- The paper introduces HVGC to produce disentangled captions for video and audio, effectively eliminating modal interference.
- It presents BridgeDiT featuring Dual Cross-Attention fusion, which robustly synchronizes audio and visual modalities through bidirectional feature exchange.
- Experimental results demonstrate state-of-the-art performance on benchmarks like AVSync15, improving both semantic alignment and audio-video synchronization.
Taming Text-to-Sounding Video Generation via Advanced Modality Condition and Interaction
Introduction and Motivation
Text-to-Sounding Video (T2SV) generation, which aims to synthesize temporally synchronized video and audio from a textual prompt, is a critical step toward comprehensive world modeling. While unimodal text-to-video (T2V) and text-to-audio (T2A) models have achieved high fidelity, their naive combination fails to ensure semantic and temporal alignment between modalities. Existing dual-tower architectures, which leverage pre-trained T2V and T2A backbones with a lightweight interaction module, have become the dominant paradigm due to their practicality and efficiency. However, two fundamental challenges persist: (1) modal interference from shared text conditioning, and (2) suboptimal cross-modal feature interaction.
Hierarchical Visual-Grounded Captioning (HVGC)
The conditioning problem arises because prior dual-tower methods typically use a single, shared text caption for both video and audio towers, leading to out-of-distribution conditioning and degraded performance. The paper introduces the Hierarchical Visual-Grounded Captioning (HVGC) framework to address this. HVGC is a three-stage pipeline that generates disentangled, modality-pure captions for each tower:
- Stage 1: A Vision-Language Large Model (VLLM) produces a detailed, visually grounded video caption (TV).
- Stage 2: A LLM extracts auditory-relevant tags from TV.
- Stage 3: The LLM generates a pure audio caption (TA) using both TV and the extracted audio tags, ensuring the audio caption is contextually consistent and free from visual attributes.

Figure 1: The HVGC framework generates disentangled, modality-pure captions for video and audio, eliminating modal interference.
This hierarchical approach is motivated by the observation that direct audio captioning from raw audio or audio LLMs is prone to hallucination due to information sparsity. By grounding audio captioning in the visual context, HVGC produces accurate, non-hallucinatory captions for both modalities.
BridgeDiT Architecture and Dual Cross-Attention Fusion
To address the interaction problem, the paper proposes BridgeDiT, a dual-tower diffusion transformer architecture. Each tower is initialized from a pre-trained T2V or T2A backbone and remains largely frozen. The key innovation is the BridgeDiT Block, which implements a Dual Cross-Attention (DCA) mechanism for bidirectional, symmetric feature exchange between the video and audio streams.
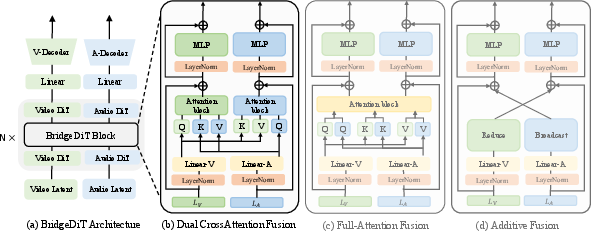
Figure 2: The BridgeDiT architecture with parallel video and audio DiT streams, connected by BridgeDiT Blocks implementing Dual Cross-Attention fusion.
The DCA mechanism operates as follows:
- In the Audio-to-Video stream, video features are updated via cross-attention using audio features as keys and values.
- In the Video-to-Audio stream, audio features are updated analogously using video features.
- Both streams employ residual connections and adaptive layer normalization (AdaLN) for timestep conditioning.
Alternative fusion strategies, including Full Attention, Additive Fusion, and unidirectional cross-attention (ControlNet-style), are evaluated. DCA consistently outperforms these baselines in both semantic and temporal synchronization metrics.
Experimental Results
The model is evaluated on three benchmarks: AVSync15, VGGSound-SS, and Landscape. The evaluation protocol covers video quality (FVD, KVD), audio quality (FAD, KL), text alignment (CLIPSIM, CLAP), and audio-video synchronization (ImageBind VA-IB, AV-Align).

Figure 3: Examples of sounding videos generated by BridgeDiT, demonstrating high-fidelity, temporally synchronized, and text-aligned audio-visual content.
Key findings include:
- BridgeDiT achieves state-of-the-art results on most metrics across all datasets. For example, on AVSync15, BridgeDiT attains FVD 765.74, FAD 5.34, and AV-Align 0.275, outperforming all baselines.
- The HVGC framework is critical: ablation studies show that shared captions or audio LLM-based captions result in significant performance drops, especially in synchronization and audio quality.
- The DCA fusion mechanism yields superior AV-Align and VA-IB scores compared to Full Attention, Additive Fusion, and unidirectional cross-attention, confirming the necessity of symmetric, bidirectional interaction.
Ablation and Analysis
Ablation studies further dissect the contributions:
- Captioning: Disentangled, visually grounded captions (HVGC) are essential for eliminating modal interference. Audio LLMs, even when trained, hallucinate non-existent sounds, degrading synchronization.
- Fusion Mechanism: DCA is empirically superior for both semantic and temporal alignment. Full Attention is the next best, but less efficient and less robust.
- Block Placement: Uniformly distributing BridgeDiT Blocks in early-to-mid layers yields the best synchronization, indicating that early feature exchange is critical.
Qualitative and Human Evaluation
Case studies illustrate that BridgeDiT produces videos where visual events and audio cues are tightly synchronized and faithful to the text prompt. Human evaluation on AVSync15 confirms that BridgeDiT is preferred over all baselines in video quality, audio quality, text alignment, synchronization, and overall impression.
Implications and Future Directions
This work demonstrates that advanced modality-specific conditioning and symmetric, bidirectional cross-modal interaction are essential for high-fidelity, temporally synchronized T2SV generation. The HVGC framework provides a generalizable approach for disentangled conditioning in other multi-modal generative tasks. The DCA mechanism sets a new standard for efficient and effective cross-modal fusion in dual-tower architectures.
Practical implications include improved generation of synthetic audio-visual content for media, entertainment, and simulation. The approach is limited by the quality of pre-trained backbones and the availability of high-quality, paired audio-visual data. Future work should address speech and music generation, lip synchronization, and reinforcement learning with human feedback for further refinement.
Conclusion
The paper provides a comprehensive solution to the core challenges of T2SV generation by introducing HVGC for disentangled conditioning and BridgeDiT with DCA for optimal cross-modal interaction. The approach achieves state-of-the-art results, validated by both automatic metrics and human preference, and offers a robust foundation for future research in multi-modal generative modeling.