Seedream 4.0: Toward Next-generation Multimodal Image Generation
Abstract: We introduce Seedream 4.0, an efficient and high-performance multimodal image generation system that unifies text-to-image (T2I) synthesis, image editing, and multi-image composition within a single framework. We develop a highly efficient diffusion transformer with a powerful VAE which also can reduce the number of image tokens considerably. This allows for efficient training of our model, and enables it to fast generate native high-resolution images (e.g., 1K-4K). Seedream 4.0 is pretrained on billions of text-image pairs spanning diverse taxonomies and knowledge-centric concepts. Comprehensive data collection across hundreds of vertical scenarios, coupled with optimized strategies, ensures stable and large-scale training, with strong generalization. By incorporating a carefully fine-tuned VLM model, we perform multi-modal post-training for training both T2I and image editing tasks jointly. For inference acceleration, we integrate adversarial distillation, distribution matching, and quantization, as well as speculative decoding. It achieves an inference time of up to 1.8 seconds for generating a 2K image (without a LLM/VLM as PE model). Comprehensive evaluations reveal that Seedream 4.0 can achieve state-of-the-art results on both T2I and multimodal image editing. In particular, it demonstrates exceptional multimodal capabilities in complex tasks, including precise image editing and in-context reasoning, and also allows for multi-image reference, and can generate multiple output images. This extends traditional T2I systems into an more interactive and multidimensional creative tool, pushing the boundary of generative AI for both creativity and professional applications. Seedream 4.0 is now accessible on https://www.volcengine.com/experience/ark?launch=seedream.
First 10 authors:











Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Seedream 4.0 explained (for a 14-year-old)
1) What is this paper about?
This paper introduces Seedream 4.0, a next‑generation AI system that can:
- Make images from text (you describe something; it draws it).
- Edit existing images based on instructions.
- Combine several images into a new one.
It’s designed to be very fast, handle high‑resolution pictures (up to 4K), and understand both pictures and words together.
2) What questions does it try to answer?
In simple terms, the team asks:
- How can we make an image AI that is both very strong (great quality, precise control) and very fast?
- Can one system handle many image tasks at once (text-to-image, image editing, multi‑image mixing)?
- How do we train it on massive, varied data—including tricky stuff like charts, math formulas, and instructions—so it works well in both creative and professional settings?
3) How did they build it? (Methods in everyday language)
To explain the tech, think of three big parts: the brain, the zipper, and the coach.
- The brain (Diffusion Transformer, “DiT”): Imagine starting with TV static (random noise) and “un‑noising” it step by step until a clear picture appears. That’s a diffusion model. The “Transformer” part is a powerful pattern-finder (used in many AIs) that helps the system understand complex instructions and details. Seedream 4.0 builds an efficient version so it can think fast and big.
- The zipper (VAE, a Variational Autoencoder): A VAE is like a smart “zip” tool: it compresses images into a smaller form for the model to handle, then unzips them back into high‑quality images. Seedream’s VAE compresses a lot (fewer “image tokens,” or pieces), so training and drawing large images is faster and cheaper—like sending a zipped file instead of the full thing.
- The coach (Post‑training with a Vision‑LLM, or VLM):
- Continuing Training (CT): broadens skills and follows instructions better.
- Supervised Fine‑Tuning (SFT): sharpens style and accuracy using examples.
- RLHF (Reinforcement Learning from Human Feedback): teaches it to match human preferences.
- A “Prompt Engineering” helper model: rewrites your prompt if needed, routes tasks, and even picks a good canvas size, like a helpful co‑pilot.
They also improved the training data:
- They used billions of text–image pairs, including tricky “knowledge” images (charts, math, documents).
- They filtered out low‑quality captions and repeated images, and improved captions to be more detailed and accurate.
They made it faster at drawing:
- Fewer steps to finish a picture, but same (or better) quality, using techniques like “adversarial distillation” (a student model learns from a teacher model and a smart checker), “distribution matching” (learn the right variety of images), and “quantization” (store numbers with fewer digits to compute faster).
- “Speculative decoding” for the helper model: it drafts likely next steps to speed up thinking, like sketching before finalizing.
They also tuned the software and hardware:
- Better memory use, custom GPU kernels, and balancing the workload so big training jobs run smoothly across many GPUs.
4) What did they find, and why is it important?
The paper reports that Seedream 4.0:
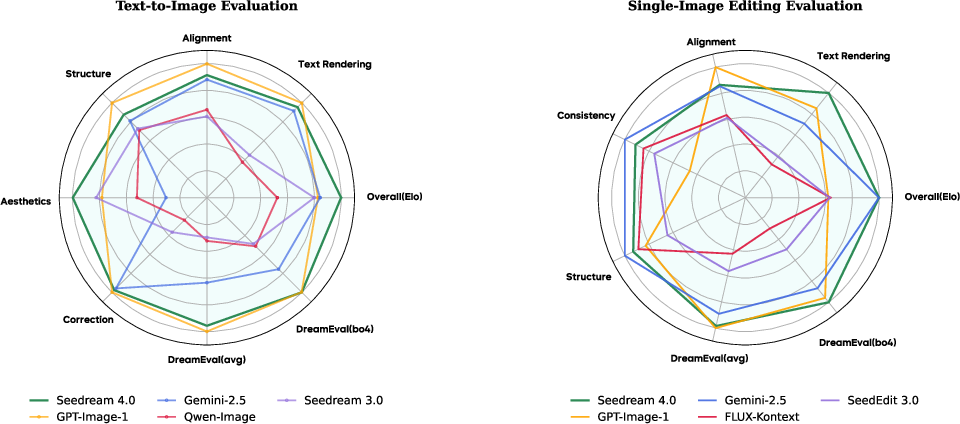
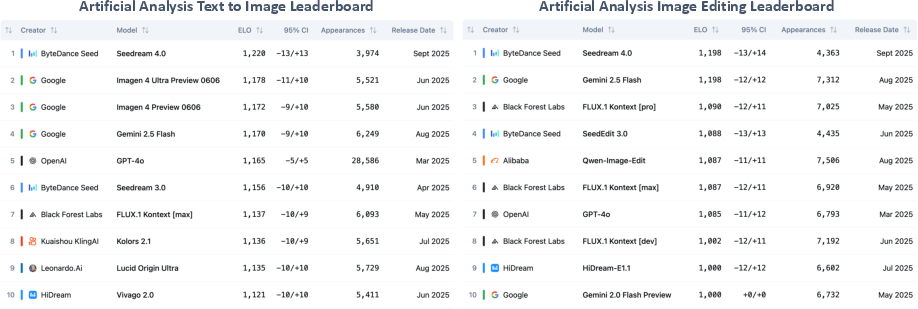
- Tops public leaderboards (as of the paper’s date) for both text‑to‑image and image editing.
- Generates a 2K image in about 1.4 seconds (without using its helper LLM), which is extremely fast for high resolution.
- Works well across many tasks:
- Precise editing (change what you want, keep everything else consistent).
- Multi‑image reference (use multiple source images to guide the result).
- Visual controls (draw with edges, masks, depth—like giving it a sketch or outline to follow).
- In‑context reasoning (it can “think” about the situation, physics, space, and style to make sensible images).
- Advanced text rendering (clear UI layouts, posters, equations, charts).
- Adaptive aspect ratio and true 4K images (it can choose a better canvas shape automatically).
- Multi‑image outputs (create a consistent set of images, helpful for comics/storyboards or product lines).
Why this matters:
- You get better pictures, more control, and less waiting—great for artists, designers, teachers, marketers, and everyday users.
- It handles professional content (like equations and charts), not just pretty pictures.
- The speed and efficiency make it more practical (cheaper, greener, easier to scale).
5) What’s the impact?
Seedream 4.0 shows how one AI can become an “all‑in‑one” creative tool:
- For creativity: faster drafts, consistent characters across panels, style transfer, precise edits—all at high resolution.
- For work and school: clean charts, diagrams, formulas, UI mockups, and multilingual text editing directly inside images.
- For the future: its efficient design means it can keep getting bigger and smarter (e.g., even better reasoning) without becoming too slow or expensive.
In short, Seedream 4.0 pushes image AI toward being fast, flexible, and reliable enough for both fun and serious projects—bringing professional‑grade image creation to more people.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what the paper leaves missing, uncertain, or unexplored. Each item is formulated to be concrete and actionable for future research.
- Architecture transparency: The paper lacks detailed DiT and VAE specifications (parameter counts, layer types, attention patterns, latent dimensions, token compression ratio, codebook, up/down-sampling, normalization, positional encoding), making replication and independent analysis impossible.
- VAE compression trade-offs: No ablation quantifying how the “high compression ratio” affects perceptual quality, text legibility, fine detail preservation, and editing fidelity across resolutions (1K–4K).
- Tokenization/latent design choices: Unclear rationale and empirical evidence for the chosen latent token granularity and its impact on controllability, memory, and speed; no comparison against alternative latent/tokenization designs.
- Efficiency attribution: Missing ablations that separate the contributions of DiT architecture changes, VAE compression, adversarial distillation, quantization, and speculative decoding to the reported >10× speedup and 1.4 s/2K latency.
- Stability criteria for adversarial distillation/matching: The adversarial post-training pipeline (ADP + ADM) is described but lacks convergence diagnostics, failure modes, hyperparameter sensitivity, and theoretical guarantees against mode collapse or distribution drift.
- Few-step sampling quality vs diversity: No systematic evaluation of how reduced NFE affects aesthetic quality, semantic alignment, structural fidelity, and diversity across prompt classes, resolutions, and editing scenarios.
- Data composition and licensing: “Billions of text–image pairs” are not broken down by source, license, geographic/language distribution, modality types, or synthetic vs natural content; consent, privacy, and intellectual property safeguards are unspecified.
- Knowledge-centric data coverage: The redesigned pipeline for instructional/formula data lacks quantitative coverage metrics (topic taxonomy, symbol/structure distributions), error rates from OCR/LaTeX synthesis, and measures of correctness and visual readability.
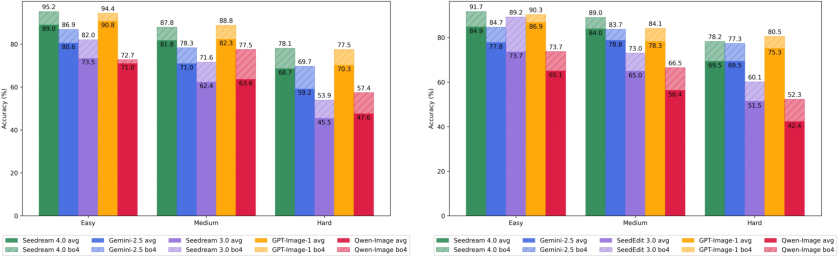
- Difficulty classifier validation: No benchmarks, inter-rater agreement, or calibration studies for the easy/medium/hard difficulty classifier; unclear how down-sampling “extremely difficult” samples affects learning and generalization.
- Caption quality classifier and refinement: Missing metrics for the text-quality classifier, caption refinement model performance, and the impact of these steps on downstream alignment and editing consistency.
- Deduplication pipeline: No quantitative evaluation of semantic + low-level visual embedding deduplication (false positive/negative rates, effect on long-tail coverage and bias).
- Cross-modal alignment: The “stronger cross-modal embedding” and retrieval engine are introduced without empirical alignment metrics, robustness tests (e.g., multilingual, noisy captions), or comparison to CLIP-like baselines.
- Training compute and scaling laws: Absent details on total GPU hours, hardware specs, batch sizes, learning rates, optimizer schedules, and scaling behavior across model sizes/resolutions.
- Causal diffusion in DiT: The joint post-training “causal diffusion” design is not specified algorithmically; unclear how causality is enforced, how it interacts with editing tasks, and whether it improves instruction-following or consistency.
- RLHF protocol: No description of preference data sources/size, annotator guidelines, reward model architecture, reward shaping, safety objectives, or quantitative alignment improvements attributable to RLHF vs SFT alone.
- PE (Prompt Engineering) VLM model specifics: Lacking architectural details, training data for the PE VLM, grounding/attribution guarantees for prompt rewriting, task routing accuracy, and failure modes (e.g., misrouting complex edits).
- Dynamic “thinking budgets”: Unclear policy for budget assignment, latency–quality tradeoffs, and user control; absent metrics showing when and how deeper reasoning meaningfully improves outputs.
- Speculative decoding for PE: No quantitative speed/accuracy gains vs baselines, robustness to stochastic sampling, and generality across languages and input types; KV-cache loss formulation details and hardware effects are missing.
- Quantization and sparsity: Missing calibration dataset description, per-layer sensitivity analysis, accuracy impact across content types (e.g., dense text), and cross-hardware performance portability (NVIDIA/AMD/CPU/NPUs).
- Ultra-fast inference reproducibility: The 1.4 s (2K) claim is reported “without a LLM/VLM as PE,” but there is no latency breakdown including PE, multi-image inputs, or visual signal controls; variability across prompts/hardware is not reported.
- Multimodal editing trade-offs: The paper claims balanced instruction-following and consistency, but lacks quantitative tests across more challenging edits (e.g., large viewpoint changes, complex compositing) and formal definitions of “consistency.”
- Dense text rendering evaluation: No standardized metrics for text legibility (CER/WER), font/style fidelity, multilingual coverage (Chinese vs other scripts), and layout correctness under high compression and few-step sampling.
- Knowledge correctness: In “knowledge-centric” generation (charts, formulas), there is no evaluation of factual correctness, numerical accuracy, or symbolic integrity; no datasets or protocols for verifying semantic validity of rendered content.
- Multi-image reference scalability: Claims of handling “more than ten images” lack memory/latency profiles, degradation curves of structure/alignment, and strategies for saliency extraction and conflict resolution across many references.
- Multi-image output coherence: No quantitative metrics for character/style consistency across sequences, global narrative coherence, or error accumulation in multi-step planning; absent user controls for coherence constraints.
- Visual signal controls: The single-model integration of edges/masks/depth/sketches lacks control strength calibration, failure cases (e.g., conflicting signals), and comparisons to specialized ControlNet variants.
- Safety and misuse: No discussion of content moderation, harmful prompt handling, watermarking/provenance (C2PA), identity/IP protection in reference-based generation, or guardrails against impersonation/deepfakes.
- Robustness to adversarial inputs: The system’s resilience to adversarial prompts, prompt injection in PE, and image-based attacks (e.g., adversarial patterns in references) is not evaluated.
- Bias and fairness: No analysis of demographic, cultural, or stylistic biases introduced by training data or post-training; missing fairness metrics and mitigation strategies across languages and regions.
- Evaluation dependence on arenas: Reliance on Elo from Artificial Analysis Arena and internal MagicBench/DreamEval lacks transparency on prompt pools, leakage risks, and reproducibility; public release and independent auditing are not indicated.
- Hard-case performance drops: Noted degradation on DreamEval’s hard level (especially single-image editing) is acknowledged but not dissected; no error taxonomy or targeted interventions beyond “scale with data.”
- Generalization beyond images: Video generation, temporal coherence, and 3D-aware view consistency are not addressed; unclear whether adversarial distillation/quantization strategies transfer to video or 3D tasks.
- Aspect ratio adaptation: The automatic canvas selection mechanism lacks algorithmic description, failure cases (extreme aspect ratios), and evaluation of composition gains vs user-specified ratios.
- API/productization details: No specifications on reproducible seeds, determinism under quantization, batch inference behaviors, or user-facing controls for consistency and safety in practical deployments.
- Environmental impact: Training/inference energy consumption, carbon footprint, and efficiency trade-offs vs prior Seedream versions are not reported.
- Open-source/release plan: Code, models, benchmarks (MagicBench 4.0, DreamEval), and data availability are unclear; without public artifacts, independent verification and community advancement are limited.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging Seedream 4.0’s efficient DiT+VAE architecture, multimodal post-training (T2I + image editing), multi-image reference and output, controllable visual signals, advanced text rendering, adaptive aspect ratio, and 1K–4K native, ultra-fast inference.
- Creative and advertising content studio (sector: media/marketing)
- Use case: Rapid generation of 4K posters, social ads, banners, and campaign variations with precise brand styling and typography.
- Tools/workflows: Adobe/Figma plugins for “Prompt-to-Poster” and “Layout-Aware Poster Builder” using adaptive aspect ratios and dense text rendering.
- Assumptions/dependencies: Brand style guides or reference images; human review for claims and compliance; color/typography asset licenses.
- E-commerce merchandising and localization (sector: retail/e-commerce)
- Use case: Bulk product imagery editing (background cleanup, colorways), on-image text translation, virtual try-on, shelf arrangement via multi-image reference.
- Tools/workflows: “SKU Studio” API integrated with Shopify/WooCommerce; batch pipelines for localization and A/B variants; perspective correction for product photos.
- Assumptions/dependencies: Access to catalog images; truthful representation policies; OCR/caption quality; PE-model latency when enabled.
- Brand identity packs and emoji/IP derivatives (sector: media/entertainment)
- Use case: Multi-image output for consistent character sheets, emoji sets, stickers, or IP-themed merchandise from a single style reference.
- Tools/workflows: “Brand Pack Generator” producing coherent sets; style/IP transfer via multi-image reference.
- Assumptions/dependencies: Legal rights to use brand/IP; curator approval; sampling to select best-of-n outputs.
- Storyboarding and comics (sector: film/animation/gaming)
- Use case: Character-consistent, multi-image sequences for previsualization and narrative exploration.
- Tools/workflows: “Storyboard Co-Pilot” that ingests character and scene references; adaptive ratio for composition.
- Assumptions/dependencies: Art-direction references; human oversight for continuity and pacing.
- UI/UX mockups and design systems (sector: software/design)
- Use case: Generating wireframes, layouts, and interface drafts with accurate text placement and dense rendering.
- Tools/workflows: Figma plugin for “Prompt-to-UI”; export high-res design boards.
- Assumptions/dependencies: Design tokens/components; review to avoid hallucinated interactions or non-compliant controls.
- Education and publishing visuals (sector: education)
- Use case: Diagrams, mathematical formulas, chemical equations, charts, and bilingual instructional graphics at 4K print quality.
- Tools/workflows: “Lesson Visualizer” producing classroom-ready visuals; labeling/annotation via the PE model.
- Assumptions/dependencies: Educator prompts; fact-checking; accessibility review (contrast, alt-text).
- Technical documentation and infographics (sector: engineering/enterprise)
- Use case: Flowcharts, schematics, dashboards, and domain-specific visuals with precise text-aware editing and layout control.
- Tools/workflows: “Docs-to-Graphic” add-ins for Office/Notion; chart rendering tied to tabular inputs.
- Assumptions/dependencies: Verified data sources; standards compliance; font and icon licensing.
- Photo labs and consumer editors (sector: consumer software)
- Use case: Prompt-based precise edits (background replacement, object addition/removal, perspective correction, text replacement) with high visual integrity.
- Tools/workflows: “Smart Editor” mobile/web app; rapid 2K generation (~1.4s when PE disabled) for interactive sessions.
- Assumptions/dependencies: Device/GPU availability; identity-sensitive edits require ethical guardrails; PE model raises latency.
- Multimodal controllable generation from visual signals (sector: architecture/interior/design)
- Use case: Sketch-/edge-/depth-guided composition for rooms, furniture, and structural layouts without separate ControlNet models.
- Tools/workflows: “Sketch-to-Render” supporting Canny edges/depth maps/masks; composition of multiple references.
- Assumptions/dependencies: Quality of control signals; user skill in drafting guides; style constraints.
- Packaging and print/signage production (sector: manufacturing/retail)
- Use case: High-resolution label/poster/packaging art with accurate typography and layout.
- Tools/workflows: Prepress workflow integration; CMYK-aware exports.
- Assumptions/dependencies: Color management; font licensing; compliance review.
- Synthetic data for computer vision (sector: academia/ML/CV)
- Use case: Controlled image generation (edges/depth/masks) for detection/pose/layout training and robustness testing.
- Tools/workflows: “Dataset Forge” to generate labeled variants and edge cases; DreamEval-style automated QA.
- Assumptions/dependencies: Domain gap mitigation; labeling pipelines; bias checks.
- Public information graphics and localization (sector: policy/public sector)
- Use case: Rapid production of infographics and multilingual public advisories with consistent visuals.
- Tools/workflows: Government content studio with approvals; templates for accessibility.
- Assumptions/dependencies: Strict fact-checking; content provenance/watermarking; accessibility standards (WCAG).
- Content moderation testbeds (sector: platform governance)
- Use case: Synthesizing edge cases for moderation systems (e.g., text-on-image in multiple languages, composite scenes).
- Tools/workflows: Scenario generators for policy audits; stress tests using multi-image composition.
- Assumptions/dependencies: Safe-mode configurations; controlled access; compliance logging.
- Platform/API adoption (sector: cloud/software)
- Use case: Enterprise deployment via Volcano Engine, Doubao, Jimeng integrations for high-throughput generation/editing.
- Tools/workflows: SLAs, autoscaling, hybrid quantization for cost efficiency; speculative decoding for the PE model.
- Assumptions/dependencies: Service availability; hardware-specific operator support; usage caps and governance.
Long-Term Applications
The following applications require further research, scaling, integration, or validation, including stronger reasoning, extended modalities, on-device optimization, provenance, and industry certification.
- Real-time, on-device generation for AR/VR (sector: mobile/XR)
- Use case: 2K scene/textured overlays in AR shopping, navigation, or entertainment.
- Tools/workflows: Hardware-aware quantization/sparsity; custom kernels; memory-optimized runtimes.
- Assumptions/dependencies: Mobile GPU/NPU support; low-latency PE; battery/thermal constraints.
- Video generation and editing (sector: media/gaming)
- Use case: One-/few-step video synthesis and precise video edits leveraging ADM/ADP principles.
- Tools/workflows: “Storyboard-to-Video” extensions; temporal consistency discriminators.
- Assumptions/dependencies: Large video datasets; temporal alignment losses; safety and IP compliance.
- Agentic creative suites (sector: marketing/design)
- Use case: Campaign-level planning and auto-composition across multiple deliverables with dynamic “thinking budgets.”
- Tools/workflows: VLM-driven task routing, prompt rewriting, aspect-ratio estimation; iterative multi-output refinement.
- Assumptions/dependencies: Reliable in-context reasoning; scalable PE; guardrails for brand and legal constraints.
- Digital twins and simulation asset generation (sector: robotics/AV/simulation)
- Use case: Photo-real textures, scene variants, and physically coherent multi-object compositions for sim pipelines.
- Tools/workflows: Texture-set generators; physics-aware layout guidance via visual signals.
- Assumptions/dependencies: Realism validation; sim-to-real transfer; domain fidelity and bias control.
- Assembly and maintenance instruction synthesis (sector: manufacturing/industrial)
- Use case: Generating stepwise visual instructions from multi-image references (parts, tools, states).
- Tools/workflows: “Assembly Composer” with structure-preserving outputs; consistency checks across steps.
- Assumptions/dependencies: Accuracy certification; safety/regulatory approval; error detection.
- Personalized education at scale (sector: education/edtech)
- Use case: Adaptive visuals, problem sets, and multi-image sequences tailored to learner profiles.
- Tools/workflows: Curriculum-aware generators; difficulty-tiered outputs (Easy/Medium/Hard).
- Assumptions/dependencies: Pedagogical alignment; fairness audits; multilingual coverage.
- Medical imaging synthesis and patient education (sector: healthcare)
- Use case: Synthetic training data for CV tasks; patient-facing illustrative visuals for procedures or conditions.
- Tools/workflows: Domain-conditioned generation; clinician-in-the-loop review.
- Assumptions/dependencies: Not for diagnosis; strict regulatory guidance; de-identification and ethics controls.
- Content provenance and watermarking at scale (sector: policy/platform governance)
- Use case: Embedding and verifying provenance (e.g., C2PA) for generated and edited images.
- Tools/workflows: Watermark insertion/verification; provenance metadata pipelines.
- Assumptions/dependencies: Industry standard adoption; robustness to transformations; user acceptance.
- Automated catalog creation from minimal inputs (sector: retail/marketplaces)
- Use case: Generating full product galleries from a few references, maintaining brand and factual consistency.
- Tools/workflows: Multi-image style/attribute transfer; “best-of-n” selection; human QA.
- Assumptions/dependencies: Legal/ethics for representation; accuracy checks; return/complaint risk management.
- Fairness and robustness reporting (sector: academia/policy)
- Use case: Public evaluation using DreamEval-like tiered benchmarks; model cards for multimodal generation.
- Tools/workflows: Continuous auditing; difficulty-stratified testing; human preference alignment (RLHF) tracking.
- Assumptions/dependencies: Representative datasets; transparent metrics; governance frameworks.
- 3D workflow integration (sector: VFX/gaming/industrial design)
- Use case: Generating texture maps (albedo/normal/roughness), decals, and style references for 3D assets and scenes.
- Tools/workflows: Plugins for Blender/Unreal; UV-consistency assistants; multi-view coherence.
- Assumptions/dependencies: Cross-view consistency; material realism; pipeline integration.
- Accessibility-first visual generation (sector: public sector/enterprise)
- Use case: Automatic alt-text, high-contrast palettes, and accessible layouts for public communications.
- Tools/workflows: Accessibility validators; PE-powered captioning; layout adjusters.
- Assumptions/dependencies: Caption reliability; compliance with WCAG; human review for critical communications.
- Cross-lingual creative markets expansion (sector: global media)
- Use case: Consistent text rendering and editing across more languages and scripts beyond current strengths.
- Tools/workflows: Extended multilingual PE and captioning models; script-specific typography support.
- Assumptions/dependencies: Data coverage for low-resource languages; font/script rendering fidelity; localization QA.
Glossary
- activation offloading: Transferring intermediate activations from GPU to host/storage to reduce peak memory during large-scale training. "Memory usage is optimized through timely release of hidden states, activation offloading, and enhanced FSDP support, enabling training of large models within available GPU resources."
- adaptive 4/8-bit hybrid quantization: A mixed-precision quantization scheme that assigns 4-bit or 8-bit precision per layer/block to balance speed and accuracy. "Our approach uses an adaptive 4/8-bit hybrid quantization, which involves offline smoothing to handle outliers, a search-based optimization to find the best granularity and scaling for sensitive layers, and post-training quantization (PTQ) to finalize parameters."
- Adversarial Distribution Matching (ADM): An adversarial objective that aligns the generated and target data distributions to improve distillation/efficiency. "Following this, an Adversarial Distribution Matching (ADM) framework employs a learnable, diffusion-based discriminator for fine-tuning, enabling a more fine-grained matching of complex distributions."
- Adversarial Distillation post-training (ADP): A distillation stage using adversarial training to initialize and stabilize accelerated sampling. "starting with a robust Adversarial Distillation post-training (ADP) stage that uses a hybrid discriminator to ensure a stable initialization."
- causal diffusion: A diffusion-generation setup with causal structure (e.g., autoregressive/ordered conditioning) enabling joint tasks in a single framework. "We pioneer a joint post-training that integrates both T2I generation and image editing through a causal diffusion designed in the DiT framework."
- Canny edges: Edge maps computed by the Canny detector used as structural guidance for controllable generation. "Visual signals, such as Canny edges, sketches, inpainting masks, or depth maps, have long been a crucial component of controllable generation."
- ControlNet: An auxiliary conditioning network that injects structural or control signals (e.g., edges, depth) into diffusion models. "Traditionally, this capability has been developed using multiple specialized models such as ControlNet \cite{zhang2023addingconditionalcontroltexttoimage,li2025controlnet}."
- cross-modal embedding: A shared representation space aligning images and text to improve retrieval/alignment. "and (4) we adopt a stronger cross-modal embedding for imageâtext alignment, substantially improving our multimodal retrieval engine."
- CUDA kernels: Custom GPU kernels written in NVIDIA’s CUDA to accelerate compute-critical operations. "Performance-critical operations are accelerated by combining torch.compile with handcrafted CUDA kernels and operator fusion, reducing redundant memory access."
- deduplication pipeline: A data-processing workflow to detect and remove duplicate or near-duplicate samples. "we combine semantic and low-level visual embeddings in the deduplication pipeline to boost the deduplication results, balancing fine-grained distribution;"
- diffusion-based discriminator: A discriminator built on diffusion modeling principles to provide fine-grained adversarial feedback. "an Adversarial Distribution Matching (ADM) framework employs a learnable, diffusion-based discriminator for fine-tuning, enabling a more fine-grained matching of complex distributions."
- Diffusion Transformer (DiT): A diffusion model architecture that replaces U-Nets with Transformers for denoising in latent/image space. "Building on recent advances in diffusion transformers (DiTs), state-of-the-art open-source and commercial systems have emerged, such as Stable Diffusion \cite{rombach2022high}, FLUX series \cite{flux2023,labs2025flux1kontextflowmatching}, Seedream models \cite{gong2025seedream,gao2025seedream,shi2024seededit}, GPT-4o image generation \cite{gpt-4o} and Gemini 2.5 flash \cite{gemini2.5}."
- dual-axis collaborative data sampling framework: A data selection strategy that jointly optimizes for visual morphology and semantic distribution. "In Seedream 3.0, we introduced a dual-axis collaborative data sampling framework that jointly optimizes pre-training data along two dimensions: visual morphology and semantic distribution."
- Elo scores: A comparative rating metric (from Elo rating) used here to rank model performance via pairwise judgments. "The Elo scores are obtained from the Artificial Analysis Arena."
- expert parallelism: A model-parallel technique distributing expert modules (e.g., in MoE) across devices to scale capacity. "We employ Hybrid Sharded Data Parallelism (HSDP) to efficiently shard weights and support large-scale training without resorting to tensor or expert parallelism."
- few-step sampling: Generating images with a very small number of diffusion steps while maintaining quality. "Our unified pipeline enables highly efficient few-step sampling, drastically reducing the Number of Function Evaluations (NFE) while achieving results that match or surpass baselines requiring dozens of steps across key dimensions like aesthetic quality, text-image alignment, and structural fidelity, effectively balancing quality, efficiency, and diversity."
- FLOPs: Floating-point operations; a measure of computational cost for training/inference. "reducing the training and inference FLOPs considerably."
- FSDP: Fully Sharded Data Parallel; shards model parameters, gradients, and optimizer states across devices to save memory. "Memory usage is optimized through timely release of hidden states, activation offloading, and enhanced FSDP support, enabling training of large models within available GPU resources."
- Gaussian prior: The standard normal distribution used as the reference/noise prior in diffusion modeling. "each sample follows an optimized, adaptive trajectory, rather than a shared path to a Gaussian prior."
- global greedy sample allocation strategy: A scheduling policy to balance variable-length workloads across GPUs for better utilization. "To address workload imbalance from variable sequence lengths, we introduce a global greedy sample allocation strategy with asynchronous pipelines, achieving more balanced per-GPU utilization."
- hardware-aware framework combining quantization and sparsity: An optimization approach that co-designs quantization and sparse execution with the target hardware for speed without quality loss. "To further boost inference performance without quality loss, we employ a hardware-aware framework combining quantization and sparsity."
- Hybrid Sharded Data Parallelism (HSDP): A data-parallel scheme that shards model weights to scale training without tensor/expert parallelism. "We employ Hybrid Sharded Data Parallelism (HSDP) to efficiently shard weights and support large-scale training without resorting to tensor or expert parallelism."
- hybrid discriminator: A discriminator architecture that combines multiple discriminator forms/inputs to stabilize adversarial training. "starting with a robust Adversarial Distillation post-training (ADP) stage that uses a hybrid discriminator to ensure a stable initialization."
- in-context reasoning: The ability to infer and generate outputs by leveraging implicit cues from the given text/images without explicit instruction. "it demonstrates exceptional multimodal capabilities in complex tasks, including precise image editing and in-context reasoning, and also allows for multi-image reference, and can generate multiple output images."
- inpainting masks: Binary/soft masks indicating regions to be synthesized or filled during editing/generation. "Visual signals, such as Canny edges, sketches, inpainting masks, or depth maps, have long been a crucial component of controllable generation."
- Key-Value (KV) caches: Cached attention keys and values reused across decoding steps to reduce computation. "We further improve this process by incorporating a loss function on Key-Value (KV) caches to enable efficient reuse during inference and an auxiliary cross-entropy loss on logits to refine the draft model."
- latent space: The compressed representation space produced by the VAE where images are encoded as tokens/latents. "significantly reducing the number of image tokens in latent space."
- Number of Function Evaluations (NFE): The count of model evaluations (e.g., diffusion steps) required to produce a sample. "Our unified pipeline enables highly efficient few-step sampling, drastically reducing the Number of Function Evaluations (NFE) while achieving results that match or surpass baselines requiring dozens of steps..."
- OCR: Optical Character Recognition; converting images of text into machine-encoded text. "For synthetic data, we used both OCR output and LaTeX source code~(when available) to generate diverse formula images that vary in structure (layout, symbol density) and resolution."
- operator fusion: Combining multiple operations into a single fused kernel to reduce memory traffic and improve throughput. "Performance-critical operations are accelerated by combining torch.compile with handcrafted CUDA kernels and operator fusion, reducing redundant memory access."
- post-training quantization (PTQ): Quantizing a trained model without additional fine-tuning to lower precision for faster inference. "Our approach uses an adaptive 4/8-bit hybrid quantization, which involves offline smoothing to handle outliers, a search-based optimization to find the best granularity and scaling for sensitive layers, and post-training quantization (PTQ) to finalize parameters."
- Prompt Engineering (PE) model: A model that rewrites, routes, and augments user prompts (and related inputs) to better steer the generator. "and a carefully fine-tuned prompt engineering (PE) model was also developed."
- Reinforcement Learning from Human Feedback (RLHF): Using human preference data to optimize a model via RL for alignment with human judgments. "Subsequently, we implement Reinforcement Learning from Human Feedback (RLHF) to meticulously align the model's outputs with nuanced human preferences."
- speculative decoding: An acceleration technique that drafts future tokens/features and verifies them to reduce latency. "for inference acceleration, we integrate adversarial distillation, distribution matching, and quantization, as well as speculative decoding."
- Supervised Fine-Tuning (SFT): Fine-tuning on curated input-output pairs to instill desired behaviors/styles. "This is followed by Supervised Fine-Tuning (SFT), which works to inculcate specific artistic qualities."
- tensor parallelism: Splitting model tensors across multiple devices for model-parallel scaling. "We employ Hybrid Sharded Data Parallelism (HSDP) to efficiently shard weights and support large-scale training without resorting to tensor or expert parallelism."
- text-to-image (T2I): Generating images conditioned on textual prompts. "We introduce Seedream 4.0, an efficient and high-performance multimodal image generation system that unifies text-to-image (T2I) synthesis, image editing, and multi-image composition within a single framework."
- torch.compile: A PyTorch compilation/graph optimization feature to speed up model execution. "Performance-critical operations are accelerated by combining torch.compile with handcrafted CUDA kernels and operator fusion, reducing redundant memory access."
- Variational Autoencoder (VAE): A probabilistic autoencoder that compresses images into latents and reconstructs them, enabling token reduction and high-res generation. "We develop a highly efficient diffusion transformer with a powerful VAE which also can reduce the number of image tokens considerably."
- Vision LLM (VLM): A multimodal model that jointly processes images and text for understanding/generation tasks. "we incorporate a VLM model with a strong understanding of multimodal inputs into our systemï¼ as designed in SeedEdit \cite{shi2024seededit}, which enables it with strong multimodal generation ability."
Collections
Sign up for free to add this paper to one or more collections.