- The paper demonstrates that strategic representation engineering can curtail redundant self-reflection in LLMs, reducing reasoning tokens by up to 33.6%.
- It employs a stepwise steering method that segments reasoning into discrete units and identifies reflection steps using linguistic cues.
- The approach leverages model uncertainty and a logistic regression classifier to predict answer correctness, ensuring efficiency and performance.
ReflCtrl: Controlling LLM Reflection via Representation Engineering
Introduction
The development of LLMs equipped with Chain-of-Thought (CoT) reasoning has marked a significant advancement in the field of artificial intelligence. These models, particularly those with capabilities to self-reflect, have demonstrated substantial improvements in diverse tasks such as mathematics, coding, and general reasoning. ReflCtrl, as proposed in this study, offers an innovative approach to understanding and controlling self-reflection in LLMs through representation engineering.
Methodology
ReflCtrl aims to manage the inherent self-reflection in LLMs to enhance efficiency and reduce unnecessary computational costs. The framework identifies self-reflection steps by segmenting model reasoning into discrete units. Reflection-related segments are distinguished using linguistic cues, allowing the extraction of a reflection direction in the model's latent space. This direction facilitates the modulation of reflection frequency, enabling control over inference cost without sacrificing accuracy. Essentially, ReflCtrl operates by applying a stepwise steering method, intervention set at the onset of reasoning steps, thereby preserving model performance even under substantial reflection reduction.
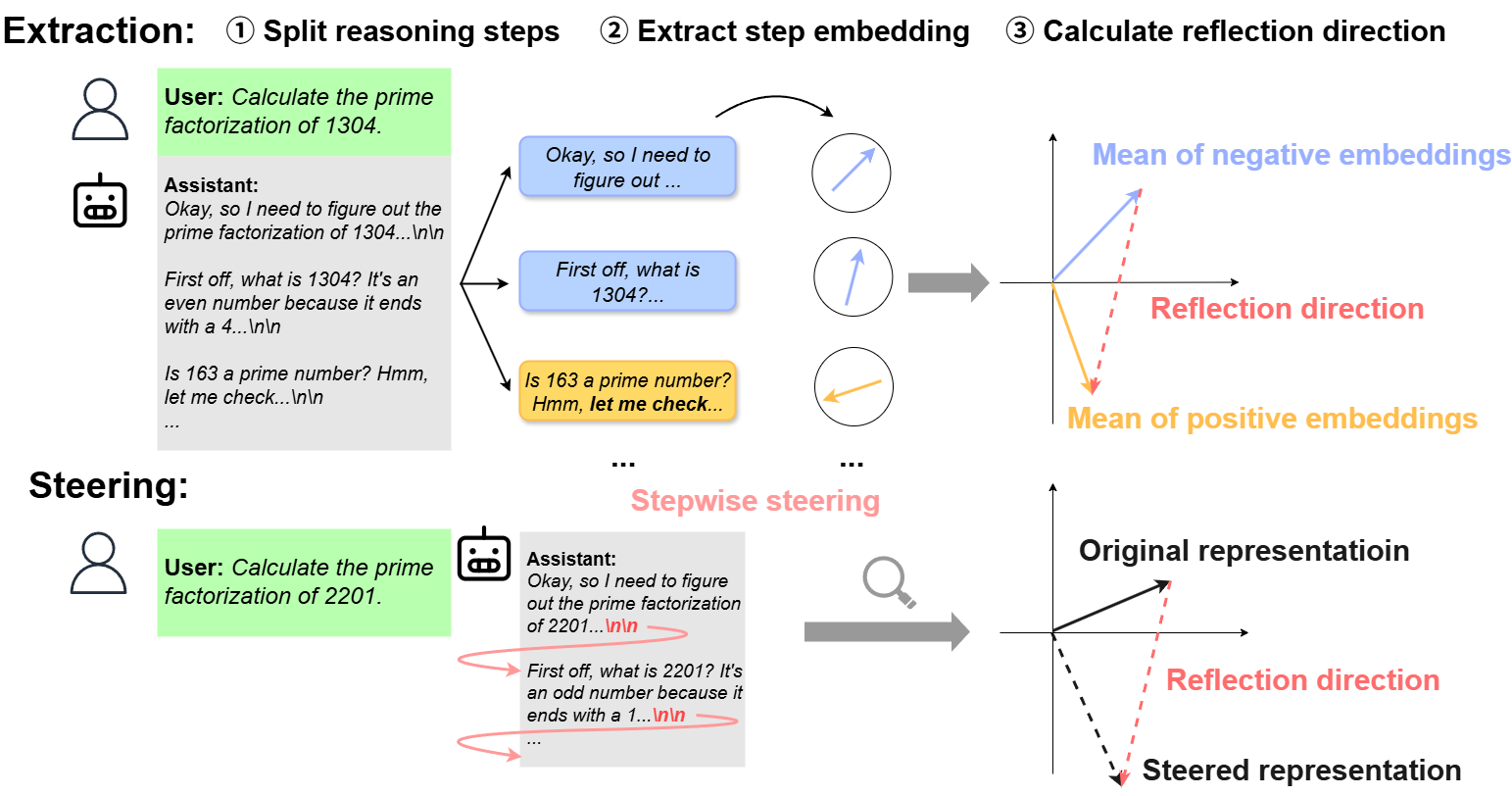
Figure 1: Overview of the proposed ReflCtrl framework. The model's reasoning is first segmented into steps, then reflection-related steps are identified through keywords. Finally, a reflection direction is extracted by calculating the mean difference in the latent space.
Experimental Results
Empirical evaluations confirm that self-reflections in LLMs are often redundant, especially in stronger models, accounting for up to a 33.6% reduction in reasoning tokens without impacting the overall performance. The reflection behavior shows high correlation with internal uncertainty signals, suggesting that a model's uncertainty perception significantly drives self-reflection initiation.
To address redundancies in self-reflection, the framework imposes an intervention by introducing a calculated reflection direction to model workings. The intervention strength can substantially lower reflection frequency, thereby decreasing reasoning token usage and conserving resources. This approach proved more efficient compared to existing methods like NoWait, offering nuanced control over the performance-cost trade-off, as seen in Figure 2 and Figure 3.
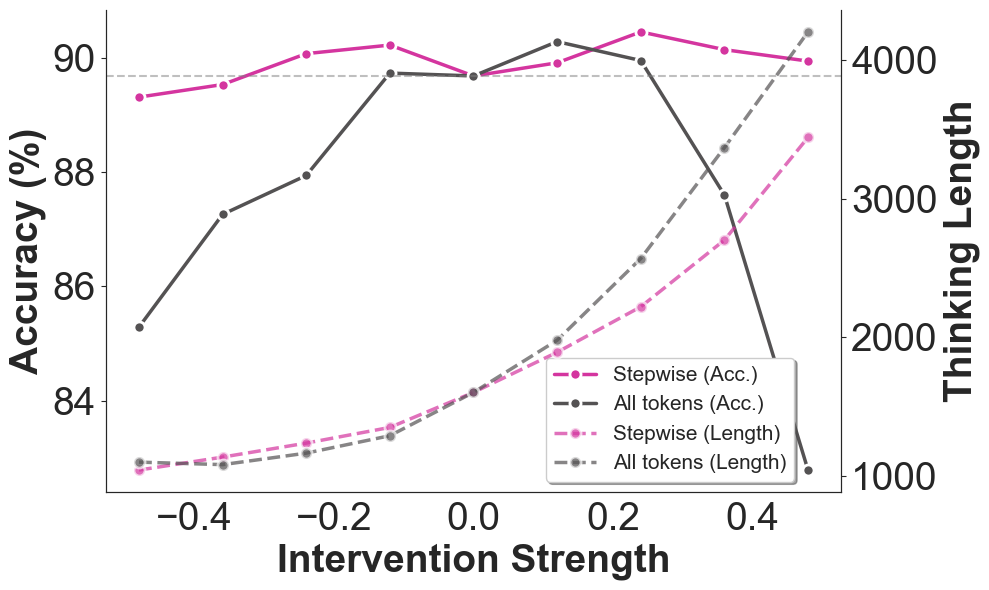
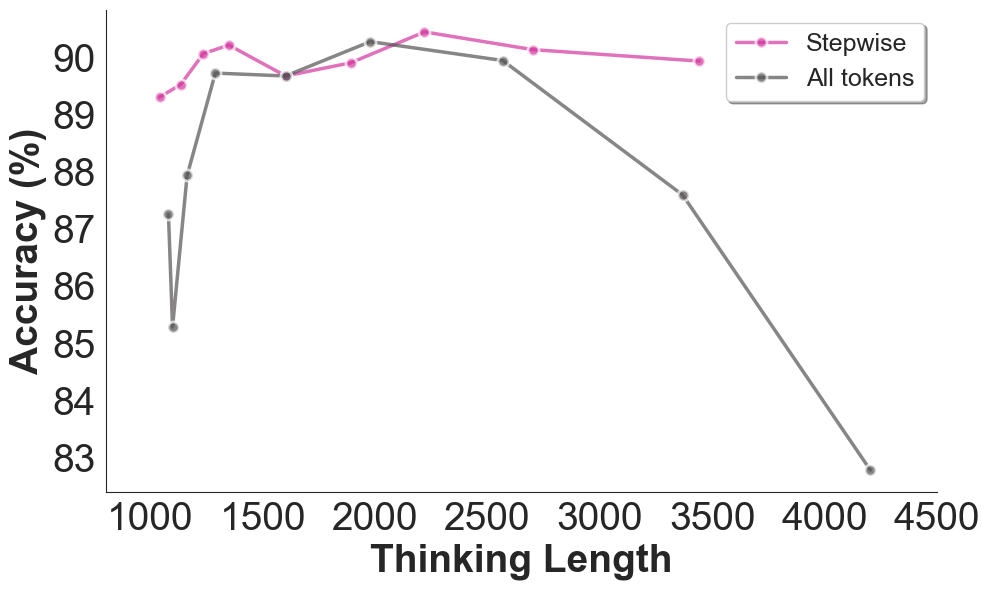
Figure 2: Accuracy and reasoning token usage under different intervention strength.
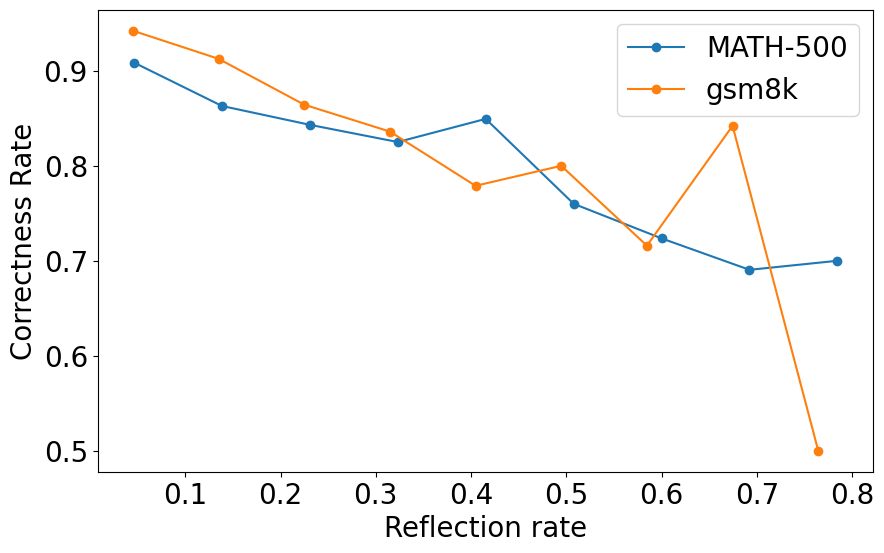
Figure 3: Relationship between correctness rate and reflection rate on MATH-500 and GSM8k datasets. Higher reflection frequency correlates with lower accuracy, partly due to more reflections are generated on difficult questions.
Representation Engineering Perspective
The exploration of reflection directions in the latent space provides insight into the model's internal uncertainty mechanism. This can potentially allow fine-grained probing of the model's reflection behavior. By incorporating reflection directions into a logistic regression classifier, ReflCtrl efficiently predicts answer correctness on benchmark datasets, affirming the hypothesis of uncertainty-based reflection control.
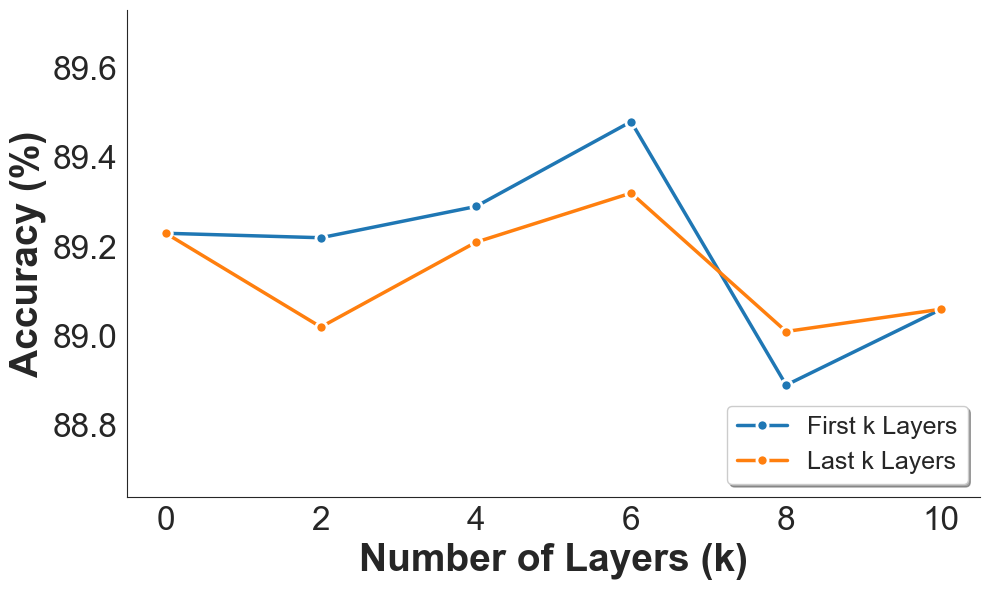
Figure 4: Effect of applying interventions to different layers of the LLM. We vary the number of skipped layers at the bottom and top of the network.
Conclusion
ReflCtrl exemplifies a pioneering step towards efficient reflection control in reasoning LLMs. By adopting a representation engineering lens, the framework optimizes model reflection processes, culminating in significant resource savings and enhanced performance reliability. The integration of reflection direction into the steering methodology promises a scalable approach applicable to a broad spectrum of reasoning tasks.
Through deliberate experimentation, ReflCtrl validates the hypothesis that self-reflection, albeit a valuable reasoning enhancement, is often dispensable in specific scenarios, especially when guided by strategic intervention. Future work could involve refining dynamic steering strengths based on real-time uncertainty assessments, thereby evolving reflection manageability in LLMs for practical applications.