T5Gemma 2: Seeing, Reading, and Understanding Longer
Abstract: We introduce T5Gemma 2, the next generation of the T5Gemma family of lightweight open encoder-decoder models, featuring strong multilingual, multimodal and long-context capabilities. T5Gemma 2 follows the adaptation recipe (via UL2) in T5Gemma -- adapting a pretrained decoder-only model into an encoder-decoder model, and extends it from text-only regime to multimodal based on the Gemma 3 models. We further propose two methods to improve the efficiency: tied word embedding that shares all embeddings across encoder and decoder, and merged attention that unifies decoder self- and cross-attention into a single joint module. Experiments demonstrate the generality of the adaptation strategy over architectures and modalities as well as the unique strength of the encoder-decoder architecture on long context modeling. Similar to T5Gemma, T5Gemma 2 yields comparable or better pretraining performance and significantly improved post-training performance than its Gemma 3 counterpart. We release the pretrained models (270M-270M, 1B-1B and 4B-4B) to the community for future research.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces T5Gemma 2, a new family of AI models that can:
- read and write text in many languages,
- look at images and talk about them, and
- remember and use very long documents (like whole chapters or even short books).
It’s designed to be “lightweight” (not too big) but still powerful, and the authors are releasing several versions for the research community to use.
What were the main questions?
The researchers wanted to find out:
- Can we turn a “text-only” model into one that understands both text and images without starting from scratch?
- Can we make such a model handle much longer inputs (like tens of thousands of words)?
- Can we do all this efficiently—using fewer model parts—without losing much quality?
How did they build and train the model?
Think of the model as a two-part brain:
- The encoder is like the “reader”: it takes in the input (text and/or image features) and builds a rich understanding.
- The decoder is like the “writer”: it uses that understanding to produce helpful answers.
Here’s how they made it work:
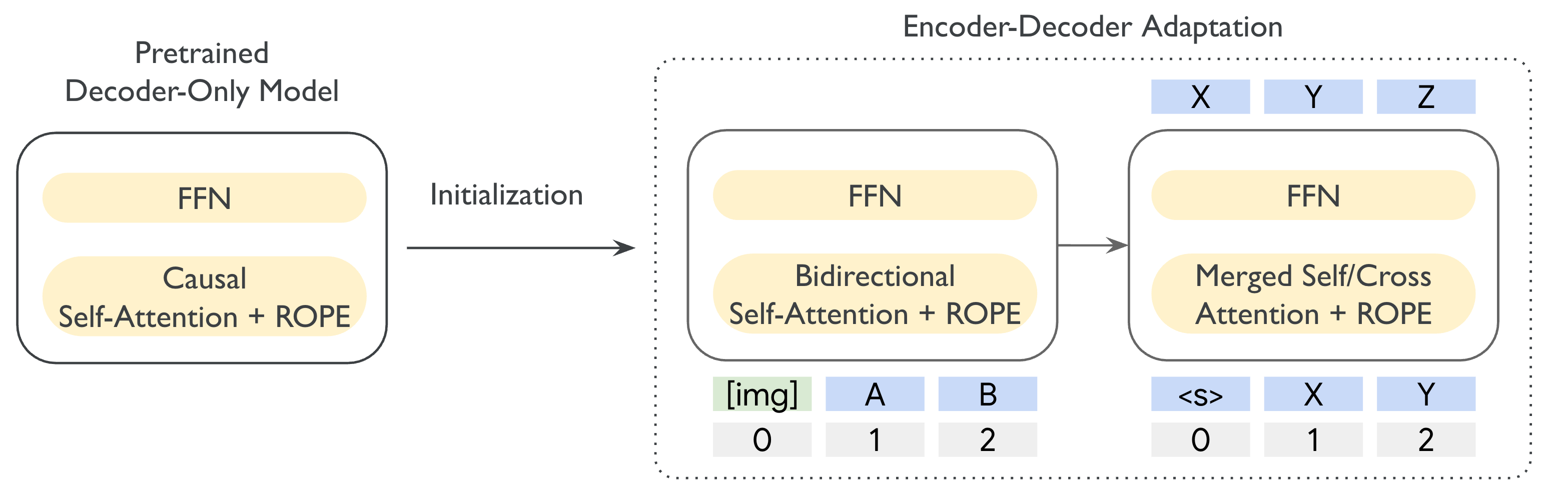
- Started from an existing “decoder-only” model (Gemma 3) and adapted it into an “encoder–decoder” model using a training setup called UL2.
- UL2 is like mixing different reading exercises: sometimes the model fills in missing parts, sometimes it continues text—so it learns to handle many types of tasks.
- Added vision by plugging in a frozen image encoder called SigLIP.
- Picture this like a camera that turns an image into 256 “tokens” (think: small pieces of meaning), which the encoder can understand just like words.
- Extended memory for long context.
- They used better “position markers” (RoPE) plus a trick called positional interpolation—like stretching a map carefully so distances still make sense—to let the model use very long inputs (up to about 128K tokens) even though it was trained on shorter ones (16K).
- Made the model more efficient with two ideas:
- Tied embeddings: The model typically keeps multiple copies of its “word dictionary” (embeddings) for different parts. They made the encoder and decoder share the same dictionary—like sharing one bookshelf instead of two—to cut down parameters without hurting quality.
- Merged attention: Normally, the decoder has two attention steps—one that looks at what it already wrote (self-attention) and one that looks at what the encoder read (cross-attention). They combined these into one step, like using one big inbox instead of two. This reduces size and speed costs with only a small quality drop.
Training details in everyday terms:
- They trained on about 2 trillion tokens (a huge amount of text and some images).
- Sequences during training were up to 16,000 tokens long.
- They tried different training recipes and found UL2 worked best for the smaller sizes.
- After pretraining, they did a small amount of instruction tuning (light post-training) to make the model better at following directions.
What did they find?
Here are the main results in simple terms:
- Strong at multiple skills:
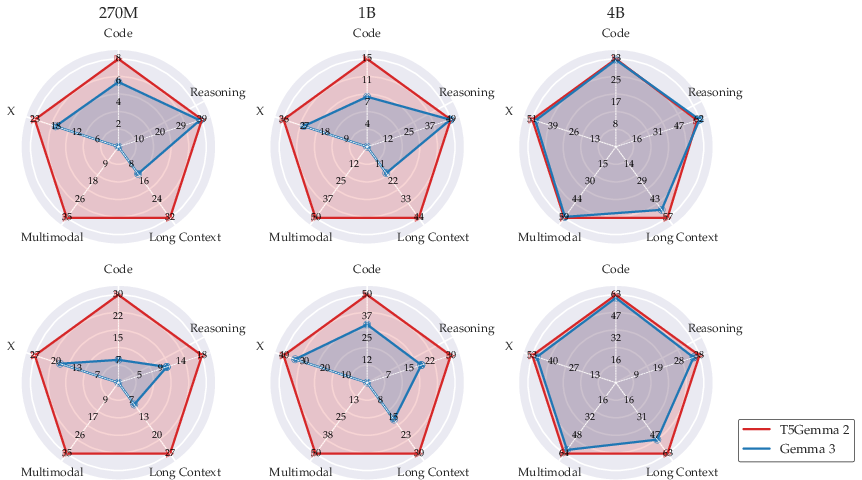
- T5Gemma 2 performs as well as or better than the original Gemma 3 across many areas: reasoning, coding, multilingual tasks, vision+language tasks, and long-context tasks.
- Long documents: impressive performance up to 128K tokens
- Even though training used sequences up to 16K tokens, T5Gemma 2 handled much longer inputs during testing and did especially well compared to similar-sized models. This shows a special advantage of the encoder–decoder setup for long context.
- Images + text, even when starting from text-only
- Smaller versions (270M-270M and 1B-1B) started from text-only bases but still learned to handle images well after adaptation. That means you don’t need to start from scratch to add vision skills.
- Efficiency wins with little quality loss
- Tied embeddings cut about 10% of parameters with almost no quality change.
- Merged attention cut about 6.5% of parameters with a very small performance drop—an acceptable tradeoff for faster, smaller models.
- Training recipe matters
- UL2 beat a simpler “just continue the text” recipe (PrefixLM+KD) for the smaller models.
- Adding distillation (learning from a stronger teacher’s predictions) didn’t always help enough to justify the extra complexity, so they preferred plain UL2 for this work.
- Post-training boosts
- Even with only light instruction tuning (no heavy reinforcement learning), T5Gemma 2 generally outperformed its counterpart (Gemma 3) on many benchmarks. The authors believe stronger post-training would improve it even more.
Why does this matter?
- Practical models that do more
- T5Gemma 2 can read long documents, look at images, and work in multiple languages—all in a compact, efficient design. That makes it useful for studying big reports, understanding charts, reading documents in different languages, and answering questions about images.
- Better value for compute
- The efficiency tweaks mean smaller models can still perform strongly, which is great for researchers, students, and companies that don’t have massive computing power.
- Open and adaptable
- The authors released multiple sizes (270M-270M, 1B-1B, 4B-4B). This helps the community build on their work, test ideas, and create improved systems—like better search engines, educational tools, or assistive technologies.
- A step forward for encoder–decoder models
- The results suggest encoder–decoder models have special strengths for long input and multimodal tasks. This could shape how future AI systems are designed, especially for tasks that require understanding lots of context or combining text with images.
In short
T5Gemma 2 shows that you can take a good text-only model, adapt it into a “reader–writer” (encoder–decoder) that understands images and very long texts, and make it more efficient—all while keeping or improving quality. It’s a practical, open resource that can help push forward research and real-world applications.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
Architecture and ablations
- Lack of causal evidence that encoder–decoder architecture (vs. decoder-only) is the main driver of long-context gains: need controlled experiments with identical tokenizer, RoPE setup, data, and compute across architectures to isolate the architectural effect.
- Insufficient analysis of merged attention: no study of failure modes, stability, gradient dynamics, or how attention mass is allocated between encoder and decoder tokens; ablate gating/bias terms, separate normalization, and learned mixing coefficients for encoder vs. decoder keys/values.
- Cross-attention sparsification remains underexplored: the “global-layers-only” variant underperforms, but alternatives (e.g., learned layer schedules, chunked or compressed cross-attention, routing to a subset of encoder tokens, kNN/pruning) are not evaluated.
- No investigation of encoder-output compression for long contexts (e.g., pooling, low-rank, token merging) to reduce decoder’s cross-attention cost without losing accuracy.
- Tied embeddings effects are not characterized: impact on rare tokens, multilingual scripts, code tokens, and downstream finetuning stability is unknown; evaluate tied vs. untied embeddings across languages and domains.
Training objective, data, and scaling
- Objective design remains underexplored beyond UL2: study hybrid objectives that mix UL2 with prefix/causal LM, retrieval-aware masking, or multimodal denoising; quantify trade-offs across capabilities.
- Effect of knowledge distillation is ambiguous: results suggest size- and teacher-dependent outcomes, but no systematic analysis of teacher quality, temperature, or distillation schedules; provide a controlled KD study across sizes and tasks.
- Data mixture composition is not disclosed in detail (text/code/math/vision proportions, language distribution, image–text pairing quality), impeding reproducibility and targeted improvements (e.g., for OCR-heavy or low-resource languages).
- Benchmark contamination and data leakage checks are not reported; conduct and publish contamination audits for all evaluated datasets.
- No scaling law analysis for encoder–decoder with UL2 and merged attention; report loss vs. compute and data for multiple scales to guide future training budgets.
Multimodal (vision–language) modeling
- Frozen SigLIP encoder choice is not compared to partially/fully finetuned variants; evaluate trade-offs in accuracy vs. compute for OCR, charts/diagrams, and document QA.
- Fixed 256 visual tokens may bottleneck high-resolution or dense-text images; ablate variable token budgets, resolution, patching, and adaptive token selection.
- Missing evaluation on multi-image, region grounding, and referring expression tasks; assess whether the encoder-only ingestion of image tokens limits stepwise visual reasoning during decoding.
- Absent analysis of error types on DocVQA/AI2D/ChartQA and failure cases where visual text recognition or layout understanding breaks; provide qualitative diagnostics and targeted finetuning recipes.
- No exploration of additional modalities (audio, video) or temporal reasoning; clarify whether the adaptation recipe generalizes beyond static images.
Long-context generalization
- Extrapolation beyond 128K is untested; evaluate at 256K–1M with robust tasks and analyze degradation curves vs. context length, including retrieval sensitivity and position bias.
- Positional interpolation design is under-specified (exact method, hyperparameters); compare alternatives (e.g., NTK/RoPE scaling variants, learned positions, ALiBi) within the same architecture.
- Missing evaluations on practical long-context tasks (e.g., long-document QA, legal/biomedical summarization, multi-file code understanding) beyond synthetic suites; measure real-world utility.
- No comparison to memory/compression approaches (e.g., selective retrieval, token merging, memory layers, recurrent/state-space modules); test whether encoder–decoder gains persist when memory mechanisms are added.
Efficiency, latency, and system concerns
- No reported decode-time latency, tokens/sec, or memory footprint (including KV cache) for merged attention vs. standard cross-attention across encoder/decoder lengths; provide wall-clock profiling on standard hardware.
- KV cache design with merged attention is unspecified (e.g., caching encoder K/V, amortization across tokens, cache growth with long contexts); clarify implementation and quantify savings.
- Autoregressive throughput under interleaved local/global layers is not profiled; report inference-time scaling with context length and number of global layers.
- Train-time compute (FLOPs), hardware setup, and energy/carbon footprint are not disclosed; report to enable fair efficiency comparisons.
Post-training and alignment
- Post-training is intentionally lightweight and excludes RL; open question: how much additional gain is achievable with comprehensive supervised signals, preference optimization, and RL? Provide controlled post-training scaling curves.
- Teacher model(s) and data for distillation during post-training are not specified; disclose to support reproducibility and to assess teacher–student mismatch effects.
- Safety, bias, toxicity, and hallucination evaluations are absent; conduct multilingual and multimodal safety audits, including robustness to adversarial/prompts and harmful visual content.
Evaluation design and reporting
- Metric definitions for multimodal tasks (e.g., COCO captioning metric choice) and noted “approximate” results hinder comparability; standardize metrics and release exact evaluation scripts/configs.
- Decoding settings (temperature, top-p, CoT prompting) are not consistently documented across benchmarks; publish per-benchmark decoding configs to avoid confounds.
- Limited baselines: comparisons to strong open encoder–decoder (e.g., mT5, BART-families) and modern decoder-only long-context/multimodal LLMs are incomplete; broaden baselines under matched training compute.
- Causal attribution claims (e.g., “unique adaptability” of encoder–decoder) lack ablations separating architecture from initialization (decoder-only checkpoint), objective (UL2), and data; run from-scratch encoder–decoder vs. adapted variants with matched budgets.
Reproducibility and release
- Missing critical training details (optimizer type and hyperparameters, exact LR values per size, weight decay, warmup units, gradient clipping specifics per module, tokenizer and vocabulary) reduce reproducibility; release full configs.
- Only pretrained checkpoints are released; absence of post-trained checkpoints limits verification of downstream claims; consider releasing lightweight post-trained variants and scripts.
- Data access and licensing for the ~2T-token corpus are not clarified; provide dataset manifests, filtering criteria, and licensing status to support ethical reuse.
Broader applicability and future directions
- Generality of the adaptation recipe across model families (non-Gemma decoder-only checkpoints), tokenizers (byte-level vs. subword), and languages (script diversity, low-resource) remains untested; perform cross-family and low-resource studies.
- Integration with retrieval-augmented generation (RAG) is not evaluated; test whether encoder–decoder strengths translate to RAG pipelines (document encoding, passage selection, fusion-in-decoder).
- Robustness and calibration under distribution shift (noisy OCR, domain-specific images, low-light photos, multilingual documents) are not measured; add stress tests and calibration metrics (ECE/Brier).
Practical Applications
Immediate Applications
The following applications can be deployed with today’s T5Gemma 2 checkpoints (270M-270M, 1B-1B, 4B-4B), given standard fine-tuning/alignment and productionization. Each item notes sectors, potential products/workflows, and key assumptions/dependencies.
- Multimodal document copilot for long reports, forms, and charts
- Sectors: finance, legal, insurance, consulting, government
- What: Q&A, summarization, compliance clause extraction across 100+ page PDFs with embedded figures/charts; answer questions over scanned documents (DocVQA, ChartQA), presentations, and images bundled with text
- Product/workflow: Email/CRM add-ins, contract review assistants, board pack analysers, analyst workbench
- Assumptions/dependencies: High-quality PDF parsing; OCR fallback for small/blurred text (SigLIP is frozen and not an OCR engine); domain-tuned prompts/finetuning; licensing and data-governance controls; GPU/CPU capacity for 16K–128K contexts
- Long-context enterprise knowledge assistant
- Sectors: software, IT, manufacturing, enterprise ops
- What: Ingest and reason over design docs, ADRs, wikis, tickets, runbooks up to 128K tokens; produce cross-document briefings and risk registers
- Product/workflow: Confluence/Notion/SharePoint copilots; incident postmortem generator; change-impact analyzers
- Assumptions/dependencies: Reliable chunking/indexing when context >128K; organizational access controls; retrieval safety; light finetuning for ontology/terminology
- Multilingual helpdesk summarization and triage
- Sectors: customer support, e-commerce, telecom
- What: Summarize and translate tickets/emails across languages; route to teams; produce response drafts
- Product/workflow: Helpdesk plugins; auto-summarization pipelines; multilingual FAQ bots
- Assumptions/dependencies: Style/alignment tuning; guardrails for PII; evaluation on in-domain language pairs
- Slide-and-meeting companion
- Sectors: enterprise productivity
- What: Combine long meeting transcripts with slide images to generate minutes, action items, and timeline summaries
- Product/workflow: Meeting assistant integrated with conferencing and file storage; slide-aware note-taker
- Assumptions/dependencies: Accurate ASR; slide image quality; prompt templates for action-item extraction
- Multimodal data extraction for receipts, invoices, and IDs
- Sectors: fintech, expense management, KYC, logistics
- What: Pull key fields (amount, vendor, date) from photos/scans; handle varied layouts
- Product/workflow: Expense apps, AP automation, onboarding portals
- Assumptions/dependencies: Fine-tuning for target document types; OCR hybridization for small text; bias/safety checks for ID documents
- Research and literature triage with figure-aware reading
- Sectors: academia, biopharma R&D, market research
- What: Summarize long papers, link text with figures/tables, produce related-work maps with citations
- Product/workflow: Scholar copilot; systematic review assistant; grant-proposal briefings
- Assumptions/dependencies: Reliable PDF-to-structure tools; citation verification; hallucination mitigation
- Code-aware documentation and snippet reasoning
- Sectors: software engineering
- What: Answer questions about code-adjacent docs (design docs, READMEs, changelogs); propose diffs for doc updates; explain scripts/pipelines
- Product/workflow: IDE doc assistant; repo governance bot for docs
- Assumptions/dependencies: Modest code generation ability out-of-the-box; better with domain finetuning and constrained decoding; repository-level RAG
- Compliance and policy scanning at scale
- Sectors: regulated industries (finance, healthcare, energy), government
- What: Map controls to regulations, surface gaps, track policy changes across large corpora
- Product/workflow: GRC copilots; regulatory-change monitoring; control evidence extractors
- Assumptions/dependencies: Domain adaptation and calibrated uncertainty; human-in-the-loop review; auditable outputs
- Multilingual knowledge base chat
- Sectors: education, public sector, NGOs
- What: Cross-lingual Q&A over long guidelines, manuals, and curricula; diagram/infographic understanding for accessibility
- Product/workflow: LMS assistant; public information portals; humanitarian ops copilots
- Assumptions/dependencies: Coverage for target languages; cultural/term disambiguation; accessibility considerations
- Retrieval and search upgrades using T5Gemma 2-based embeddings
- Sectors: search, enterprise data platforms, e-discovery
- What: Use T5Gemma 2 as a foundation to train high-quality text (and potentially multimodal) embeddings for retrieval/ranking
- Product/workflow: Vector search, RAG pipelines, similarity deduplication
- Assumptions/dependencies: Availability of EmbeddingGemma or in-house contrastive finetuning; vector DB infra; evaluation on domain corpora
- Efficient encoder-decoder adoption in model engineering
- Sectors: ML infrastructure, model tooling
- What: Apply tied embeddings and merged attention to reduce parameters and memory while keeping quality near baseline
- Product/workflow: Custom seq2seq stacks with lower memory footprint; cheaper training/fine-tuning runs
- Assumptions/dependencies: Compatibility with existing training code; regression tests on target tasks; careful masking with merged attention
- Privacy-preserving on-prem deployments
- Sectors: healthcare, finance, defense, legal
- What: Run 270M–1B class models (plus frozen SigLIP) on secured infra with quantization; process sensitive long-context data locally
- Product/workflow: Containerized inference with policy/PII filters; offline batch summarization
- Assumptions/dependencies: Hardware capacity; quantization-aware calibration; security reviews and logging
Long-Term Applications
These opportunities are enabled by the paper’s methods (UL2 adaptation from decoder-only to encoder-decoder, multimodality via frozen SigLIP, long-context generalization via positional interpolation) but need further research, scaling, or domain alignment.
- RAG-less long-context systems for multi-document reasoning
- Sectors: enterprise search, legal tech, finance, scientific discovery
- What: Replace or minimize retrieval pipelines by ingesting large corpora directly into 128K–1M-token contexts; persistent workspace memory
- Dependencies: Robust quality beyond 128K; efficient inference/caching; stronger truthfulness/citation grounding
- End-to-end legal/financial analysis with verifiable citations
- Sectors: legal, finance, compliance
- What: Drafts with clause-level traceability, risk tagging, and chart-based evidence linking
- Dependencies: Advanced alignment to reduce hallucinations; structured output schemas; audit trails and certification
- Full codebase refactoring and architecture reasoning
- Sectors: software engineering
- What: Understand monorepos with code+docs+designs; propose multi-file refactors and migration plans
- Dependencies: Larger context or hierarchical memory; tool-use/orchestration; robust static-analysis integration
- Clinical multimodal assistants combining notes, scans, and images
- Sectors: healthcare
- What: Joint reasoning over EHR text, radiology reports, dermatology images, and forms
- Dependencies: Medical-grade VLM training (SigLIP is general-purpose and frozen); regulatory approvals; rigorous safety/validation; strong de-identification
- Visual tool-use planners for robotics and automation
- Sectors: robotics, manufacturing, warehousing
- What: Use images and long instructions to plan procedures, verify steps with visual inputs, and generate operator guidance
- Dependencies: Real-time constraints; embodied control interfaces; safety certification; closed-loop perception-action training
- Executive analytics for earnings and macro reports
- Sectors: finance, consulting
- What: Synthesize 10-Ks/earnings calls with charts/tables and produce scenario analyses and forecast narratives
- Dependencies: Factuality guarantees; market-risk guardrails; domain-specific finetuning and evaluation
- Multilingual government-scale translation and summarization with intake of long dossiers
- Sectors: public sector, international organizations
- What: Cross-lingual briefings with embedded figures and maps; policy option evaluation
- Dependencies: Human-in-the-loop workflows; bias/harms mitigation; coverage for low-resource languages
- On-device multimodal assistants
- Sectors: consumer devices, automotive, AR
- What: Local assistants that interpret photos/handouts and long notes; privacy-first household/vehicle copilots
- Dependencies: Aggressive compression/distillation; hardware acceleration; low-latency memory paging
- General adaptation recipe adoption: convert proprietary decoder-only LLMs into efficient encoder-decoder multimodal models
- Sectors: foundation model providers, enterprise AI labs
- What: Apply UL2 adaptation + merged attention + tied embeddings to repurpose existing decoder-only checkpoints into long-context, V+L seq2seq models
- Dependencies: Licensing rights for base models; compute budget; careful initialization and masking; validation across modalities
- Knowledge-grounded STEM tutoring with diagram understanding and step-checked reasoning
- Sectors: education, EdTech
- What: Tutor that reads textbooks/diagrams, scaffolds solutions, and verifies steps over long lesson contexts
- Dependencies: Stronger reasoning alignment (RLHF/RLAIF); pedagogical safety; content-moderation and grading integrations
Cross-cutting assumptions and dependencies
- Alignment and safety: The paper’s post-training is “lightweight”; many high-stakes applications require stronger alignment (e.g., RLHF/RLAIF), bias evaluation, and red-teaming.
- Licensing and IP: Confirm license terms for T5Gemma 2 checkpoints and the frozen SigLIP vision encoder in your target deployment scenario.
- Context scaling: Models were trained with up to 16K tokens and generalize to 128K via positional interpolation; quality beyond trained lengths can degrade and should be validated task-by-task.
- Vision limits: The vision encoder is frozen; for small-text OCR or domain-specific imaging (medical, industrial), add OCR pipelines or domain finetuning where permitted.
- Compute and latency: Long-context + multimodal inference is compute-intensive; plan for quantization, caching, and throughput engineering.
- Data governance: Handling PII, financial, or health data requires secure deployment, logging, and compliance controls.
Glossary
- Ablation: An experiment that removes or modifies components to assess their impact on performance. "We present the detailed results and also provide ablations justifying our architectural designs."
- Autoregressive inference bottleneck: The latency constraint arising from generating tokens sequentially during inference. "However, this adds non-ignorable computational cost particularly considering the autoregressive inference bottleneck and its global-attention structure."
- Checkpoint averaging: Combining multiple saved model checkpoints by averaging their weights to improve robustness. "The final pretraining checkpoint is created by averaging over the last 5 checkpoints (saved with an interval of 10K steps)"
- Cosine decay: A learning rate schedule that decreases the rate following a cosine curve. "Learning rate follows cosine decay with a warmup step of 100."
- Cross-attention: An attention mechanism where decoder queries attend to encoder outputs to condition generation on inputs. "In the encoder-decoder architecture, cross-attention is often represented as a separated sub-layer in the decoder block, inserted in between the self-attention and feed-forward sub-layers."
- Cross-entropy loss: A standard loss function for classification and language modeling measuring divergence between predicted and true distributions. "All models are trained with a batch size of 4.2M tokens, and with the standard cross-entropy loss."
- Decoder-only model: A Transformer that generates outputs autoregressively without an explicit encoder component. "adapting a pretrained decoder-only model into an encoder-decoder model"
- Encoder-decoder architecture: A sequence-to-sequence Transformer with an encoder processing inputs and a decoder generating outputs. "In recent years, the encoder-decoder architecture has regained increasing interests in LLMs for its competitive scaling properties and flexible architectures"
- Frozen (parameters): Model components kept fixed (not updated) during training. "The 400M SigLIP encoder is adopted as the vision encoder, which transforms an image to 256 embedding tokens and is frozen during the training."
- Global gradient clipping: Limiting the norm of the aggregated gradients to stabilize training. "we apply global gradient clipping at 1.0"
- Grouped-query attention (GQA): An attention variant that shares key/value projections across groups of query heads for efficiency. "grouped-query attention~\citep{ainslie2023gqa} with QK-norm~\citep{dehghani2023scaling}"
- Head dimension: The size of the per-head subspace in multi-head attention. "where / represents the encoder/decoder input length and / is model/head dimension."
- Instruction tuning: Fine-tuning a model on instruction–response data to improve following user prompts. "We also perform slight instruction tuning to showcase the strengths of encoder-decoder LLMs on downstream finetuning."
- Interleaved local and global attention: Alternating layers that restrict attention to nearby tokens (local) and layers that allow full context (global). "interleaved local and global attention layers with a ratio of 5:1."
- Knowledge distillation (KD): Training a model to match a stronger teacher’s outputs (logits) to transfer knowledge. "we only apply distillation learning"
- Long-context modeling: Techniques enabling models to process and reason over very long input sequences. "To improve long-context modeling, we set the RoPE base frequency to 10k and 1M for local and global attention layers, respectively"
- Masking (attention): A visibility matrix controlling which tokens can attend to which others during attention. "The masking handles the visibility to tokens from both encoder and decoder."
- Merged attention: A unified attention module that jointly performs self- and cross-attention with shared parameters. "we merge these two types of attentions into a single module with shared attention parameters."
- Multilingual: Supporting multiple languages within a single model. "strong multilingual, multimodal and long-context capabilities."
- Multimodal: Handling multiple data types (e.g., text and images) within a single model. "strong multilingual, multimodal and long-context capabilities."
- Positional interpolation: Extending a model’s positional encoding to longer lengths by interpolating existing positions. "we adopt the positional interpolation methods"
- Prefix language modeling (PrefixLM): An objective where the model conditions on a prefix of the sequence and predicts the remaining tokens. "we only use prefix language modeling: all input tokens until the end of the final image are used as prefix, and the remaining text tokens are used as targets."
- QK-norm: Normalization applied to query/key vectors in attention to improve stability and scaling. "with QK-norm~\citep{dehghani2023scaling}"
- Reinforcement learning (RL) finetuning: Post-training using RL-based objectives (e.g., human feedback) to align model behavior. "Different from Gemma 3 post-training which includes distillation from stronger teacher and RL finetuning"
- RMSNorm: A normalization technique using root-mean-square statistics instead of mean/variance. "pre- and post-norm with RMSNorm~\citep{zhang2019root}"
- RoPE (Rotary Position Embedding): A positional encoding that rotates query/key vectors to encode relative positions. "RoPE for positional encoding~\citep{su2024roformer}"
- RoPE base frequency: A hyperparameter controlling the frequency scaling of rotary positional embeddings. "we set the RoPE base frequency to 10k and 1M for local and global attention layers, respectively"
- Self-attention: An attention mechanism where tokens attend to other tokens within the same sequence. "inserted in between the self-attention and feed-forward sub-layers."
- SigLIP: A vision encoder trained with a sigmoid-based image–text loss used to produce image embeddings. "Image is preprocessed by SigLIP into 256 embedding tokens"
- Softmax embedding: The output embedding matrix tied to the softmax layer for token prediction. "decoder output/softmax embedding"
- Teacher logits: Output probabilities from a teacher model used as supervision in distillation. "we use teacher logits for real target tokens and one-hot logits for special masking tokens."
- Tied embeddings: Sharing the same embedding parameters across multiple roles/components (e.g., encoder/decoder/input/output) to save parameters. "we instead tie all word embeddings (encoder input embedding, decoder input embedding and decoder output/softmax embedding)"
- Vision encoder: A module that converts images into embedding tokens consumable by the LLM. "The 400M SigLIP encoder is adopted as the vision encoder"
- Vision-language: Models that jointly process vision and language inputs/outputs. "the new collection of vision-language encoder-decoder foundation model."
- Warmup (learning rate): Gradually increasing the learning rate at the start of training to stabilize optimization. "Learning rate follows cosine decay with a warmup step of 100."
- Weight decay: L2-style regularization applied during optimization to prevent overfitting. "and weight decay."
Collections
Sign up for free to add this paper to one or more collections.