TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones
Abstract: In recent years, multimodal LLMs (MLLMs) such as GPT-4V have demonstrated remarkable advancements, excelling in a variety of vision-language tasks. Despite their prowess, the closed-source nature and computational demands of such models limit their accessibility and applicability. This study introduces TinyGPT-V, a novel open-source MLLM, designed for efficient training and inference across various vision-language tasks, including image captioning (IC) and visual question answering (VQA). Leveraging a compact yet powerful architecture, TinyGPT-V integrates the Phi-2 LLM with pre-trained vision encoders, utilizing a unique mapping module for visual and linguistic information fusion. With a training regimen optimized for small backbones and employing a diverse dataset amalgam, TinyGPT-V requires significantly lower computational resources 24GB for training and as little as 8GB for inference without compromising on performance. Our experiments demonstrate that TinyGPT-V, with its LLM 2.8 billion parameters, achieves comparable results in VQA and image inference tasks to its larger counterparts while being uniquely suited for deployment on resource-constrained devices through innovative quantization techniques. This work not only paves the way for more accessible and efficient MLLMs but also underscores the potential of smaller, optimized models in bridging the gap between high performance and computational efficiency in real-world applications. Additionally, this paper introduces a new approach to multimodal LLMs using smaller backbones. Our code and training weights are available in the supplementary material.
- Flamingo: a visual language model for few-shot learning. Advances in Neural Information Processing Systems, 35:23716–23736, 2022.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Instruction mining: When data mining meets large language model finetuning, 2023.
- Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts, 2021.
- Visualgpt: Data-efficient adaptation of pretrained language models for image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18030–18040, 2022.
- Minigpt-v2: large language model as a unified interface for vision-language multi-task learning. arXiv preprint arXiv:2310.09478, 2023.
- Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023), 2023.
- Instructblip: Towards general-purpose vision-language models with instruction tuning, 2023.
- Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- An image is worth 16x16 words: Transformers for image recognition at scale, 2021.
- Eva: Exploring the limits of masked visual representation learning at scale, 2022.
- Accurate, large minibatch sgd: Training imagenet in 1 hour, 2018.
- Vizwiz grand challenge: Answering visual questions from blind people. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3608–3617, 2018.
- Bag of tricks for image classification with convolutional neural networks, 2018.
- Query-key normalization for transformers, 2020.
- Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
- Lora: Low-rank adaptation of large language models, 2021.
- Gqa: A new dataset for real-world visual reasoning and compositional question answering. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6700–6709, 2019.
- Phi-2: The surprising power of small language models. https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/, 2023.
- Referitgame: Referring to objects in photographs of natural scenes. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 787–798, 2014.
- The hateful memes challenge: Detecting hate speech in multimodal memes. Advances in neural information processing systems, 33:2611–2624, 2020.
- The hateful memes challenge: Detecting hate speech in multimodal memes, 2021.
- Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models, 2023.
- Textbooks are all you need ii: phi-1.5 technical report, 2023.
- Microsoft coco: Common objects in context, 2015.
- Improved baselines with visual instruction tuning, 2023.
- Visual instruction tuning, 2023.
- Visual instruction tuning. arXiv preprint arXiv:2304.08485, 2023.
- Iconqa: A new benchmark for abstract diagram understanding and visual language reasoning. arXiv preprint arXiv:2110.13214, 2021.
- Iconqa: A new benchmark for abstract diagram understanding and visual language reasoning, 2022.
- Generation and comprehension of unambiguous object descriptions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 11–20, 2016.
- OpenAI. Introducing chatgpt. https://openai.com/blog/chatgpt, 2022.
- Im2text: Describing images using 1 million captioned photographs. In J. Shawe-Taylor, R. Zemel, P. Bartlett, F. Pereira, and K.Q. Weinberger, editors, Advances in Neural Information Processing Systems, volume 24. Curran Associates, Inc., 2011.
- Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- Learning transferable visual models from natural language supervision, 2021.
- Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- Laion-400m: Open dataset of clip-filtered 400 million image-text pairs, 2021.
- A-okvqa: A benchmark for visual question answering using world knowledge. In European Conference on Computer Vision, pages 146–162. Springer, 2022.
- Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Iryna Gurevych and Yusuke Miyao, editors, Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2556–2565, Melbourne, Australia, July 2018. Association for Computational Linguistics.
- Stanford alpaca: An instruction-following llama model, 2023.
- Llama 2: Open foundation and fine-tuned chat models, 2023.
- Multimodal few-shot learning with frozen language models. Advances in Neural Information Processing Systems, 34:200–212, 2021.
- Instructiongpt-4: A 200-instruction paradigm for fine-tuning minigpt-4, 2023.
- Bloom: A 176b-parameter open-access multilingual language model. arXiv preprint arXiv:2211.05100, 2022.
- The dawn of lmms: Preliminary explorations with gpt-4v(ision), 2023.
- Modeling context in referring expressions. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14, pages 69–85. Springer, 2016.
- Artgpt-4: Towards artistic-understanding large vision-language models with enhanced adapter, 2023.
- Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022.
- Judging llm-as-a-judge with mt-bench and chatbot arena, 2023.
- Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592, 2023.
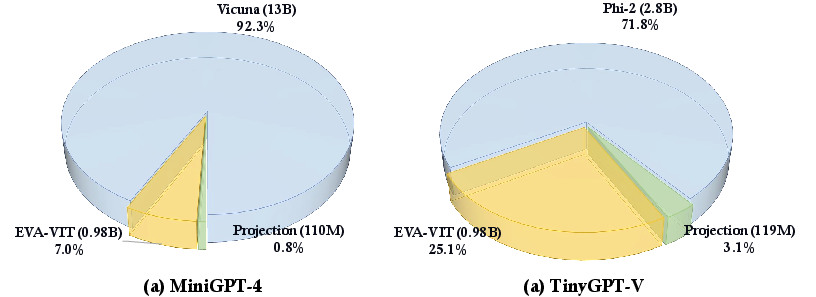
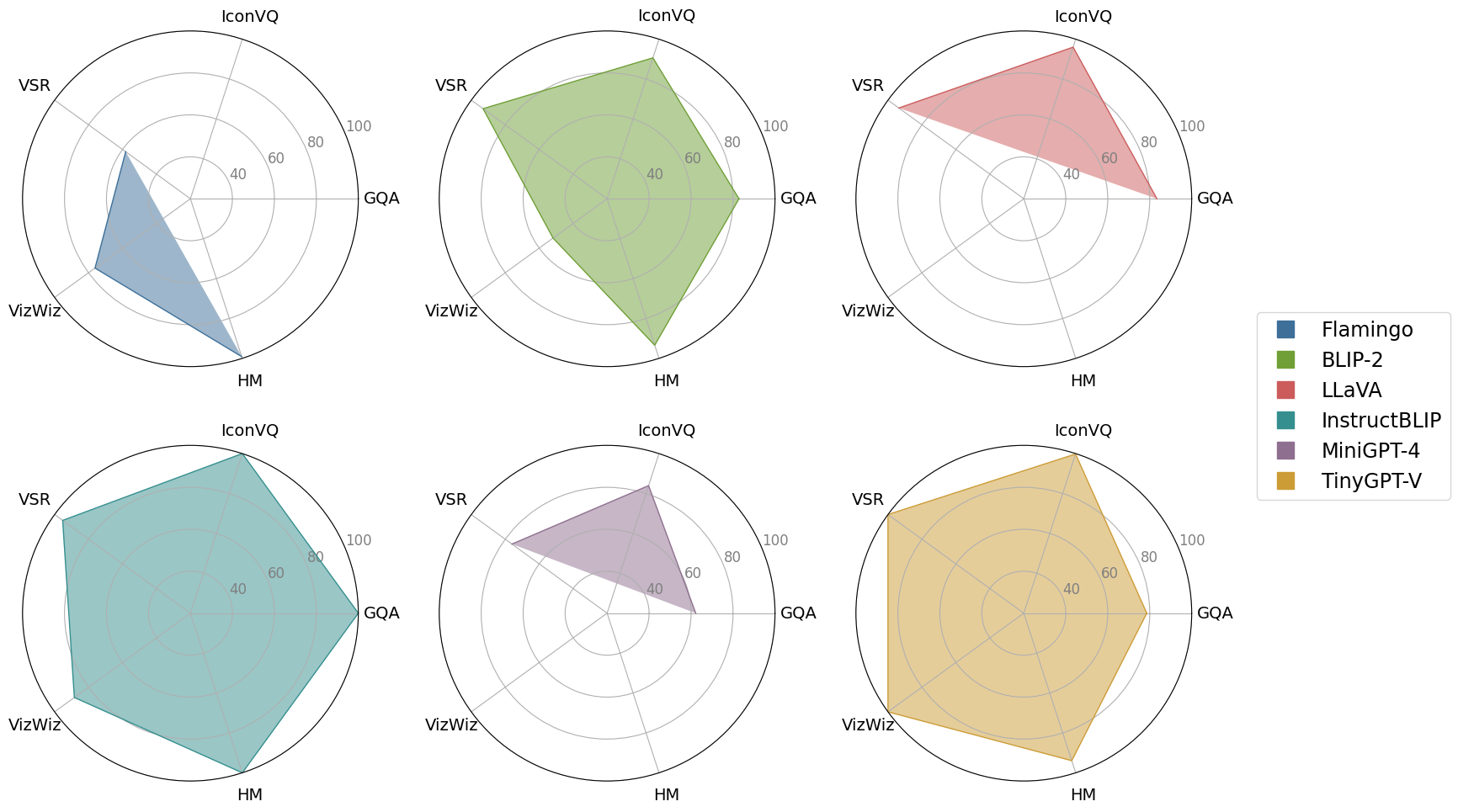
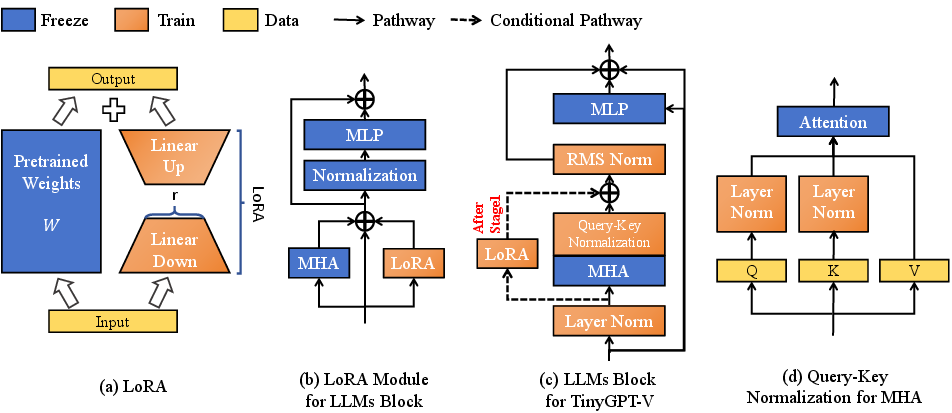
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.