and analytics extraction at scale
- Sectors: marketing analytics, operations analytics, data platforms
- Tools/workflows: Apply repetition to entity/sentiment classification, span extraction, and schema mapping prompts in batch pipelines; integrate into label tools (e.g., Label Studio, Argilla) as a preprocessor
- Assumptions/dependencies: Budget for higher input-token costs; verify neutrality of output format; evaluate cost-per-correct improvements
- EdTech MCQ engines and grading/answer verification
- Sectors: education technology, testing platforms, LMS
- Tools/workflows: Repeat multiple-choice questions (especially options-first formats) to improve accuracy of automated grading and practice apps without changing expected “single-letter” outputs
- Assumptions/dependencies: Tasks should not require explicit step-by-step reasoning; ensure fairness and transparency in assessment contexts; monitor for context-window limits on long option lists
- On-device and low-latency user experiences
- Sectors: mobile keyboards, smart home, automotive, wearables
- Tools/workflows: Client-side prompt duplication for short, non-reasoning intents (classification, command understanding) to improve reliability without noticeable latency change
- Assumptions/dependencies: Memory and context-window constraints on-device; privacy policies if duplicating user inputs; evaluate power and throughput impacts despite unchanged generation time
- A/B testing and evaluation harnesses
- Sectors: MLOps, platform teams
- Tools/workflows: Add “repeat vs. baseline” as a default arm in offline/online evals; compute cost-per-correct; use McNemar or similar paired tests to gate rollout
- Assumptions/dependencies: Representative eval datasets; track model-specific effects (paper shows benefits across Gemini, GPT-4o, Claude, DeepSeek; neutral-to-slightly-positive with reasoning prompts)
Academia
- Stronger baselines for non-reasoning tasks in papers and benchmarks
- Sectors: NLP/ML research
- Tools/workflows: Include a “Prompt Repetition” baseline in multiple-choice QA, classification, and structured-output tasks; report accuracy/latency/response-length impacts
- Assumptions/dependencies: Reproducibility with provider APIs; document context length and pricing effects; disclose when reasoning or very long prompts reduce benefit
- Teaching and courseware for prompt engineering
- Sectors: higher education, professional training
- Tools/workflows: Add repetition as a low-complexity technique students can test on non-CoT tasks; compare with padding (control) to show causal effect
- Assumptions/dependencies: Lab environments with model API access; ensure tasks align with non-reasoning conditions
Policy
- Procurement and deployment checklists for cost-neutral accuracy improvements
- Sectors: public sector IT, regulated enterprises
- Tools/workflows: Mandate A/B tests that include prompt repetition for non-reasoning use-cases before adopting heavier reasoning modes; document cost-per-correct changes
- Assumptions/dependencies: Input-token pricing policies (costs likely rise even if latency doesn’t); domain-specific validation (health, finance, legal) required
- Risk and privacy assessment for duplicated inputs
- Sectors: compliance, data protection
- Tools/workflows: Update DPIAs and logging policies recognizing that inputs are duplicated; apply redaction/tokenization before duplication if needed
- Assumptions/dependencies: Regulatory alignment (GDPR/CCPA/sectoral rules); unchanged downstream output formats simplify audits
Daily Life
- Quick personal tip for factual or multiple-choice prompts
- Sectors: general users, students
- Tools/workflows: Paste your question twice for short, non-reasoning tasks (e.g., “Which option is correct?”) to improve reliability without asking for chain-of-thought
- Assumptions/dependencies: May increase input-token usage on paid plans; limited benefit for tasks requiring reasoning or long creative outputs
Long-Term Applications
These opportunities likely require further research, scaling, or engineering changes before broad deployment.
Industry
- Inference-engine support: KV-cache and prefill optimizations for repetition
- Sectors: model serving, cloud inference platforms
- Tools/workflows: Only keep the second copy in KV-cache; fuse identical spans in prefill; add a server-side repeat_prompt flag
- Assumptions/dependencies: Engine and scheduler changes (e.g., vLLM, TGI); rigorous correctness and throughput validation
- Dynamic repetition controllers and partial repetition
- Sectors: MLOps, agent frameworks
- Tools/workflows: Small policy model to choose when to repeat, how many times (×2 vs ×3), and which sections (instructions vs. options vs. context); integrate with prompt rewriters
- Assumptions/dependencies: Training data for policy; safeguards to prevent exceeding context limits; A/B validation per task and model
- Training-time adoption (fine-tuning/pretraining with repetition)
- Sectors: model vendors, foundation model teams
- Tools/workflows: Fine-tune with repeated prompts so models internalize the benefit; RL to reduce redundant verbatim repetition while preserving the accuracy lift
- Assumptions/dependencies: Compute budgets; measure generalization and safety; ensure benefits persist for non-reasoning tasks
- Prompt reordering assistants instead of full duplication
- Sectors: enterprise automation, developer tooling
- Tools/workflows: A small, fast model reorders prompt segments (e.g., question-first) or repeats only critical sections to minimize token overhead while neutralizing positional biases
- Assumptions/dependencies: Additional latency from the helper model; reliability of reordering must be high; domain-specific templates
- IDE and code-assistant integrations
- Sectors: software engineering
- Tools/workflows: Repeat or reorder code + instruction blocks for non-reasoning actions (classification of diffs, test identification, doc tagging) to improve adherence without changing output formats
- Assumptions/dependencies: Evaluate on code-specific tasks; watch context limits for large files
Academia
- Multi-turn and streaming strategies
- Sectors: conversational AI research
- Tools/workflows: Periodic repetition of recent turns or selective repetition of salient spans; evaluate trade-offs on latency, memory, and accuracy across tasks
- Assumptions/dependencies: Careful budget of input tokens; conversation-length growth; interaction with turn-taking policies
- Cross-modal evaluation (vision, audio) and architectures
- Sectors: multimodal AI
- Tools/workflows: Investigate whether repeating non-text modalities (e.g., duplicated image regions or repeated captions) or mixed text–vision repetition yields similar benefits
- Assumptions/dependencies: Yet unproven; requires dataset design and modality-specific serving changes
- Attention-pattern and representation analyses
- Sectors: interpretability
- Tools/workflows: Probe how repetition changes token attention and representations vs. padding; inform architectural tweaks that reduce order sensitivity without duplication
- Assumptions/dependencies: Access to model internals or high-fidelity probing tools
Policy
- Standards for compute-efficient prompting
- Sectors: standards bodies, public procurement
- Tools/workflows: Create guidance on when prompt repetition is preferable to chain-of-thought for cost, latency, and privacy; include measures like cost-per-correct and energy-per-correct
- Assumptions/dependencies: Independent audits across models and domains; careful accounting for increased input tokens vs. reduced retries/reasoning
- Privacy-by-design patterns for duplication
- Sectors: compliance engineering
- Tools/workflows: Redact-before-repeat templates; server-side repetition to avoid duplicating PII in client logs; policy hooks in SDKs
- Assumptions/dependencies: Provider support for server-side preprocessing; legal review
Daily Life
- “Smart repeat” defaults in consumer assistants
- Sectors: productivity apps, study tools
- Tools/workflows: Apps auto-detect non-reasoning short tasks and silently repeat the prompt (or key parts) to boost reliability while keeping responses concise
- Assumptions/dependencies: Careful detection to avoid unnecessary token costs; transparency controls for users
Notes on feasibility common to many applications:
- Benefits are strongest when reasoning is disabled; with chain-of-thought enabled, effects are neutral to slightly positive on average.
- Input-token usage approximately doubles; pricing and context windows must be considered even if output length and latency are largely unchanged (exceptions observed for very long prompts and some providers).
- Validate per model and task via A/B tests; improvements varied across benchmarks, with particularly strong gains on tasks sensitive to token order and list/indexing (analogous to the paper’s NameIndex and MiddleMatch).
Collections
Sign up for free to add this paper to one or more collections.