- The paper introduces a lightweight, model-agnostic framework using multi-branch decoders to provide interactive previews during video diffusion generation.
- Methodology leverages early-emerging scene intrinsics (RGB, albedo, depth, normals) to achieve over 4× real-time throughput and effective mode separation.
- Implications include enhanced controllability, reduced hallucination, and improved efficiency in video synthesis through user-guided steering and stochastic renoising.
DiffusionBrowser: Interactive Diffusion Previews via Multi-Branch Decoders
Overview and Motivation
The paper "DiffusionBrowser: Interactive Diffusion Previews via Multi-Branch Decoders" (2512.13690) introduces a model-agnostic, lightweight framework for enabling interactive previews throughout the multi-step denoising trajectory of video diffusion models. Addressing limitations in controllability and sampling efficiency, DiffusionBrowser allows users to inspect, steer, and terminate video generations at any point during the sampling process without compromising final quality. The framework provides multi-modal previews—including RGB, base color (albedo), depth, and surface normals—at more than 4× real-time throughput, and introduces novel multi-branch decoder architectures to tackle inherent superposition and hallucination phenomena in multimodal video synthesis.
Early Emergence of Scene Intrinsics
Recent research indicates that generative models can extract geometric and semantic cues at early stages of processing. To verify whether stable, semantically meaningful previews are feasible before denoising completion, the authors employ systematic linear probing across transformer blocks and diffusion steps. Significant predictive power for scene intrinsics saturates rapidly—around the 5th–15th out of 50 timesteps and 10th–20th out of 30 blocks. Notably, base color, depth, and normals are reliably predicted much earlier than conventional RGB outputs; this trend holds across both linear and nonlinear analyses.


Figure 1: Prediction accuracy saturates for scene intrinsics early in both block and timestep domains, supporting efficient preview capability from intermediate diffusion features.
Architectural Innovations: Multi-Branch Decoders
A core technical advance is the multi-branch, multi-loss decoder architecture. Standard decoders trained with MSE loss are susceptible to multimodal uncertainty, manifesting as ambiguous, superimposed, or blurred patches during intermediate steps. This arises because the conditional posterior is highly multimodal at high-noise timesteps, and the model's prediction of the posterior mean yields unrealistic samples between valid modes. The multi-branch decoder mitigates this by introducing K independent predictor branches, each optimizing both branch-wise and ensemble losses. Each branch learns to favor different modes, and their ensemble average approximates the ground truth mean. A toy tri-modal experiment demonstrates that the multi-branch approach eliminates hallucination and superposition, producing artifact-free, mode-consistent outputs even under stringent sampling.

Figure 2: The multi-branch decoder recovers each distinct data mode in a toy tri-modal setting, resolving the superposition issue present in standard single-branch MSE decoders.

Figure 3: The multi-branch decoder, trained on intermediate diffusion features, leverages both per-branch and ensemble losses for optimal mode separation.

Figure 4: Multi-branch decoding delivers sharper, more interpretable previews compared to naive single-branch counterparts, which blur ambiguous regions.
Temporal and Structural Evolution of Previews
The paper provides an extensive analysis of how various intrinsics evolve temporally and structurally throughout the denoising process. Coarse scene geometry and semantic structure emerge as early as ∼10% of the denoising schedule, with subsequent steps refining detail and appearance. Blockwise analysis reveals that mid-level transformer blocks capture the optimal balance between geometric fidelity and color layout, with minor degradation observed in deeper layers.
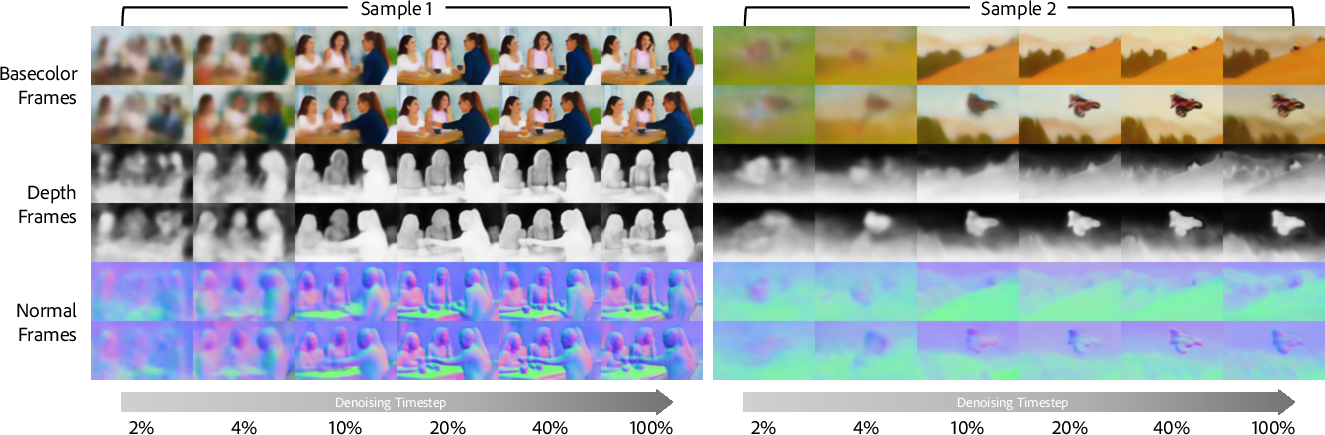
Figure 5: Timestep-wise evolution captures the rapid emergence and refinement of base color, normal, and albedo.
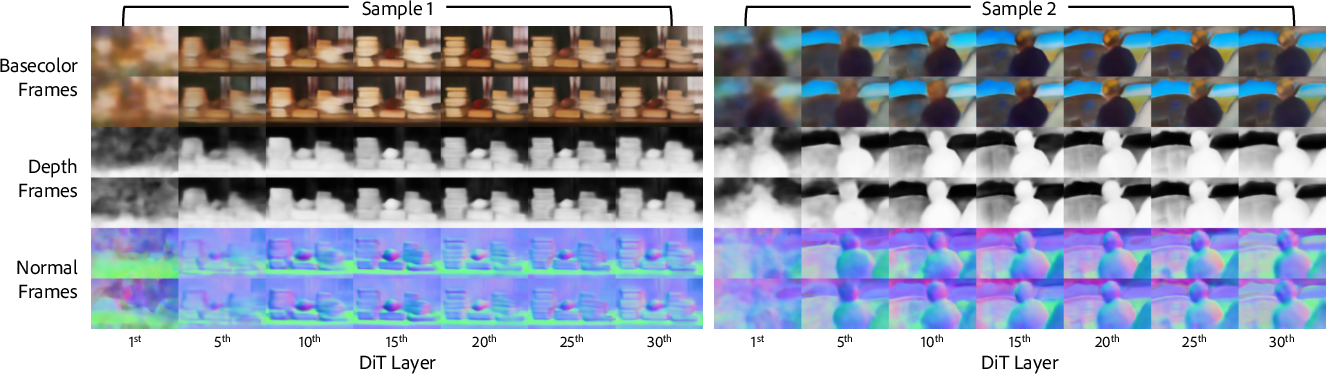
Figure 6: Block-wise intrinsics show peak predictability in mid-level blocks, aligning with the temporal emergence trends.
Rubber-Like 4D Previsualization and Interpretation
Intrinsic previews from DiffusionBrowser facilitate a "rubber-like" visualization of temporal scene dynamics at early noise levels, enabling interpretable recognition of objects, motion, and layout long before the full-denoised output is produced.
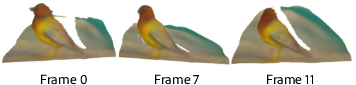
Figure 7: Even at early timesteps, previews enable robust, structurally coherent 4D visualizations of the scene.
Interactive Variation and Steering
DiffusionBrowser supports new interactive modalities for user-driven exploration:
- Stochastic Renoising: Users inject controlled stochasticity at preview stages, renoising latents to produce diversified outputs that retain coarse context but vary fine details.

Figure 8: Stochastic variation preserves global structure while modifying localized video content.
- Latent Steering: The preview decoder enables targeted modification of base color, depth, or normal at intermediate timesteps, allowing for semantically meaningful changes directly in feature space.

Figure 9: Steering base color mid-denoising yields pronounced, contextually coherent output variations on a fixed text prompt.

Figure 10: Expression of user-guided variation in base color, depth, and normal demonstrates utility and control over generative outcomes.
Addressing Hallucination and Superposition
A central claim is that the superposition problem—diffusion features encoding multiple plausible future states—causes artifacts in naive decoders and is a superset of classical hallucination issues (e.g., six-finger hands). The multi-branch ensemble, optimized with LPIPS and L1 losses, explicitly alleviates these by separating modes and maintaining diversity. Toy and real data experiments empirically corroborate this claim.
Ablation, Efficiency, and Perceptual Quality
Quantitative evaluation indicates that the multi-branch decoder achieves superior PSNR and lower L1 error across modalities when compared to both linear decoders and direct VAE latent predictions. Wall-clock inference benchmarks show the approach is resource-efficient, with negligible overhead. User studies—across content predictability, visual fidelity, and scene clarity—demonstrate that intrinsic previews are preferred over standard latents by a majority of participants.
Limitations and Future Directions
Certain steering operations (intrinsic editing) occasionally fail, particularly for out-of-distribution targets or extreme geometric edits; the added objects or manipulated structures can gradually dissipate during denoising. The preview steering methodology is dependent on the decoder's capacity and intrinsic representation design. Potential extensions include improved decoder architectures, finer granularity control, text-conditioned interaction, and expansion to cover broader intrinsic modalities.
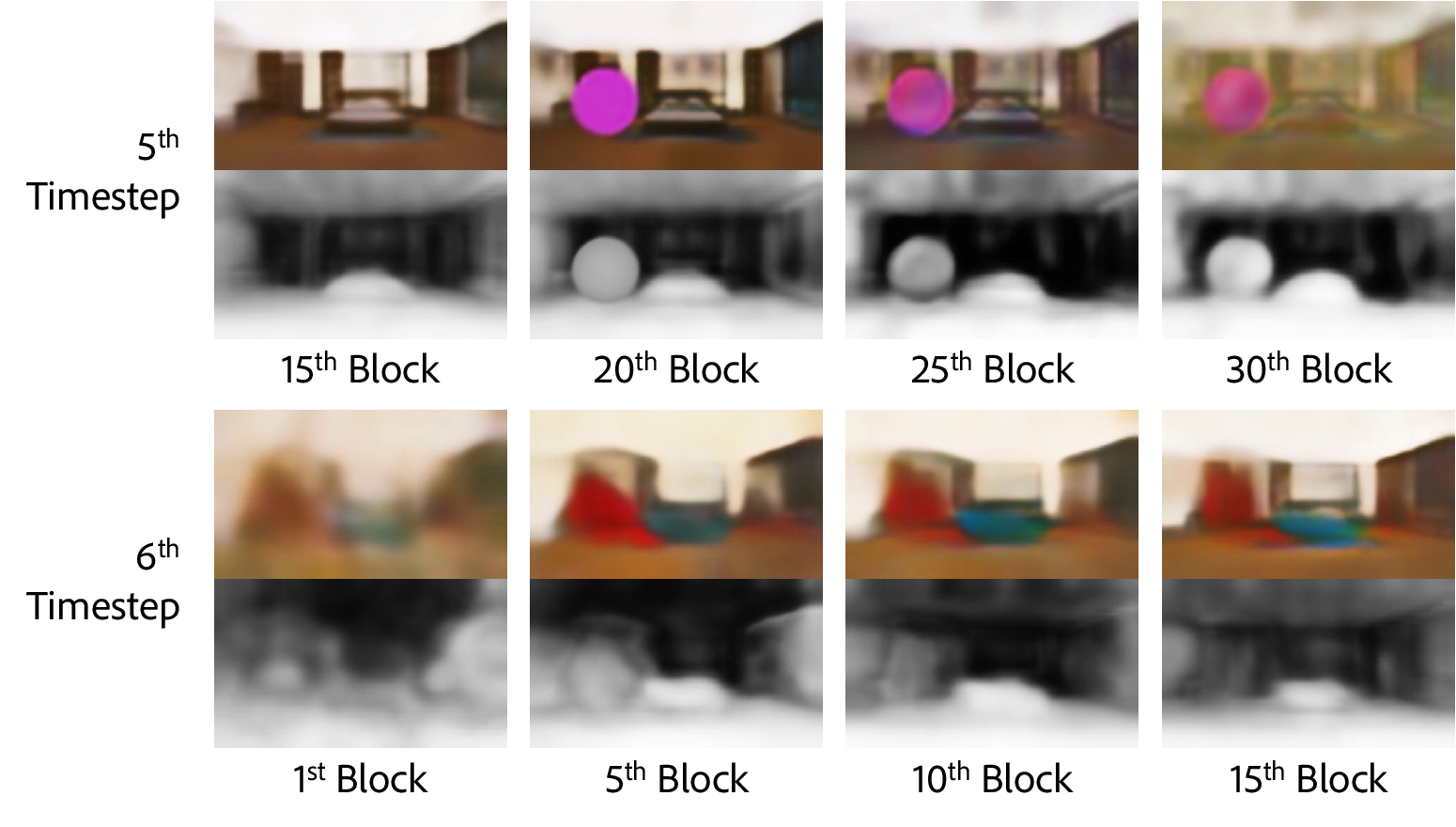
Figure 11: Example of steering failure, highlighting gradual dissipation of added object across subsequent denoising steps.
Conclusion
DiffusionBrowser systematically exposes, interprets, and manipulates the internal evolution of video diffusion models by leveraging early-emerging scene intrinsics and multi-branch decoding. The framework yields actionable previews, advances controllable video synthesis, and provides efficient, modality-rich tools for user interaction, interpretability, and resource management. The architectural insights on superposition and mode collapse have practical implications for future generative model design and sampling, especially in high-dimensional and multihypothesis scenarios. This work sets a foundation for developing transparent, interactive, and control-driven generative video pipelines.