- The paper introduces Diffusion Preview and ConsistencySolver, a method enabling fast and consistent low-step sampling for generative diffusion models.
- It employs an RL-optimized, step-adaptive ODE integrator that blends predicted noises to enhance perceptual and structural fidelity.
- Empirical results show improved FID scores with 47% fewer steps and reduced user interaction time by up to 50%, outperforming baselines.
Diffusion Preview and ConsistencySolver: Efficient, Consistent Low-Step Diffusion Sampling
Motivation and Framework
The computational latency of iterative diffusion model inference remains a principal limitation for interactive and resource-constrained generative applications. This work introduces the Diffusion Preview paradigm, which decomposes user interactions into a rapid, low-step preview phase followed by full-fidelity refinement. The approach mandates previews that are both high-fidelity surrogates of the final output and strictly consistent with the refinement step, i.e., identical input parameters must yield deterministically aligned outputs for preview and full-resolution generations. This property enables fast iteration on prompts and seeds with effective expectation management and significantly reduced wasted computation.
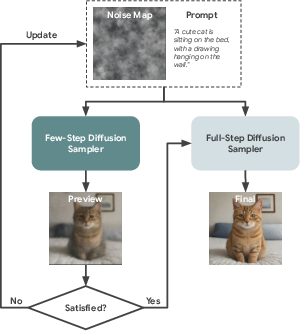
Figure 1: Workflow of the Diffusion Preview paradigm, combining rapid, low-step previews for user evaluation and full-fidelity generation only for candidate refinement.
ConsistencySolver: Adaptive High-Order ODE Solving
Classical sampling acceleration for Score-based Generative Models relies on either training-free numerical schemes (e.g., DPM-Solver, UniPC, DDIM) or post-training distillation to fewer denoising trajectories. The former often fails to deliver structural or semantic fidelity in the low-step regime, while the latter introduces undesirable error accumulation and breaks deterministic ODE mapping, fundamentally damaging seed-to-output correspondence.
This work proposes ConsistencySolver, an explicit, lightweight, multi-step ODE integrator derived from the general Linear Multistep Method (LMM) and optimized by reinforcement learning. Unlike fixed-coefficient solvers, at each denoising step ConsistencySolver synthesizes the weighted blend of previous predicted noises using an MLP policy, whose coefficients are tuned to maximize perceptual and structural similarity with the reference high-step trajectory.
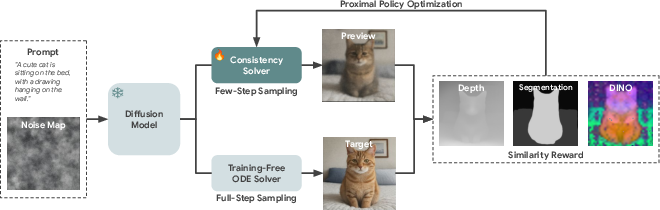
Figure 2: Structure of the RL-driven ConsistencySolver, which generates preview images using a learned ODE solver parametrized by step-adaptive coefficients.
The solver explicitly enforces:
- Explicit-only update (avoiding implicit methods, justified by non-stiffness of PF-ODEs),
- Anchor to the current state (only the latest latent is the integration base),
- Timestep-conditioned, context-adaptive coefficients (learned by the policy net).
Reinforcement Learning for Solver Policy
Solver coefficients are directly parameterized and optimized using PPO, leveraging non-differentiable perceptual rewards (e.g., CLIP, DINO, Depth, or semantic segmentation alignment) between previews and full-resolution references. This bypasses backpropagation through the diffusion model itself and ensures low memory overhead. The reward model can be readily swapped to enforce desired edit properties or task-dependent alignment metrics.
Empirical results substantiate several strong claims:
- ConsistencySolver achieves equivalent FID to DPM-Solver (20.39 vs. 25.87) using 47% fewer steps.
- It outperforms all considered distillation and training-free baselines in semantic, structural, and perceptual consistency across multiple metrics.
- User studies (both human and LLM-based) report up to 50% reduction in user interaction time, and satisfaction coverage of 94.2% of prompts, compared to <60% for one-step GAN-distilled models.
Empirical Results
For both text-to-image (Stable Diffusion) and instructional image editing (FLUX.1-Kontext), ConsistencySolver demonstrates significantly better preview fidelity, adherence, and seed-to-output stability than all baselines irrespective of step count. Notably, for five inference steps, ConsistencySolver yields FID=20.39, outperforming DPM-Solver and deviation-minimizing distillation baselines on all major image-level, feature-level, and structural metrics.

Figure 3: Visual comparison for text-to-image preview generation, showing superior output similarity and structure retention for ConsistencySolver over baselines.
In context-driven image editing, it similarly demonstrates state-of-the-art Edit Reward and consistency, underlining its applicability in vision editing tasks.

Figure 4: Qualitative results on the FLUX.1-Kontext instructional editing task, where ConsistencySolver achieves high-fidelity, instruction-aligned previews at very low step counts.
Ablation over solver order confirms that order-4 yields the best efficiency/fidelity trade-off, and reward model search reveals that Depth reward confers superior generalization and robustness for structural consistency.
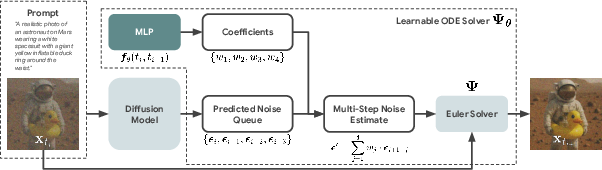
Figure 5: ConsistencySolver workflow for order-4, with dynamic coefficient generation conditioning each integration update in the trajectory.
Discussion and Implications
The work establishes that low-step, RL-optimized multi-step ODE solvers can provide practically viable, deterministic, high-fidelity previews for diffusion models, unlocking their utility for real-world, iterative human workflows. Enforcement of deterministic seed-to-preview-to-final output mappings is shown to be essential—improving FID is insufficient if user decisions in preview mode misalign with final outputs, as is the case for most GAN-based distillation strategies.
Theoretically, this demonstrates that the PF-ODE sampling dynamics of state-of-the-art diffusion models remain sufficiently regular to be captured and adapted by compact neural integrators, obviating the need for weight distillation and complex error-trading. Practically, this design is readily portable across architectures and amenable to swap-in reward functions, suggesting broad deployment potential in creative applications, design tools, and on-device generative systems.
Conclusion
Diffusion Preview and ConsistencySolver constitute a significant advance in fast, consistent, human-aligned generative sampling. The explicit, RL-driven solver attains strong improvement in speed-quality trade-off, ensures robust determinism under user exploration, and outperforms both training-free and distillation-based predecessors across major axes of generative utility. This architecture suggests a new pathway for integrating RL-based policy search into core generative model runtime, and points to greater customizability and user-aligned reward optimization for future diffusion frameworks.